
Everything all the time?
Entry and Exit in U.S. Import Varieties*
Abstract:
1 Introduction
International trade has expanded dramatically during the last half century, doubling every seven years. This wave of globalization has been driven by trade agreements, falling transportation costs, and increased specialization. A phenomenon of such sheer magnitude is surely worth dissecting. One of the questions to receive the most attention is how much newly-traded goods have contributed to overall trade growth--what is commonly referred as the extensive margin of trade. The attention is not unwarranted. First, many of the benefits from increased trade integration proposed in the literature operate through newly-traded goods: by increasing the varieties available to consumers, through pro-competitive effects, and by improving aggregate productivity.1 Second, the extensive margin may have its own idiosyncratic response to price or economic fluctuations, and possibly adjust at a distinct pace as well.2 This, in turn, has important implications for the evaluation and design of trade policies.
In this paper we propose a new theory of the extensive margin of trade. We introduce a novel demand system for imports, building on a standard random-utility, discrete choice model of product differentiation.3 Each country is assumed to supply a differentiated variety for each good or product. Crucially, there are only a finite number of independent purchase decisions or transactions each period. As a result, the demand for any particular commodity is a random variable. Whereas traditional demand systems predict market shares, our model yields instead the probability that a purchase of a given good is supplied by any given country. As long as the number of purchase decisions is finite, there is a positive probability that a country variety for a given good is not traded--the exact probability being determined by the price vector and the structural parameters. In other words, even though all varieties for all goods are available in all periods, not all of them are purchased in every period. Our model collapses to the standard CES demand when the number of purchase decisions per period tends to infinity.4 By the law of large numbers, probabilities converge to market shares and all available commodities are traded in all periods.
The model yields a rich set of predictions regarding the extensive margin, both in the cross-section and across time. We obtain simple expressions for the expected number of traded commodities per period along the the dimension of choice, say, countries or product classifications. Across time, we derive formulas for the net change in newly-traded commodities, as well as the gross amounts of entering and disappearing varieties, their survival probabilities and the associated hazard rates. Our model also has implications for the intensive margin, which allow us to derive, among other things, the contribution of newly-traded goods weighted by value and how sales per variety change conditional on survival.
We evaluate the model's quantitative performance with data on U.S. imports at the HS10 product level from 1990 through 2001. To this end we propose a parsimonious calibration of the model's structural parameters. We assume a Cobb-Douglas preference structure across products, which we use to fit the average expenditures share across goods over the period. We assume the relative prices across varieties, for each good, are constant over time. This allows us to capture the relative prices through country fixed-effects or a standard gravity regression.5 Jointly with the number of purchase decisions, the country fixed-effects are used to match the average number of traded products per country. We also take advantage of the underlying relationship between the dispersion parameter of the random-utility terms in the discrete choice model and the elasticity of substitution to use the estimates at the HS10 product level provided by Broda and Weinstein (2006). The growth rate of purchase decisions for foreign varieties is set to reproduce import penetration from 1990 to 2001.
The model's predictions line up with the data with astounding precision. We start by checking whether our model reproduces the cross-section distribution of varieties per product in a given year. It does, and it actually also traces very well the distribution conditional on the product expenditure shares or country size. These results are perhaps not too surprising since they are closely tied to our calibration. However, we also find in the data that varieties per product decrease with the elasticity of substitution--an important prediction of the model.
Our model performs excellently in matching time-series moments. The average growth rate of the number of trade country-good varieties, per year, is 2.18 percent in the model versus 2.23 percent in the data. The extensive margin contributes 0.3 percentage points to trade growth--both in the model and data. The model also approximates very well the gross entry and exit of varieties, both by count and weighted by value. We also find that entry and exit rates vary with good and country size as they do in the data. Finally we perform a survival analysis for the set of traded commodities in 1990. Once again the model predictions match the data very well. The model also reproduces how average sales per variety change with survival, i.e., years continuously being traded.
What is behind our model's ability to reproduce the data? At the core the model posits that trade, for very detailed product classifications, is a rare event that should not be expected to be observed regularly at the annual frequency. This naturally reconciles, at once, two immediate observations in the data: there is a large fraction of varieties that are not traded yet the entry and exit rates of commodities are very high. The model's quantitative performance, though, requires that in addition we get the distribution of the underlying probabilities right. For example, the amount of churning expected for a given variety is maximized when the probability of observing such commodity is exactly one half, and decreases symmetrically as the probability increases or decreases from there. The aggregate level of churning depends then crucially on where the mass of the distribution of probabilities lies.
We explore our model implications with two exercises. First we take a closer look at Mexico's experience in the aftermath of the North American Free Trade Agreement (NAFTA). Because our baseline calibration features constant relative prices, the model misses the rapid expansion of U.S. imports from Mexico on both the extensive and intensive margin. Once we account for the tariff reductions, the model predicted response on the extensive margin lies side by side with the data. The reason is quite prosaic: as Mexican goods get cheaper, they get purchased more often. Thus a larger fraction of them will be observed in the course of a year. We see this result as suggestive that the model can also perform well in response to price changes.
Finally, we revisit the computation of variety-adjusted import price indexes in Feenstra (1994) and Broda and Weinstein (2006). We find that when purchase decisions grow over time there is the potential for a substantial downward bias in the import price index--and thus to overstate the welfare gains associated with new varieties. There are, obviously, no welfare gains in our model: all varieties are available at all times.
There is by now a very large literature on the extensive margin in trade that we do not hope or attempt to review here. Most trade models posit that economies of scale in exporting, at the level of the firm, are behind the extensive margin.6 Clearly the extensive margin does not operate through economies of scale in our paper. We will consequently focus here our review on the few alternatives in the literature.
Elsewhere we have developed an atheoretical benchmark designed to capture the sparsity that is commonplace in trade data.7 The balls-and-bins model matches several stylized facts regarding the cross-section of exports across goods, countries, and firms--suggesting there was little scope to identify the relevant theory of the extensive margin. While our model shares a similar underlying probabilistic structure, it is tied down to structural parameters allowing us, for example, to contrast the model's implications for goods with different elasticities. We also emphasize that Armenter and Koren (2010) limited the analysis of sparsity to the cross-section while our model's performance is especially accurate regarding dynamic facts--e.g., exit, entry, survival.
Eaton et al. (2012) amend a standard heterogeneous-firm model to allow for a finite number of firms to export and show how it can account for zeros in bilateral trade. As in our paper, removing the law of large numbers creates the desired sparsity in the data. There are two important differences. First, we argue for granularity on the demand side rather than on the supply side. This mainly reflects the difference in focus--firm selection in exporting or import composition--and we thus view both approaches as complementary. The second second difference is more conceptual in nature. We posit a finite number of purchase decisions per period, which allows to explore the dynamic implications of our model. Eaton et al. (2012) instead view the population of firms as a single realization.
Some other work does not break the law of large numbers yet deviate from standard models in order to capture some of the sparsity in the trade data. Bekes and Murakozy (2012) tackle the phenomenon of temporary trade, that is, short trading spells at the firm level. This observation is closely related to our measures of churning. Kropf and Saure (2011) introduce a fixed cost per trade shipment. Firms choose optimally to ship large amounts infrequently, balancing shipment and storage costs. It is thus possible then that an exporting firm is not observed to trade at an annual frequency. That said, such a model is not likely to be able to explain the extensive margin from the import side.
There is also substantial work at measuring the extensive margin. Kehoe and Ruhl (2012), Hummels and Klenow (2005), and Bils and Klenow (2001). Feenstra (1994) and Broda and Weinstein (2006) go one step further and provide import price indexes that adjust for changes in the traded varieties. These, in turn, are used to compute welfare gains.
The paper is organized as follows. Section 2 describes our model and derives the main formulas for the extensive and intensive margin. We turn to the data description and model calibration in Section 3. Our results regarding the cross-section and time-series are presented in Section 4 and 5, respectively. NAFTA is the object of attention of Section 6; import price indexes that of Section 7. The last Section previsibly concludes.
