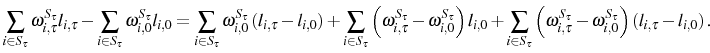Firm Dynamics with Infrequent Adjustment and Learning
Keywords: Adjustment costs, learning, young firms
Abstract:
We propose an explanation for the rapid post-entry growth of surviving firms found in recent studies. At the core of our theory is the interaction between adjustment costs and learning by entering firms about their efficiency. We show that linear adjustment costs, i.e., proportional costs, create incentives for firms to enter smaller and for successful firms to grow faster after entry. Initial uncertainty about profitability makes entering firms prudent since they want to avoid incurring superfluous costs on jobs that prove to be excessive ex post. Because higher adjustment costs imply less pruning of inefficient firms and faster growth of surviving firms, the contribution of survivors to growth in a cohort's average size increases. For the cohort of 1988 entrants in the Portuguese economy, we conclude that survivors' growth is the main factor behind growth in the cohort's average size. However, initial selection is higher and the survivors' contribution to growth is smaller in services than in manufacturing. An estimation of the model shows that the proportional adjustment cost is the key parameter to account for the high empirical survivors' contribution. In addition, firms in manufacturing learn relatively less initially about their efficiency and are subject to larger adjustment costs than firms in services.
JEL Classification: E24, L11, L16
1 Introduction
In recent years there has been renewed interest in explaining patterns of firm dynamics, with new longitudinal datasets confirming heterogeneities between firms of different size and age. In particular, small and young (surviving) firms tend to grow faster and have higher failure rates than large and old firms, and both job creation due to the scaling-up of firm size and job destruction due to firm exit decrease with age.2 Moreover, entering firms tend to be small, but survivors grow rapidly after entry and are the main factor behind the shift to the right of a cohort's size distribution.3 These patterns differ markedly across sectors and countries, suggesting that both technological differences and country specific factors matter.4
This paper proposes an explanation for the leading role of survivors' growth in post-entry firm dynamics based on the interaction between adjustment costs and a learning-about-efficiency mechanism. Following a literature that uses adjustment costs to account for some dynamic properties of firms' labor demand, such as Campbell and Fisher (2000) , we show that proportional costs can impact the lifetime dynamics of firms' labor demand in a way consistent with the data. To implement our theory, we use a standard model of firm dynamics with passive learning. In order to check the empirical fit of our model, we also assume that inefficient firms are pruned from the market, although the predictions of our theory hold even in the absence of a selection mechanism (e.g. when exit is not allowed).
Our contribution is twofold. First, we contribute to the empirical literature by introducing a decomposition of the change in a cohort's average size into a survivor component and a non-survivor component, and by using this decomposition as the centerpiece in a structural estimation of adjustment costs. Given the emphasis on survivors' growth, our measure allows a quick assessment of how well a particular theory matches the data in that respect. We apply our decomposition to the 1988 cohort of entrants in the Portuguese economy, using the Quadros de Pessoal dataset. Similarly to Cabral and Mata (2003) , we find that growth of survivors is the main force behind the change in the cohort's average firm size. However, we also find that growth of survivors is especially intense in the initial years after entry and that there are significant cross-sector differences in terms of our decomposition. In particular, initial exit rates are smaller and the survivors' contribution to changes in size is higher in manufacturing than in services.
Second, we contribute to the theoretical literature by introducing linear adjustment costs into a model of Bayesian learning about efficiency. Our assumption of linear or proportional costs is justified by the finding of high inaction rates in employment adjustment, in varying degrees across sectors. Our model builds on Jovanovic (1982) by adding proportional costs that apply not only to regular labor adjustment, but also to job creation at entry and job destruction at exit. We show that proportional adjustment costs create incentives for firms to start smaller and, if successful, grow faster after entry. We prove this analytically in a simplified model in which there is no exit of firms. This result shows that proportional costs can generate firm growth without selection. When firms are allowed to exit, selection intensifies the effects of adjustment costs on firm growth, while costs to adjustment reduce exit rates. Therefore, adjustment costs increase the contribution of surviving firms to growth in the cohort's average size.
All that is needed for firm growth under linear adjustment costs is the existence of a learning environment that generates a stochastic process for perceived efficiency with both persistence and decreasing uncertainty in age.5 The intuition for why firms grow faster and display smaller exit rates under proportional adjustment costs is that initial uncertainty about true profitability makes entering firms prudent; that is, they enter small and "wait and see" since they want to avoid incurring superfluous entering/hiring costs and firing/shutdown costs on jobs thatprove to be excessive ex post. This implies that surviving firms will grow faster, even though adjustment costs imply that there are fewer firms exiting the market and therefore less pruning of inefficient firms.
