
The Cyclical Behavior of Equilibrium Unemployment and Vacancies Across OECD Countries *
Keywords: Labor market, vacancies, unemployment, OECD countries
Abstract:
JEL Classification: E24, E32, J63, J64.
1 Introduction
Labor market search models as pioneered by Diamond (1982), Mortensen (1994), and Pissarides (2000), henceforth DMP, proved to be very useful in understanding equilibrium unemployment and vacancies as well as the long-run relationship between the two. However, when the model is extended to accommodate aggregate fluctuations, as in Shimer (2005), it fails to generate the observed volatility at business-cycle frequencies by an order of magnitude. In particular, the model requires implausibly large shocks to generate substantial variation in key variables; unemployment, vacancies and market tightness (vacancy to unemployment ratio). This result, sometimes referred to as the "Shimer Puzzle", spurred a large literature on the subject and a scramble for a "solution" to the puzzle.
The availability of vacancy data from the OECD, as well as the work of Elsby and Sahin (2011) in estimating job-finding and separation rates in a set of OECD countries has created opportunities to analyze labor market fluctuations in the context of a search model across a fairly large set of countries beyond the U.S. This is important because potential solutions to the volatility puzzle identified by Shimer (2005) have been associated with features of the economic environment that might vary, at least to a degree, across countries.
In this paper, we accomplish three goals. First,we document a set of labor market facts at business-cycle frequencies for a cross-section of OECD countries, focusing on unemployment, vacancies, market tightness, and labor productivity. Second, we evaluate the DMP model's ability to replicate business-cycle frequency fluctuations in these variables. We find that all countries in our sample exhibit significantly higher volatility in their labor market variables relative to labor productivity. Moreover, simulations of the DMP model calibrated to country-specific parameter values in a standard Shimer (2005)-like way fail to generate the observed degree of amplification.1
Third, and most important, we show how the cross-country scrutiny this data allows can be of help in evaluating the different solutions to the puzzle that have been proposed in the literature. To illustrate this point we take the work of Hagedorn and Manovskii (2008) that shows how calibrating a modified version of Shimer (2005) to target average market tightness and the elasticity of wages with respect to productivity, enables the model to replicate the observed labor market fluctuation in the U.S.. This strategy fails to work for some of the countries in our sample. It may lead, just like the standard calibration strategy, to a counterfactually low volatility in labor market variables, but also, to the opposite result, where volatility far exceeds the magnitudes observed in the data.
In trying to get at the root causes of this failure we come up with a couple of observations. First, for countries that exhibit small enough persistence in their estimated productivity process, the model continues to deliver significantly smaller volatilities for labor market variables than the data does. The intuition is that everything else being the same, when faced with a positive productivity shock, more vacancies will be created in an economy where the shock exhibits high persistence as the expected gains from creating such vacancies are higher, everything else being the same. Secondly, low job finding rates lead to lower volatility in unemployment but not necessarily in vacancies. This is because conditional on existing vacancies a productivity shock means unemployment will decrease by less the smaller the job finding rate is. Everything else the same, this reduces expected profits for firms, leading them to post more vacancies when job finding rates are smaller.
Our paper is related to a large body of literature that emerged in response to Shimer (2005). In the standard stochastic version of the DMP model, firms respond to a positive productivity shock by creating more vacancies and unemployment duration goes down. This in turn puts upward pressure on wages, absorbing most of the gains in productivity, and thus resulting in insignificant changes in unemployment and vacancies. Several studies proposed wage rigidity as a potential resolution to the puzzle. Shimer (2004), Hall (2005) and Kennan (2010) build on this diagnosis and introduce wage rigidity either exogenously or through an endogenous mechanism, such as asymmetric information. Nonetheless, Mortensen and Nagypal (2007), argue that introducing wage rigidity is not, by itself, sufficient to generate amplification.2 Moreover, Pissarides (2009) argues that there is no empirical evidence in favor of wage rigidity over the cycle for newly created matches, which is the important margin for job creation in the canonical DMP model.
Several recent studies also provide mechanisms that can amplify the effects of business cycles on unemployment and vacancies by extending the prototype model in several dimensions and/or approaching the calibration differently. This includes not only the aforementioned Hagedorn and Manovskii (2008), but also Silva (2009) that introduces post-match labor turnover costs. While both Costain (2008) and Hornstein and Violante (2005) argue that the former study gives rise to counterfactual implications regarding the impact of unemployment subsidies on the equilibrium unemployment rate, the latter study's result depends on a particular constellation of parameter values for separation, hiring and training costs that is hard to justify empirically. There is also a line of research that argues that incorporating on-the-job-search improves the quantitative fit of the model: Krause (2006), Nagypal (2006), and Tasci (2007). Finally, Petrosky-Nadeau and Wasmer (2010) argue that financial frictions, in addition to the labor market frictions, can significantly increase the response of vacancies and unemployment to productivity shocks.
While our paper does not provide a direct test of the validity of each channel in a cross-country context, it is certainly a step in that direction. The ability of most (if not all) mechanisms described above to quantitatively match the volatility of labor market variables is predicated on particular calibrations designed to hit U.S. targets for the most part. We bring in an extra dimension of scrutiny that we hope will prove helpful in distinguishing between all the existent potential explanations. Recent work by Justiniano and Michelacci (2011) has proceeded in exactly this direction. They look at a real business cycle model with search and matching frictions driven by several shocks capturing some transmission mechanisms suggested in the literature and estimate it on data from 5 European countries, in addition to the U.S. They find that while technology shocks are able replicate the volatility of labor market variables in the U.S., matching shocks and job destruction shocks play a substantially more important role in European countries.
Our work is also related to a strand of literature that focuses mainly on the role of labor market institutions and policies, in accounting for the differences in unemployment rates across countries in the long-run; in particular between Europe and North America. Nickell (2005) and Blanchard (2006) provide nice surveys of this literature and illustrate how the debate evolved over time and mostly settled on the conclusion that a particular interaction between shocks and labor market institutions can explain both the relatively low average rates of unemployment in Europe early in the post-war period as well as the higher rates observed between 1985 and the early 2000s.3 Our focus, instead, is on the business-cycle frequency variation in the unemployment rate and also involves a discussion of additional labor market variables such as vacancies and market tightness for a similar cross-section of countries.
2 Data
We have collected unbalanced data panels at a quarterly frequency on vacancies, unemployment, employment, labor force, and real GDP for a set OECD countries. The proximate sources are the OECD's Economic Outlook Database, the IMF's International Finance Statistics, as well as some direct national sources like Statistics Canada and the Canadian Conference Board for Canadian vacancies, the Office for National Statistics for U.K. vacancies, and the Ministry of Health, Labor and Welfare.
While the data collection process for unemployment, employment, labor force and real GDP is fairly standard across the set of OECD countries we look at, the same cannot be said for the vacancy data. The OECD compiles its vacancy data from a variety of national sources with no harmonized reporting procedures. As a result, this study will not emphasize cross-country comparisons. Instead, we opt for using all the available data we have for each country as opposed to choosing common dates to compare across.
Tables 1 to 3 summarize the data.4 Here, the statistics pertain to all the data available for each variable-country pair, as indicated by the columns labeled "Start date" and "End date".
