
Robust Monetary Policy with Imperfect Knowledge
Keywords: Monetary Policy, natural rate misperceptions, rational expectations, learning
Abstract:
JEL Classification System: E52
Correspondence: Orphanides: Federal Reserve Board, Washington, D.C. 20551, Tel.: (202) 452-2654, e-mail: [email protected]. Williams: Federal Reserve Bank of San Francisco, 101 Market Street, San Francisco, CA 94105, Tel.: (415) 974-2240, e-mail: [email protected].org.
* We would like to thank Jim Bullard, Stephen Cecchetti, Alex Cukierman, Stephen Durlauf, Vitor Gaspar, Stefano Eusepi, Bruce McGough, Ricardo Reis, and participants at numerous presentations for useful discussions and comments. The opinions expressed are those of the authors and do not necessarily reflect views of the Board of Governors of the Federal Reserve System or the management of the Federal Reserve Bank of San Francisco.
1 Introduction
To paraphrase Clausewitz, monetary policy is conducted in a fog of uncertainty. Our understanding of many key features of the macroeconomic landscape remains imperfect, and the landscape itself evolves over time. As emphasized by McCallum (1988) and Taylor (1993), a crucial requirement for a monetary policy rule is that its good performance be robust to various forms of model misspecification. In this view, it is not enough for a monetary policy rule to be optimal in one specific model, but instead it must be "stress tested" in a variety of alternative model environments before one can conclude with any confidence that the policy is likely to perform well in practice.1 In this paper, we examine the performance and robustness of monetary policy rules in the context of fundamental uncertainty related to the nature of expectations formation and structural change in the economy. Our goal is to identify characteristics of policy rules that are robust to these types of imperfect knowledge, as well as to identify those that are not.
The first form of uncertainty facing the policymaker that we consider relates to the way in which agents form expectations. There is a growing literature that analyzes a variety of alternative models of expectations formation. The key conclusion we take from our reading of this literature is that there is a great deal of uncertainty regarding exactly how private expectations are formed. In particular, the standard assumption of rational expectations may be overly restrictive for monetary policy analysis, especially in the context of an economy undergoing structural change. But, the available evidence does not yet provide unequivocal support for any other single model of expectations formation. Therefore, fundamental uncertainty about the nature of expectations formation appears to be an unavoidable aspect of the policy environment facing central banks face today.
In this paper, we consider two popular alternative models of private expectations formation. Our approach can easily be extended to incorporate other alternative models of expectations as well, but for reasons of tractability, we leave this for future research. One model is rational expectations, which assumes that private agents know all the parameters of the model and form expectations accordingly. This, of course, is the model used in much of the recent monetary policy rule literature. The second model is perpetual learning, where it is assumed that agents do not know the true parameters of the model, but instead continuously reestimate a forecasting model (see Sargent (1999) and Evans and Honkapohja (2001) for expositions of this model). This form of learning represents a relatively modest, and arguably realistic, deviation from rational expectations. An advantage of the perpetual learning framework is that it allows varying degrees of deviations in expectations formation relative to the rational expectations benchmark, which are characterized by variation in a single model parameter. As shown in Orphanides and Williams (2004, 2005a, 2005b), perpetual learning on the part of economic agents introduces an additional layer of interaction between monetary policy, expectations, and economic outcomes.
The second source of uncertainty that we consider is unobserved structural change, which we represent in the form of low-frequency variation in the natural rates of unemployment and interest. The equilibrium of our model economy is described in terms of deviations from these natural rates. In particular, the inflation rate is in part determined by the unemployment gap, the deviation of the unemployment rate from its natural rate. Similarly, the unemployment rate gap is determined in part by the real interest rate gap, the difference between the real short-term interest rate and the real natural rate of interest. We assume that the central bank does not observe the true values of the natural rates and, indeed, is uncertain about the processes generating the natural rates.
Natural rate uncertainty presents a difficulty for policymakers who follow an interest rate rule with the goal of maintaining price stability and minimizing fluctuations of unemployment around its natural rate. With perfect knowledge of natural rates, the setting of policy would ideally account for the evolution of the economy's natural rates. But, if policymakers do not know the values of the natural rates of interest and unemployment when they make policy decisions, they must either rely on inherently imprecise real-time estimates of these rates for setting the policy instrument, or, alternatively, eschew natural rates altogether and follow a policy rule that does not respond to natural rate estimates.
The evidence suggests there exists considerable uncertainty regarding the natural rates of unemployment and interest and ambiguity about how best to model and estimate natural rates, even with the benefit of hindsight. 2![]() 3Indeed, the measurement of the natural rate of output has been a key issue in U.S. monetary policy debates in both the 1970s and 1990s, and uncertainty about the natural rate of interest has been the topic of increasing discussion. The evidence indicates that substantial
misperceptions regarding the economy's natural rates may persist for some time, before their presence is recognized. In the meantime, policy intended to be contractionary may actually inadvertently be overly expansionary, and vice versa. Moreover, in an environment where the private sector is
learning, the learning process can interact with the policy errors and feed back to economic outcomes, as pointed out Orphanides and Williams, (2004, 2005a, 2005b) and Gaspar, Smets and Vestin (2006).
3Indeed, the measurement of the natural rate of output has been a key issue in U.S. monetary policy debates in both the 1970s and 1990s, and uncertainty about the natural rate of interest has been the topic of increasing discussion. The evidence indicates that substantial
misperceptions regarding the economy's natural rates may persist for some time, before their presence is recognized. In the meantime, policy intended to be contractionary may actually inadvertently be overly expansionary, and vice versa. Moreover, in an environment where the private sector is
learning, the learning process can interact with the policy errors and feed back to economic outcomes, as pointed out Orphanides and Williams, (2004, 2005a, 2005b) and Gaspar, Smets and Vestin (2006).
We examine the effects and policy implications of imperfect knowledge of expectations formation and unknown time-varying natural rates using a quarterly model of the U.S. economy estimated over 1981-2004. We first consider the performance and robustness characteristics of simple operational monetary policy rules under perfect and imperfect knowledge. We then analyze the characteristics and performance of policy rules optimized taking into account model uncertainty about expectations formation and natural rate uncertainty. We approach this problem of optimal policy under uncertainty from Bayesian and Min-Max perspectives and compare the results.
Our analysis yields several key findings. First, the scope for stabilization of the real economy in our model with imperfect knowledge is significantly reduced relative to the economy under perfect knowledge (where private agents and the central bank are assumed to know all features of the model). Second, monetary policies that would be optimal under perfect knowledge can perform very poorly when knowledge is imperfect. Third, the optimal Bayesian policy under uncertainty performs very well across all of our model specifications and is therefore highly robust to the types of model uncertainty that we examine here. This policy features greater policy inertia, a larger response to inflation, and a smaller response to the perceived unemployment gap than would be optimal under perfect knowledge. Fourth, the resulting optimal Bayesian and Min-Max policies are closely related to policies that target the price level as opposed to the inflation rate, despite the fact that we assume that the objective is to stabilize the inflation rate not the price level.
The remainder of the paper is organized as follows. Section II discusses the problems for monetary policy caused by natural rate mismeasurement. Section III briefly describes the estimated macro model. Section IV describes the class of monetary policy rules that we study. Section V presents the models of expectations formation and natural rate estimation. Section VI provides details on the simulation methodology. Section 7 analyzes monetary policy under different models of expectations formation, but assuming constant natural rates. Section 8 explores the joint effects of alternative models of expectations and time-varying natural rates. Section 9 examines the optimal Bayesian and Min-Max policies. Section 10 concludes.
2 Natural Rates, Misperceptions, and Policy Errors
We start our analysis with an illustration of some of the difficulties presented by the evolution of the economy's natural rates. To highlight the role of natural rate misperceptions and the role of policy in propagating them in the economy, consider a generalization of the simple policy rule
proposed by Taylor (1993). Let ![]() denote the short-term interest rate employed as the policy instrument, (the federal funds rate in the Unites States),
denote the short-term interest rate employed as the policy instrument, (the federal funds rate in the Unites States), ![]() the rate of inflation, and
the rate of inflation, and ![]() the rate of unemployment, all measured in quarter
the rate of unemployment, all measured in quarter ![]() . The classic Taylor rule can then be expressed by
. The classic Taylor rule can then be expressed by
where
The Taylor rule has been found to perform quite well in terms of stabilizing economic fluctuations, at least when the natural rates of interest and unemployment are accurately measured.5 However, historical experience suggests that policy guidance from this family of rules may be rather sensitive to misperceptions regarding the natural rates of interest and unemployment. The experience of the 1970s, discussed in Orphanides (2003b) and Orphanides and Williams (2005b), offers a particularly stark illustration of policy errors that may result.6
Following Orphanides and Williams (2002), we explore two dimensions along which the Taylor rule has been generalized that in combination offer the potential to mitigate the problem of natural rate mismeasurement. The first aims to mitigate the effects of mismeasurement of the natural rate of unemployment by partially (or even fully) replacing the response to the unemployment gap with one to the change in the unemployment rate.7 The second dimension we explore is incorporation of policy inertia, represented by the presence of the lagged short-term interest rate in the policy rule. Policy rules that exhibit a substantial degree of inertia typically improve the stabilization performance of the Taylor rule in forward-looking models.8 As argued by Orphanides and Williams (2002), the presence of inertia in the policy rule also reduces the influence of the estimate of the natural rate of interest on the current setting of monetary policy and, therefore, the extent to which misperceptions regarding the natural rate of interest affect policy decisions. To see this, consider the generalized Taylor rule of the form
The degree of policy inertia is measured by
To see more clearly how misperceptions regarding the natural rates of unemployment and interest translate to policy errors it is useful to distinguish the real-time estimates of the natural rates,
![]() and
and
![]() , available to policymakers when policy decisions are made, from their "true" values
, available to policymakers when policy decisions are made, from their "true" values ![]() and
and ![]() . If policy follows the generalized rule given by equation (2), then the "policy error" introduced in period
. If policy follows the generalized rule given by equation (2), then the "policy error" introduced in period ![]() by misperceptions in period
by misperceptions in period ![]() is given by
is given by
A limiting case that is immune to natural rate mismeasurement of the kind considered here is a "difference" rule, in which
![]() and
and
![]() :
:
As Orphanides and Williams (2002) point out, this policy rule is as simple, in terms of the number of parameters, as the original formulation of the Taylor rule and is arguably simpler to implement in practice since it does not require knowledge of the natural rates of interest or unemployment. However, because this type of rule ignores potentially useful information about the natural rates of interest and unemployment, its performance relative to the classic "level" Taylor rule and the generalized rule will depend on the degree of mismeasurement and the structure of the model economy, as we explore below.
3 An Estimated Model of the U.S. Economy
We examine the interaction of natural rate misperceptions, learning, and expectations for the design of robust monetary policy rules using a simple quarterly model motivated by the recent literature on micro-founded models incorporating some inertia in inflation and output (see Woodford, 2003, for a fuller discussion). The specification of the model is closely related to that in Gianonni and Woodford (2005), Smets (2003), and others. The key difference is that instead of the output gap concept in these models, we employ the unemployment gap concept as the cyclical measure of real economic activity. As already noted, the two concepts are closely related in practice by Okun's law and the properties of the model are largely invariant to this choice. In addition, the empirical problem of measuring the natural rate of unemployment--needed to define the unemployment gap--is essentially similar to the problem of measuring the level of potential output--needed to define the output gap.