The assumption that entering firms face a Bayesian learning problem concerning their efficiency is standard in selection theories and has been advanced as an explanation for the high rates of exit, job creation, and job destruction among young firms. The initial literature on adjustment costs used a (strictly) convex specification in an attempt to explain the sluggishness in input responses to aggregate shocks. However, the assumption that costs of adjustment are linear is now standard in dynamic labor demand models, following a number of studies since the late 1980s that have documented the importance of inaction in employment adjustment at the micro level.6 Since strictly convex costs imply smooth adjustments over time, whereas linear costs imply immediate adjustment when it occurs, allowing for strictly convex costs, instead of linear costs, in the context where they also apply at entry and exit, would bias our analysis and eventually make our argument stronger. In the case of hiring/entering costs, entering firms would prefer to start smaller and adjust gradually to their optimal size, even if their perceived productivity remained unchanged or learning was absent. For firing/exiting costs, firms experiencing large declines in perceived productivity would adjust downwards in several steps, a scenario that would make firms start smaller to attenuate its effects. Therefore, by avoiding a bias towards firm growth, our decision to assume linear costs is conservative and permits a simplification of the methods employed to measure the effects of adjustment costs.7
To assess our model quantitatively, we calibrate and estimate a version of the model with finite learning horizon and positive dispersion in entry size. We conclude that linear costs are the key element to account for the high empirical contribution of survivors to changes in a cohort's average size. A calibration/estimation for the manufacturing and services cohorts also suggests that firms in manufacturing learn relatively less initially about their efficiency and are subject to substantially larger adjustment costs than firms in services.
This paper is related to the literature on both adjustment costs and firm dynamics. Within the literature on adjustment costs, the paper is associated with theories that use linear adjustment costs to explain certain aspects of the dynamic behavior of labor demand and job flows. Well-known examples are Bentolila and Bertola (1990) , Hopenhayn and Rogerson (1993) , and Campbell and Fisher (2000) . Bentolila and Bertola (1990) and Hopenhayn and Rogerson (1993) analyze the effects of proportional firing (and hiring) costs on the dynamics of hiring and firing decisions, and on average labor demand. Both papers conclude that high firing costs make hiring and firing adjustments more sluggish, but they disagree on the implications of that for long-run employment. Campbell and Fisher (2000) use proportional costs of job creation and job destruction to explain the higher aggregate volatility of job destruction found in the U.S. manufacturing sector. These costs imply that in reaction to aggregate wage shocks employment changes at contracting firms are larger than employment changes at expanding firms. What is new in our paper is the assumption that adjustment costs apply equally to the entry/exit decisions and the hiring/firing decisions.8
Within the literature on firm dynamics the paper is connected with theories that attempt to explain the stylized facts on the lifecycle dynamics outlined above. The two main explanations for these facts are theories based on selection of firms and theories based on financing constraints.9 Selection theories stress the tendency for firms that accumulate bad realizations of productivity to exit the market and for firms that accumulate good realizations to survive and expand. This implies a composition bias towards larger and more efficient firms as smaller, inefficient, and slow-growing firms gradually exit the industry. Representative papers of selection theories are Jovanovic (1982) , Hopenhayn (1992) , Ericson and Pakes (1995) , and Luttmer (2007) . In all cases productivity realizations are exogenous, except in Ericson and Pakes (1995) where they are to some extent endogenous.
Meanwhile, theories employing financing constraints argue that some imperfection in financial markets causes young firms to have limited access to credit, forcing them to enter at a suboptimally small scale. As firms get older and survive, they establish creditworthiness and build up internal resources that enable them to expand to their optimal size. Important contributions to this literature are those of Cooley and Quadrini (2001) , Albuquerque and Hopenhayn (2004) , and Clementi and Hopenhayn (2006) . In Cooley and Quadrini (2001) a transaction cost on equity and a default cost on debt imply that equity and debt are not perfect substitutes, resulting in a positive dependence of firm size on the amount of equity. In Albuquerque and Hopenhayn (2004) and Clementi and Hopenhayn (2006) lenders introduce credit constraints because of limited liability of borrowers and enforcement of debt contracts, in the first case, and because of asymmetric information on the use of funds or the return on investment, in the second case.
Cabral and Mata (2003) analyze whether these two theories are consistent with the evolution of a cohort's size distribution in the Portuguese manufacturing sector. They find that, as the cohort ages, the firm size distribution shifts to the right largely due to growth of surviving firms rather than exit of small firms. In addition, they find that in the first year after entry younger business owners are associated with smaller firms but that is no longer the case once the cohort gets to age seven. Assuming that age is a proxy for the entrepreneur's initial wealth, the authors conclude that the age-size effect supports the idea of financially constrained firms starting at a suboptimal size and present a model with financing constraints capturing this effect.
More recently, Angelini and Generale (2008) use survey and balance sheet information for Italian manufacturing firms to analyze the impact of financing constraints on the evolution of the firm size distribution. They find that financially constrained firms tend to be small and young, although this does not have a significant effect on the overall firm size distribution. Moreover, they find that financing constraints decrease firm growth, with this effect being entirely due to small firms. In particular, being young and financially constrained does not have any additional effect. Based on these results and the fact that young firms grow faster than old firms, the authors conclude that financing constraints are not the main factor behind the evolution of the firm size distribution. In line with their argument, this paper interprets the facts presented in Cabral and Mata (2003) and other cross-sector evidence as the result of the interaction between adjustment costs and learning about efficiency.10
To our knowledge, this work is the first to suggest adjustment costs as an explanation for differences in firm dynamics by age. The paper by Cabral (1995) is nearest to this paper. In his model, firms must pay a proportional sunk cost to increase their production capacity. He argues that, in a model with Bayesian learning, a proportional capacity cost would make small entering firms grow faster than large entering firms. The reason is that small entrants are those whose initial profitability signals were not good, so their exit probabilities are higher, and therefore they choose to invest more gradually. Unlike our model, Cabral's model depends on the existence of selection. Also, by analyzing a size-growth relationship, his model is not able to explain why some large entering firms also grow substantially.