Tables 5 to 17 show the business cycle statistics for each country when we control for the dates by choosing those for the shortest-lived series in that country.5 Some patterns emerge that can provide useful clues regarding the DMP model's ability to account for the data.
First, there is a fairly strong positive cross-country correlation between the volatility of productivity and that of both unemployment and vacancies as shown in figures 1 and 2. This suggests that the DMP model with neutral technological shocks as the main driver may be an appropriate framework, or at least one that is not rejected by these data.
Second, there is substantial variation in the degree of correlation between productivity and unemployment and vacancies. While this correlation is mostly negative, it is positive in countries like Spain or Australia. This fact, in contrast to the previous one, casts some doubt on the importance of technology shocks in accounting for labor market volatility, at least for countries like Spain, which exhibit the opposite sign correlation between productivity and labor market variables relative to what the model would imply.
Finally, while vacancies and unemployment tend to be equally persistent across countries, vacancies are on average 60% more volatile than unemployment. Something one would not be able to tell just by looking at U.S. data where they have roughly the same volatility. In section 5.2 we will have something more to say about why this is the case.
3 Model
We use an aggregate, stochastic, discrete time version of the DMP model akin to the one used in Shimer (2005). Each country is a closed economy and even though the calibration below is country-specific, in detailing the model, we abstract from country-indexing to make the notation easier to follow.
There is an underlying exogenous productivity process
![]() that evolves according to an AR(1) process
that evolves according to an AR(1) process
![]() , where
, where
![]() .
.
The economy is populated by two types of risk-neutral, infinitely-lived agents, both in a measure one continuum: workers and firms. Workers have preferences defined over stochastic streams of income
![]() which they discount at rate
which they discount at rate
![]() . They maximize their expected lifetime utility
. They maximize their expected lifetime utility
![]() .
.
At any point in time a worker is either matched with a firm or not. Unmatched workers are said to be unemployed and search for jobs while receiving a utility flow of ![]() . Matched workers are
said to be employed and while they are not allowed to search, they earn a period wage
. Matched workers are
said to be employed and while they are not allowed to search, they earn a period wage ![]() . This wage rate is the outcome of a generalized Nash bargaining problem where firms and workers
bargain over the match surplus. We let the worker's bargaining power be denoted by
. This wage rate is the outcome of a generalized Nash bargaining problem where firms and workers
bargain over the match surplus. We let the worker's bargaining power be denoted by
![]() . Firms and workers get separated with probability
. Firms and workers get separated with probability ![]() . Firms are free
to enter the market but have to pay a vacancy posting cost of
. Firms are free
to enter the market but have to pay a vacancy posting cost of ![]() to be able to obtain a match.
to be able to obtain a match.
Let ![]() denote the measure of vacancies posted, and
denote the measure of vacancies posted, and ![]() denote the measure of
employed people. Then,
denote the measure of
employed people. Then, ![]() denotes the unemployment rate. The vacancy-to-unemployment ratio,
denotes the unemployment rate. The vacancy-to-unemployment ratio,
![]() , or market tightness, will turn out to be a key variable in the model, as it fully describes the state of the economy. We assume the flow of new matches is given by a
Cobb-Douglas function
, or market tightness, will turn out to be a key variable in the model, as it fully describes the state of the economy. We assume the flow of new matches is given by a
Cobb-Douglas function
![]() . The rate at which workers find a new job is:
. The rate at which workers find a new job is:
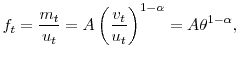
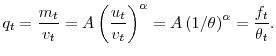
Employment evolves according to
![]() while unemployment's law of motion is
while unemployment's law of motion is
![]() . In this model, there exists a unique equilibrium in which the vacancy-to-unemployment ratio, and consequently all other variables, depends exclusively on
. In this model, there exists a unique equilibrium in which the vacancy-to-unemployment ratio, and consequently all other variables, depends exclusively on
![]() and not on
and not on ![]() , as shown in Mortensen and Nagypal (2007).
This is the equilibrium we focus on.
, as shown in Mortensen and Nagypal (2007).
This is the equilibrium we focus on.
The value of a filled position for a firm is given by:
The value of a job for a worker is:
The firms' free entry condition implies that, in equilibrium, entry will occur until the value of a vacancy is driven all the way down to zero: ![]() for all
for all ![]() . This means the match surplus is given by
. This means the match surplus is given by
![]() . Given the Nash bargaining weights, this means the firm gets
. Given the Nash bargaining weights, this means the firm gets
![]() , and the worker gets
, and the worker gets
![]() . Noting that the free entry condition implies
. Noting that the free entry condition implies
![]() , this means that
, this means that
![]() Finally, replacing this and the free entry condition into the value of a filled position for a firm yields a first-order difference
equation that can be used to compute the equilibrium:
Finally, replacing this and the free entry condition into the value of a filled position for a firm yields a first-order difference
equation that can be used to compute the equilibrium:
![\displaystyle \frac{c}{\delta q(p_t)}=E_t\left[(1-\delta)(p_{t+1}-z)-\beta c \theta(p_{t+1})+(1-s)\frac{c}{q(p_{t+1})}\right].](img34.gif)
4 Calibration
As we discuss in section 1, the model's ability to replicate the data will ultimately depend on modeling extensions and on the calibration details. Here, to establish a benchmark for each country against which to test potential solutions to the puzzle we use the same calibration method as in Shimer (2005). We will call this the standard calibration.
While most of the parameters are country specific, some are common across countries. In particular, we choose a model period to be a week and we set ![]() , the discount rate, such as to
generate a yearly interest rate of of 4%. The standard calibration uses the Hosios condition, which in the context of our model means
, the discount rate, such as to
generate a yearly interest rate of of 4%. The standard calibration uses the Hosios condition, which in the context of our model means
![]() . Although there are a wealth of studies estimating matching functions across different countries, not all the countries in our sample, as far as we could find, were the subject
of such studies, and more importantly, different studies often use different underlying data, estimation methods, etc., making it hard to compare across countries.6 As a result we set
. Although there are a wealth of studies estimating matching functions across different countries, not all the countries in our sample, as far as we could find, were the subject
of such studies, and more importantly, different studies often use different underlying data, estimation methods, etc., making it hard to compare across countries.6 As a result we set
![]() for all countries, the value Shimer (2005) estimates for the U.S. using his constructed job-finding rate and the vacancy-to-unemployment ratio
constructed by the BLS from the CPS.
for all countries, the value Shimer (2005) estimates for the U.S. using his constructed job-finding rate and the vacancy-to-unemployment ratio
constructed by the BLS from the CPS.
The remaining parameters are set on a country-by-country basis. The data on replacement rates, ![]() , are from the OECD and capture the average total benefit payable in a year of
unemployment in 2009. Even though the OECD measures compute net (not gross) replacement rates and try to take into account housing and child support related benefits, comparisons across countries may not be warranted for the reasons laid out in Whiteford (1995). Again, recall
that the goal of the exercise is not a cross-country comparison, but a comparison country-by-country between data and simulated data.
, are from the OECD and capture the average total benefit payable in a year of
unemployment in 2009. Even though the OECD measures compute net (not gross) replacement rates and try to take into account housing and child support related benefits, comparisons across countries may not be warranted for the reasons laid out in Whiteford (1995). Again, recall
that the goal of the exercise is not a cross-country comparison, but a comparison country-by-country between data and simulated data.