3.1 The Structural Model
The model consists of the following two structural equations:
where
The "Phillips curve" in this model (equation 4) relates inflation (measured as the annualized percent change in the GNP or GDP price index, depending on the period) during quarter ![]() to
lagged inflation, expected future inflation, and the unemployment gap during the current quarter. The parameter
to
lagged inflation, expected future inflation, and the unemployment gap during the current quarter. The parameter
![]() measures the importance of expected inflation on the determination of inflation, while
measures the importance of expected inflation on the determination of inflation, while
![]() captures inflation inertia. The unemployment equation (equation 5) relates the unemployment rate during quarter
captures inflation inertia. The unemployment equation (equation 5) relates the unemployment rate during quarter ![]() to the expected future unemployment rate and one lag of the unemployment rate and the ex ante real interest rate gap.
to the expected future unemployment rate and one lag of the unemployment rate and the ex ante real interest rate gap.
We imposed the coefficients
![]() on the lead-lag structure of the two equations. We opted to concentrate attention on this case to ensure that expectations are of comparable importance for the
determination of the rates of inflation and unemployment in the model. These values for
on the lead-lag structure of the two equations. We opted to concentrate attention on this case to ensure that expectations are of comparable importance for the
determination of the rates of inflation and unemployment in the model. These values for
![]() and
and ![]() are the largest allowable by the micro-founded theory
developed in Woodford (2003) and are consistent with the empirical findings of Giannoni and Woodford (2005) and others.10To estimate the remaining
parameters, as in Orphanides and Williams (2002), we rely on survey forecasts as proxies for the expectations variable which allows estimation of equations (4) and (5) with ordinary least squares. Specifically, we use the mean values of the forecasts provided in the Survey of Professional
Forecasters. From this survey, we use the forecasts of the unemployment rate and three-month treasury bill rate as reported. For inflation, we rely on the annualized log difference of the GNP or GDP price deflator, which we construct from the forecasts of real and nominal GNP or GDP which are
reported in the survey. We posit that the relevant expectations are those formed in the previous quarter; that is, we assume that the expectations determining
are the largest allowable by the micro-founded theory
developed in Woodford (2003) and are consistent with the empirical findings of Giannoni and Woodford (2005) and others.10To estimate the remaining
parameters, as in Orphanides and Williams (2002), we rely on survey forecasts as proxies for the expectations variable which allows estimation of equations (4) and (5) with ordinary least squares. Specifically, we use the mean values of the forecasts provided in the Survey of Professional
Forecasters. From this survey, we use the forecasts of the unemployment rate and three-month treasury bill rate as reported. For inflation, we rely on the annualized log difference of the GNP or GDP price deflator, which we construct from the forecasts of real and nominal GNP or GDP which are
reported in the survey. We posit that the relevant expectations are those formed in the previous quarter; that is, we assume that the expectations determining ![]() and
and ![]() are those collected in quarter
are those collected in quarter ![]() . This matches the informational structure in the
theoretical models (see Woodford, 2003, and Giannoni and Woodford, 2005). To match the inflation and unemployment data as best as possible with these forecasts, we use first announced estimates of these series. Our primary sources for these data are the Real-Time Dataset for Macroeconomists and the
Survey of Professional Forecasters, both currently maintained by the Federal Reserve Bank of Philadelphia (Zarnowitz and Braun (1993), Croushore (1993) and Croushore and Stark (2001)). For the estimation of the inflation equation, we also use the most recent estimates of the NAIRU by the
Congressional Budget Office (2001, 2002) as a proxy of the true level of the historical natural rate of unemployment.
. This matches the informational structure in the
theoretical models (see Woodford, 2003, and Giannoni and Woodford, 2005). To match the inflation and unemployment data as best as possible with these forecasts, we use first announced estimates of these series. Our primary sources for these data are the Real-Time Dataset for Macroeconomists and the
Survey of Professional Forecasters, both currently maintained by the Federal Reserve Bank of Philadelphia (Zarnowitz and Braun (1993), Croushore (1993) and Croushore and Stark (2001)). For the estimation of the inflation equation, we also use the most recent estimates of the NAIRU by the
Congressional Budget Office (2001, 2002) as a proxy of the true level of the historical natural rate of unemployment.
We obtain the following OLS estimates for our model between 1981:4 and 2004:2, where the starting point of this sample reflects the availability of the Survey of Professional Forecasters data for the short-term interest rate.
| (6) |
| (7) |
The numbers in parentheses are the estimated standard errors of the corresponding regression coefficients. The estimated unemployment equation also includes a constant term that provides an estimate of the natural real interest rate, which is assumed to constant in estimating this equation. The estimated residuals show no signs of serial correlation in the price equation. Some serial correlation is suggested by the residuals of the unemployment equation, but for simplicity we ignore this serial correlation in evaluating the performance of monetary policies.
We model the natural rates as exogenous AR(1) processes independent of all other variables. We assume these processes are stationary based on the finding using the standard ADF test that one can reject the null of nonstationarity of both the unemployment rate and real federal funds rate over 1950-2003 at the 5 percent level. However to capture the near-nonstationarity of the series, we set the AR(1) coefficient to 0.99 and and then calibrate the innovation variances to be consistent with estimates of time variation in the natural rates in postwar U.S. data. In particular, we set the innovation standard deviation of the natural rate of unemployment to 0.07 and that of the natural rate of interest to 0.085. These values imply an unconditional standard deviation of the natural rate of unemployment (interest) of 0.50 (0.60), in the low end of the range of standard deviations of smoothed estimates of these natural rates suggested by various estimation methods (see Orphanides and Williams 2002 for details).
4 Monetary Policy
We evaluate the performance of monetary policies rules using a loss equal to the weighted sum of the unconditional variances of the inflation rate, the unemployment gap, and the change in the nominal federal funds rate:
| (8) |
where
We complete the structural model by specifying a monetary policy rule according to which the federal funds rate is determined by a generalized Taylor Rule of the form:
| (9) |
where
In the following we focus on different versions of this policy rule. In one, all four parameters are freely chosen. We also examine the two alternative simpler, 2-parameter rules that are nested by the generalized rule: The "level" variant, where we constrain
![]() and
and
![]() to be zero, and which is closer to the original Taylor rule; and the "difference" variant, where we impose the constraints
to be zero, and which is closer to the original Taylor rule; and the "difference" variant, where we impose the constraints
![]() and
and
![]() .
.
5 Expectations
We consider two methods by which private agents form expectations: rational expectations and learning. Under rational expectations, private agents know all features of the model, including the realized values of the natural rates. Under learning, we assume that private agents form expectations using an estimated forecasting model, and that the central bank forms estimates of the natural rates of interest and unemployment using simple time-series methods. Specifically, following Orphanides and Williams (2005c), we posit that private agents and central banks engage in perpetual learning, that is they reestimate their respective models using a constant-gain least squares algorithm that weighs recent data more heavily than past data.13 In this way, these estimates allow for the possible presence of time variation in the economy, including in the natural rates of interest and unemployment. Given the structure of the model, private agents need to forecast inflation, the unemployment rate, and the federal funds rate for up to two quarters into the future.
5.1 Perpetual Learning with Least Squares
Under perfect knowledge with no shocks to the natural rate of unemployment, the predictable components of inflation, the unemployment rate, and the interest rate in the model each depend on a constant, one lag each of the inflation and the ex post real interest rate (the difference between the nominal interest rate and the inflation rate), and one or two two lags of the unemployment rate, depending on whether the policy rule responds to just the lagged unemployment gap or also the change in the unemployment rate. We assume that agents estimate forecasting equations for the three variables using a restricted VAR of the form corresponding to the reduced form of the rational expectations (RE) equilibrium with constant natural rates. They then construct multi-period forecasts from the estimated VAR.
Consider the case where policy is described by the Taylor rule. To fix notation, let ![]() denote the
denote the ![]() vector consisting of the inflation rate, the unemployment rate, and the interest rate, each measured at time
vector consisting of the inflation rate, the unemployment rate, and the interest rate, each measured at time ![]() :
:
![]() ; let
; let ![]() be the
be the ![]() vector of regressors in the forecast model:
vector of regressors in the forecast model:
![]() ; let
; let ![]() be the
be the ![]() vector of coefficients of the forecasting model. This corresponds to the case of the Taylor rule. In the case of the generalized policy rule, the second lag of the unemployment rate also
appears in
vector of coefficients of the forecasting model. This corresponds to the case of the Taylor rule. In the case of the generalized policy rule, the second lag of the unemployment rate also
appears in ![]() .
.
Note that we impose that the forecasting model include only the variables that appear with non-zero coefficients in the reduced form of the rational expectations solution of the model with constant natural rates. In principle, these zero restrictions may help or hinder the forecasting performance of agents in the model. In practice, allowing agents to include additional lags of variables in the forecasting model worsens macroeconomic outcomes. Thus, by imposing this structure, we are likely erring on the side of understating the costs of learning on macroeconomic performance.
Using data through period ![]() , the least squares regression parameters for the forecasting model can be written in recursive form:
, the least squares regression parameters for the forecasting model can be written in recursive form:
where
Under the assumption of least squares learning with infinite memory,
![]() , as
, as ![]() increases,
increases,
![]() converges to zero. Assuming constant natural rates, this mechanism will converge to the correct expectations functions and the economy converges to the perfect knowledge rational
expectations equilibrium. That is, in our model the perceived law of motion that agents employ for forecasting corresponds to the correct specification of the equilibrium law of motion under rational expectations.
converges to zero. Assuming constant natural rates, this mechanism will converge to the correct expectations functions and the economy converges to the perfect knowledge rational
expectations equilibrium. That is, in our model the perceived law of motion that agents employ for forecasting corresponds to the correct specification of the equilibrium law of motion under rational expectations.
As noted above, to formalize perpetual learning we replace the decreasing gain implied by the infinite memory recursion with a small constant gain, ![]() .14 With imperfect knowledge, expectations are based on the perceived law of motion of the inflation process, governed by the perpetual learning algorithm described
above.
.14 With imperfect knowledge, expectations are based on the perceived law of motion of the inflation process, governed by the perpetual learning algorithm described
above.