The paper is organized as follows. In section 2, we present evidence of firm dynamics for a cohort of entering firms. In section 3, we build the general model, obtain optimality conditions, and provide heuristic arguments explaining the effects of adjustment costs. In section 4, using a simplified version of the model we analytically prove the effect of linear adjustment costs on survivors' growth. In section 5, we calibrate and estimate a finite learning horizon version of the model and quantify the contribution of adjustment costs to firm dynamics. Section 6 concludes. All proofs are left for an appendix.
2 Firm Dynamics in a Cohort of Entering Firms
There is a well established literature on the identification and explanation of differences in behavior between young and old firms. In this section, we analyze firm dynamics in a cohort of entering firms. We use Quadros de Pessoal, a database containing information on all Portuguese firms with paid employees. This dataset originates from a mandatory annual survey run by the Ministry of Employment, which collects information about the firm, its establishments, and its workers. All economic sectors except public administration are included. The panel we have access to covers the period 1985-2000. Information refers to March of each year from 1985 through 1993, and to October of each year since the reformulation of the survey in 1994. On average the dataset contains 250,000 firms, 300,000 establishments, and 2,500,000 workers in each year.
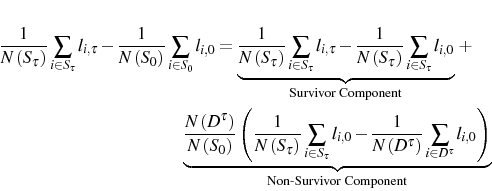
The literature on firm dynamics typically finds that young firms grow faster than old firms. Using kernel density estimates of the firm size distribution in a cohort of entrants, Cabral and Mata (2003) argue graphically that the cohort's evolution is mostly due to growth of survivors rather than exit of small firms. Their analysis points to the need for a measure of the contribution of survivors versus non-survivors to the growth in a given cohort's average size. To accomplish this, we propose a decomposition of the cohort's cumulative growth that will later allow an assessment of the empirical relevance of adjustment costs. We consider the following decomposition:
where
In general, the growth in a cohort's average size can originate from growth of survivors or from smaller initial size of non-survivors. Any theory of firm dynamics should consider both these sources of growth. Our measure allows a check on whether a particular theory can explain the key source
of growth in a cohort's average size. The survivor component compares the current average size of period ![]() survivors with their initial average size, so that it measures how much survivors
have grown. The non-survivor component compares the average initial size of period
survivors with their initial average size, so that it measures how much survivors
have grown. The non-survivor component compares the average initial size of period ![]() non-survivors with the average initial size of period
non-survivors with the average initial size of period ![]() survivors, so that it measures how relatively small non-survivors were initially.
survivors, so that it measures how relatively small non-survivors were initially.
We can obtain a similar decomposition for employment-weighted moments. The weighted decomposition contains information about the entire distribution of employment, not just its cross-sectional mean, and is affected both by within- and between-firm growth. Therefore, the weighted decomposition would be more relevant for assessing a richer model that considers the reallocation of employment shares between firms within the cohort. In the results that follow we focus on the unweighted decomposition because it analyzes within-firm growth, which in our model is the most relevant statistic to assess the effect of adjustment costs on the incentives for firms to grow.12
We can also produce a decomposition based on the cohort's annual growth instead of the cohort's cumulative growth. However, the annual version of the above decomposition is more sensitive to two aspects that would complicate the analysis in the paper. First, the annual survivor component is significantly affected by the business cycle, especially after the first few years of life. To control for this, we would need to somehow remove the cyclical part of the survivor component. Second, as the age of the cohort increases, the annual survivor component becomes increasingly sensitive to downsizing and exit by some survivors that become technologically outdated and consequently relatively less efficient. To fully consider this aspect of the data would force us to introduce additional parameters into the model that we present in section 3. Therefore, we believe that by employing a decomposition based on the cohort's cumulative growth we avoid having to adjust the analysis for these two aspects, and instead focus on how intense is survivor's growth while learning-about-efficiency effects are significant.
In table 6, we present the evolution of exit rates and the share of firm growth due to the survivor component in the 1988 cohort of entering firms for the overall economy.13 In 1988 there were ![]() entering firms. The exit rate is very high initially but tends to decrease as firms get older.14 However, ten years after entry only
entering firms. The exit rate is very high initially but tends to decrease as firms get older.14 However, ten years after entry only ![]() of the initial entrants remain active. There is significant growth in the cohort's average size, especially in the first few years, which is mostly due to the growth of survivors rather than to the exit of small inefficient firms:
survivors' growth contributes around
of the initial entrants remain active. There is significant growth in the cohort's average size, especially in the first few years, which is mostly due to the growth of survivors rather than to the exit of small inefficient firms:
survivors' growth contributes around ![]() to the growth in the cohort's average size.15
to the growth in the cohort's average size.15
Table 6 presents similar evidence on cohort dynamics for the manufacturing and services sectors.16 We include the employment shares of each sector in the 1988 cohort of entering firms, which are close to shares in the overall economy. Although
manufacturing has a much higher employment share than services, the number of entering firms in services surpasses that of manufacturing (![]() and
and ![]() , respectively). Both sectors display a cumulative exit rate around
, respectively). Both sectors display a cumulative exit rate around ![]() by 1999. However, initial differences in exit rates are
more significant, with manufacturing displaying the smallest values, and services displaying the highest values. In terms of initial size, manufacturing has the largest entrants, and services the smallest. Although manufacturing has the largest entrants, it exhibits more growth in average
employment and a larger contribution of survivors to that growth than services.
by 1999. However, initial differences in exit rates are
more significant, with manufacturing displaying the smallest values, and services displaying the highest values. In terms of initial size, manufacturing has the largest entrants, and services the smallest. Although manufacturing has the largest entrants, it exhibits more growth in average
employment and a larger contribution of survivors to that growth than services.