The separation and job-finding rates, ![]() and
and ![]() , are from Hobijn (2009) who use data on job-tenure and unemployment duration to obtain their estimates.7 Since the level of the vacancy-to-unemployment
ratio is meaningless in this calibration of the model, we normalize its steady-state value to to one, which means setting
, are from Hobijn (2009) who use data on job-tenure and unemployment duration to obtain their estimates.7 Since the level of the vacancy-to-unemployment
ratio is meaningless in this calibration of the model, we normalize its steady-state value to to one, which means setting ![]() . Normalizing the steady-state value of productivity
. Normalizing the steady-state value of productivity
![]() , we can recover the vacancy posting cost,
, we can recover the vacancy posting cost, ![]() , from the analogue of
(1) in steady-state.
, from the analogue of
(1) in steady-state.
Finally, the parameters governing productivity's law of motion, ![]() and
and
![]() , are set such that the autocorrelation and the standard deviation of H-P filtered productivity in the model and the data is the same for each country. The model does
not account for movements in and out of the labor force, as it assumes the labor force to be constant. Therefore, our variables should be adjusted by the labor force. When we do that, the statistics we obtain hardly change, as most labor force movements tend to be of relatively low frequency and
are therefore filtered out. The calibrated parameters are summarized in table 4.
, are set such that the autocorrelation and the standard deviation of H-P filtered productivity in the model and the data is the same for each country. The model does
not account for movements in and out of the labor force, as it assumes the labor force to be constant. Therefore, our variables should be adjusted by the labor force. When we do that, the statistics we obtain hardly change, as most labor force movements tend to be of relatively low frequency and
are therefore filtered out. The calibrated parameters are summarized in table 4.
5 Results: cross-country performance
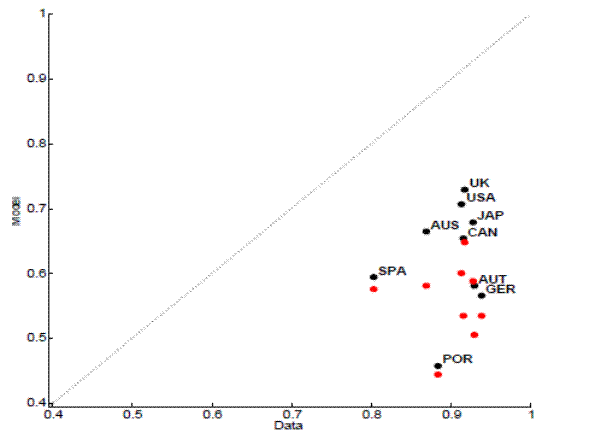
The model's strengths and weaknesses in being able to replicate cross-country data are very similar to those regarding its ability to replicate U.S. data. It does a good job of matching the persistence in unemployment, as shown in figure 4, but it systematically underpredicts the persistence in vacancies (figure 5). This well known shortcoming can be addressed by considering extensions to the model that add mechanisms that slow the adjustment in vacancies, like in Fujita and Ramey (2007).
The model also systematically overpredicts the (absolute) correlation between productivity and labor market variables, as figure 6 shows for unemployment.8 Finally, another dimension along which the model does a good job is at capturing the correlation between unemployment and vacancies, the unconditional average slope of the Beveridge curve, as shown in figure 7.
The DMP model's transmission mechanism is such that when there is a positive productivity shock vacancies should go up (as the value of an unfilled position increases since the expected match surplus also increases), wages should go up (as workers capture part of a match surplus that has increased) and unemployment should go down. While most of the data conforms to these correlation signs, there are some exceptions. In Australia and Poland, the correlation between productivity and unemployment is positive. In Spain both the correlation between productivity and unemployment and between productivity and vacancies have signs that are the opposite of what one would expect. This either means that shocks other than neutral productivity shocks are the main driver or that unmodelled frictions, like different labor market institutions, are of paramount importance in these countries. Justiniano and Michelacci (2011) take the former perspective in the context of an RBC model with search and matching frictions and allow for multiple shocks (neutral technology shocks, investment-specific shocks, discount factor shocks, search and matching technology shocks, job destruction shocks, and aggregate demand shocks) in 6 of these countries. They conclude that there is a lot of cross-country heterogeneity regarding the drivers of labor market-variables' fluctuations.
5.1 Cross-country lack of amplification
For all countries without exception, the model is unable replicate the volatility in labor market variables by an order of magnitude. This extends the finding of Shimer (2005) from the U.S. to a broad set of OECD countries. Tables 5 to 17 present the details for each country. While in the data the standard deviation of labor market tightness is higher than the standard deviation of productivity by a factor that averages 22.3, in the model the same factor averages 1.1. Similar results hold for the volatilities of unemployment and vacancies separately.
5.2 Targeting the cyclicality of wages
Another way the cross-sectional data can be of use is in helping evaluate the relative plausibility of the different resolutions for the volatility puzzle that have been suggested in the literature. Here we start by subjecting one of the most prominent proposals, the one in Hagedorn and Manovskii (2008), to this cross-country scrutiny.
Hagedorn and Manovskii (2008) think of the standard DMP model as an approximation to a more complex model economy with heterogeneous agents and curvature both in utility and in production. They suggest an alternative mapping between the data and a slightly modified version of the model above. Here we follow their work closely, and change the matching function to
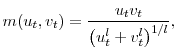
In addition, the vacancy posting cost is no longer constant and is the sum of a capital cost component and and a labor cost component that are both cyclical:
Regarding the mapping between data and model, while separation rates continue to be calibrated directly to their data counterpart, the same is not true of replacement rates. The idea being that the utility flow unemployed agents receive in the model, ![]() , stands in for more than measured replacement rates and include things like home production and leisure. The strategy is then to set values for parameters
, stands in for more than measured replacement rates and include things like home production and leisure. The strategy is then to set values for parameters ![]() ,
, ![]() , and
, and ![]() for each country, so as to
match the average job finding rate,
for each country, so as to
match the average job finding rate, ![]() , the average labor market tightness,
, the average labor market tightness, ![]() , and the elasticity of wages with respect to productivity that we obtain from the data,
, and the elasticity of wages with respect to productivity that we obtain from the data,
![]() .
.