2 Model
Our demand system is based on the discrete choice model detailed in Anderson et al. (1992). The commodity space is as follows. Each country
![]() supplies a differentiated variety of every product (or good)
supplies a differentiated variety of every product (or good)
![]() . There is also a non-traded numeraire good, bringing the total number of differentiated commodities to
. There is also a non-traded numeraire good, bringing the total number of differentiated commodities to ![]() .
.
For each period
![]() there is a finite number of purchase decisions or transactions for each good, denoted
there is a finite number of purchase decisions or transactions for each good, denoted
![]() . These decisions may originate at firms or consumers: the demand system is silent about the identity of the agents behind the purchases. The distribution of purchase
decisions across goods is given by
. These decisions may originate at firms or consumers: the demand system is silent about the identity of the agents behind the purchases. The distribution of purchase
decisions across goods is given by
where
| (2) |
where
The demand for the country ![]() variety of a given good
variety of a given good ![]() is determined as follows.
Each purchase decision represents an independent, discrete choice between each of the varieties
is determined as follows.
Each purchase decision represents an independent, discrete choice between each of the varieties
![]() governed by prices and a vector of random utility terms,
governed by prices and a vector of random utility terms,
![]() . It is a discrete choice because each purchase decision must be satisfied by a single country--albeit in the quantity of choice. It is an
independent choice each purchase for good
. It is a discrete choice because each purchase decision must be satisfied by a single country--albeit in the quantity of choice. It is an
independent choice each purchase for good ![]() has its own idiosyncratic type
has its own idiosyncratic type ![]() , drawn from distribution
, drawn from distribution ![]() independently of the type of other purchases in the same or different good or period.
independently of the type of other purchases in the same or different good or period.
The non-negative vector ![]() determines the agent's preferences over the country-specific varieties
determines the agent's preferences over the country-specific varieties
![]() ,
,
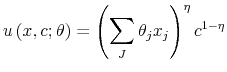
Let
![]() be the vector of country prices for good
be the vector of country prices for good ![]() at date
at date ![]() . A single variety must be chosen for each purchase decision. First, we solve for the indirect utility function
. A single variety must be chosen for each purchase decision. First, we solve for the indirect utility function ![]() associated with choosing the country
associated with choosing the country ![]() variety. The optimal quantities
variety. The optimal quantities ![]() and
and ![]() must then solve
must then solve
The solution is
or, in terms of revenues,
Given the vector
![]() , the optimal choice amoung country varieties associated with type
, the optimal choice amoung country varieties associated with type ![]() purchase decision is given by
purchase decision is given by
Note how the choice model lays out the foundations for the gains from new varieties. A new variety ![]() comes with a new draw
comes with a new draw
![]() . Quite obviously, the maximum across draws,
. Quite obviously, the maximum across draws, ![]() , is increasing
with the number of independent draws--that is, the number of varieties--as there is always the chance the random utility term
, is increasing
with the number of independent draws--that is, the number of varieties--as there is always the chance the random utility term
![]() comes high enough that the new variety becomes the optimal choice. How likely this is will depend on the distribution
comes high enough that the new variety becomes the optimal choice. How likely this is will depend on the distribution ![]() as well as the price differences across varieties.
as well as the price differences across varieties.
Let
![]() be independently and identically distributed according to a Gumbel (or type I extreme value) distribution
be independently and identically distributed according to a Gumbel (or type I extreme value) distribution ![]() ,
,
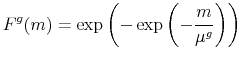
The Gumbel distribution is a particular case of the generalized extreme value distribution. It thus arises naturally as the distribution of the maximum of a (properly normalized) sequence of i.i.d. random variables.10 Perhaps one can view these underlying random variables as the variety's value for different uses and the random utility term as the variety's value for its best use.
In any case, the Gumbel distribution keeps the demand system tractable due to its properties regarding the maximum order statistic. If
![]() is a sequence of i.i.d. variables with a Gumbel distribution, the probability that country
is a sequence of i.i.d. variables with a Gumbel distribution, the probability that country ![]() supplies any given purchase decision for good
supplies any given purchase decision for good ![]() is then simply given by
is then simply given by
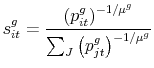
It is immediate to see why the Gumbel distribution is commonly used in discrete choice models. It is perhaps less known that, as Anderson et al. (1987) first pointed out, the discrete choice model presented here serves as a foundation for the CES demand specification as the number of independent purchase decisions tends to infinity.
2.1 Retrieving the CES demand as
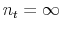
For asymptotically large ![]() we can invoke the law of large numbers and treat the probability that any country satisfies a given purchase decision for good
we can invoke the law of large numbers and treat the probability that any country satisfies a given purchase decision for good ![]() as the fraction of purchase decisions actually supplied by each country,
as the fraction of purchase decisions actually supplied by each country, ![]() . Each purchase decision is of
the amount given by (4), and thus the demand of variety
. Each purchase decision is of
the amount given by (4), and thus the demand of variety ![]() of good
of good ![]() at date
at date ![]() is given by
is given by
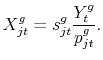
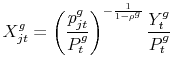
where
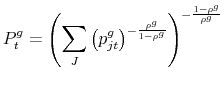
is the familiar price index.
The elasticity of substitution relates to the underlying distribution parameter by
![]() . When
. When ![]() is low, the random utility terms show
little dispersion and the optimal choice is mostly driven by the price, that is, varieties become close substitutes--as we will expect from a high elasticity
is low, the random utility terms show
little dispersion and the optimal choice is mostly driven by the price, that is, varieties become close substitutes--as we will expect from a high elasticity ![]() . Conversely, when the
random utility terms are highly dispersed (high
. Conversely, when the
random utility terms are highly dispersed (high ![]() ), the choice of a variety is not very sensitive to prices. Note how the
), the choice of a variety is not very sensitive to prices. Note how the ![]() also links the elasticity of substitution with the magnitude of the gains from new varieties, even if prices are constant across old and new varieties. The higher
also links the elasticity of substitution with the magnitude of the gains from new varieties, even if prices are constant across old and new varieties. The higher ![]() , the more skewed to the right the Gumbel distribution is and new draws become more valuable.
, the more skewed to the right the Gumbel distribution is and new draws become more valuable.
A well-known property of the CES demand system is that we have that the reservation price for any variety is infinite, that is, there is positive trade
![]() for all
for all ![]() and periods
and periods ![]() . In other words, all available varieties are traded all the time. This property is the key identification scheme used in Feenstra (1994) and Broda and Weinstein (2006): whenever a
category is observed to have zero sales, it must be it is simply unavailable. We next show this not to be the case when the number of purchase decisions is finite.
. In other words, all available varieties are traded all the time. This property is the key identification scheme used in Feenstra (1994) and Broda and Weinstein (2006): whenever a
category is observed to have zero sales, it must be it is simply unavailable. We next show this not to be the case when the number of purchase decisions is finite.
2.2 Finite number of purchase decisions
For a finite number of purchase decisions, the demand for each variety ![]() is a non-degenerate random variable. Define
is a non-degenerate random variable. Define ![]() as the number of purchase decisions satisfied by country
as the number of purchase decisions satisfied by country ![]() at date
at date ![]() in good
in good ![]() . The vector
. The vector
![]() is a random variable distributed according to the multinomial distribution
is a random variable distributed according to the multinomial distribution
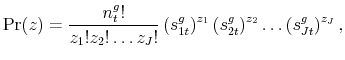
with
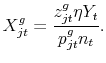
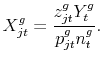
The market share for variety
Importantly, the demand ![]() can be zero with positive probability. The variety is available,
can be zero with positive probability. The variety is available,
![]() , yet none of the purchase decisions may be supplied by country
, yet none of the purchase decisions may be supplied by country ![]() at
period
at
period ![]() . A missing variety in our model constitutes a sample zero in a precise sense: we may observe all purchase decisions for some dates, but as long as we do
not observe them forever, we find ourselves with a finite sampling period. That is, zero demand events have vanishing probability only as
. A missing variety in our model constitutes a sample zero in a precise sense: we may observe all purchase decisions for some dates, but as long as we do
not observe them forever, we find ourselves with a finite sampling period. That is, zero demand events have vanishing probability only as ![]() tends to
infinity--which requires an infinitely long sampling period.
tends to
infinity--which requires an infinitely long sampling period.