We perform two robustness checks on the previous findings. First, we redo our calculations using establishments rather than firms as the unit of analysis. For the 1988 establishment cohort, we obtain similar results, although exit rates and the survivor component are higher than in the case of
firms. Second, we examine an alternative cohort to make sure our results are not driven by business cycle conditions. The Portuguese economy experienced an expansion between 1986 and 1991, a period of slow growth with a recession between 1992 and 1994, and another weaker expansion between 1995 and
2000. The growth rates of real GDP were ![]() in 1989,
in 1989, ![]() in 1992, and
in 1992, and ![]() in 1995, so that the 1991 cohort did not face as favorable a macroeconomic environment as the 1988 cohort. However, the results for the 1991 cohort are, in all dimensions, very similar to those
presented above. The results for the 1994 cohort are also very similar, but with slightly smaller values for the survivor component in the first few years after entry.17
in 1995, so that the 1991 cohort did not face as favorable a macroeconomic environment as the 1988 cohort. However, the results for the 1991 cohort are, in all dimensions, very similar to those
presented above. The results for the 1994 cohort are also very similar, but with slightly smaller values for the survivor component in the first few years after entry.17
In table 6, we provide evidence on the properties of labor adjustment in the 1988 cohort of entering firms. Namely, we present three characteristics of the distribution of adjusted growth rates, conditional on survival, in 1989 and 1993: the fraction of firms that do not
adjust employment, ![]() , and the fractions of firms that increase/reduce their size by less than
, and the fractions of firms that increase/reduce their size by less than ![]() ,
, ![]() /
/![]() .18 The table shows that the incidence of inaction is very high, increases with age, and is higher in services than in manufacturing. This may reflect technology-induced differences in adjustment costs, or job
indivisibilities affecting to a larger extent the services sector for having a higher share of small firms. The table also shows that the large majority of firms have adjustment rates within the
.18 The table shows that the incidence of inaction is very high, increases with age, and is higher in services than in manufacturing. This may reflect technology-induced differences in adjustment costs, or job
indivisibilities affecting to a larger extent the services sector for having a higher share of small firms. The table also shows that the large majority of firms have adjustment rates within the
![]() interval. A high rate of inaction and small adjustment is usually considered consistent with the presence of linear or proportional adjustment costs. In addition, comparing the
columns
interval. A high rate of inaction and small adjustment is usually considered consistent with the presence of linear or proportional adjustment costs. In addition, comparing the
columns ![]() and
and ![]() it appears that the 1989 growth distributions are more left-skewed
than the 1993 distributions, suggesting that survivors tend to grow more initially, especially in manufacturing. The evidence on inaction justifies our assumption of linear adjustment costs in the model that we present next.
it appears that the 1989 growth distributions are more left-skewed
than the 1993 distributions, suggesting that survivors tend to grow more initially, especially in manufacturing. The evidence on inaction justifies our assumption of linear adjustment costs in the model that we present next.
3.1 Assumptions and Solution
In this section, we introduce linear adjustment costs into a model of Bayesian learning about efficiency. We derive conditions for optimal employment over time and present heuristic arguments about the effects of adjustment costs on the path of employment. Our model is based on Jovanovic (1982) , adding adjustment costs and using a different specification for the idiosyncratic shock.
We assume an industry with competitive output and input markets. Current profits of a representative firm are defined by
Concerning technology we make the following assumption.
(a)
![]() is
is ![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() , and
, and
![]() . (b) Letting
. (b) Letting ![]() denote
the firm's age and 0 the period in which the firm enters, the stochastic process of
denote
the firm's age and 0 the period in which the firm enters, the stochastic process of ![]() is defined by
is defined by
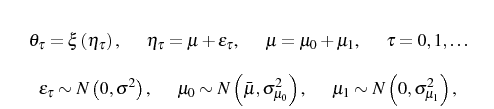
where
Part (a) ensures a well defined interior optimum. In some of the analyses below, we will assume that ![]() is a power function. Meanwhile, part (b) establishes that in each period productivity is stochastic with a constant mean over the firm's lifetime. The productivity component,
is a power function. Meanwhile, part (b) establishes that in each period productivity is stochastic with a constant mean over the firm's lifetime. The productivity component, ![]() , is made of two parts:
, is made of two parts: ![]() , which is observed before entry, and
, which is observed before entry, and ![]() , which is never directly observed by the firm.
Intuitively,
, which is never directly observed by the firm.
Intuitively, ![]() can be thought of as indexing ex ante efficiency, measuring initial technology choice, while
can be thought of as indexing ex ante efficiency, measuring initial technology choice, while ![]() indexes ex post productivity, measuring how well a firm performs within its technology choice.
indexes ex post productivity, measuring how well a firm performs within its technology choice.