The values for the average job-finding rate in each country, ![]() appear in table 4. To compute the average market tightness we use the fact that
appear in table 4. To compute the average market tightness we use the fact that
![]() . We don't have country specific data for the vacancy-filling rate
. We don't have country specific data for the vacancy-filling rate ![]() , so we use the value reported by Den Haan and Watson (2000),
, so we use the value reported by Den Haan and Watson (2000),
![]() for all countries.10 To compute the
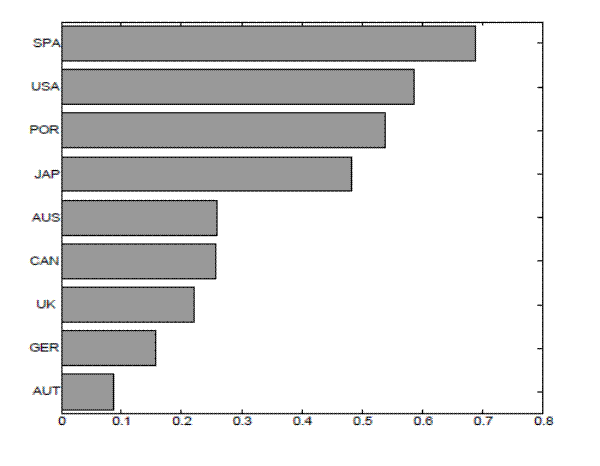
labor share of income we use OECD data. For each country and quarter we take employee compensation and subtract indirect taxes and then divide this by GDP minus indirect taxes.11 We then multiply this share by labor productivity; this gives us total wages per worker. We H-P filter this series and compute its elasticity with respect to productivity. The results appear in figure 3 for all the countries in our sample for which
data was available. The measure varies substantially across countries, from near acyclicality in Austria to a relatively strong procyclicality in Spain.
for all countries.10 To compute the
labor share of income we use OECD data. For each country and quarter we take employee compensation and subtract indirect taxes and then divide this by GDP minus indirect taxes.11 We then multiply this share by labor productivity; this gives us total wages per worker. We H-P filter this series and compute its elasticity with respect to productivity. The results appear in figure 3 for all the countries in our sample for which
data was available. The measure varies substantially across countries, from near acyclicality in Austria to a relatively strong procyclicality in Spain.
The calibration is able to match all targets and the business-cycle statistics are shown from tables 18 to 26. While the model, under this calibration strategy, is more than able to account for the volatility of labor market variables in most countries, it is unable to do so for others, notably Portugal and Spain. Moreover, the model overpredicts the volatility of labor market variables for other countries, like Japan and the U.K.
As a first pass at understanding more precisely why this calibration strategy may fail to work, we conduct some counterfactual experiments. We take a country's set of parameters and conduct sensitivity analysis with respect to some of its parameters. Table 26
summarizes the results. Each row shows the model's resulting labor market volatility - the standard deviations of unemployment vacancies and tightness - as well as a comparison of model moments and targets - steady-state job finding rates, steady-state tightness, and wage elasticities,
distinguished by subscript: an ![]() for model and a
for model and a ![]() for target. The shaded rows
indicate the benchmark calibration where model moments exactly match the targets.
for target. The shaded rows
indicate the benchmark calibration where model moments exactly match the targets.
The implied volatility of market variables for Portugal is way below the data's, but if we replace its first-order auto-regressive parameter for the productivity process, ![]() with that of
the U.S., the resulting volatilities increase substantially and are much more aligned with the data. When we do this, the elasticity of wages becomes counterfactually high, though. Nonetheless, this suggests that the productivity shock's autocorrelation may play an important role. At the same time,
Portugal's extremely low job finding rate suggests that the volatility in productivity shocks may not necessarily translate into volatility in vacancies.
with that of
the U.S., the resulting volatilities increase substantially and are much more aligned with the data. When we do this, the elasticity of wages becomes counterfactually high, though. Nonetheless, this suggests that the productivity shock's autocorrelation may play an important role. At the same time,
Portugal's extremely low job finding rate suggests that the volatility in productivity shocks may not necessarily translate into volatility in vacancies.
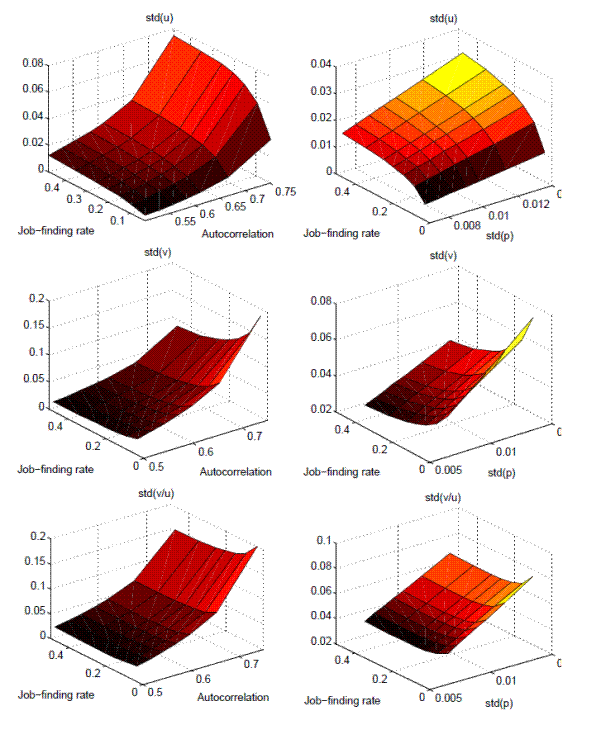
To verify these conjectures more precisely we generate a series of simulated economies that differ only in their average job finding rates, ![]() , and in their unconditional first-order
auto-correlation of the productivity process.12 Other than this, the parameters are calibrated to common targets (eg. separation rate, wage elasticity).
, and in their unconditional first-order
auto-correlation of the productivity process.12 Other than this, the parameters are calibrated to common targets (eg. separation rate, wage elasticity).
The first column of figure 11 reports the resulting volatility in labor market variables for each of these economies. The top panel shows that while an economy with a job finding rate of 3.5% (Portugal is at 3.9%) and a first order auto-correlation of 0.5 (Portugal is at 0.46) generates a standard deviation of unemployment of 0.0037, an economy with the U.S. job finding rate, 48%, and first order auto-correlation, 0.75, generates a standard deviation of unemployment of 0.0748. Therefore these two factors together can account for a factor of 20 in the standard deviation of unemployment.
The second panel in the first column shows that as far as the volatility of vacancies goes, the persistence of the productivity process can account for roughly a factor of 6, while variations in the job finding rate actually work the other way: economies with lower job finding rates actually exhibit higher volatility in vacancies, although not by a large factor.
We need to answer two questions. The first one is why do economies that exhibit more persistence in their productivity processes generate a larger volatility in labor market variables? The second one is why do economies with higher job finding rates exhibit higher volatility in unemployment but not in vacancies?
The answer to the first question is that given a positive productivity shock, the incentive for firms to post vacancies is stronger the more persistent the productivity process is, as expected profits from doing so are larger, and therefore the response of vacancies will be stronger. Given the same job finding rates and separation rates, unemployment will then decrease faster. This is precisely what we see in the impulse response functions (to a positive productivity shock) for vacancies and unemployment in figures 12 and 13.
The answer to the second question is that conditional on a positive productivity shock and on a given number of posted vacancies, unemployment will decrease by less the smaller the job finding rate is. On the other hand, because this reduces expected profits for firms, more vacancies will be posted when the job finding rate is smaller, conditional on everything else.
The HM calibration also leads to counterfactually low volatilities for Spain. Going back to table 26 we again see that replacing the Spanish ![]() with that of
the U.S. goes a long way in increasing those volatilities. Note though, from table 18 that Spain and Germany have very similar
with that of
the U.S. goes a long way in increasing those volatilities. Note though, from table 18 that Spain and Germany have very similar ![]() , and the model seems to do a
lot better for Germany. Why is this so? Partly because Germany's calibration involves a much higher replacement rate
, and the model seems to do a
lot better for Germany. Why is this so? Partly because Germany's calibration involves a much higher replacement rate ![]() . But this is not the whole story, as increasing
. But this is not the whole story, as increasing ![]() helps increase Spain's volatility of vacancies but not the volatility of unemployment. We can only increase both when we increase the standard dev of the productivity shock,
helps increase Spain's volatility of vacancies but not the volatility of unemployment. We can only increase both when we increase the standard dev of the productivity shock, ![]() at the same time as the replacement rate.
at the same time as the replacement rate.