2.3 The extensive margin
Next we provide the model's key formulas regarding the extensive margin. Let ![]() be an indicator variable equal to one if
be an indicator variable equal to one if
![]() , zero otherwise. The probability that
, zero otherwise. The probability that
![]() , that is, variety
, that is, variety ![]() in good
in good ![]() at date
at date ![]() is not traded, is given by
is not traded, is given by
The probability (10) appears often in our computations so it is worth a brief discussion. The formula is quite intuitive: the probability country
We will be interested in the expected number of varieties imported for a given good; or the expected number of products that are imported from a given country. Both calculations can be obtained as the appropriate sum of the random variables, ![]() . While these are not independent of each other, the expectation operator is linear. For the expected number of varieties for good
. While these are not independent of each other, the expectation operator is linear. For the expected number of varieties for good ![]() at date
at date ![]() , we have
, we have
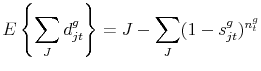
where we have made use of the fact that
For our analysis of the churning of varieties we need to compute the expected number of varieties that enter and exit between to two periods, ![]() and
and ![]() . Once again the indicator variable
. Once again the indicator variable ![]() comes handy. Entry of variety
comes handy. Entry of variety ![]() in good
in good ![]() at date
at date ![]() is equivalent to the event
is equivalent to the event
![]() . Since purchase decisions are independent across time, the probability is simply given by
. Since purchase decisions are independent across time, the probability is simply given by
We can then compute the expected number of varieties
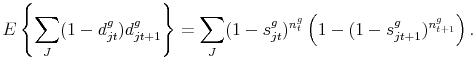
The same steps lead to the expected number of varieties that exit in good
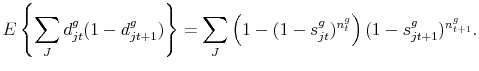
Both (13) and (14) can be easily written for the expected number of goods for a given country, or for two arbitrary dates. The expected net entry is simply the difference between the two.13
Finally, we show how to compute the survival function. The probability that a variety ![]() in good
in good ![]() has positive sales for periods
has positive sales for periods
![]() is equal
is equal
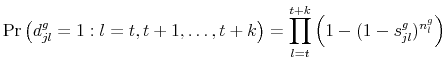
In practice, we will not be able to compute the survival function at the variety-good level from the data. Instead we will be aggregating across varieties, goods, or both. Unfortunately, there are no simple expressions for the survival function if there is price or good heterogeneity: the
distribution conditional on survival for ![]() periods within, say, good
periods within, say, good ![]() is no longer given by (8). We can make some progress towards the model counterpart for the empirical survival function by computing the number of varieties (or goods) expected to last at least
is no longer given by (8). We can make some progress towards the model counterpart for the empirical survival function by computing the number of varieties (or goods) expected to last at least ![]() periods. We rewrite the survival event as
periods. We rewrite the survival event as
![]() to obtain
to obtain
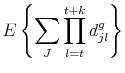 |
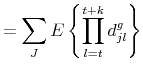 |
|
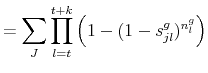 |
for adding up within a good
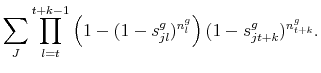
2.4 The intensive margin
The model has also implications regarding the intensive margin, that is, the amount traded in a given variety-good pair conditional on such flow being positive. Conditional on
![]() , the expected spending in variety
, the expected spending in variety ![]() in good
in good ![]() can be easily calculated by noting that
can be easily calculated by noting that
![]() . We thus obtain
. We thus obtain
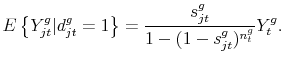
We can actually easily characterize the expectation on the additional condition that a set
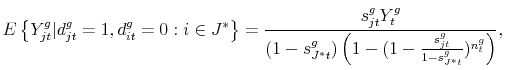 |
where
We would also like to provide measures of exit and entry of new products in terms of spending. This can be done easily with (15) at hand. Say, for example, that we want to compute the expected spending in new varieties ![]() in good
in good ![]() at date
at date ![]() . As
in (13), we rewrite the expectation as
. As
in (13), we rewrite the expectation as
![]() . Using the law of iterated expectations, and noting that
. Using the law of iterated expectations, and noting that
![]() is independent from
is independent from ![]() , we obtain
, we obtain
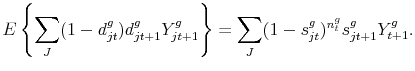
Finally we would like to compute the expected spending per variety ![]() conditional on positive trade for
conditional on positive trade for ![]() periods. Recalling that the survival event can be written as
periods. Recalling that the survival event can be written as
![]() , and following similar steps as before, we find that
, and following similar steps as before, we find that
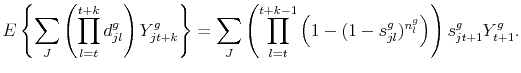
2.5 Missing domestic varieties
In principle, the set of ![]() of country-specific varieties should include the domestic variety as well. Unfortunately, there are no data on U.S. spending on
domestic products at the desired level of detail. This data shortcoming is ever-present in the literature. To get around it, domestic varieties are commonly assumed to enter the agent's preferences as a composite at the highest level of aggregation, instead of at the product level.16 This allows to compute the welfare gains associated with new import varieties within the data restrictions.
of country-specific varieties should include the domestic variety as well. Unfortunately, there are no data on U.S. spending on
domestic products at the desired level of detail. This data shortcoming is ever-present in the literature. To get around it, domestic varieties are commonly assumed to enter the agent's preferences as a composite at the highest level of aggregation, instead of at the product level.16 This allows to compute the welfare gains associated with new import varieties within the data restrictions.
While our model allows this approach, we will not pursue it. We will instead simply treat the demand for domestic varieties as an unobserved parameter. Doing so, the model implications for the foreign varieties are isomorphic to those for the full set of varieties. Let ![]() be the domestic variety and
be the domestic variety and ![]() the number of purchase decisions being captured by
the domestic variety. The distribution over the
the number of purchase decisions being captured by
the domestic variety. The distribution over the ![]() foreign varieties, conditional on
foreign varieties, conditional on ![]() , is still a multinomial with parameters
, is still a multinomial with parameters
![]() and probabilities equal to
and probabilities equal to
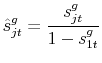
3.1 Data
Our main data source are the U.S. imports merchandise trade files provided by the U.S. Census Bureau for the years 1990 to 2001.17 The data contain all goods valued at more than $2,000 per commodity shipped by individuals and organizations (including importers and customs brokers) into the U.S. from other countries. The records are compiled in terms of commodity classification, values and country of origin as well as several other dimensions.
Regarding the product classification, we will work with the Harmonized Tariff Schedules of the United States at the ten-digit level (HS10 henceforth).18 Since their introduction in January 1989, the HS10 classification spans more than 18,000 codes. The classification, though, is dynamic as either the World Customs Organization or the United States International Trade Commission introduced new product codes or declare some obsolete. To address this, we keep only those HS10 product codes that have positive trade in 1990-2001.19 We make two additional adjustments. We drop chapters 98 and 99 containing special classification provisions and estimates of low-value imports, among others. We also drop products under the four-digit headline numbers 2710 to 2716: these codes include petroleum, fuels, and electric energy. These goods constitute an important part of total U.S. imports but are clearly out of place in our analysis. A total of 10537 HS10 product codes are in the final data set we use.
We also restrict our list of countries as follows. As done with product codes, we drop all countries that drop or appear during the period 1990-2001. We do make an exemption with Germany, assigning it the imports from West Germany in 1990.20 We further restrict our data to the largest 120 U.S. import partners over all the sample, accounting for more than 99 percent of total imports. We also append some gravity and GDP data, obtained from the CEPII website and completed with some additional GDP data from World Bank.