The introduction of ![]() is essential to obtain a non-degenerate distribution of firms' entry size, allowing an analysis of the contribution of survivors to growth in the cohort's average
size. In contrast, the absence of
is essential to obtain a non-degenerate distribution of firms' entry size, allowing an analysis of the contribution of survivors to growth in the cohort's average
size. In contrast, the absence of ![]() in Jovanovic's (1982) model generates a degenerate distribution of firms' entry size. Under this scenario, for any period
after entry, survivors and non-survivors have the same average initial size implying a value of
in Jovanovic's (1982) model generates a degenerate distribution of firms' entry size. Under this scenario, for any period
after entry, survivors and non-survivors have the same average initial size implying a value of ![]() to our measure of the survivors' component. By assuming
to our measure of the survivors' component. By assuming
![]() , we avoid this aspect of Jovanovic's model.
, we avoid this aspect of Jovanovic's model.
Before entry the firm knows the parameters governing the stochastic process of ![]() , i.e.,
, i.e., ![]() ,
,
![]() ,
,
![]() and
and
![]() , and learns its ex ante productivity,
, and learns its ex ante productivity, ![]() ,
after paying a research cost,
,
after paying a research cost, ![]() . After entry, the firm will learn about its specific ex post productivity,
. After entry, the firm will learn about its specific ex post productivity, ![]() , over time as it observes the realizations of productivity,
, over time as it observes the realizations of productivity, ![]() . In particular, the firm forecasts period-
. In particular, the firm forecasts period-![]() productivity based on the ex ante efficiency parameter
productivity based on the ex ante efficiency parameter ![]() and
on the past realizations of productivity,
and
on the past realizations of productivity,
![]() . Similarly to Zellner (1971) , a firm with age
. Similarly to Zellner (1971) , a firm with age ![]() has the following Bayesian posterior distribution for
has the following Bayesian posterior distribution for ![]() at the beginning of period
at the beginning of period ![]() :
:
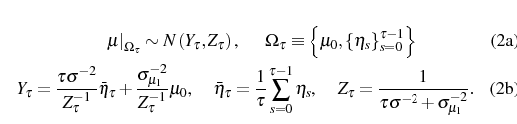
In lemma 2 of appendix A we show that, for purposes of
predicting ![]() , the information set
, the information set ![]() can be summarized by
can be summarized by ![]() , where
, where ![]() is the period-
is the period-![]() forecast of the productivity coefficient
based on the information available at the beginning of period
forecast of the productivity coefficient
based on the information available at the beginning of period
![]() . That is,
. That is,
![]() , where
, where
![]() is the expectation conditional on the period-
is the expectation conditional on the period-![]() information set.
information set.
We now lay out the timing assumptions.
(i.a) Research cost and ex ante productivity: the firm pays a fixed cost
(i.b) Entry decision and entry cost: based on the idiosyncratic realization of
(i.c) Initial employment and production decisions: conditional on entering the industry, the firm chooses how much labor to use and how much output to produce in period 0.
A firm of age
(ii.a) Update of posterior productivity: at the beginning of period
(ii.b) Exit decision: given the new posterior productivity estimate,
(ii.c) Employment and production decisions: conditional on staying, the firm chooses how much labor to use and how much output to produce in the current period. At the end of period
In the absence of adjustment costs, while deciding whether to stay one more period or to exit, the firm compares the expected profit in case it stays, ![]() , with the opportunity cost of doing
so,
, with the opportunity cost of doing
so, ![]() , the value it would recover by selling the (exogenous) capital initially acquired, i.e.,
, the value it would recover by selling the (exogenous) capital initially acquired, i.e.,
where
At entry, we have
![]() , and in equilibrium expected profits must compensate for the cost of acquiring capital, i.e.,
, and in equilibrium expected profits must compensate for the cost of acquiring capital, i.e.,
![]() . Since markets are competitive and there is no friction in the entry and exit processes, in equilibrium the research cost equals expected gains at
the research phase, i.e.,
. Since markets are competitive and there is no friction in the entry and exit processes, in equilibrium the research cost equals expected gains at
the research phase, i.e.,
![]() . If
. If
![]() more firms will initiate research and later enter the industry, causing a decrease in output price until equality is restored. A strictly positive fixed research
cost,
more firms will initiate research and later enter the industry, causing a decrease in output price until equality is restored. A strictly positive fixed research
cost, ![]() , is essential to avoid the extreme situation where trial research is so high that only the highest productivity firms enter and survive. Because there is no reliable capital stock
variable in Quadros de Pessoal, we do not make the capital decision endogenous to the model. Instead, we assume that firms are homogeneous along the capital dimension and face the same opportunity cost of remaining in activity,
, is essential to avoid the extreme situation where trial research is so high that only the highest productivity firms enter and survive. Because there is no reliable capital stock
variable in Quadros de Pessoal, we do not make the capital decision endogenous to the model. Instead, we assume that firms are homogeneous along the capital dimension and face the same opportunity cost of remaining in activity, ![]() .
.