Turning now to the country's for which the Hm calibration results in over-prediction of volatility of labor market variables we note from table 18 that Japan and Canada have very similar replacement rates ![]() , but volatilities seem in line with the data for the Canadian case. Table 26 shows that reducing the variance of the productivity shock to Canada's level goes a long way in bringing the volatility down.
, but volatilities seem in line with the data for the Canadian case. Table 26 shows that reducing the variance of the productivity shock to Canada's level goes a long way in bringing the volatility down.
Finally, the U.K.'s implied replacement rate is the highest in the sample. Reducing it to the U.S. level brings down labor market volatilities to levels that are commensurate with what we see in the data.
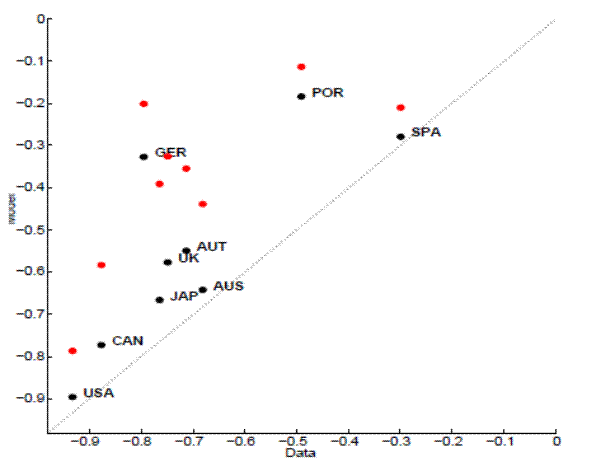
While the HM calibration is successful (with the caveats noted above) in bringing the model closer to the data along the labor market volatility dimension, it fails to do so along other dimensions. Figures 11-14, are the analogues of figures 4-7 under the HM calibration. Its performance in terms of the persistence of labor market variables and the correlation of unemployment and vacancies is worse than the standard model's, while it does marginally better regarding the correlation of productivity with unemployment and vacancies (figure not shown).
6 Conclusion
Cross-country data can be used as a tool to better understand the dimensions along which search and matching models can successfully approximate relevant business-cycle moments. We start by establishing that the model's inability to deliver the sort of volatility in labor market variables present in the data extends beyond the U.S. and to a large set of OECD countries. We go on to show that the model, at least with technology shocks as the main driver, has no hope of capturing the mechanics of labor markets in some countries where the correlations implied by the model's transmission mechanism are contradicted by the data.
To further illustrate how useful this cross-country scrutiny can be, we modify the standard model as proposed by Hagedorn and Manovskii (2008) and show that while the model's ability to match the labor market variables' volatility observed in the data improves substantially, this improvement in not ubiquitous. In particular it does not work for economies that have sufficiently small job-finding rates and/or productivity processes that are not persistent enough. Moreover, this modification fails to improve the model's cross-country performance along other margins.
Our findings cast some doubt on the DMP model's usefulness to serve as the workhorse of labor market research at business-cycle frequencies for two reasons. The first one is that some countries exhibit sets of moments that are in plain disagreement with the model's basic mechanisms; the second one is that extensions of the basic model seem to work for some countries, but not others, while not improving matters along other margins (which, granted, they were not designed to do so). These findings lead one to think that looking for shocks (other than productivity) that may be impinging on the labor market, as in Justiniano and Michelacci (2011) may be a promising line of research.
Nonetheless, the Hagedorn and Manovskii (2008) framework is one of many that have been proposed in the literature to try to reconcile the predictions of the DMP model with the data. In future work we plan to look at others, like rigid wages as in Shimer (2004), Hall (2005), or Kennan (2010), labor turnover costs, as in Silva (2009), on-the-job search, as in Nagypal (2006) Krause (2006), or Tasci (2007), and financial frictions, as in Petrosky-Nadeau and Wasmer (2010).
Bibliography
"European Unemployment: The Evolution of Facts and Ideas," Economic Policy, 21, 5-59.![Figure 1: Productivity and unemployment. The figure is a scatterplot of the volatility of productivity and unemployment. On a scatterplot, each point represents a country in the sample, with the y-axis equal to the std(u) and the x-axis equal to the std(p). The y-axis ranges from 0 to 0.2, while the x-axis ranges from 0 to 0.025. Since the cloud of points tends to slop downward from left to right, the relationship between the volatility of productivity and unemployment is negative. However, it is positive in countries like Spain and Australia. This suggests that as std (p) increases std (u) tends to decrease. There is a clump around [0.01,0.1]. Other data points like Germany, Finland, Norway and Czech are scattered around [0.013, 0.2] and [0.023, 0.15].](figure1.gif)
![Figure 2: Productivity and vacancies. The figure displays a scatterplot of the volatility of productivity and vacancies. On a scatter plot, each point represents a country in the sample, with the y-axis equal to stu(v) and the x-axis equal to the std(p). The y-axis ranges from 0.05 to 0.3, while the x-axis ranges from 0 to 0.025. The cloud of points tends to slope upward from left to right, implying that there is a fairly strong positive cross-country correlation between the volatility of productivity and that of vacancies. The points are clustered closely around [0.01, 0.15]. There is an outlier, which is Czech Rep [0.023, 0.3].](figure2.gif)
| Countries | Start Date | End Date | Std. Dev. | Autocorr. |
| Australia | Q2-1979 | Q3-2011 | 0.1642 | 0.8689 |
| Austria | Q1-1955 | Q3-2011 | 0.1577 | 0.9251 |
| Canada | Q1-1962 | Q3-2011 | 0.1545 | 0.9155 |
| Czech Rep. | Q1-1991 | Q2-2011 | 0.2649 | 0.9132 |