5.2 Calibrating the Learning Rate
A key parameter for the constant-gain-learning algorithm is the updating rate ![]() . To calibrate the relevant range for this parameter we examined how well different values of
. To calibrate the relevant range for this parameter we examined how well different values of
![]() fit either the expectations data from the Survey of Professional Forecasters, following Orphanides and Williams (2005b). To examine the fit of the Survey of Professional Forecasters
(SPF), we generated a time series of forecasts using a recursively estimated VAR for the inflation rate, the unemployment rate, and the federal funds rate. In each quarter we reestimated the model using all historical data available during that quarter (generally from 1948 through the most recent
observation). We allowed for discounting of past observations by using geometrically declining weights. This procedure resulted in reasonably accurate forecasts of inflation and unemployment, with root mean squared errors (RMSE) comparable to the residual standard errors from the estimated
structural equations, (6) and (7). We found that discounting past data with values corresponding to
fit either the expectations data from the Survey of Professional Forecasters, following Orphanides and Williams (2005b). To examine the fit of the Survey of Professional Forecasters
(SPF), we generated a time series of forecasts using a recursively estimated VAR for the inflation rate, the unemployment rate, and the federal funds rate. In each quarter we reestimated the model using all historical data available during that quarter (generally from 1948 through the most recent
observation). We allowed for discounting of past observations by using geometrically declining weights. This procedure resulted in reasonably accurate forecasts of inflation and unemployment, with root mean squared errors (RMSE) comparable to the residual standard errors from the estimated
structural equations, (6) and (7). We found that discounting past data with values corresponding to ![]() in the range 0.01 to 0.04 yielded forecasts closest on average to the SPF than the
forecasts obtained with lower or higher values of
in the range 0.01 to 0.04 yielded forecasts closest on average to the SPF than the
forecasts obtained with lower or higher values of ![]() . In light of these results, we consider
. In light of these results, we consider
![]() as a baseline value for our simulations, but also examine the robustness of policies to alternative values of this parameter. The value
as a baseline value for our simulations, but also examine the robustness of policies to alternative values of this parameter. The value
![]() is also in line with the discounting reported by Sheridan (2003) as best for explaining the inflation expectations data reported in the Livingston Survey.
is also in line with the discounting reported by Sheridan (2003) as best for explaining the inflation expectations data reported in the Livingston Survey.
5.3 Policymaker's estimation of natural rates
Given the time variation in the natural rates, policymakers need to continuously reestimate these variables in real time. Based on the results of Williams (2005) who found that such a procedure performed well and was reasonably robust to model misspecification, we assume that policymakers use a simple constant gain method to update their natural rates based on the observed rates of unemployment and ex post real interest rates. Thus, policymakers update their estimates of the natural rates of unemployment and interest as follows:
| (12) |
| (13) |
where
The model under imperfect knowledge consists of the structural equations for inflation, the unemployment gap, the federal funds rate (the monetary policy rule), the forecasting model, and the updating rule for the natural rates of interest and unemployment.
6 Simulation Methodology
As noted above, we measure the performance of alternative policies rules based on the central bank loss equal to the weighted sum of unconditional variances of inflation, the unemployment gap, and the change in the funds rate. In the case of rational expectations with constant and known natural rates, we compute the unconditional variances numerically as described in Levin, Wieland, and Williams (1999). In all other cases, we compute approximations of the unconditional moments using stochastic simulations of the model.
6.1 Stochastic Simulations
For stochastic simulations, the initial conditions for each simulation are given by the rational expectations equilibrium with known and constant natural rates. Specifically, all model variables are initialized to their steady-state values, assumed without loss of generality to be zero. The
central bank's initial perceived levels of the natural rates are set to their true values, likewise equal to zero. Finally, the initial values of the ![]() and
and ![]() matrices describing the private agents' forecasting model are initialized to their respective values corresponding to reduced-form of the rational equilibrium solution to he structural model assuming constant and known
natural rates.
matrices describing the private agents' forecasting model are initialized to their respective values corresponding to reduced-form of the rational equilibrium solution to he structural model assuming constant and known
natural rates.
Each period, innovations are generated from Gaussian distributions with variances reported above. The innovations are assumed to be serially and contemporaneously uncorrelated. For each period, the structural model is simulated, the private agent's forecasting model is updated and a new set of forecasts computed, and the central bank's natural rate estimate is updated. We simulate the model for 41,000 periods and discard the first 1000 periods to mitigate the effects of initial conditions. We compute the unconditional moments from sample root mean squares from the remaining 40,000 periods (10,000 years) of simulation data.
Private agents' learning process injects a nonlinear structure into the model that may generate explosive behavior in a stochastic simulation of sufficient length for some policy rules that would do a good job of stabilizing the economy under rational expectations. One possible cause of such
explosive behavior is that the forecasting model itself may become explosive. We take the view that in practice private forecasters reject explosive models. We implement this by computing, in each period of the simulation, the maximum root of the forecasting VAR excluding the constants. If this
root falls below the critical value of 0.995, the forecast model is updated as described above; if not, we assume that the forecast model is not updated and the matrices ![]() and
and ![]() are held at their respective previous period values.15
are held at their respective previous period values.15
This constraint on the forecasting model is insufficient to assure that the model economy does not exhibit explosive behavior in all simulations. For this reason, we impose a second condition that restrains explosive behavior. In particular, if the inflation rate, nominal interest rate, or
unemployment gap exceed in absolute value six times their respective unconditional standard deviations (computed under the assumption of rational expectations and known and constant natural rates), then the variables that exceeds this bound is constrained to equal the corresponding limit in that
period. These constraints on the model are sufficient to avoid explosive behavior for the exercises that we consider in this paper and are rarely invoked for most of the policy rules we study, particularly for optimized policy rules. An illustrative example is the benchmark calibration of the model
with monetary policy given by the Taylor Rule with
![]() and
and
![]() , for which the limit on the forecasting model is binding less than 0.1 percent of the time, and that on the endogenous variables, only about 0.4 percent of the time.
, for which the limit on the forecasting model is binding less than 0.1 percent of the time, and that on the endogenous variables, only about 0.4 percent of the time.
7 Monetary Policy and Learning
We first consider the design of optimal monetary policy in the presence of learning by private agents but assuming that natural rates are constant and known by the policymaker. In this way we can more easily identify the private sector effects of learning in isolation. In the next section, we analyze the case of private learning with time varying natural rates that are unobserved by the policymaker.
7.1 The Effects of Learning under the Taylor Rule
To gauge the effects of learning for a given monetary policy rule, we consider macroeconomic performance under the Taylor Rule under alternative assumptions regarding the public's updating rate, ![]() . For these exercises, we assume that the policymaker knows the true values of the natural rates of interest and unemployment and, consequently, does not face the problem of natural rate misperceptions.
. For these exercises, we assume that the policymaker knows the true values of the natural rates of interest and unemployment and, consequently, does not face the problem of natural rate misperceptions.
Table 1 reports the performance of the Taylor Rule given by
![]() and
and
![]() . The coefficient on the unemployment gap has the reverse sign and is twice the size of the coefficient of 0.5 on the output gap in the standard Taylor rule, the latter
modification reflecting the smaller variation in the unemployment gap relative to the output gap. The first row shows the outcomes under rational expectations. (This can also be thought of as corresponding to the limiting case
. The coefficient on the unemployment gap has the reverse sign and is twice the size of the coefficient of 0.5 on the output gap in the standard Taylor rule, the latter
modification reflecting the smaller variation in the unemployment gap relative to the output gap. The first row shows the outcomes under rational expectations. (This can also be thought of as corresponding to the limiting case ![]() .) The second through fourth rows show the outcomes under learning for values of
.) The second through fourth rows show the outcomes under learning for values of ![]() ranging from 0.01 to 0.03 (recall that 0.02 is our benchmark
value).
ranging from 0.01 to 0.03 (recall that 0.02 is our benchmark
value).
The time variation in the coefficients of the forecasting model determining expectations induces greater variability and persistence in inflation and the unemployment gap. As shown in Table 1, the variability in these variables rises with the learning rate, ![]() , as does their first-order unconditional autocorrelation.
, as does their first-order unconditional autocorrelation.
In this model, the introduction of learning with constant natural rates induces nearly proportional increases in the variability of inflation and the unemployment gap. For example, in the case of
![]() , the standard deviation of inflation is 32 percent higher than under rational expectations, and that of the unemployment gap is 33 percent higher. This holds true for other
values of
, the standard deviation of inflation is 32 percent higher than under rational expectations, and that of the unemployment gap is 33 percent higher. This holds true for other
values of ![]() and stems from the fact that the model equations for inflation and the unemployment rate have identical lead-lag structures. It is worth noting that in other models, the two
variables may be affected differently by learning.
and stems from the fact that the model equations for inflation and the unemployment rate have identical lead-lag structures. It is worth noting that in other models, the two
variables may be affected differently by learning.
The rise in persistence results from the effects of shocks on the estimated parameters of the forecasting model. Consider, for example, a positive shock to inflation. Upon reestimation of the forecasting model, a portion of the shock will pass through to the intercept of the inflation forecasting equation. This raises in the next period the value of expected inflation, which boosts inflation, and so on. If by chance another positive shock arrives, the estimated coefficient on lagged inflation in the forecasting model will be elevated, further raising the persistence of inflation.
A key aspect of learning is that its effects are especially felt in episodes when particularly large shocks or a series of positively correlated shocks occurs. Indeed, the model impulse responses to i.i.d. shocks, evaluated at the steady state, are quantitatively little different from those in the model under rational expectations. However, following an unusually large shock or a sequence of shocks in the same direction, the nonlinear nature of the learning process can have profound effects. The unconditional moments thus represent an average of periods in which the behavior of the economy is approximately that described by the rational expectations equilibrium and episodes in which expectations deviate significantly from that implied by rational expectations. Such "problem" episodes contribute importantly to the deterioration in macroeconomic performance reported in the table.
7.2 Optimized Taylor-style Rules
We now consider the optimal coefficients of the Taylor-style rule under different assumptions regarding learning. As noted above, for this exercise we assume weights of 4 on unemployment gap variability and 0.25 on interest rate variability. Table 2 reports summary results. The first two columns
in the table report the optimized coefficients of the policy rules, the third through fifth columns report the standard deviations of the target variables, and the sixth column reports the associated loss, denoted by
![]() . The final column reports the loss under the policy rule optimized under rational expectations (RE), denoted by
. The final column reports the loss under the policy rule optimized under rational expectations (RE), denoted by
![]() , evaluated under the alternative specifications of learning.
, evaluated under the alternative specifications of learning.
As can be seen, the optimized Taylor-style rule under rational expectations performs very poorly when the public in fact is learning. If policy is given by the optimal policy assuming rational expectations, the loss under the benchmark value of
![]() is nearly 60 percent higher than under the optimized Taylor-style rule policy given in the third row of the table. The problem with the policy rule coefficients chosen assuming
rational expectations is the relatively weak response to inflation. This mild response to inflation allows inflation fluctuations to feed into inflation expectations and back to inflation, driving the standard deviation of inflation to 2.8 percent for
is nearly 60 percent higher than under the optimized Taylor-style rule policy given in the third row of the table. The problem with the policy rule coefficients chosen assuming
rational expectations is the relatively weak response to inflation. This mild response to inflation allows inflation fluctuations to feed into inflation expectations and back to inflation, driving the standard deviation of inflation to 2.8 percent for
![]() .
.
A particular problem with the policy optimized assuming rational expectations is that it allows the autocorrelation of inflation to rise considerably if agents engage in learning, prolonging the response of inflation expectations to any shock. For example, under the optimal policy assuming
rational expectations, the first-order autocorrelation of inflation rises from 0.71 under rational expectations to 0.90 under learning with
![]() . The efficient policy response with learning responds more aggressively to inflation relative to the optimal response under rational expectations. The stronger response to
inflation dampens inflation variability and lowers the autocorrelation of inflation. Indeed, focusing on the outcomes under the optimal policies, the resulting autocorrelation of inflation is only modestly higher under learning than it is under rational expectations. Together, these effects reduce
damaging fluctuations in the coefficients of agents' forecasting model and ensure greater economic stability.