Up to this point, the only differences between our model and Jovanovic (1982) are that in the latter model the efficiency parameter implicitly affects the cost function and the cohort's entry size distribution is degenerate. Therefore, without adjustment costs there
would be no intertemporal linkages in our model aside from the exit decision. As in Jovanovic, because ![]() is strictly increasing in
is strictly increasing in
![]() , the exit decision is characterized by an age-dependent exit threshold. For values of
, the exit decision is characterized by an age-dependent exit threshold. For values of
![]() above or equal to that threshold, the firm would stay and choose employment to maximize current period profits. For values of
above or equal to that threshold, the firm would stay and choose employment to maximize current period profits. For values of
![]() below that threshold, the firm would leave the industry, since its expected profitability is below the opportunity cost. The increasing confidence the firm puts in
below that threshold, the firm would leave the industry, since its expected profitability is below the opportunity cost. The increasing confidence the firm puts in
![]() as it grows older implies that the exit threshold is increasing with age. This is the driving force underlying Jovanovic's result that the size distribution and the
survival probability increase with age.
as it grows older implies that the exit threshold is increasing with age. This is the driving force underlying Jovanovic's result that the size distribution and the
survival probability increase with age.
We now introduce linear adjustment costs into the model. The adjustment cost for continuing firms, ![]() , is defined as
, is defined as
With adjustment costs, the problem now becomes,
![\begin{multline} V^{S}\left( L_{\tau-1},\theta_{\tau}^{\ast},\tau\right) =\max_{L_{\tau} }\left\{ \left[ \Pi\left( L_{\tau},\theta_{\tau}^{\ast}\right) -C^{S}\left( L_{\tau},L_{\tau-1}\right) \right] +\right. \ \left. \beta E_{\tau}\left[ \max\left\{ V^{EX}\left( L_{\tau}\right) ,V^{S}\left( L_{\tau},\theta_{\tau+1}^{\ast},\tau+1\right) \right\} \right] \right\} \text{,} \end{multline}](img110.gif)
for all periods after entry (
for the entry period, where
In general, we could allow for asymmetry among the cost parameters in ![]() ,
, ![]() , and
, and ![]() . However, asymmetries between the cost of regular firing and the cost of firing at exit or between the cost of regular hiring and the cost of hiring at entry
lead to biases in entry and exit decisions. For example, if the per unit regular hiring cost is higher than the per unit entry hiring cost, then firms will hire more workers at entry in order to save on expected future higher hiring costs. Similarly, if the per unit regular firing cost is smaller
than the per unit exit firing cost, then firms facing the prospect of exit will fire workers before exiting the industry, saving on expected future higher exit firing costs. To avoid these biases, throughout the paper we assume symmetry between the parameters in
. However, asymmetries between the cost of regular firing and the cost of firing at exit or between the cost of regular hiring and the cost of hiring at entry
lead to biases in entry and exit decisions. For example, if the per unit regular hiring cost is higher than the per unit entry hiring cost, then firms will hire more workers at entry in order to save on expected future higher hiring costs. Similarly, if the per unit regular firing cost is smaller
than the per unit exit firing cost, then firms facing the prospect of exit will fire workers before exiting the industry, saving on expected future higher exit firing costs. To avoid these biases, throughout the paper we assume symmetry between the parameters in ![]() ,
, ![]() , and
, and ![]() . A more interesting distinction is between firing and hiring costs. We will see below that the conclusion of the paper is immune to asymmetries between the costs of adding and subtracting workers.
. A more interesting distinction is between firing and hiring costs. We will see below that the conclusion of the paper is immune to asymmetries between the costs of adding and subtracting workers.
In solving the firm's problem, we consider a two-step optimization procedure where the firm first chooses optimal employment in each of three possible scenarios, and then selects the scenario with the highest pay-off. More precisely,
Let
(a) There exists a unique value function
(b) There exists a unique optimal exit policy function
In contrast, the non-differentiability of the objective function generates an inaction region in the employment policy, within which optimal employment does not vary with changes in productivity.
For any period
![\displaystyle \left[ F^{\prime}\left( L_{\tau}^{\ast}\right) \theta_{\tau}^{\ast }-w\right] +\sum_{s=1}^{\infty}E_{\tau}\beta^{s}\left\{ \tilde{\chi} _{\tau+s}^{\ast}\left( -P\right) +\hat{\chi}_{\tau+s}^{\ast}\left[ F^{\prime}\left( L_{\tau+s}^{\ast}\right) \theta_{\tau+s}^{\ast}-w\right] \right\} =P](img134.gif) ,
,whereas if the firm adjusts downwards optimal employment satisfies
![\displaystyle \left[ F^{\prime}\left( L_{\tau}^{\ast}\right) \theta_{\tau}^{\ast }-w\right] +\sum_{s=1}^{\infty}E_{\tau}\beta^{s}\left\{ \tilde{\chi} _{\tau+s}^{\ast}\left( -P\right) +\hat{\chi}_{\tau+s}^{\ast}\left[ F^{\prime}\left( L_{\tau+s}^{\ast}\right) \theta_{\tau+s}^{\ast}-w\right] \right\} =-P](img135.gif) ,
,In period 0, the firm enters the industry if
![\displaystyle \left[ F^{\prime}\left( L_{0}^{\ast}\right) \theta_{0}^{\ast}-w\right] +\sum_{s=1}^{\infty}E_{0}\beta^{s}\left\{ \tilde{\chi}_{s}^{\ast}\left( -P\right) +\hat{\chi}_{s}^{\ast}\left[ F^{\prime}\left( L_{s}^{\ast }\right) \theta_{s}^{\ast}-w\right] \right\} =P](img137.gif) .