| Finland | Q1-1961 | Q2-2010 | 0.2385 | 0.8948 |
| Germany | Q1-1962 | Q2-2010 | 0.1954 | 0.9387 |
| Japan | Q2-1967 | Q4-2011 | 0.1254 | 0.9303 |
| Norway | Q1-1955 | Q3-2011 | 0.1874 | 0.8803 |
| Poland | Q1-1990 | Q2-2011 | 0.1824 | 0.8524 |
| Portugal | Q1-1974 | Q3-2011 | .2588 | 0.8927 |
| Spain | Q1-1977 | Q1-2005 | 0.2065 | 0.8031 |
| U.K. | Q3-1958 | Q3-2011 | 0.1991 | 0.9205 |
| U.S. | Q1-1955 | Q3-2011 | 0.1353 | 0.9036 |
| Countries | Start date | End date | Std. dev. | Autocorr. |
| Australia | Q1-1964 | Q2-2011 | 0.1100 | 0.8424 |
| Austria | Q1-1969 | Q2-2011 | 0.1098 | 0.6433 |
| Canada | Q1-1955 | Q3-2011 | 0.1069 | 0.8785 |
| Czech Rep. | Q1-1990 | Q2-2011 | 0.2535 | 0.6704 |
| Finland | Q1-1958 | Q4-2010 | 0.1872 | 0.8856 |
| Germany | Q1-1956 | Q2-2011 | 0.1985 | 0.9188 |
| Japan | Q1-1955 | Q2-2011 | 0.0699 | 0.7993 |
| Norway | Q1-1972 | Q2-2011 | 0.1564 | 0.7573 |
| Poland | Q4-1991 | Q2-2011 | 0.1223 | 0.9352 |
| Portugal | Q1-1983 | Q2-2011 | 0.0994 | 0.9155 |
| Spain | Q1-1977 | Q2-2011 | 0.0842 | 0.9405 |
| U.K. | Q1-1971 | Q2-2011 | 0.1163 | 0.9320 |
| U.S. | Q1-1955 | Q3-2011 | 0.1177 | 0.8994 |
| Countries | Start date | End date | Std. dev. | Autocorr. |
| Australia | Q1-1964 | Q2-2011 | 0.0118 | 0.5541 |
| Austria | Q1-1960 | Q2-2011 | 0.0104 | 0.6239 |
| Canada | Q1-1960 | Q2-2011 | 0.0090 | 0.7111 |
| Czech Rep. | Q1-1994 | Q2-2011 | 0.0214 | 0.7282 |
| Finland | Q1-1960 | Q2-2011 | 0.0159 | 0.6774 |
| Germany | Q1-1960 | Q2-2011 | 0.0112 | 0.5918 |
| Japan | Q1-1960 | Q2-2011 | 0.0143 | 0.7385 |
| Norway | Q1-1960 | Q2-2011 | 0.0124 | 0.5472 |
| Poland | Q1-1995 | Q2-2011 | 0.0102 | 0.4515 |
| Portugal | Q2-1983 | Q2-2011 | 0.0112 | 0.4684 |
| Spain | Q3-1972 | Q2-2011 | 0.0078 | 0.6428 |
| U.K. | Q1-1960 | Q2-2011 | 0.0119 | 0.7322 |
| U.S. | Q1-1960 | Q2-2011 | 0.0093 | 0.7544 |
| Countries | Replacement | Separation | Job-Finding |
| Australia | 0.5353 | 0.0175 | 0.1705 |
| Austria | 0.6182 | 0.0106 | 0.1561 |
| Canada | 0.5535 | 0.0178 | 0.2890 |
| Czech Rep. | 0.5535 | 0.0094 | 0.0806 |
| Finland | 0.6984 | 0.0138 | 0.1336 |
| Germany | 0.6375 | 0.0106 | 0.0698 |
| Japan | 0.7459 | 0.0060 | 0.1907 |
| Norway | 0.7068 | 0.0134 | 0.3053 |
| Poland | 0.4617 | 0.0099 | 0.0720 |
| Portugal | 0.6042 | 0.0096 | 0.0388 |
| Spain | 0.4726 | 0.0203 | 0.0398 |
| U.K. | 0.6142 | 0.0153 | 0.1127 |
| U.S. | 0.3346 | 0.0260 | 0.4772 |
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.095 | 0.165 | 0.240 | 0.010 | 0.003 | 0.015 | 0.017 | 0.010 |
| Autocorr. | 0.907 | 0.869 | 0.903 | 0.719 | 0.879 | 0.664 | 0.719 | 0.719 |
| Correlation:u | 1 | -0.681 | -0.864 | 0.056 | 1 | -0.642 | -0.747 | -0.747 |
| Correlation:v | - | 1 | 0.957 | 0.230 | - | 1 | 0.989 | 0.989 |
| Correlation:v/u | - | - | 1 | 0.136 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1979 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.110 | 0.163 | 0.254 | 0.011 | 0.003 | 0.015 | 0.017 | 0.011 |
| Autocorr. | 0.643 | 0.929 | 0.879 | 0.639 | 0.854 | 0.582 | 0.640 | 0.640 |
| Correlation:u | 1 | -0.713 | -0.892 | -0.387 | 1 | -0.550 | -0.667 | -0.667 |
| Correlation:v | - | 1 | 0.953 | 0.480 | - | 1 | 0.989 | 0.989 |
| Correlation:v/u | - | - | 1 | 0.477 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1969 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.091 | 0.155 | 0.239 | 0.009 | 0.004 | 0.014 | 0.017 | 0.009 |
| Autocorr. | 0.888 | 0.916 | 0.919 | 0.717 | 0.838 | 0.653 | 0.718 | 0.718 |
| Correlation:u | 1 | -0.876 | -0.950 | -0.247 | 1 | -0.772 | -0.856 | -0.856 |
| Correlation:v | - | 1 | 0.983 | 0.299 | - | 1 | 0.990 | 0.989 |
| Correlation:v/u | - | - | 1 | 0.288 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1962 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.137 | 0.275 | 0.399 | 0.021 | 0.003 | 0.018 | 0.017 | 0.021 |
| Autocorr. | 0.927 | 0.927 | 0.931 | 0.728 | 0.944 | 0.684 | 0.728 | 0.727 |
| Correlation:u | 1 | -0.867 | -0.939 | -0.435 | 1 | -0.512 | -0.619 | -0.619 |
| Correlation:v | - | 1 | 0.985 | 0.631 | - | 1 | 0.991 | 0.991 |
| Correlation:v/u | - | - | 1 | 0.583 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1994 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.187 | 0.238 | 0.407 | 0.016 | 0.005 | 0.028 | 0.031 | 0.016 |
| Autocorr. | 0.899 | 0.895 | 0.915 | 0.665 | 0.874 | 0.615 | 0.665 | 0.665 |
| Correlation:u | 1 | -0.826 | -0.944 | -0.282 | 1 | -0.532 | -0.645 | -0.645 |
| Correlation:v | - | 1 | 0.966 | 0.408 | - | 1 | 0.990 | 0.990 |
| Correlation:v/u | - | - | 1 | 0.369 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1961 : Q2-2010 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.199 | 0.195 | 0.373 | 0.011 | 0.001 | 0.010 | 0.011 | 0.011 |
| Autocorr. | 0.921 | 0.939 | 0.938 | 0.591 | 0.884 | 0.566 | 0.591 | 0.591 |
| Correlation:u | 1 | -0.794 | -0.948 | -0.376 | 1 | -0.327 | -0.417 | -0.417 |
| Correlation:v | - | 1 | 0.946 | 0.445 | - | 1 | 0.995 | 0.995 |
| Correlation:v/u | - | - | 1 | 0.433 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1962 : Q2-2010 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.066 | 0.123 | 0.179 | 0.014 | 0.010 | 0.038 | 0.045 | 0.014 |
| Autocorr. | 0.799 | 0.928 | 0.909 | 0.727 | 0.883 | 0.679 | 0.739 | 0.739 |
| Correlation:u | 1 | -0.764 | -0.896 | -0.461 | 1 | -0.667 | -0.776 | -0.776 |
| Correlation:v | - | 1 | 0.971 | 0.612 | - | 1 | 0.987 | 0.987 |
| Correlation:v/u | - | - | 1 | 0.592 | - | - | 1 | 0.999 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1967 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.156 | 0.187 | 0.328 | 0.013 | 0.006 | 0.023 | 0.027 | 0.013 |