. The efficient policy response with learning responds more aggressively to inflation relative to the optimal response under rational expectations. The stronger response to
inflation dampens inflation variability and lowers the autocorrelation of inflation. Indeed, focusing on the outcomes under the optimal policies, the resulting autocorrelation of inflation is only modestly higher under learning than it is under rational expectations. Together, these effects reduce
damaging fluctuations in the coefficients of agents' forecasting model and ensure greater economic stability.
8 Interaction of Learning and Time-varying Natural Rates
Having examined some of the policy implications of perpetual learning under the maintained assumption that natural rates are known and constant, we now turn our attention to the more general case that acknowledges the possible presence of time variation in the natural rates of interest and unemployment. In terms of the model, we add innovations to the natural rate equations, introduce the central bank's real-time updating problem and keep track of the way in which policymaker estimates of the natural rate influence the setting of policy. The learning model of the agents remains the same as considered before.
8.1 The Effects of Learning and Natural Rate Variation
Table 3 summarizes the optimal policy responses and associated economic outcomes under learning and time-varying natural rates when monetary policy follows the classic Taylor rule. The rows corresponding to "![]() " report the results where both natural rates are assumed to be constant and known by the policymaker; these results are identical to those reported in Table 1 and provide a point of reference for the results that incorporate time variation in the natural rates.
The rows corresponding to "
" report the results where both natural rates are assumed to be constant and known by the policymaker; these results are identical to those reported in Table 1 and provide a point of reference for the results that incorporate time variation in the natural rates.
The rows corresponding to "![]() " report the results for the main calibration of the innovation variances. Finally, the rows under the heading "
" report the results for the main calibration of the innovation variances. Finally, the rows under the heading "![]() " report the results associated with standard deviation of the natural rate innovations that are twice as large. The layout of the table is the same as Table 1 except that we have added columns reporting the standard deviations of
natural rate misperceptions.
" report the results associated with standard deviation of the natural rate innovations that are twice as large. The layout of the table is the same as Table 1 except that we have added columns reporting the standard deviations of
natural rate misperceptions.
Under the benchmark calibration of the innovation variances and private sector learning, the standard deviation of central bank misperceptions of the natural rate of unemployment is 0.6 percentage points, while that of the natural rate of interest is about 1.1 percentage points. With higher
innovation variances given by ![]() , the standard deviation of misperceptions of the natural rate of unemployment increases to about 1.0 percentage points, and of the natural rate of interest
rises to about 1.6 percentage points. In all cases, these misperceptions are highly persistent, with first-order autocorrelation of about 0.99 (not shown in the table).
, the standard deviation of misperceptions of the natural rate of unemployment increases to about 1.0 percentage points, and of the natural rate of interest
rises to about 1.6 percentage points. In all cases, these misperceptions are highly persistent, with first-order autocorrelation of about 0.99 (not shown in the table).
Time varying natural rates inject serially correlated errors to the processes driving inflation, the unemployment rate, and the interest rate. The coefficients of private agents' forecasting model only gradually adjust to changes in the natural rates. Moreover, policymakers themselves are unavoidably confused about the true level of natural rates and these misperceptions feed back into the coefficient estimates of the agents' forecasting model. As a result, these shocks and the feedback through policy back into expectations cause a deterioration in macroeconomic performance. For a given rate of learning, the inclusion of time varying natural rates affects the standard deviations of inflation and the unemployment gap in about the same proportion. The introduction of time-varying natural rates also raises the autocorrelations of inflation and the unemployment rate gap, as seen in the final columns of Table 3.
To assess how policymakers would wish to adjust policy under alternative assumptions regarding learning and natural rate variation, Table 4 reports the optimized Taylor-style rules under the various alternatives. The format of the table parallels that of Tables 2 and 3. For comparison,
the case of constant natural rates reported in Table 2 is provided in the rows corresponding to ![]() .
.
As can be seen in the table, for a given rate of learning, time variation in natural rates raises the optimal policy response to inflation and lowers that to the perceived unemployment gap. For example, for
![]() , the optimal coefficient on inflation rises from 0.77 to 1.08 to 1.24 for
, the optimal coefficient on inflation rises from 0.77 to 1.08 to 1.24 for ![]() and 2, respectively, and that on the unemployment gap falls from 1.20 to 0.99 to 0.60 (in absolute value). The performance of the RE-optimal Taylor-style rule, given in
the final column, is truly abysmal in the model under learning and time-varying natural rates.
and 2, respectively, and that on the unemployment gap falls from 1.20 to 0.99 to 0.60 (in absolute value). The performance of the RE-optimal Taylor-style rule, given in
the final column, is truly abysmal in the model under learning and time-varying natural rates.
Interestingly, for a given positive natural rate innovation variance, the optimal coefficients both on inflation and the unemployment gap are generally higher the greater is ![]() . With
time-varying natural rates but a low rate of learning, the optimal policy is to dampen the response to the mismeasured unemployment gap and to concentrate on inflation. In this case, expectations help stabilize the unemployment gap even with a modest direct policy response to the gap, as discussed
in Orphanides and Williams (2002). But, with a higher rate of learning, noise in the economy, including that related to time-varying natural rates, interferes with the public's understanding of the economy and expectations formation may no longer act as a stabilizing influence. In these
circumstances, policy needs to respond relatively strongly to the perceived unemployment gap, even recognizing that this may amplify policy errors owing to natural rate misperceptions. Doing so helps stabilize unemployment expectations and avoids situations where private expectations of
unemployment veer away from fundamentals.
. With
time-varying natural rates but a low rate of learning, the optimal policy is to dampen the response to the mismeasured unemployment gap and to concentrate on inflation. In this case, expectations help stabilize the unemployment gap even with a modest direct policy response to the gap, as discussed
in Orphanides and Williams (2002). But, with a higher rate of learning, noise in the economy, including that related to time-varying natural rates, interferes with the public's understanding of the economy and expectations formation may no longer act as a stabilizing influence. In these
circumstances, policy needs to respond relatively strongly to the perceived unemployment gap, even recognizing that this may amplify policy errors owing to natural rate misperceptions. Doing so helps stabilize unemployment expectations and avoids situations where private expectations of
unemployment veer away from fundamentals.
Figure 1 presents a graphical perspective on the performance of the economy corresponding to alternative rules under the various possibilities regarding the degree of time-variation in natural rates and rate of learning. In the figure, each panel shows iso-loss contours drawn from the loss
associated with policies for alternative parameters
![]() and
and
![]() , as shown in the two axes. The top left panel shows the loss associated with these policies under rational expectations and constant natural rates. The remaining panels show the
loss under rational expectations or under learning for different degrees of variation in the natural rates,
, as shown in the two axes. The top left panel shows the loss associated with these policies under rational expectations and constant natural rates. The remaining panels show the
loss under rational expectations or under learning for different degrees of variation in the natural rates,
![]() . Each panel corresponds to one of the 12 possible alternative combinations of these assumptions--comparable to the alternatives in Table 4. The minimum loss achievable with a
Taylor rule under the assumptions in each panel is also identified. Comparing these points across the different panels shows how the optimal response coefficients of the Taylor rule vary with the alternative assumptions. The figure also allows examination of the loss associated with a specific
policy that may be optimal under one set of assumptions when implemented in an economy where an alternative set of assumptions hold. This provides a useful graphical overview of the robustness characteristics of alternative rules. Of particular interest in this regard is an important asymmetry
pertaining to the robustness characteristics of the responsiveness to inflation in the Taylor rule. While the loss across alternative assumptions is extremely sensitive to changes in
. Each panel corresponds to one of the 12 possible alternative combinations of these assumptions--comparable to the alternatives in Table 4. The minimum loss achievable with a
Taylor rule under the assumptions in each panel is also identified. Comparing these points across the different panels shows how the optimal response coefficients of the Taylor rule vary with the alternative assumptions. The figure also allows examination of the loss associated with a specific
policy that may be optimal under one set of assumptions when implemented in an economy where an alternative set of assumptions hold. This provides a useful graphical overview of the robustness characteristics of alternative rules. Of particular interest in this regard is an important asymmetry
pertaining to the robustness characteristics of the responsiveness to inflation in the Taylor rule. While the loss across alternative assumptions is extremely sensitive to changes in
![]() when that is near the RE-optimal policy, a similar sensitivity is not evident for the higher values of
when that is near the RE-optimal policy, a similar sensitivity is not evident for the higher values of
![]() that are optimal under learning. This suggests that robust Taylor rule policies may need to be considerably more aggressive towards inflation compared to the RE-optimal policies.
We return to a detailed examination of the design of robust rules later on.
that are optimal under learning. This suggests that robust Taylor rule policies may need to be considerably more aggressive towards inflation compared to the RE-optimal policies.
We return to a detailed examination of the design of robust rules later on.
8.2 Optimized Difference Rule
The Taylor-style rule implicitly places a coefficients of one on the perceived natural rate of interest and
![]() on the perceived unemployment gap. As discussed in Orphanides et al (2000) and Orphanides and Williams (2002) in forward-looking models with natural rate misperceptions, an
alternative specification of a policy rule that does not respond directly to perceived natural rates may perform better than the Taylor-style rule specification. In light of that, we consider one such specification of a two-parameter policy rule in which
on the perceived unemployment gap. As discussed in Orphanides et al (2000) and Orphanides and Williams (2002) in forward-looking models with natural rate misperceptions, an
alternative specification of a policy rule that does not respond directly to perceived natural rates may perform better than the Taylor-style rule specification. In light of that, we consider one such specification of a two-parameter policy rule in which
![]() is constrained to equal one,
is constrained to equal one,
![]() is constrained to equal zero, and
is constrained to equal zero, and
![]() and
and
![]() are freely chosen to minimize the policymaker loss. We refer to policy rules with this specification as "difference" rules. Because the policy rule responds to the lagged
first-difference of the unemployment rate, we expand private agents' forecasting model to include the second lag on the unemployment rate. With this specification, the learning model is identical to the reduced form rational expectations solution of the model with constant natural rates. Table 5
summarizes the results from rules of this optimized to the 12 alternative sets of assumptions regarding the formation of expectation and variation in natural rates. The losses resulting under the optimized difference rules are reported in the sixth column under the heading
are freely chosen to minimize the policymaker loss. We refer to policy rules with this specification as "difference" rules. Because the policy rule responds to the lagged
first-difference of the unemployment rate, we expand private agents' forecasting model to include the second lag on the unemployment rate. With this specification, the learning model is identical to the reduced form rational expectations solution of the model with constant natural rates. Table 5
summarizes the results from rules of this optimized to the 12 alternative sets of assumptions regarding the formation of expectation and variation in natural rates. The losses resulting under the optimized difference rules are reported in the sixth column under the heading
![]() ; for comparison, the loss under the optimized Taylor-style rule is given in the final column of the table. Figure 2 presents contour plots of these rules under the
alternative assumptions, in a format directly comparable to that of Figure 1, except that
; for comparison, the loss under the optimized Taylor-style rule is given in the final column of the table. Figure 2 presents contour plots of these rules under the
alternative assumptions, in a format directly comparable to that of Figure 1, except that
![]() rather than
rather than
![]() is plotted on the vertical axis.
is plotted on the vertical axis.
As can be seen in the table, with time-varying natural rates, the optimized first-difference rules outperform the optimized Taylor-style rules. The more volatile the natural rates are, the greater the performance advantage of the difference rules over the Taylor-style rules. With constant natural rates, the Taylor-style rules perform better than the difference rules, reflecting the fact that when policymakers have perfect knowledge of the natural rates of interest and unemployment, it pays to use this information in the setting of policy. We conclude that in an environment of imperfect knowledge, difference rules may provide a better simple benchmark for policy than level Taylor-style rules.