3.2 Calibration
We aim for a calibration as parsimonious as possible. We start with the parameters governing spending across goods,
![]() . The counterpart in the data is easily available, so for each HS10 product code we pin down
. The counterpart in the data is easily available, so for each HS10 product code we pin down ![]() to its average share in total U.S. imports.21 The defining feature of the product share
distribution is its skewness: there is a very large fraction of very small products. It is not clear these are economically meaningful classifications, yet we lack a systematic method to establish which are so.
to its average share in total U.S. imports.21 The defining feature of the product share
distribution is its skewness: there is a very large fraction of very small products. It is not clear these are economically meaningful classifications, yet we lack a systematic method to establish which are so.
Recall there is a one-to-one correspondence between our dispersion parameters ![]() and the elasticity of substitution,
and the elasticity of substitution, ![]() . We exploit this and obtain the good-specific elasticities of substitution from Broda and Weinstein (2006). There are several product codes for which there are no estimates available: we assign them the average elasticity
for their respective four-digit headline classification. The mean and median elasticities are 19.4 and 4, respectively. It should be mentioned that close to 40 percent of all products have an elasticity of substitution below 3. There is also a substantial amount of products with very high
elasticities too, in excess of 100, for example.
. We exploit this and obtain the good-specific elasticities of substitution from Broda and Weinstein (2006). There are several product codes for which there are no estimates available: we assign them the average elasticity
for their respective four-digit headline classification. The mean and median elasticities are 19.4 and 4, respectively. It should be mentioned that close to 40 percent of all products have an elasticity of substitution below 3. There is also a substantial amount of products with very high
elasticities too, in excess of 100, for example.
Our model requires to take a stand on the full distribution of prices. The data, at best, contains only average unit prices for the observed trade flows in a given period. To bridge both, we posit a parsimonious yet quite flexible specification for prices, allowing for country, good, and time fixed-effects:
While (16) can be used to fit the available data, it turns out that the only source of price heterogeneity that is relevant for the model are the country fixed-effects. Inspecting (5) is clear that both good and time fixed-effects cancel in the calculation of the probabilities
Finally we turn to the key parameter of the model: the number of purchase decisions, ![]() . The defining feature of a purchase decision is that it is an independent event. This makes it
difficult to map
. The defining feature of a purchase decision is that it is an independent event. This makes it
difficult to map ![]() directly to the data. For example, a large firm may decide to buy a specific input from a foreign country, resulting in a large order that may be spread over many
shipments over the course of several months. At the same time, it would be naive to equate
directly to the data. For example, a large firm may decide to buy a specific input from a foreign country, resulting in a large order that may be spread over many
shipments over the course of several months. At the same time, it would be naive to equate ![]() to the number of firms or households: clearly a retail chain may decide to stock its shelves
with a several computer models, possibly produced in as many countries.
to the number of firms or households: clearly a retail chain may decide to stock its shelves
with a several computer models, possibly produced in as many countries.
We decided instead to set ![]() to match the total count of good-variety pairs with positive trade in 1990. There were approximately 128,000 good-variety pairs with positive trade--a little
more than 10 percent of all possible good-variety pairs. We find that we need to set
to match the total count of good-variety pairs with positive trade in 1990. There were approximately 128,000 good-variety pairs with positive trade--a little
more than 10 percent of all possible good-variety pairs. We find that we need to set ![]() in the neighborhood of 1.6 million. Together with our calibration of the country fixed-effects, we
have thus matched the data regarding the count of varieties per country in 1990, that is, the extensive margin across countries in the first year in our sample.
in the neighborhood of 1.6 million. Together with our calibration of the country fixed-effects, we
have thus matched the data regarding the count of varieties per country in 1990, that is, the extensive margin across countries in the first year in our sample.
We are left with three parameters: the expenditure share of the numeraire ![]() and the growth rate of purchase decisions and aggregate income,
and the growth rate of purchase decisions and aggregate income, ![]() and
and ![]() respectively.24 We set
respectively.24 We set ![]() so 70 percent of expenditures are in domestic, non-tradeable goods; and set
so 70 percent of expenditures are in domestic, non-tradeable goods; and set ![]() to the average growth rate of real GDP over the period, 3.5 percent. It turns out neither of these parameters have virtually any impact on our results. It is instead the growth rate of purchase
decisions,
to the average growth rate of real GDP over the period, 3.5 percent. It turns out neither of these parameters have virtually any impact on our results. It is instead the growth rate of purchase
decisions, ![]() , that is key. Recall that
, that is key. Recall that ![]() should measure the number of
purchase decisions supplied abroad, as we do not have access to detailed domestic varieties. The natural target for the calibration is thus the sharp increase in import penetration in the U.S. over the period 1990-2001. Real imports grew at a torrid rate over the period, in excess of 10 percent on
average. We match the observed real import growth then by setting
should measure the number of
purchase decisions supplied abroad, as we do not have access to detailed domestic varieties. The natural target for the calibration is thus the sharp increase in import penetration in the U.S. over the period 1990-2001. Real imports grew at a torrid rate over the period, in excess of 10 percent on
average. We match the observed real import growth then by setting
![]() .
.
Table 1 summarizes our parameter choices and the targeted fact or source which we link the parameter to. We should note that all country fixed-effects and the number of purchase decisions have to be determined jointly by solving for the model. The link, though, with the stated targets is tight enough for the purpose of the exposition.
4 Cross-sectional results
We have calibrated the parameters to target the extensive margin across countries and the intensive margin across products. The first step is to check that model replicates successfully the cross-section distribution of the extensive margin across products we observe in the data.
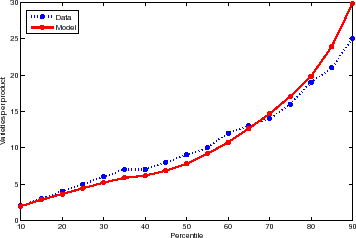
Let us start by looking at the distribution of the number of varieties per product. By construction, the model exactly matches the average number of varieties per product in 1990. Figure 1 shows the model's fit extends to the overall distribution. The dashed line plots the data by 5 percentile intervals between the 10th and the 90th.25 The solid line corresponds to the distribution of expected number of varieties across products. Model and data are rarely off by more than 1 variety: since the data will necessary come at discrete values, one could argue that the fit is essentially spot on. The model does come a tad below the data around the median ( 7.8 versus 9) and makes it up by over-predicting the right tail.
While the model reproduces very well the overall distribution, we want to make sure it is the right products that have the right amount of expected varieties. We will look then at the number of varieties by product market share and the elasticity of substitution. Regarding the former, data display a clear positive relationship: products with larger market share feature more countries supplying the good. We sorted the products in 20 categories with an equal number of products, according to their market shares.26 Thus the first bin contains products with a market share equal or smaller than the 5th percentile, the second bin contains products with a market share bigger than the 5th percentile but smaller than the 10th percentile, and so on. Products in the median category have an average of ten varieties, about double of what products in the first quartile do, and 50 percent less than what products in the last quartile do. It is not surprising that the model reproduces this very well: in our calibration, larger products simply have more purchase decisions, and thus the expected number of varieties is increasing in the product market share.
Perhaps a more striking data feature is that there remains a large amount of dispersion in the number of varieties in each size category. For example, the size category corresponding to the median number of varieties (about 10) has an inter-quartile range of 5 and 15 varieties per product. The dispersion is also clearly increasing in the product share.
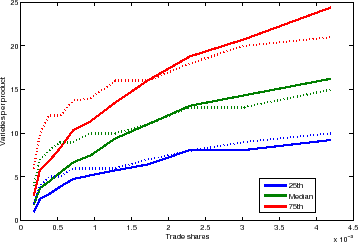
Figure 2 plots the first to last quartiles for each product size category for both data (dotted line) and model (solid line). With the exception of the right tail for very small products, the model tracks the data with uncanny precision. As in the data, the inter-quartile range expands with the product market share. Note that because the calibration matches the product market shares in the data, each size category contains exactly the same set of products in the model and in the data.
In the model, the only source of variation in the expected number of varieties per product, given its market share, is the elasticity of substitution. There is no correlation between the elasticities and market shares. However, we find that products with higher elasticities tend to have fewer varieties with positive trade. The dispersion in the number of varieties per product also has a (weak) negative relationship with the elasticity of substitution.