| Autocorr. | 0.757 | 0.877 | 0.879 | 0.501 | 0.708 | 0.413 | 0.502 | 0.502 |
| Correlation:u | 1 | -0.828 | -0.948 | -0.038 | 1 | -0.668 | -0.777 | -0.777 |
| Correlation:v | - | 1 0.964 | 0.056 | - | 1 | 0.987 | 0.987 | |
| Correlation:v/u | - | - | 1 | 0.050 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1972 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.132 | 0.168 | 0.253 | 0.010 | 0.000 | 0.004 | 0.004 | 0.010 |
| Autocorr. | 0.948 | 0.862 | 0.925 | 0.451 | 0.843 | 0.425 | 0.451 | 0.451 |
| Correlation: u | 1 | -0.416 | -0.797 | 0.244 | 1 | -0.277 | -0.362 | -0.362 |
| Correlation:v | - | 1 | 0.881 | 0.271 | - | 1 | 0.996 | 0.996 |
| Correlation:v/u | - | - | 1 | 0.052 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1995 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.099 | 0.188 | 0.251 | 0.011 | 0.000 | 0.004 | 0.004 | 0.011 |
| Autocorr. | 0.915 | 0.884 | 0.908 | 0.468 | 0.872 | 0.456 | 0.467 | 0.467 |
| Correlation:u | 1 | -0.491 | -0.760 | -0.082 | 1 | -0.183 | -0.236 | -0.236 |
| Correlation:v | - | 1 | 0.940 | 0.282 | - | 1 | 0.999 | 0.998 |
| Correlation:v/u | - | - | 1 | 0.243 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1983 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.059 | 0.206 | 0.231 | 0.007 | 0.000 | 0.004 | 0.004 | 0.007 |
| Autocorr. | 0.941 | 0.803 | 0.831 | 0.605 | 0.900 | 0.594 | 0.606 | 0.605 |
| Correlation:u | 1 | -0.299 | -0.523 | 0.472 | 1 | -0.279 | -0.333 | -0.332 |
| Correlation:v | - | 1 | 0.970 | -0.076 | - | 1 | 0.998 | 0.998 |
| Correlation:v/u | - | - | 1 | -0.188 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1977 : Q1-2005 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.116 | 0.196 | 0.293 | 0.012 | 0.005 | 0.024 | 0.027 | 0.012 |
| Autocorr. | 0.932 | 0.918 | 0.926 | 0.767 | 0.920 | 0.728 | 0.768 | 0.767 |
| Correlation:u | 1 | -0.749 | -0.897 | -0.185 | 1 | -0.577 | -0.683 | -0.683 |
| Correlation:v | - | 1 | 0.965 | 0.625 | - | 1 | 0.991 | 0.990 |
| Correlation:v/u | - | - | 1 | 0.491 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1971 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.115 | 0.132 | 0.243 | 0.009 | 0.003 | 0.010 | 0.013 | 0.009 |
| Autocorr. | 0.915 | 0.913 | 0.920 | 0.754 | 0.815 | 0.707 | 0.754 | 0.754 |
| Correlation:u | 1 | -0.932 | -0.980 | -0.242 | 1 | -0.897 | -0.940 | -0.940 |
| Correlation:v | - | 1 | 0.985 | 0.408 | - | 1 | 0.994 | 0.994 |
| Correlation:v/u | - | - | 1 | 0.337 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1960 : Q2-2011 | |||||||
![Figure 4: Unemployment autocorrelation. The figure 4 illustrates a scatterplot. On a scatter plot, each point indicates a country in the sample. The y-axis on the scatter plot is labeled, Model and ranges from 0.6 to 1. The x-axis on the scatter plot is labeled, Data and ranges from 0.6 to 0.95. The solid grey line of 45 degree angle represents a regression line with a positive slope. The overall shape of the relationship is linear (data points are scattered about a regression line). 11 out of 14 data points cluster around the regression line [0.91, 0.9] and tend to move upward from left to right. Therefore, there is a strong positive association exists between these two variables (Data vs. Model). The other data points, including Japan, Norway and Austria, are scattered farther from the line. Japan and Austria lie above the line while Norway lies below the line.](figure4.gif)
![Figure 5: Vacancies autocorrelation. The figure 5 displays a scatterplot. On a scatter plot, each point denotes a country in the sample. The y-axis on the scatter plot labeled, Model and ranges from 0.4 to 1. The x-axis on the scatter plot labeled,Data and ranges from 0.4 to 0.9. The solid grey line of 45 degree angle represents a regression line with a positive slope. All data points lie below the regression line. The data points are mostly clumped, with groups of points about [0.9, 0.6] and [0.9, 0.5].](figure5.gif)
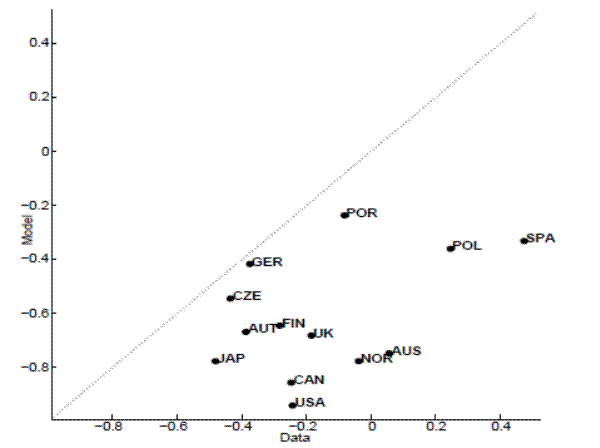
![Figure 7: Unemployment-vacancies correlation. The figure 7 shows a scatterplot of the unemployment-vacancies correlation, with the x-axis equal to Model and the y-axis equal to Data. The x-axis ranges from -0.9 to -0.2 and the y-axis also ranges from -0.9 to -0.2. Again, each data point indicates a country in the sample. The solid grey line of 45 degree angle represents a regression line with a positive slope. All the data points lie above the regression line and generally follow an upward sloping line. Among these points, Spain, USA and Australia points are scattered close to the regression line. Other points such as Austria, Japan, Norway, Canada, Finland and UK are clustered tightly around the line [-0.7,-0.6].](figure7.gif)
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.095 | 0.165 | 0.240 | 0.010 | 0.108 | 0.202 | 0.268 | 0.010 |
| Autocorr. | 0.907 | 0.869 | 0.903 | 0.719 | 0.879 | 0.582 | 0.713 | 0.719 |
| Correlation:u | 1 | -0.681 | -0.864 | 0.056 | 1 | -0.440 | -0.734 | -0.740 |
| Correlation:v | - | 1 | 0.957 | 0.230 | - | 1 | 0.932 | 0.905 |
| Correlation:v/u | - | - | 1 | 0.136 | - | - | 1 | 0.981 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1979 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.110 | 0.163 | 0.254 | 0.011 | 0.078 | 0.161 | 0.202 | 0.011 |
| Autocorr. | 0.643 | 0.929 | 0.879 | 0.639 | 0.853 | 0.505 | 0.636 | 0.639 |
| Correlation:u | 1 | -0.713 | -0.892 | -0.387 | 1 | -0.354 | -0.665 | -0.668 |
| Correlation:v | - | 1 | 0.953 | 0.480 | - | 1 | 0.933 | 0.923 |