As in the case of the Taylor-style rule, both the existence of private sector learning and time variation in natural rates imply stronger optimal responses to inflation relative to rational expectations. The optimal coefficient on the change in the unemployment rate, however, is relatively
insensitive to the learning rate and the degree of natural rate variation. In addition, as can be seen from the figure, in all panels the loss function appears to be relatively flat in the region around the optimal difference rule for our benchmark case with learning (![]() and
and
![]() ), suggesting that a benchmark difference rule can be selected that would be robust to uncertainty regarding the precise degree of time-variation in natural rates and expectations
formation mechanism.
), suggesting that a benchmark difference rule can be selected that would be robust to uncertainty regarding the precise degree of time-variation in natural rates and expectations
formation mechanism.
8.3 Optimized Generalized Rules
Next, we consider the performance of the generalized form of the policy rule that combines elements of both the Taylor rule and the difference rule studied above. The specification, shown in equation (9), is the same as in Orphanides and Williams (2002). Here, the interest rate depends on the
lagged interest rate, the lagged inflation rate and perceived unemployment gap, and the lagged changed in the unemployment rate. Optimal rules for each of the twelve combinations of alternative assumptions regarding learning and natural rates are shown in Table 6. In the table, which follows the
same general structure as Tables 4 and 5, the loss from the optimal generalized policy rule is denoted by
![]() ; for comparison, the loss resulting from the optimized difference rule, denoted by
; for comparison, the loss resulting from the optimized difference rule, denoted by
![]() , and the optimized Taylor-style rule, denoted by
, and the optimized Taylor-style rule, denoted by
![]() , are reported in the final two columns of the table.
, are reported in the final two columns of the table.
The optimized four-parameter rules perform significantly better than the optimized Taylor-style rules, especially in the presence of time varying natural rates, and outperforms the simple difference rule, particularly when natural rates are constant. This superior performance is related to three factors. First, rules in this class respond to more variablesinformation, in particular the lagged funds rate, and thus have an advantage over the simple Taylor rule. Second, by incorporating a near-unity response to the lagged funds rate, the optimal generalized rules nearly completely remove the perceived natural rate of interest from influencing policy. Movements in the true natural rate of interest affect the economy, but there is no direct feedback of central bank misperceptions of the natural rate of interest to the economy. Third, by responding to the change in the unemployment rate as a proxy for the unemployment gap, this specification allows for a strong response to utilization variables without relying exclusively on imperfect measures of the gap.
9 Robust Policy
A striking feature of the results from the generalized policy rule is that the optimal coefficients of the rule do not appear to be very sensitive to the rates of learning that we consider or the magnitude of variation in natural rates, as long as both elements are present. In all cases, the optimal coefficient on the lagged funds rate is near one. The coefficients on inflation and the unemployment gap vary, but are generally of approximately the same size. And the coefficient on the change in the unemployment rate is relatively similar across the different cases. These findings suggest that precise knowledge regarding the extent of imperfections in the formation of expectations or extent of natural-rate variation may not be crucial for designing a good policy rule. What is more critical is to acknowledge these imperfections in the design of the rule.
To highlight the concern for robustness, Figures 3 and 4 present a graphical summary of alternative simulations that quantify the costs of pursuing policy optimized under potentially incorrect assumptions. In Figure 3 we examine the problem arising from potentially incorrect assumptions
regarding the extent of variation in natural rates. To isolate this complication, we maintain that expectations are rational and plot the outcomes corresponding to the generalized policy rules optimized for
![]() .16 (The parameters of these
rules are shown in the first three rows of Table 6). As can be seen, the performance of the rule optimized under perfect knowledge is truly abysmal for even small degrees of time-variation, whereas, the performance of the rules optimized for
.16 (The parameters of these
rules are shown in the first three rows of Table 6). As can be seen, the performance of the rule optimized under perfect knowledge is truly abysmal for even small degrees of time-variation, whereas, the performance of the rules optimized for ![]() and
and ![]() is relatively insensitive to the true degree of variation in natural rates.
is relatively insensitive to the true degree of variation in natural rates.
Similarly, in Figure 4 we examine the problem arising from potentially incorrect assumptions regarding the formation of expectations. To illustrate this complication in isolation, we maintain ![]() and plot the outcomes corresponding to the generalized policy rules optimized for
and plot the outcomes corresponding to the generalized policy rules optimized for
![]() . (The parameters of these rules are shown in rows 1, 4 and 7 in Table 6). Here as well, we see that the performance of the rule optimized on the assumption that
expectations are rational (denoted with
. (The parameters of these rules are shown in rows 1, 4 and 7 in Table 6). Here as well, we see that the performance of the rule optimized on the assumption that
expectations are rational (denoted with ![]() here) deteriorates rapidly as the true value of
here) deteriorates rapidly as the true value of ![]() increases, and is quite poor even when
increases, and is quite poor even when ![]() is much smaller than our benchmark value of 0.02. By contrast, the performance of the rules optimized for either
is much smaller than our benchmark value of 0.02. By contrast, the performance of the rules optimized for either
![]() or
or
![]() is much less sensitive to the true value and the loss is smaller than that of the RE-optimal rule for any values of
is much less sensitive to the true value and the loss is smaller than that of the RE-optimal rule for any values of ![]() larger than 0.005.
larger than 0.005.
As the experiments described above demonstrate, failing to account for imperfect knowledge can be costly in both of the dimensions of uncertainty we consider. The challenge is to design a policy rule that would be robust to all recognized sources of uncertainty. To that end, we turn to an
examination of robustness of a benchmark policy following the methodology in Levin, Wieland, and Williams (2003). An informative benchmark rule may be identified with the optimal policy rule corresponding to an agnostic Bayesian prior when the policymaker does not know which among a range of models
is a better representation of the economy. For our benchmark, we assume that the policymaker is unsure about both the degree of structural change in the economy, as reflected in variation in natural rates, as well as about how expectations are formed, that is whether they are rational or based on
adaptive learning. Thus, we assume the policymaker has a flat prior on three possible values of
![]() ), and on four possible models for expectations, rational and learning with values
), and on four possible models for expectations, rational and learning with values
![]() . The policymaker's objective, then, is to identify the policy rule (8) that minimizes the expected loss (9) accounting for his agnostic prior over the correct
model. Note that since he is uncertain about the presence of structural change, the policymaker updates his estimates of natural rates using his updating rules (12) and (13) to set policy.
. The policymaker's objective, then, is to identify the policy rule (8) that minimizes the expected loss (9) accounting for his agnostic prior over the correct
model. Note that since he is uncertain about the presence of structural change, the policymaker updates his estimates of natural rates using his updating rules (12) and (13) to set policy.
The optimal Bayesian policy for our baseline loss (![]() and
and ![]() ) is:
) is:
The benchmark Bayesian rule performs very well across all different combinations of parameterizations of learning and natural rate fluctuations. In the parlance of Levin and Williams (2003), the model is reasonably fault tolerant once policy has accounted for some degree of learning and natural
rate variation. The relative performance of this rule is actually poorest in the cases of little or no learning and constant natural rates. But, these are states of the world that are associated with the lowest loss so from a robustness perspective, the loss in efficiency in such situations is less
worrisome than the outcomes corresponding to the larger losses that might occur under substantial variation in natural rates and learning. Remarkably, the relative performance of the benchmark rule is excellent for all values of ![]() for both
for both ![]() and
and ![]() .
.
Three of the parameters of the benchmark Bayesian rule differ noticeably from the RE-optimal policy. First, the response of policy to inflation is considerably more aggressive. Second, the rule is almost completely inertial, that is,
![]() is close to unity. Third the policy responsiveness to changes in unemployment is larger, while that to the level of the estimated unemployment gap is muted. To check the
sensitivity of these findings to the assumption of a flat prior over the twelve model specifications, we also repeated the Bayesian optimization with alternative priors. The results suggested that the optimal Baysesian policy exhibited these three differences relative to the RE-optimal policy for a
wide range of alternatives in our model. In particular these results held as long as the policymaker assigned some non-trivial probability to the possibility that knowledge is imperfect.
is close to unity. Third the policy responsiveness to changes in unemployment is larger, while that to the level of the estimated unemployment gap is muted. To check the
sensitivity of these findings to the assumption of a flat prior over the twelve model specifications, we also repeated the Bayesian optimization with alternative priors. The results suggested that the optimal Baysesian policy exhibited these three differences relative to the RE-optimal policy for a
wide range of alternatives in our model. In particular these results held as long as the policymaker assigned some non-trivial probability to the possibility that knowledge is imperfect.
An alternative way to design a robust policy is by identifying the optimal rule under a Min-Max criterion. The Min-Max policy minimizes the maximum loss for the model under the alternative assumptions under consideration which here occurs when ![]() and
and ![]() take their largest values, 0.03 and 2, respectively. The loss corresponding to this rule for the 12 alternative sets
of assumptions is reported in the column labeled
take their largest values, 0.03 and 2, respectively. The loss corresponding to this rule for the 12 alternative sets
of assumptions is reported in the column labeled
![]() in Table 8. As can be seen in the table, this rule does very well when
in Table 8. As can be seen in the table, this rule does very well when ![]() and
and ![]() are in the upper halves of their respective allowable ranges, but not as well when these parameters are both in the lower halves of the ranges. Indeed, in only two
of the twelve cases of parameter combinations that we consider does the Min-Max policy outperform the optimal Bayesian policy and even in those cases the loss is only very modestly lower.
are in the upper halves of their respective allowable ranges, but not as well when these parameters are both in the lower halves of the ranges. Indeed, in only two
of the twelve cases of parameter combinations that we consider does the Min-Max policy outperform the optimal Bayesian policy and even in those cases the loss is only very modestly lower.
The analysis above was based on a baseline specification of the loss function, but we are also interested in the sensitivity of robust-rule design to alternative weights. This is of particular interest because, as with other aspects of the monetary policy problem, it is not entirely clear what
the appropriate relative weights on the stabilization of inflation and employment should be. Recall that our baseline loss function has a unit weight on inflation and a weight ![]() on
unemployment variability (which corresponds to a unit weight on output gap variability). In Table 9 we show the parameters of optimal rules for alternative values of
on
unemployment variability (which corresponds to a unit weight on output gap variability). In Table 9 we show the parameters of optimal rules for alternative values of ![]() ranging from 0 to
16. For each specification, we compare the parameters of the RE-optimal rule with the parameters of the optimal Bayesian and Min-Max rules corresponding to the same preferences. Some key results are evident for all of the relative stabilization weights. The robust rules exhibit a high degree of
inertia and are much more responsive to inflation than the corresponding RE-optimal policies. Indeed, with the Min-Max criterion, the optimal rule is essentially a difference rule (
ranging from 0 to
16. For each specification, we compare the parameters of the RE-optimal rule with the parameters of the optimal Bayesian and Min-Max rules corresponding to the same preferences. Some key results are evident for all of the relative stabilization weights. The robust rules exhibit a high degree of
inertia and are much more responsive to inflation than the corresponding RE-optimal policies. Indeed, with the Min-Max criterion, the optimal rule is essentially a difference rule (
![]() ) and the robust response to inflation is about 1 regardless of the weight in the loss functions. Relative to the RE-optimal policies, the robust rules are much less responsive
to the unemployment gap and more responsive to changes in unemployment, but these parameters vary with the relative weight in the loss function.