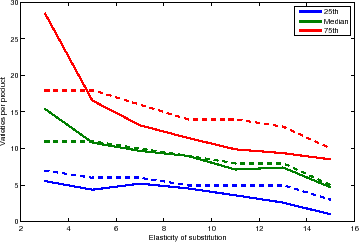
Figure 3 reproduces the plot in Figure 2, but this time products have been classified according to their elasticity of substitution.27 The dotted lines display the first to last quartiles. Both the median and the top quartile are decreasing with the elasticity of substitution--though the bottom quartile displays only a slight downward slope.
The model performance is striking. The median and bottom quartile are virtually spot on with the data thorough the range of elasticities. The model overpredicts the amount of skewness for low elasticities and has a substantially sharper fall in the dispersion for higher elasticities. Still, the top quartile does not wander too far from the data. Recall the elasticities were estimated by Broda and Weinstein (2006) using unit price data.
What is behind the decreasing relationship between elasticities and the extensive margin? As it is well-known to anyone familiar with the standard CES demand system, a higher elasticity given prices will lead to a more skewed distribution of market shares. Intuitively, suppliers with lower
prices capture a larger market share the closer substitutes the commodities are. In our framework, a high elasticity corresponds to a low dispersion parameter ![]() and the same comparative
statics lead to a more skewed probability distribution
and the same comparative
statics lead to a more skewed probability distribution ![]() , as it can be easily confirmed from (5). For the next step, we reproduce the formula for the expected number
of varieties for a given good
, as it can be easily confirmed from (5). For the next step, we reproduce the formula for the expected number
of varieties for a given good ![]() , (11):
, (11):
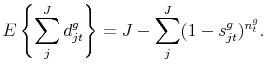
Finally, we also confirm that the model's prediction for the intensive margin--that is, the country's market share in revenues--line up with the data very well. The model's prediction for both quartiles and the median are within half a percentage point from the data. The model also reproduces the observed skewness in the distribution of country's market shares: the ranking of the largest 5 trading partners coincides in both data and mode, and together they account for the same fraction of total trade--about half.
5 Entry, exit and survival
We now turn to the model's performance over time and compare it with the data. The first question has to be whether the model correctly predicts the long-run growth of the extensive margin in trade. In the decade from 1990 to 2001, we saw the number of traded country-product pairs increase from 127,500 to 162,500.
![Figure 4: Good-variety pairs with positive trade. Figure 4 plots the expected number of good-variety pairs traded in the model (solid line) and the data (dotted line), in thousands, from 1990 to 2001. This single panel has a line graph with two lines. The y-axis is labeled, Thousands and ranges from 125 to 165. The x-axis is labeled Year and ranges from 1990 to 2001. Both the data and model lines start at 127 and then slant upward to the right. The ''model'' line increases steadily from 127 to 160. The ''Data'' line also increases but fluctuates a lot, crossing the ''model'' line twice . The model line stays virtually below the data line until year 1996. The model and data lines intersect at a point [199,145]. The model line then makes it up and rises above the model from 1997 to 2001.](img144.gif)
Figure 4 plots the expected number of good-variety pairs traded in the model and the data, in thousands, from 1990 to 2001. We did not target this data series directly in any year other than 1990, yet the model is virtually on the top of the data. The model predicts the average growth rate of the extensive margin within half a tenth of a percentage point: 2.18 percent versus 2.23 percent in the data
This result is more nuanced that it may appear at first sight. The predicted growth rate of traded varieties is only about one third of the growth rate of purchases, 6.5 percent. The difference in growth rates is due to some of the new purchase decisions in each good being assigned to varieties that had already positive trade, and thus do not add to the total count of traded varieties. Given that only about 10 percent of the possible varieties were traded, a tempting back-of-the-envelope calculation would lead us to conclude that only 10 percent of the new purchase orders would end up in previously-traded varieties--and the growth rate of traded varieties would have to be near 5 percent. Indeed, this would be an accurate calculation if, for each good, all varieties had the same price. But there is instead a large amount of price variation across countries. Some varieties are thus more attractive than others, that is, have a higher probability of capturing any given purchase. We are to expect that previously-traded varieties are those that are more attractive and thus bound to absorb a large fraction of the new purchases. The more skewed the underlying probability distribution, the slower the growth rate of the extensive margin. Reproducing the overall growth rate of the extensive margin is a strong reassurance for our calibration.
We performed some robustness analysis by varying some of the parameters. Alternative values for the growth rate of purchase decisions between 4 and 8 percent implies that the extensive growth rate is between 1.71 and 2.6 percent. We should also emphasize that model's predictions regarding the
growth rate depend on the level of ![]() as well. For example, we set
as well. For example, we set ![]() such that
only 6 percent of the varieties are traded in 1990: the predicted growth rate of the extensive margin increases to 2.7 percent. Going the opposite way, setting
such that
only 6 percent of the varieties are traded in 1990: the predicted growth rate of the extensive margin increases to 2.7 percent. Going the opposite way, setting ![]() such that 15 percent of
the varieties are traded in 1990 cuts down the predicted growth rate to 1.7 percent. The reason is quite straightforward. The more varieties are previously traded, the harder it is that the new purchases count towards the extensive margin.
such that 15 percent of
the varieties are traded in 1990 cuts down the predicted growth rate to 1.7 percent. The reason is quite straightforward. The more varieties are previously traded, the harder it is that the new purchases count towards the extensive margin.
5.1 Entry and exit
A striking feature of the data is the large number of varieties that start or stop being traded in any given year. As mentioned earlier, the total number of traded varieties increases a little bit more than 2 percent per year. On average, though, a little bit less of 23 percent of the previously-traded varieties stop being so, and the amount of new varieties almost adds up to a quarter of the number of traded varieties. The large count numbers do not have continuity in terms of expenditures: it is mainly varieties with small value that enter and exit. The net change in varieties accounts only for a small 0.3 percent of the previous value, with gross entry and exit being just around 1 percent.
|
Table 2 presents the rates for data and model, both by count and by value.28 The model predictions are very much line with the data. Gross flows are very large by count but relatively small by value. We have already seen the model matched the data regarding net entry by count: it is also spot on regarding the trade growth, in value, contributed by net entry. Since we calibrated the model to match total trade value growth, the model fully matches the decomposition between intensive and extensive margin.
The model slightly overstates the amount of churning by count. This is perhaps not surprising: we have no intrinsic persistence mechanism, as purchase decisions are completely independent across periods. The "persistence" is instead driven by the probability a variety has positive trade:
varieties that are either very likely or very unlikely to have positive trade count little toward churning. To see this, consider the probability a variety ![]() in good
in good ![]() enters assuming that there is no growth in purchase decisions so varieties are identically distributed across periods. From (12), the probability is simply
enters assuming that there is no growth in purchase decisions so varieties are identically distributed across periods. From (12), the probability is simply
![]() .29 Clearly the expression is concave in
.29 Clearly the expression is concave in
![]() and thus the probability of entry is maximized at
and thus the probability of entry is maximized at
![]() . It is also symmetric, that is, two varieties with
. It is also symmetric, that is, two varieties with
![]() have identical probability of entry. Once we average across varieties--see (13)--the amount of entry will be determined
by the fraction of varieties whose likelihood
have identical probability of entry. Once we average across varieties--see (13)--the amount of entry will be determined
by the fraction of varieties whose likelihood
![]() is near .5, that is, how many varieties are very uncertain to
be observed.30
is near .5, that is, how many varieties are very uncertain to
be observed.30
What is the effect of growth in purchase decisions? By inspecting (13) and (14) we confirm what we would guess, namely, that faster growth leads to more entry and less exit. A perhaps more intriguing comparative static is regard the level of
purchase decisions, ![]() . More purchase decisions reduce both exit and entry, so it unambiguously reduces churning. We explore some higher values of
. More purchase decisions reduce both exit and entry, so it unambiguously reduces churning. We explore some higher values of ![]() and find the model can match the observed entry and exit rates spot on while only slightly overstating the number of traded varieties in 1990.31
and find the model can match the observed entry and exit rates spot on while only slightly overstating the number of traded varieties in 1990.31
|
The model's predictions for total entry and exit, both measured by count and by value, are very much in line with the data. We now go one step further and ask whether entry and exit across goods and countries are similar in model and data. To this end we compute entry, exit, and net entry at the good and country level.32 We then see how the gross and net changes correlate with the market share of the good or country.