| Correlation:v/u | - | - | 1 | 0.477 | - | - | 1 | 0.993 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1969 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.091 | 0.155 | 0.239 | 0.009 | 0.101 | 0.142 | 0.217 | 0.009 |
| Autocorr. | 0.888 | 0.916 | 0.919 | 0.717 | 0.838 | 0.535 | 0.713 | 0.717 |
| Correlation:u | 1 | -0.876 | -0.950 | -0.247 | 1 | -0.583 | -0.846 | -0.843 |
| Correlation:v | - | 1 | 0.983 | 0.299 | - | 1 | 0.926 | 0.907 |
| Correlation:v/u | - | - | 1 | 0.288 | - | - | 1 | 0.986 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1962 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.199 | 0.195 | 0.373 | 0.011 | 0.037 | 0.139 | 0.151 | 0.011 |
| Autocorr. | 0.921 | 0.939 | 0.938 | 0.591 | 0.882 | 0.533 | 0.588 | 0.589 |
| Correlation:u | 1 | -0.794 | -0.948 | -0.376 | 1 | -0.201 | -0.428 | -0.429 |
| Correlation:v | - | 1 | 0.946 | 0.445 | - | 1 | 0.971 | 0.967 |
| Correlation:v/u | - | - 1 | 0.433 | - | - | 1 | 0.997 | |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1962 : Q2-2010 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.066 | 0.123 | 0.179 | 0.014 | 0.172 | 0.325 | 0.422 | 0.014 |
| Autocorr. | 0.799 | 0.928 | 0.909 | 0.727 | 0.889 | 0.588 | 0.718 | 0.738 |
| Correlation:u | 1 | -0.764 | -0.896 | -0.461 1 | -0.391 | -0.710 | -0.731 | |
| Correlation:v | - | 1 | 0.971 | 0.612 | - | 1 | 0.925 | 0.832 |
| Correlation:v/u | - | - | 1 | 0.592 | - | - | 1 | 0.936 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1967 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.099 | 0.188 | 0.251 | 0.011 | 0.005 | 0.031 | 0.032 | 0.011 |
| Autocorr. | 0.915 | 0.884 | 0.908 | 0.468 | 0.869 | 0.441 | 0.465 | 0.465 |
| Correlation:u | 1 | -0.491 | -0.760 | -0.082 | 1 | -0.113 | -0.251 | -0.251 |
| Correlation:v | - | 1 | 0.940 | 0.282 | - | 1 | 0.990 | 0.990 |
| Correlation:v/u | - | - | 1 | 0.243 | - | - | 1 | 0.999 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q2-1983 : Q2-2011 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.059 | 0.206 | 0.231 | 0.007 | 0.005 | 0.027 | 0.029 | 0.007 |
| Autocorr. | 0.941 | 0.803 | 0.831 | 0.605 | 0.897 | 0.576 | 0.606 | 0.606 |
| Correlation:u | 1 | -0.299 | -0.523 | 0.472 | 1 | -0.211 | -0.361 | -0.361 |
| Correlation:v | - | 1 | 0.970 | -0.076 | - | 1 | 0.988 | 0.987 |
| Correlation:v/u | - | - | 1 | -0.188 | - | - | 1 | 1.000 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1977 : Q1-2005 | |||||||
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | |
| Std. Dev. | 0.116 | 0.196 | 0.293 | 0.012 | 0.143 | 0.567 | 0.622 | 0.012 |
| Autocorr. | 0.932 | 0.918 | 0.926 | 0.767 | 0.922 | 0.647 | 0.715 | 0.768 |
| Correlation:u | 1 | -0.749 | -0.897 | -0.185 | 1 | -0.325 | -0.563 | -0.655 |
| Correlation:v | - | 1 | 0.965 | 0.625 | - | 1 | 0.962 | 0.791 |
| Correlation:v/u | - | - | 1 | 0.491 | - | - | 1 | 0.869 |
| Correlation:p | - | - | - | 1 | - | - | - | 1 |
| Dates: | Q1-1971 : Q2-2011 | |||||||
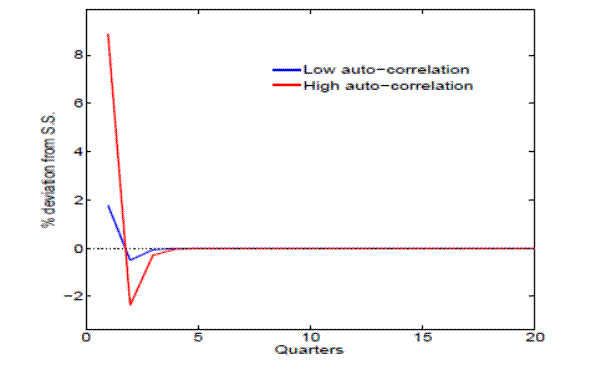
![Figure 10: Impulse response: unemployment. The single panel figure is a line graph with two lines. The y-axis is labeled, % deviation from s.s. and ranges from -3 to 0.5. The x-axis is labeled, Quarters and ranges from 0 to 20. The two lines are as follows: the blue line represents low auto-correlation and the red line represents high auto-correlation. The red line begins at the origin and goes linearly upwards to reach zero at the very left of the graph and remain constant. The blue line begins at [1,-0.7] and rises to reach zero at the very left of the graph and remain constant. Both lines increases rapidly until two lines converge (remain constant over time).](figure10.gif)
![Figure 11: Unemployment autocorrelation (HM calibration). The figure 11 is a scatterplot of unemployment autocorrelation with HM calibration, with the x-axis equal to Data and the y-axis equal to Model. Both x-axis and y-axis range from 0.6 to 1. Each data point (in black) characterizes a country in the sample. The red dots and the black dots overlap each other with the addition of HM calibration. The grey line of 45 degree angle represents a regression line that slopes upward to the right. Most of the data points except for Austria and Japan are below the regression line. The points below the line are clustered together at the very right side of the graph [0.9,0.9].](figure11.gif)
![figure13: Unemployment-productivity correlation (HM calibration). This single-panel displays a scatterplot with a regression line (in grey). The y-axis is labeled, Model,whereas the x-axis is labeled, Data. Both y-axis and x-axis range from -0.8 to 0.4. All data points are scattered farther from the regression line. They also lie below the regression line. Every data point is shown in black with a red dot plotted near each other (except for Austria). Canada, USA, Australia, Austria and Japan are clustered at around [-0.2, 0.6]. On the other hand, Spain is plotted farther from other points.](figure13.gif)
| Data:u | Data:v | Data:v/u | Data:p | Model:u | Model:v | Model: v/u | Model:p | ||
| Std. Dev. | 0.115 | 0.132 | 0.243 | 0.009 | 0.073 | 0.084 | 0.149 | 0.009 | |
| Autocorr. | 0.915 | 0.913 | 0.920 | 0.754 | 0.817 | 0.602 | 0.752 | 0.755 | |
| Correlation:u | 1 | -0.932 | -0.980 | -0.242 | 1 | -0.787 | -0.936 | -0.923 | |
| Correlation:v | - | 1 | 0.985 | 0.408 | - | 1 | 0.954 | 0.939 | |
| Correlation:v/u | - | - | 1 | 0.337 | - | - | 1 | 0.985 | |
| Correlation:p | - | - | - | 1 | - | - | - | 1 | |
| Dates: | Q1-1071: Q2-2011 | Q1-1960 : Q2-2011 | |||||||