.![]()
Equations (6), (7) and (8) are marginal conditions, similar to the smooth pasting conditions in the (S, s) model literature, and they state that if the firm adjusts then the marginal adjustment cost must equal the expected present discounted value of the marginal revenue product for all future periods in which the firm is still in the industry, minus the increase in the exit cost when the firm decides to exit. This is the discrete-time analog of the continuous-time result present in Nickell (1986) and Bentolila and Bertola (1990) , adjusted for the fact that now we also have an exit decision. Because the firm will not change employment if the marginal cost of adjustment exceeds its marginal benefit for the first unit of adjustment, proportional costs imply inaction in the employment decision of the firm.
Although the results in proposition 6 do not allow a formal proof of the effects on firm growth of adjustment costs in this general model, the following corollary of proposition 6 enables us to make qualitative heuristic statements about those effects.
Corollary 7: For any period ![]() , the marginal benefit of one additional unit of labor, that is, the LHS of expressions (6),
(7), and (8), can be recursively represented as
, the marginal benefit of one additional unit of labor, that is, the LHS of expressions (6),
(7), and (8), can be recursively represented as
where
![]()
3.2 Linear Adjustment Cost and Firm Growth
As we have seen above, in the absence of adjustment costs, optimal employment is determined solely to maximize current period profits, so that
![]() . Therefore, firms' growth is essentially a by-product of a selection mechanism: those firms that are inefficient, and therefore small, exit,
while those firms that are efficient survive and grow. There is an additional source of positive growth when the frictionless employment decision rule,
. Therefore, firms' growth is essentially a by-product of a selection mechanism: those firms that are inefficient, and therefore small, exit,
while those firms that are efficient survive and grow. There is an additional source of positive growth when the frictionless employment decision rule,
![]() , is convex in
, is convex in
![]() . Because of Jensen's inequality and because
. Because of Jensen's inequality and because
![]() is a Martingale, surviving firms will grow over time:
is a Martingale, surviving firms will grow over time:
![]() .
However,
.
However, ![]() will not be convex in
will not be convex in
![]() for general
for general
![]() .21
.21
In arguing heuristically about the impact of the proportional cost on firm growth we use the property that ![]() is weakly increasing in
is weakly increasing in
![]() , and that
, and that
![]() is locally weakly increasing in
is locally weakly increasing in
![]() . Because it is not immediately obvious why firing and hiring costs should give similar incentives for firm growth, we analyze separately these two costs.22 We present in figure 1 the case where there is a hiring cost,
. Because it is not immediately obvious why firing and hiring costs should give similar incentives for firm growth, we analyze separately these two costs.22 We present in figure 1 the case where there is a hiring cost, ![]() , and no firing cost,
, and no firing cost, ![]() . This figure assumes a given
. This figure assumes a given
![]() . For that specific value of
. For that specific value of ![]() ,
,
![]() and
and
![]() are the frontiers between non-adjustment and upward and downward adjustment, respectively. Therefore, if
are the frontiers between non-adjustment and upward and downward adjustment, respectively. Therefore, if
![]() there will be no adjustment and the marginal benefit of an additional unit of labor (represented by the dashed line) is contained
in the interval
there will be no adjustment and the marginal benefit of an additional unit of labor (represented by the dashed line) is contained
in the interval
![]() . To simplify the argument, we consider a firm whose sequence of productivity draws is such that in every period it has a perceived productivity equal to the
unconditional mean of
. To simplify the argument, we consider a firm whose sequence of productivity draws is such that in every period it has a perceived productivity equal to the
unconditional mean of
![]() , even though the firm's uncertainty over next period
, even though the firm's uncertainty over next period
![]() decreases with age.
decreases with age.
Case 1: Hiring Cost: ![]() ,
, ![]()
Because the firm starts at the hiring margin, we must have
![]() at entry, and
at entry, and
![]() , for all subsequent periods,
, for all subsequent periods,
![]() , with the two extremes of the interval representing firing and hiring of workers, respectively. Consider first a situation where exit is not allowed. Under this assumption,
(9) would become
, with the two extremes of the interval representing firing and hiring of workers, respectively. Consider first a situation where exit is not allowed. Under this assumption,
(9) would become
The Bayesian learning mechanism implies both persistence and a reduction in variance with age in the Markov process associated with
![]() . The effect of persistence, that is, the fact that
. The effect of persistence, that is, the fact that
![]() , was analyzed in the previous paragraph. The reduced uncertainty in the posterior estimate of
productivity will be reflected in a smaller inaction region as firms accumulate information on realized productivity; that is,
, was analyzed in the previous paragraph. The reduced uncertainty in the posterior estimate of
productivity will be reflected in a smaller inaction region as firms accumulate information on realized productivity; that is,
![]() decreases with
decreases with ![]() . This causes an increase in
. This causes an increase in
![]() for those firms already at the hiring margin, which must be balanced by an increase in
for those firms already at the hiring margin, which must be balanced by an increase in
![]() for the right hand side of (9) to remain equal to
for the right hand side of (9) to remain equal to ![]() . As firms become more certain about their true productivity they are more willing to adjust to their long run optimal size. Because most firms are at the hiring margin, this will cause a further increase in average size.
. As firms become more certain about their true productivity they are more willing to adjust to their long run optimal size. Because most firms are at the hiring margin, this will cause a further increase in average size.