) and the robust response to inflation is about 1 regardless of the weight in the loss functions. Relative to the RE-optimal policies, the robust rules are much less responsive
to the unemployment gap and more responsive to changes in unemployment, but these parameters vary with the relative weight in the loss function.
Finally, we wish to examine the robustness of simpler policies than the generalized rule which has four parameters, as simpler rules, for example rules that only have one or two argument, may be more useful than their more complicated counterparts in policy discussions. To that end, we compute
the optimal Bayesian and Min-Max level and difference rules each of which has only two parameters. We report results for the baseline preferences we consider, ![]() and
and ![]() . For the Bayesian rules, we employ the same flat prior over the alternative models of learning and natural rates as before. The resulting optimal Bayesian rules are:
. For the Bayesian rules, we employ the same flat prior over the alternative models of learning and natural rates as before. The resulting optimal Bayesian rules are:
nally, we consider the robustness of the difference rule optimized to our benchmark model. Table 8 reports the results. The final column reports the losses under the benchmark four-parameter rule reported in table 7. The benchmark difference rule performs nearly as well as the benchmark
generalized rule in the case of ![]() , but performs significantly worse if natural rates are constant and known by the central bank.
, but performs significantly worse if natural rates are constant and known by the central bank.
10 Conclusion
In an environment of imperfect knowledge regarding the potential for structural change in the economy and the formation of expectations, the scope for stabilization of the real side of our economy may be significantly reduced relative to an economy under rational expectations with perfect knowledge. Policies that appear to be optimal under perfect knowledge can perform very poorly if they are implemented in such an environment. In our model economy, the presence of imperfect knowledge tends to raise the persistence of inflation, partly as a result of the persistent policy errors due to misperceptions of the natural rates and partly as a result of the learning process agents may rely upon to form expectations. This leads to a deterioration in economic performance, especially with regard to a policymaker's price stability objective. Policymakers who recognize the presence of these imperfections in the economy can adjust their policies and protect against this deterioration in economic outcomes.
Efficient policies that take account of private learning and misperceptions of natural rates appear to have two important characteristics. First, and arguably most important, these policies call for more aggressive responses to inflation that would be optimal under perfect knowledge. This finding tends to confirm the conventional wisdom that associates good central bank policy practice with policies that may appear to stress the role of maintaining price stability more than might appear warranted in simple models of the economy under perfect knowledge. Second, efficient policies exhibit a high degree of inertia in the setting of the interest rate. Indeed, simple difference rules which circumvent the need to rely on uncertain estimates of natural rates in setting policy, appear to be robust to potential misspecification of private sector learning and the magnitude of variation in natural rates. Importantly, it seems possible to design a simple policy rule that can deliver reasonably good macroeconomic performance even in an environment of considerable uncertainty regarding expectations formation and natural rate uncertainty.
Bullard, James and Stefano Eusepi (2005), "Did the Great Inflation Occur Despite Policymaker Commitment to a Taylor Rule?" Review of Economic Dynamics, 8(2), 324-59.
Clark, Todd, and Sharon Kozicki (2005), "Estimating Equilibrium Interest Rates in Real Time," North American Journal of Economics and Finance, 16(3), 395-413.
Cogley, Timothy and Sargent, Thomas (2001), "Evolving Post-World War II U.S. Inflation Dynamics," in NBER Macroeconomics Annual.
Collard, Fabrice and Harris Dellas (2004), "The Great Inflation of the 1970s," European Central Bank Working Paper 336, April.
Congressional Budget Office (2001), "CBO's Method for Estimating Potential Output: An Update," Washington, DC: Government Printing Office (August).
Congressional Budget Office (2002), The Budget and Economic Outlook: An Update. Washington DC: Government Printing Office (August).
Croushore, Dean (1993), "Introducing: The Survey of Professional Forecasters," Federal Reserve Bank of Philadelphia Business Review, November/December, 3-13.
Croushore, Dean and Tom Stark (2001), "A Real-Time Data Set for Macroeconomists," Journal of Econometrics 105, 111-130, November.
Cukierman, Alex and Francesco Lippi (2005), "Endogenous Monetary Policy with Unobserved Potential Output," Journal of Economic Dynamics and Control, 29(11), pp. 1951-83.
Evans, George and Honkapohja, Seppo (2001), Learning and Expectations in Macroeconomics. Princeton: Princeton University Press.
Friedman, Milton (1968), "The Role of Monetary Policy," American Economic Review, 58(1), 1-17.
Gaspar, Vitor and Smets, Frank (2002), "Monetary Policy, Price Stability and Output Gap Stabilisation," International Finance, 5(2), Summer, 193-211.
Gaspar, Vitor, Frank Smets, and David Vestin (2006). "Adaptive Learning, Persistence, and Optimal Monetary Policy" ECB Working paper, June.
Giannoni, Marc P. and Michael Woodford (2005). "Optimal Inflation Targeting Rules," in The Inflation Targeting Debate, Ben Bernanke and Michael Woodford (eds.), Chicago: University of Chicago Press.
Laubach, Thomas and John C. Williams (2003). "Measuring the Natural Rate of Interest," Review of Economics and Statistics, 85(4) 1063-1070.
Leitemo, Kai, and Ingunn Lonning (2006). "Simple Monetary Policymaking without the Output Gap." Journal of Money, Credit, and Banking 38(6), p. 1619-1640.
Levin, Andrew, Volker Wieland and John Williams (1999), "Robustness of Simple Monetary Policy Rules under Model Uncertainty," in Monetary Policy Rules, John B. Taylor (ed.), Chicago: University of Chicago.
Levin, Andrew, Volker Wieland and John Williams (2003), "The Performance of Forecast-Based Policy Rules under Model Uncertainty," American Economic Review, 93(3), 622-645, June.
McCallum, Bennett T. (1988). "Robustness Properties of a Rule for Monetary Policy." Carnegie-Rochester Conference Series on Public Policy, 29, Autumn, 173-203.
McCallum, Bennett T. (2001). "Should Monetary Policy Respond Strongly to Output Gaps?" American Economic Association Papers and Proceedings, 91(2), May, 258-262.
Okun, Arthur (1962), "Potential Output: Its Measurement and Significance," in American Statistical Association 1962 Proceedings of the Business and Economic Section, Washington, D.C.: American Statistical Association.
Orphanides, Athanasios (2003a), "Monetary Policy Evaluation With Noisy Information," Journal of Monetary Economics, 50(3), 605-631, April.
Orphanides, Athanasios (2003b), "The Quest for Prosperity Without Inflation," Journal of Monetary Economics, 50(3), 633-663, April.
Orphanides, Athanasios (2003c), "Historical Monetary Policy Analysis and the Taylor Rule," Journal of Monetary Economics, 50(5), 983-1022, July.
Orphanides, Athanasios, Richard Porter, David Reifschneider, Robert Tetlow and Frederico Finan (2000), "Errors in the Measurement of the Output Gap and the Design of Monetary Policy," Journal of Economics and Business, 52(1/2), 117-141, January/April.
Orphanides, Athanasios and Simon van Norden (2002), "The Unreliability of Output Gap Estimates in Real Time," Review of Economics and Statistics, 84(4), 569-583, November.
Orphanides, Athanasios and John C. Williams (2002), "Robust Monetary Policy Rules with Unknown Natural Rates", Brookings Papers on Economic Activity, 2:2002, 63-118.
Orphanides, Athanasios and John C. Williams (2005a), "Inflation scares and forecast-based monetary policy", Review of Economic Dynamics, 8(2), 498-527, April.
Orphanides, Athanasios and John C. Williams (2005b), "The Decline of Activist Stabilization Policy: Natural Rate Misperceptions, Learning, and Expectations" Journal of Economic Dynamics and Control. 29(11), 1927-1950, November.
Orphanides, Athanasios and John C. Williams (2005c) "Imperfect Knowledge, Inflation Expectations and Monetary Policy," in The Inflation Targeting Debate, Ben Bernanke and Michael Woodford (eds.), Chicago: University of Chicago Press.
Orphanides, Athanasios and John C. Williams (2007) "Inflation Targeting Under Imperfect Knowledge," in Monetary Policy Under Inflation Targeting, Frederic Mishkin and Klaus Schmidt-Hebbel (eds.), Santiago: Central Bank of Chile.
Phillips, A. W. (1954), "Stabilisation Policy in a Closed Economy," Economic Journal, 290-323, June.
Rotemberg, Julio J. and Michael Woodford (1999), "Interest Rate Rules in an Estimated Sticky Price Model," in Monetary Policy Rules, John B. Taylor (ed.), Chicago: University of Chicago Press, 57-119.
Sargent, Thomas J. (1999), The Conquest of American Inflation, Princeton: Princeton University Press.
Sheridan, Niamh (2003), "Forming Inflation Expectations," Johns Hopkins University, mimeo, April.
Smets, Frank (2003), "Maintaining Price Stability: How Long Is the Medium Term?" Journal of Monetary Economics, September 2003, 50(6), 1293-1309.
Staiger, Douglas, James H. Stock, and Mark W. Watson (1997), "How Precise are Estimates of the Natural rate of Unemployment?" in: Reducing Inflation: Motivation and Strategy, ed. by Christina D. Romer and David H. Romer, Chicago: University of Chicago Press. 195-246.
Taylor, John B. (1993), "Discretion versus Policy Rules in Practice," Carnegie-Rochester Conference Series on Public Policy, 39, December, 195-214.
Taylor, John B., ed., (1999a), Monetary Policy Rules, Chicago: University of Chicago.
Taylor, John B. (1999b), "The Robustness and Efficiency of Monetary Policy Rules as Guidelines for Interest Rate Setting by the European Central Bank," Journal of Monetary Economics, 43(3), 655-679.
van Norden, Simon (2002), "Filtering for Current Analysis" Bank of Canada Working Paper 2002-28, October.
Walsh, Carl (2003), "Implications of a Changing Economic Structure for the Strategy of Monetary Policy," in Monetary Policy and Uncertainty: Adapting to a Changing Economy, Federal Reserve Bank of Kansas City.
Williams, John C. (2003) "Simple Rules for Monetary Policy," Federal Reserve Bank of San Francisco Review, 1-12.
Williams, John C. (2005). "Robust Estimation and Monetary Policy with Unobserved Structural Change." In Models and Monetary Policy: Research in the Tradition of Dale Henderson, Richard Porter and Peter Tinsley, edited by Jon Faust, Athanasios Orphanides and David L. Reifschneider. Washington: Board of Governors of the Federal Reserve System.
Woodford, Michael (2003), Interest and Prices: Foundations of a Theory of Monetary Policy, Princeton University Press.