Table 3 documents the set of correlations for both model and data.33 Let us first discuss the data. Both entry and exit gross flows are positively correlated with the market share of the underlying good or country. In particular, the correlation is very high with the country market share. Thus, we observe more churning for larger good categories and with large trade partners. Net entry, though, is negatively, albeit weakly, correlated. Hence, there is a substantial amount of net entry being driven by smaller products and trade partners.
The same patterns arise in the model: the predicted correlations are very close to the data, with perhaps the exceptions of exit flows across goods and the net entry across countries. As in the data, correlations are stronger for country market shares. The correlation with net entry is negative, albeit it is virtually zero for country market shares.
What is behind the positive relationship between churning and country/good market share? As discussed earlier, the amount of churning is highest when the probability of observing a given variety is close to .5. The vast majority of varieties in our model have a much lower probability than .5: after all, the model is calibrated such that just 10 percent of them are expected to have positive trade. Now, the distribution of probabilities shifts to the right for goods or countries with larger market share and thus most varieties get closer to the maximum entropy level of .5. As a result, churning increases for these categories. Note we could have ended up with a negative correlation if all varieties were very likely to be observed: then a rightward shift would have set most probabilities away from .5 and thus decreased churning.
The explanation for the negative correlation of net entry is different. Our model features a strong non-linearity regarding the number of purchase decisions. If there are very few purchases initially, every new one is virtually guaranteed to imply a new variety being traded, as the likelihood the new purchase order ends up being supplied by a previously-traded is quite low. At the other extreme, when most varieties are already traded, new purchases are very likely to be satisfied by a previously traded category. Thus, despite all categories having the same growth in purchase decisions, the expected growth in varieties is faster in smaller categories.34
5.2 Survival analysis
We complete our analysis by tracking the 1990 cohort of traded varieties over the entire sample. We will then compare the "survival" probability and exit hazard rates in the data with their model counterparts. Special attention will be paid to the composition of the varieties over time that are continuously traded over time.
Let us start with the survival analysis with the data. Figure 5 displays the empirical survival probability and hazard function, in a dashed line, in the top and bottom panels, respectively. The survival probability drops steeply in the first and second years, and then slopes down only very gently. After ten years, about half of the varieties with positive trade in 1990 have been traded continuously for all the years in between. The exit hazard rate also falls steeply. A quarter of the traded varieties in 1990 are dropped in 1991 but, among those surviving for five years, less than 6 percent do. The hazard rate seems to settle down to a very low 2 percent after 8 years.
Figure 5 also plots the model's predictions with a solid line. Once again model and data lie very close together. The model replicates the steep drop in both survival probabilities and the hazard function. The survival probability also becomes practically flat after five years. Looking at the hazard function we see the model slightly overstates the exit rate in the first year but then tracks the data quite well. In the long run, the model's hazard function dips below 1 percent, undershooting the data.
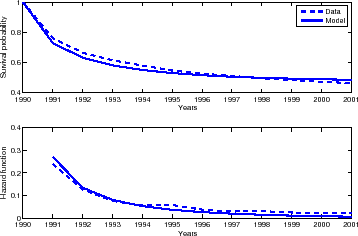
In Section 2 we described how to approximate the survival probability. The forces behind the downward slopping survival probability and hazard function are purely those of selection: the underlying likelihood of a variety of being trade is essentially constant in our model.35 We should expect the less likely varieties to drop earlier, and thus the remaining varieties have a decreasing probability of exit. These dynamics are well known and we would not dwell further on them.
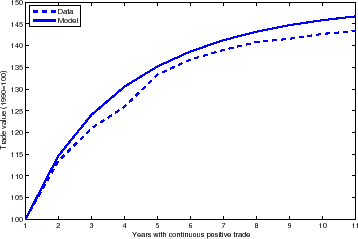
The selection mechanism also appears when we look at the intensive margin of the surviving varieties. Figure 6 plots the average value associated with varieties that have been continuously traded, for data and the model. It should not be surprising that it is increasing both in the data and the model. Note the magnitudes are substantial, and the model does an excellent job at matching the data quantitatively. After five years the surviving variety is about 32 percent larger than the original cohort in 1990--in the model, it is just below 35 percent. After ten years, the data shows an increase of 44 percent versus 46 percent in the model.36
Finally we look at the cumulative entry and exit since 1990. That is, for every year in the sample after 1990 we compute the number of varieties present in that year which were not traded in 1990 for entry; and similarly for exit. Note the main difference with the previous survival analysis is that we do not require the disappearing varieties to have been traded until the current year, or new varieties to appear for first time then. For example, a variety that was traded, say, in 1990 and 1991 as well as in 1994 but not in 1992, would count toward exit in 1995 if it is not traded in 1995.
Figure 7 plots the data--in a dashed line--and the model--in a solid line. Model and data still line up quite well, but we can no longer claim the model delivers a good quantitative fit. This is, in part, because 1991 turns out to be quite an outlier in the sample, with very low entry--actually the net change in varieties was zero. As a result the model predicts too much entry early on and too little later on.
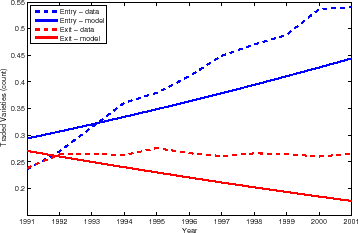
It is also apparent from Figure 7 that while the model predicts a sloping-down cumulative exit, in the data the cumulative exit rate seems to stabilize.37 In contrast, the model seems to predict the cumulative entry should grow at a slightly slower rate than it does in the data. Recall that the model is pretty much spot on regarding survival, as shown in Figure 5. What the model is having some trouble reproducing are the probabilities of re-entry and re-exit. In particular, the data features a substantial amount of varieties that permanently exit after 1990, as well as a fraction of varieties that do not exit after seeing positive trade for first time after 1990.
We see this as indicative of underlying price movements. Recall our calibration assumed constant relative prices across countries. This is clearly a simplification that served our aim to keep the calibration as parsimonious as possible, yet it is blatantly at odds with the data. Temporary price movements will naturally bring the model more in line with the data by introducing mean-reversion effects. Varieties that had a (temporarily) low price in 1990 would be likely to appear in 1990 but, once their price returned to the mean, may not be expected to re-appear. Similarly, varieties with a temporary price increase would likely return permanently to positive trade later in the sample once their prices return to the mean. While the model allows for price dynamics, we would need substantial additional structure in order to infer the counter-factual prices. In the next Section we will instead look at a particular episode for which we do have a good grasp of the price dynamics.
6 Entry and exit during NAFTA
The North American Free Trade Agreement (NAFTA) is one of the most studied trade liberalizations episodes in the literature.38 NAFTA called for the phasing out of virtually all restrictions on trade among the United States, Canada, and Mexico. The biggest impact was regarding Mexico, since U.S. and Canada were already well into removing trade barriers between themselves in accordance to their Free Trade Agreement signed five years prior. U.S. imports from Mexico grew a staggering 70 percent in just three years, virtually doubling Mexico's share of U.S. imports and eventually consolidating its position as the second largest U.S. trade partner, only behind Canada.39
A natural question is what fraction of the trade expansion following NAFTA was due to the introduction of new goods from Mexico and Canada. The answer for Mexico is substantial. In three years 30 percent more goods were imported from Mexico into the U.S., adding to more than 10 percent in trade value. Recall that the average growth rate for varieties (including all countries) over the period is substantially more modest, of the tune of 2 percent product growth per year, adding to little value overall. The extensive-margin response for U.S. imports from Canada was quite muted in comparison.