Zarnowitz, Victor and Phillip A. Braun (1993), "Twenty-two Years of the NBER-ASA Quarterly Economic Outlook Surveys: Aspects and Comparisons of Forecasting Performance," in Business Cycles, Indicators, and Forecasting, James H. Stock and Mark W. Watson (eds.), Chicago: University of Chicago Press, 11-84.
| Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
First-order Autocorrelation: |
First-order Autocorrelation: |
First-order Autocorrelation: |
|
|---|---|---|---|---|---|---|
| RE | 1.48 | 0.54 | 1.96 | 0.64 | 0.77 | 0.6 |
| 0.01 | 1.68 | 0.63 | 1.97 | 0.72 | 0.83 | 0.67 |
| 0.02 | 1.95 | 0.72 | 1.99 | 0.79 | 0.86 | 0.75 |
| 0.03 | 2.13 | 0.79 | 2.03 | 0.81 | 0.88 | 0.78 |
Notes: ![]()
| Policy Rule Coefficient: |
Policy Rule Coefficient: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
First-order Autocorrelation: |
First-order Autocorrelation: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|---|---|---|---|
| RE | 0.16 | -1.38 | 1.6 | 0.47 | 1.53 | 0.71 | 0.75 | 4 | 4 |
| 0.01 | 0.53 | -1.21 | 1.69 | 0.61 | 2.02 | 0.73 | 0.82 | 5.4 | 7 |
| 0.02 | 0.77 | -1.2 | 1.73 | 0.72 | 2.34 | 0.74 | 0.85 | 6.4 | 10.3 |
| 0.03 | 0.89 | -1.37 | 1.81 | 0.77 | 2.53 | 0.75 | 0.86 | 7.3 | 12.4 |
Notes: ![]()
| Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
First-order Autocorrelation: |
First-order Autocorrelation: |
First-order Autocorrelation: |
|
|---|---|---|---|---|---|---|---|---|
| RE: 0 | 1.48 | 0.54 | 1.96 | -- | -- | 0.64 | 0.77 | 0.6 |
| RE: 1 | 1.91 | 0.56 | 1.96 | 0.42 | 0.5 | 0.78 | 0.78 | 0.74 |
| RE: 2 | 2.82 | 0.6 | 1.99 | 0.83 | 1 | 0.89 | 0.78 | 0.87 |
| 1.68 | 0.63 | 1.97 | -- | -- | 0.72 | 0.83 | 0.67 | |
| 2.13 | 0.84 | 1.99 | 0.6 | 1.18 | 0.82 | 0.9 | 0.82 | |
| 2.87 | 1.16 | 2.02 | 1.06 | 1.73 | 0.9 | 0.94 | 0.89 | |
| 1.95 | 0.72 | 1.99 | -- | -- | 0.79 | 0.86 | 0.75 | |
| 2.53 | 0.92 | 2.03 | 0.6 | 0.96 | 0.87 | 0.91 | 0.85 | |
| 3.46 | 1.22 | 2.1 | 1.09 | 1.56 | 0.92 | 0.94 | 0.92 | |
| 2.13 | 0.79 | 2.03 | -- | -- | 0.81 | 0.88 | 0.78 | |
| 2.78 | 0.98 | 2.05 | 0.61 | 0.95 | 0.89 | 0.92 | 0.87 | |
| 3.82 | 1.27 | 2.17 | 1.09 | 1.46 | 0.93 | 0.94 | 0.92 |
Notes: ![]()
| Policy Coefficient: |
Policy Coefficient: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|---|---|
| RE: 0 | 0.16 | -1.38 | 1.6 | 0.47 | 1.53 | 4 | 4 |
| RE: 1 | 0.72 | -0.65 | 1.62 | 0.6 | 2.24 | 5.3 | 19.9 |
| RE: 2 | 1.02 | -0.39 | 1.72 | 0.68 | 2.64 | 6.5 | 67.6 |
| 0.53 | -1.21 | 1.69 | 0.61 | 2.02 | 5.4 | 7 | |
| 0.74 | -0.57 | 1.8 | 0.9 | 2.29 | 7.8 | 24.7 | |
| 1.05 | -0.31 | 1.88 | 1.23 | 2.72 | 11.4 | 199.8 | |
| 0.77 | -1.2 | 1.73 | 0.72 | 2.34 | 6.4 | 10.3 | |
| 1.08 | -0.99 | 1.81 | 0.94 | 2.76 | 8.7 | 44.8 | |
| 1.24 | -0.6 | 1.96 | 1.24 | 2.98 | 12.2 | 195.3 | |
| 0.89 | -1.37 | 1.81 | 0.77 | 2.53 | 7.3 | 12.4 | |
| 1.2 | -1.03 | 1.86 | 0.98 | 2.96 | 9.5 | 57.2 | |
| 1.43 | -0.87 | 2.02 | 1.23 | 3.28 | 12.9 | 260.6 |
Notes: ![]()
| Policy Coefficient: |
Policy Coefficient: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|---|---|
| RE: 0 | 0.31 | -3.76 | 1.75 | 0.58 | 1.34 | 4.9 | 4 |
| RE: 1 | 0.39 | -3.72 | 1.74 | 0.63 | 1.37 | 5.1 | 5.3 |
| RE: 2 | 0.52 | -3.63 | 1.74 | 0.72 | 1.43 | 5.6 | 6.5 |
| 0.49 | -4.04 | 1.79 | 0.72 | 1.54 | 5.9 | 5.4 | |
| 0.54 | -3.94 | 1.78 | 0.87 | 1.54 | 6.8 | 7.8 | |
| 0.68 | -3.82 | 1.78 | 1.15 | 1.6 | 9.1 | 11.4 | |
| 0.57 | -4.08 | 1.84 | 0.82 | 1.61 | 6.7 | 6.4 | |
| 0.65 | -4.2 | 1.83 | 0.94 | 1.7 | 7.6 | 8.7 | |
| 0.82 | -4.15 | 1.82 | 1.19 | 1.8 | 9.7 | 12.2 | |
| 0.76 | -4.51 | 1.85 | 0.92 | 1.87 | 7.7 | 7.3 | |
| 0.85 | -4.55 | 1.83 | 1.02 | 1.95 | 8.5 | 9.5 | |
| 0.95 | -4.6 | 1.85 | 1.23 | 2.04 | 10.5 | 12.9 |
Notes: ![]()
| Policy Coefficient: |
Policy Coefficient: |
Policy Coefficient: |
Policy Coefficient: |
Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Loss: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|---|---|---|---|---|
| RE: 0 | 0.76 | 0.18 | -0.97 | -0.43 | 1.51 | 0.47 | 0.77 | 3.3 | 4.9 | 4 |
| RE: 1 | 0.92 | 0.45 | -0.66 | -1.72 | 1.58 | 0.61 | 1.08 | 4.2 | 5.1 | 5.3 |
| RE: 2 | 0.92 | 0.56 | -0.41 | -2.28 | 1.64 | 0.71 | 1.27 | 5.1 | 5.6 | 6.5 |
| 0.85 | 0.42 | -1.01 | -1.23 | 1.6 | 0.61 | 1.12 | 4.4 | 5.9 | 5.4 | |
| 0.95 | 0.52 | -0.74 | -1.89 | 1.6 | 0.83 | 1.21 | 5.7 | 6.8 | 7.8 | |
| 1 | 0.68 | -0.6 | -2.5 | 1.66 | 1.13 | 1.41 | 8.3 | 9.1 | 11.4 | |
| 0.87 | 0.61 | -1.09 | -1.78 | 1.64 | 0.71 | 1.43 | 5.2 | 6.7 | 6.4 | |
| 0.95 | 0.66 | -0.8 | -2.43 | 1.66 | 0.89 | 1.48 | 6.5 | 7.6 | 8.7 | |
| 1 | 0.83 | -0.62 | -2.93 | 1.7 | 1.16 | 1.66 | 9 | 9.7 | 12.2 | |
| 0.93 | 0.63 | -1.13 | -2.17 | 1.78 | 0.76 | 1.53 | 6.1 | 7.7 | 7.3 | |
| 0.99 | 0.84 | -0.94 | -3.01 | 1.71 | 0.95 | 1.8 | 7.3 | 8.5 | 9.5 | |
| 1 | 1 | -0.69 | -3.34 | 1.73 | 1.2 | 1.95 | 9.7 | 10.5 | 12.9 |
Notes: ![]()
| Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|
| RE: 0 | 1.43 | 0.62 | 1.48 | 4.1 | 3.3 |
| RE: 1 | 1.51 | 0.64 | 1.48 | 4.4 | 4.2 |
| RE: 2 | 1.71 | 0.67 | 1.49 | 5.3 | 5.1 |
| 1.51 | 0.7 | 1.5 | 4.8 | 4.4 | |
| 1.55 | 0.85 | 1.5 | 5.8 | 5.7 | |
| 1.7 | 1.12 | 1.5 | 8.4 | 8.3 | |
| 1.59 | 0.77 | 1.51 | 5.4 | 5.2 | |
| 1.64 | 0.9 | 1.51 | 6.5 | 6.5 | |
| 1.84 | 1.14 | 1.53 | 9.2 | 9 | |
| 1.71 | 0.84 | 1.55 | 6.3 | 6.1 | |
| 1.77 | 0.96 | 1.55 | 7.4 | 7.3 | |
| 1.98 | 1.18 | 1.57 | 10.1 | 9.7 |
Notes: Each row shows the performance of the economy under alternative assumptions regarding the true mechanism for the formation of expectations (RE and learning with
![]() ) and variation in natural rates (
) and variation in natural rates (
![]() ) when the policymaker follows the optimal Bayesian policy:
) when the policymaker follows the optimal Bayesian policy:
![]() The parameters in this rule minimize the expected loss associated with the alternative assumptions shown under a uniform prior.
The parameters in this rule minimize the expected loss associated with the alternative assumptions shown under a uniform prior.
| Standard Deviation: |
Standard Deviation: |
Standard Deviation: |
Loss: |
Loss: |
Loss: |
|
|---|---|---|---|---|---|---|
| RE: 0 | 1.43 | 0.7 | 1.91 | 4.9 | 4.1 | 3.3 |
| RE: 1 | 1.46 | 0.71 | 1.91 | 5 | 4.4 | 4.2 |
| RE: 2 | 1.55 | 0.74 | 1.91 | 5.5 | 5.3 | 5.1 |
| 1.48 | 0.77 | 1.93 | 5.5 | 4.8 | 4.4 | |
| 1.49 | 0.9 | 1.92 | 6.4 | 5.8 | 5.7 | |
| 1.56 | 1.14 | 1.92 | 8.6 | 8.4 | 8.3 | |
| 1.54 | 0.84 | 1.93 | 6.1 | 5.4 | 5.2 | |
| 1.55 | 0.95 | 1.93 | 6.9 | 6.5 | 6.5 | |
| 1.64 | 1.16 | 1.93 | 9 | 9.2 | 9 | |
| 1.6 | 0.91 | 1.95 | 6.8 | 6.3 | 6.1 | |
| 1.64 | 1.01 | 1.95 | 7.7 | 7.4 | 7.3 | |
| 1.73 | 1.2 | 1.95 | 9.7 | 10.1 | 9.7 |
Notes: Each row shows the performance of the economy under alternative assumptions regarding the true mechanism for the formation of expectations (RE and learning with
![]() ) and variation in natural rates (
) and variation in natural rates (
![]() ) when the policymaker follows the Min-Max generalized policy:
) when the policymaker follows the Min-Max generalized policy:
![]() The parameters in this rule minimize the maximum loss expected under any of the alternative assumptions regarding the formation of expectations and variation in natural rates considered.