We now approach the response to the extensive margin to NAFTA through the lens of our model. We start by comparing the model predictions under the baseline calibration, featuring constant relative prices. In other words, there is no NAFTA-related reduction in tariffs so we can think of the model results as a counterfactual exercise in which only trend growth in trade expands the set of goods with positive trade. Figures 8 and 9 compare the data with the model output for the net changes by count and value, as well as the cumulative entry and exit rates, relative to 1993--the last year before NAFTA.
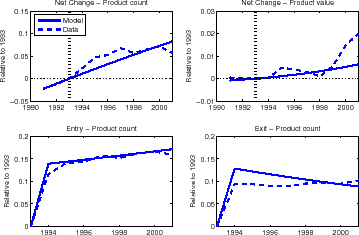
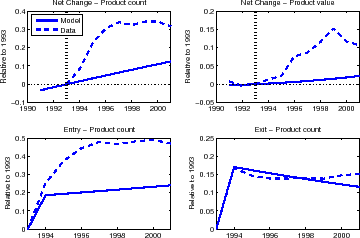
The model is spot on with Canada, as Figure 8 shows. The net change, by count, is right as predicted; the contribution, by value, is a little bit more noisy but the model remains in the ballpark of the data. Canada is also one of the countries for which the model does an excellent job with the cumulative entry rate. The model is also very close regarding cumulative exit, though the data does not display a downward slope, an issue previously encountered. We conclude from Figure 8 that NAFTA did not have a substantial impact regarding Canada imports to the U.S. This is not really surprising, as U.S. tariffs for Canadian goods were already low or nonexistent since 1989.
The contrast with Mexico is remarkable, as shown in Figure 9. The model does not predict anything close to what we observed: net change, both by count and by value, are much larger in the data than in the model. Similarly the cumulative entry rates virtually triple those predicted in the model over the period 1994-2001. Only the cumulative exit rate seems to be in line.
In short, the model is completely missing the impact NAFTA had on U.S. imports from Mexico. We set ourselves to fix this omission by tweaking Mexico's trade costs starting in 1994. In order to match the increase in Mexico's share of total U.S. imports over the sample period we find we have to decrease the country-specific trade costs by 10 percentage points.40 We also have to decide on the transition path: a substantial fraction of the import tariffs were phased out in five years or more, as the NAFTA agreement allowed to, yet many tariffs on Mexico exports to the U.S. were immediately eliminated in January 1994. By the end of our sample period, more than 85 percent of Mexico goods entered the U.S. duty free.41. We settle on a three year transition. Note we are not adjusting the underlying growth in purchase decisions. Implicitly, we are assuming no domestic varieties were substituted by Mexican imports: while we doubt this was really the case, we prefer an agnostic calibration regarding this margin as we have no data to contrast any alternative.
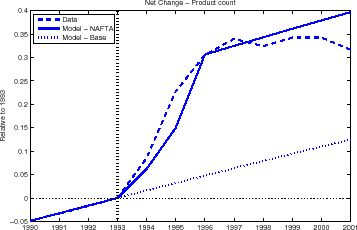
Figure 10 shows the model's path for the net change in imported products from Mexico after incorporating the tariff cut (solid line), as well as the data (dashed line) and the baseline calibration (dotted line). The model's predicted response captures very well the magnitude in the expansion in the good mix imported from Mexico. It also broadly captures the speed of adjustment. We should note, though, that this is entirely due to the assumed pace of tariff phase outs: the model does not have intrinsic persistence. The model also still underpredicts the importance of the extensive margin by value, only closing the gap in Figure 9 by about half.
We find it surprising that the model matches the data with such ease once tariff cuts are accounted for in the calibration. After all, the extensive margin in our framework adjusts for very prosaic reasons. As Mexican goods get cheaper, they get purchased more often. Thus a larger fraction of them will be observed in the course of a year. We view our results as strongly suggestive that a complete analysis of NAFTA or similar trade liberalization episodes has to specify a micro-founded model of demand at the transaction level.
7 Re-evaluating welfare gains from new varieties
TBC
Feenstra (1994) and Broda and Weinstein (2006) have pioneered the estimation of the welfare gains due to new import varieties under a CES demand system. Available commodities are identified as those observed to have positive trade, as dictated by the CES demand. As we have already seen, all varieties are available in our model yet most are not traded. In this Section we re-evaluate the computation of the welfare gains through the lens of our model.
Feenstra (1994) shows how to derive an exact import price index under a CES demand when the set of varieties available changes across periods. The price index can then be used to compute the welfare gains associated with trade.42 For the ease of notation, we drop the superscript ![]() and compare two consecutive
periods,
and compare two consecutive
periods, ![]() and
and ![]() . Let
. Let ![]() be the set of varieties with positive trade at date
be the set of varieties with positive trade at date ![]() ,
,
![]() , and
, and
![]() . Given that prices are constant across periods, the import price index when
. Given that prices are constant across periods, the import price index when
![]() is given by
is given by
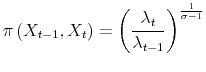
where
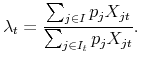
When we have the exact CES demand system, that is, when
![]() in both periods, we have that all commodities are traded in all periods,
in both periods, we have that all commodities are traded in all periods,
![]() . Since there are no price changes,
. Since there are no price changes,
![]() , and as one would expected the import price index is unchanged,
, and as one would expected the import price index is unchanged, ![]() . We will obviously find no welfare gains associated with new varieties, since there are none.
. We will obviously find no welfare gains associated with new varieties, since there are none.
If the number of purchase decisions is finite, then
![]() are random variables, and so it is
are random variables, and so it is ![]() . Thus we should treat
the resulting import price index as an estimate, subject to sampling error. We will next ask whether it is a unbiased estimator, and if it is not, what can be said about the sign and size of the bias.
. Thus we should treat
the resulting import price index as an estimate, subject to sampling error. We will next ask whether it is a unbiased estimator, and if it is not, what can be said about the sign and size of the bias.
Let us take a closer look at the import price index with finite purchase decisions. Since a constant fraction of income is always spent on the variety of choice, we have that
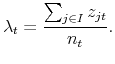
When
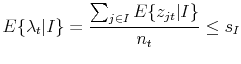
Because of the intersection set ![]() ,
, ![]() and
and
![]() are not independent variables. Moreover, the import price index
are not independent variables. Moreover, the import price index ![]() is a non-linear function of both,
is a non-linear function of both,
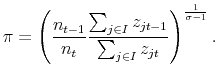
7.1 No growth
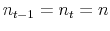
We first analyze the case when the number of purchase decisions is identical in both periods,
![]() . In this case the particular realizations of
. In this case the particular realizations of ![]() in each period are
identically and independently distributed events. This allows us to characterize the bias even as the import price index
in each period are
identically and independently distributed events. This allows us to characterize the bias even as the import price index ![]() is a non-linear function of
is a non-linear function of ![]() and
and
![]() , which are not independent.
, which are not independent.