The parameters in this rule minimize the maximum loss expected under any of the alternative assumptions regarding the formation of expectations and variation in natural rates considered.
| Parameter | Policy Rule Coefficient: |
Policy Rule Coefficient: |
Policy Rule Coefficient: |
Policy Rule Coefficient: |
|---|---|---|---|---|
| lambda=0: RE-optimal | 0.81 | 0.32 | -0.60 | -0.31 |
| lambda=0: Bayesian | 0.95 | 0.79 | -0.55 | -1.06 |
| lambda=0: Min-Max | 0.99 | 1.03 | -0.46 | -1.59 |
| lambda=0.25:�RE-optimal | 0.80 | 0.30 | -0.63 | -0.23 |
| lambda=0.25:�Bayesian | 0.94 | 0.77 | -0.56 | -1.16 |
| lambda=0.25:�Min-Max | 1.00 | 1.05 | -0.55 | -1.76 |
| lambda=1.00:�RE-optimal | 0.79 | 0.26 | -0.72 | -0.03 |
| lambda=1.00:�Bayesian | 0.92 | 0.75 | -0.60 | -1.58 |
| lambda=1.00:�Min-Max | 1.00 | 1.04 | -0.57 | -2.34 |
| lambda=4.00:�RE-optimal | 0.76 | 0.18 | -0.97 | -0.43 |
| lambda=4.00:�Bayesian | 0.96 | 0.69 | -0.75 | -2.57 |
| lambda=4.00:�Min-Max | 1.00 | 1.00 | -0.69 | -3.34 |
| lambda=16.00:�RE-optimal | 0.73 | 0.11 | -1.46 | -1.16 |
| lambda=16.00:�Bayesian | 1.00 | 0.60 | -0.84 | -4.02 |
| lambda=16.00:�Min-Max | 1.00 | 0.99 | -0.97 | -5.02 |
Notes: ![]()
| Min-Max: |
Min-Max: |
Bayesian: |
Bayesian: |
|
|---|---|---|---|---|
| RE: 0 | 6.1 | 5.7 | 5.3 | 5.2 |
| RE: 1 | 6.3 | 5.8 | 5.6 | 5.3 |
| RE: 2 | 7 | 6 | 6.6 | 5.7 |
| 6.8 | 6.4 | 6.1 | 6 | |
| 8.5 | 7.2 | 8 | 6.8 | |
| 11.8 | 9.3 | 11.6 | 9.1 | |
| 7.5 | 7.1 | 6.9 | 6.8 | |
| 9.1 | 7.8 | 8.7 | 7.6 | |
| 12.3 | 9.8 | 12.4 | 9.9 | |
| 8.2 | 7.9 | 7.6 | 7.8 | |
| 9.8 | 8.6 | 9.5 | 8.5 | |
| 12.9 | 10.5 | 13.3 | 10.7 |
Notes: Each row compares the loss incurred under alternative assumptions regarding the true mechanism for the formation of expectations and variation in natural rates for two-parameter optimal Bayesian and Min-Max policy rules. The corresponding Min-Max rules for the level,
![]() , and difference specifications,
, and difference specifications,
![]() , are:
, are:
![]()
![]() The corresponding Bayesian rules for the level,
The corresponding Bayesian rules for the level,
![]() , and difference specifications,
, and difference specifications,
![]() , are:
, are:
![]()
![]()
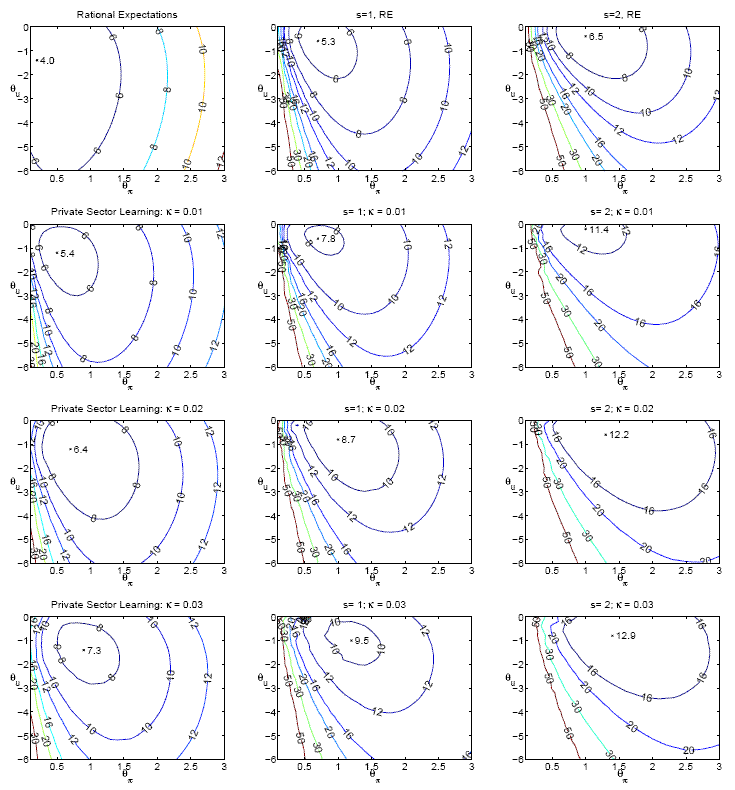
Notes: Each panel shows contours of the loss associated with the Taylor-style policy rule
![]() for the assumptions regarding expectations formation and time-variation of
the natural rates shown.
for the assumptions regarding expectations formation and time-variation of
the natural rates shown.
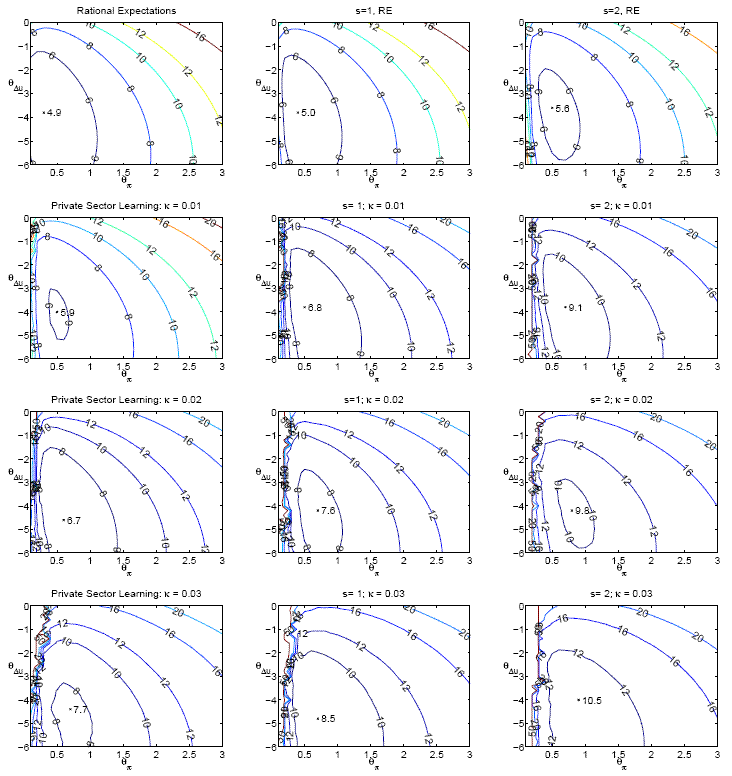
Notes: Each panel shows contours of the loss associated with the difference rule
![]() for the assumptions regarding expectations formation and time-variation of the natural rates
shown.
for the assumptions regarding expectations formation and time-variation of the natural rates
shown.
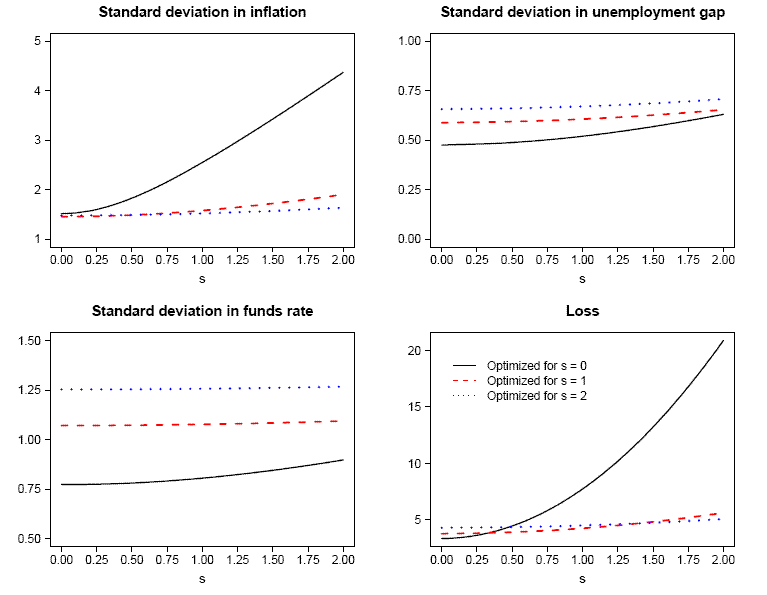
Notes: In each panel, each line plots the asymptotic standard deviation/expected loss that obtain with a fixed policy rule for a range of natural-rate variation, ![]() , shown in the horizontal
axis. In all simulations expectations are assumed to be rational. The three fixed policies represent the generalized rule optimized for
, shown in the horizontal
axis. In all simulations expectations are assumed to be rational. The three fixed policies represent the generalized rule optimized for
![]() under rational expectations.
under rational expectations.
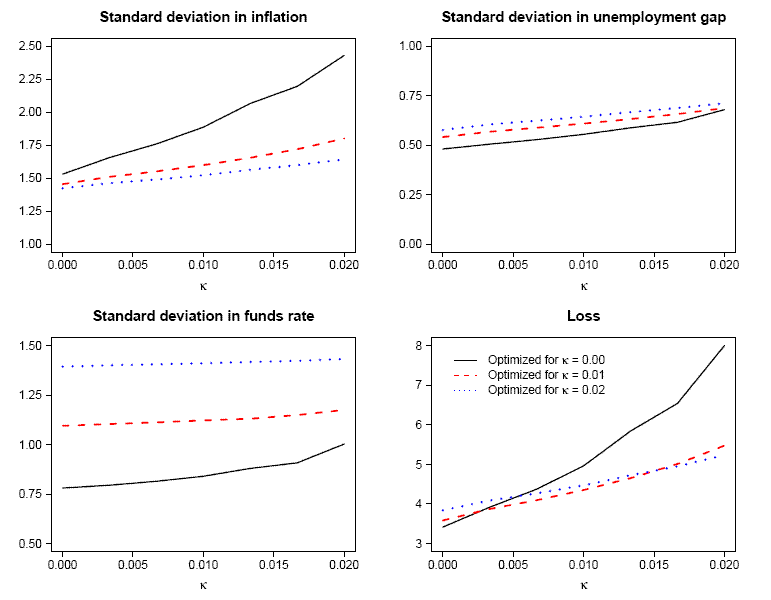
Notes: In each panel, each line plots the asymptotic standard deviation/expected loss that obtain with a fixed policy rule under alternative learning rates, ![]() , shown in the horizontal
axis. In all simulations
, shown in the horizontal
axis. In all simulations ![]() . The three fixed policies represent the generalized rule optimized for
. The three fixed policies represent the generalized rule optimized for
![]() when
when ![]() .
.