Let ![]() and
and ![]() be two realizations from the multinomial distribution (8). Because the realizations in each period are independent, it is equally likely that
be two realizations from the multinomial distribution (8). Because the realizations in each period are independent, it is equally likely that ![]() and
and ![]() than
than
![]() and
and ![]() . In a slight abuse of notation let
. In a slight abuse of notation let
![]() and
and
![]() be the import price index in each case. Clearly,
be the import price index in each case. Clearly,
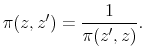
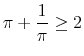
The upward bias, though, tends to be very small. Since ![]() is i.i.d., variable
is i.i.d., variable ![]() has the same expectation in each period,
has the same expectation in each period,
![]() . For the convexity to produce a sizeable bias, we would need
. For the convexity to produce a sizeable bias, we would need ![]() to be quite dispersed. Instead the variance in
to be quite dispersed. Instead the variance in ![]() actually converges to zero quite fast with
actually converges to zero quite fast with ![]() . Given intersection set
. Given intersection set ![]() ,
,
![]() is distributed according to a Binomial distribution with parameters
is distributed according to a Binomial distribution with parameters ![]() and
and ![]() . The variance of
. The variance of ![]() is then
is then
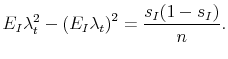
7.2 Growth
Next we consider the case where the number of purchase decisions grows over time,
![]() , which constitutes our baseline calibration. An exact characterization of
, which constitutes our baseline calibration. An exact characterization of
![]() proves to be particularly difficult in this case, since
proves to be particularly difficult in this case, since ![]() and
and
![]() are no longer identically distributed. Fortunately, we can make considerable progress by ignoring the non-linearity,
are no longer identically distributed. Fortunately, we can make considerable progress by ignoring the non-linearity,
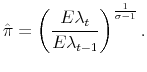
We start by solving for
![]() . We must keep in mind that
. We must keep in mind that ![]() is itself a random variable, that
depends on realizations in both periods. To make the argument clear, consider the indicator function
is itself a random variable, that
depends on realizations in both periods. To make the argument clear, consider the indicator function
![]() , which takes value 1 if
, which takes value 1 if ![]() , 0 otherwise. We can then write
, 0 otherwise. We can then write
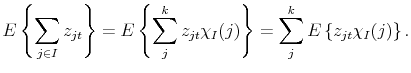 |
Since
We can easily solve for each of these terms:
Thus
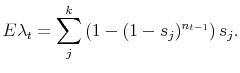
Combining
![]() and
and
![]() we obtain
we obtain
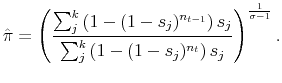
Not surprisingly, the size of the downward bias depends on how fast the number of purchase decisions grows. It is easy to see that ![]() decreases with the difference
decreases with the difference
![]() for a fixed
for a fixed ![]() . Moreover even a small increase in purchase decisions
can result in a large downward bias if the number of purchase decisions in the base period
. Moreover even a small increase in purchase decisions
can result in a large downward bias if the number of purchase decisions in the base period ![]() is small. This is relevant since most studies on variety gains compare years often a decade
or more apart for finely disaggregated categories that can be expected to have little trade to start with.
is small. This is relevant since most studies on variety gains compare years often a decade
or more apart for finely disaggregated categories that can be expected to have little trade to start with.
7.3 A sample of import products
We take a look at the quantitative importance of the biases discussed above. We choose to focus on the 8 import goods studied in Feenstra (1994) as a basis for the simulations, now comparing years 1967 and 1987. We take the point estimate for the elasticity from Feenstra (1994) and use the same country fixed-effects computed in Section 3.44 We pin down the number of purchase decisions in each period simply by matching the observed number of varieties traded. Note we do not impose a common growth rate or constant expenditure shares across goods. By letting the data speak, good by good, we get a chance to explore our results under different but informed parameters.
Table 4 includes a description of each import good, the number of suppliers in 1967 and 1987, and the estimated elasticity for each category. There is substantial variation on both counts. All but one good (portable typewriters) saw the number of varieties increase yet some good categories almost tripled the variety count, while others had very modest growth. The elasticity estimates range from a low of 3 to highs of 27 and 43 for gold and silver bullion, respectively. The next column reports the good-specific growth rate in purchase decisions, at an annual rate, needed to match the data. The growth rate are quite dispersed, as one would expect by matching point to point differences: recall the number of varieties in a given year is a random variable from the point of view of the model. Note it is not necessarily the case that goods that saw the largest increase in varieties have the highest growth rate in purchase decisions. Both the elasticity of substitution as well as the level of varieties impact the calibrated growth rate.
The last three columns in Table 4 finally reports our results regarding the import price index. Our "null hypothesis" is that all varieties were available at both dates--but not necessarily observed to have positive trade. For each product we report ![]() and contrast this linear approximation with
and contrast this linear approximation with
![]() , computed by simulating the model. From the latter we also obtain the probability that the import price index is biased downwards,
, computed by simulating the model. From the latter we also obtain the probability that the import price index is biased downwards,
![]() .
.
Let us start with the first four goods. They all display a substantial downward bias, ranging from close to 4 percent for men's leather athletic shoes to 11 percent for carbon steel sheets. The linear approximation turns out to be pretty good. For three out of these four products we are almost
certain that the point estimate will come below 1. For stainless steel bars the estimates for the import price index are very dispersed but there is more than a 75 percent probability of
them being below 1. Note the bias is larger for goods with lower elasticities and higher growth: the good with the largest bias, carbon steel sheets, features one of the lowest elasticities
in our sample as well as above average growth. We have already discussed how the bias depends on the growth rate of purchase decisions. The relationship between the bias and the elasticity is also quite straightforward, as lower elasticities makes the price index simply more sensitive to variation
in the ratio of expenditures
![]() . If varieties are close to perfect substitutes, then the price index naturally gives little importance to new goods. This is perfectly illustrated by our results
regarding gold and silver bullion. For these two goods, the bias is essentially negligible.
. If varieties are close to perfect substitutes, then the price index naturally gives little importance to new goods. This is perfectly illustrated by our results
regarding gold and silver bullion. For these two goods, the bias is essentially negligible.
Let us turn our discussion to color television receivers and portable typewriters. These two goods experienced a substantial transformation over the period, albeit with very different fates. Portable typewriters were progressively outdated by personal computers, while color televisions started as a luxurious novelty and ended up in every American household. Their results stand out in Table 4 for their own reasons.
First, portable typewriters saw negative growth in purchase decisions and, as a result, the import price index is biased upwards. Yet in close to one third of our simulations the import price index came below 1, as the estimate is very noisy. Second, color television receivers show a gap between the linear approximation and the simulated expectation. This reflects that more often than not there was simply no overlap between varieties between 1967 and 1987.45 This points to a potential problem with goods that have experienced a quick product cycle driven by technological transformations: as the common base of varieties supplied at both ends of the time sample becomes narrow, or non-existent, the resulting import price indexes are less precisely estimated.
Table 4: Bias in import price indexes
| Import | Varieties α1967 | Varieties α1987 | Elasticityα σ | Growth purchases |
Import Price Index |
Import Price Index |
Import Price Index |
| Men's Leather Athletic Shoes | 16 | 27 | 6.2 | 4.4 % | .9620 | .9623 | .9103 |
| Men's and boys' cotton knit shirts | 24 | 51 | 5.8 | 8.0% | .9592 | .9590 | .9974 |
| Stainless steel bars | 10 | 15 | 3.6 | 3.1 % | .9241 | .9293 | .7601 |
| Carbon steel sheets | 11 | 26 | 4.2 | 7.2 % | .89 | .8896 | .9678 |
| Color television receivers | 6 | 15 | 8.4 | 6.8 % | .9317 | .982 | .9231 |
| Portable typewriters | 17 | 14 | 3 | -1.7 % | 1.0484 | 1.0549 | .3277 |
| Gold bullion |
19 | 32 | 27.2 | 9.5 % | .9931 | .9931 | .9389 |
| Silver bullion | 11 | 15 | 42.9 | 2.5 % | .9963 | .9962 | .7131 |
8 Conclusions
Conspicuously absent from our theory of the extensive margin are economies of scale--the most common approach in the literature to capture missing trade links has been to introduce fixed costs on the supply side. We find these trade models most appealing for the export decision margin at the firm level. Our results indicate, though, that one does not need economies of scale to explain the extensive margin at a more aggregated level. That said, we should note that economies of scale may be important for wholesale retailers which, we suspect, would be a key determinant of the number of independent purchase decisions we need to match the data.
Our model also has implications regarding at what frequency we should approach the data. For example, given a ratio of purchase decisions per unit of time, we can derive the length of time we would need to have a certain level of confidence that a given commodity would have been observed if available. Unfortunately, at high levels of detail, our model indicates these sampling periods will far exceed anything practical. It is thus perhaps the right decision to work with likelihoods at the usual frequencies, annual or bi-annual. Ideally, a complete model would allow some probability that a given commodity is indeed not available. It is an open question what additional data can be used to inform this margin given that our model matches the data very well while assuming all varieties are available.
Bibliography
Working paper, FRB Philadelphia.
NBER Working paper 17864.
University of California, Davis.
Working paper 2012-12.
Journal of Political Economy, forthcoming.
Working paper, Swiss National Bank.
Yale University.
Working paper, NYU.