Consider now the possibility of exit. In this case, the uncertainty reduction as the firm ages implies a decrease in the exit probability, and a further increase in the future-periods component of ![]() in (9). Consequently,
in (9). Consequently,
![]() needs to increase further in order to offset that.24 On the other hand, the smaller exit probability implies less pruning of inefficient slow-growing firms as a cohort ages, which tends to make growth in average firm size smaller. Therefore, we will have less cohort growth due to non-survivors and more cohort growth due to survivors, so
that survivors' contribution to average firm growth in the cohort should increase when exit is allowed.
needs to increase further in order to offset that.24 On the other hand, the smaller exit probability implies less pruning of inefficient slow-growing firms as a cohort ages, which tends to make growth in average firm size smaller. Therefore, we will have less cohort growth due to non-survivors and more cohort growth due to survivors, so
that survivors' contribution to average firm growth in the cohort should increase when exit is allowed.
Case 2: Firing Cost: ![]() ,
, ![]()
In this case, we have ![]() ,
,
![]() ,
,
![]() . Assume first that exit is not allowed. The intuition is the same as in case 1. In comparison with
. Assume first that exit is not allowed. The intuition is the same as in case 1. In comparison with ![]() , when
, when ![]() firms start smaller and subsequently hire more frequently than they fire. As firms age, the reduction in variance of
firms start smaller and subsequently hire more frequently than they fire. As firms age, the reduction in variance of
![]() causes an increase in
causes an increase in
![]() , which must be compensated by an increase in
, which must be compensated by an increase in
![]() for firms at the hiring margin. When exit is possible, those effects become more intense, since the exit probability will decrease as firms age.
for firms at the hiring margin. When exit is possible, those effects become more intense, since the exit probability will decrease as firms age.
From the heuristic intuition we have just given it becomes clear that proportional hiring and proportional firing costs reinforce each other in creating incentives for firms to grow. In the end, our assessment of the relevance of linear adjustment costs for firm growth will depend on how well a pure selection model can fit the empirical evidence, and on how much adjustment costs improve the fit. Before we move into a quantitative assessment, we present analytical results for a simple version of the general model.
4 Model with One Period Learning Horizon and No Exit
In this section, we analyze a model where firms' efficiency is revealed after the first period of life and where firms' lifetime horizon is know with certainty at entry. We assume that firms live for ![]() periods, where
periods, where ![]() is any integer greater than
is any integer greater than ![]() , and that
no exit is allowed prior to age
, and that
no exit is allowed prior to age ![]() . These two simplifications allow us to determine the effect of linear adjustment costs on firm growth.
. These two simplifications allow us to determine the effect of linear adjustment costs on firm growth.
The introduction of adjustment costs implies an additional expected operating cost for entering firms. Therefore, the equilibrium price must increase to generate higher expected future profits that compensate for the costs incurred while adjusting to optimal size. As a consequence, pre-entry
pruning of inefficient firms should increase while post-entry pruning should decrease. This is optimal from a social point of view, since with higher adjustment costs there should be less experimentation in order to save in unrecoverable costs. Therefore, the assumption that exit is exogenous is
not critical for the results in this section. Since adjustment costs attenuate post-entry pruning, even if exit was endogenous to the model, the relative contribution of survivors to growth in the cohort's average size would increase through this channel. By eliminating any exit prior to
![]() we focus only on the incentives for survivors to grow.
we focus only on the incentives for survivors to grow.
To formulate the problem, we use the fact that once the firm learns its true efficiency in period 2, it will adjust once and for all to its long run employment level.25 Then, if upon exit at age ![]() firms recover the initial investment net of exit costs, in period 2 we have
firms recover the initial investment net of exit costs, in period 2 we have
where
We examine the impact of adjustment costs on the log growth rate of employment, rather than the standard growth rate, in order to attenuate the effect of Jensen's inequality on firm growth.26 In this simple model, the inaction region of optimal employment can be expressed as an interval:
![]() . Therefore, the average log growth rate between period 1 and period 2, conditional on
. Therefore, the average log growth rate between period 1 and period 2, conditional on
![]() , is defined as
, is defined as
![\begin{multline*} g\left( \theta_{1}^{\ast}\right) =E\left[ \ln\left( L_{2}^{\ast}\right) -\ln\left( L_{1}^{\ast}\right) \right] =\ \int_{\nu_{1}}^{\theta^{SD}}\left\{ \ln\left( L_{2}^{\ast SD}\right) -\ln\left( L_{1}^{\ast}\right) \right\} dF_{\theta_{1}^{\ast}}\left( \theta_{2}^{\ast}\right) +\int_{\theta^{SU}}^{\nu_{2}}\left\{ \ln\left( L_{2}^{\ast SU}\right) -\ln\left( L_{1}^{\ast}\right) \right\} dF_{\theta_{1}^{\ast}}\left( \theta_{2}^{\ast}\right) \end{multline*}](img210.gif)
where
Optimal employment in period 2 is determined by
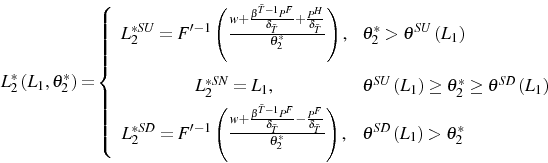
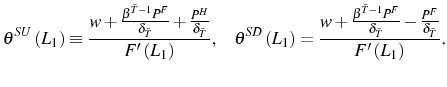
We then have the following result concerning the effects of changes in ![]() and
and ![]() on the cohort's average log growth rate of employment.
on the cohort's average log growth rate of employment.
Assuming that
(a) The marginal effect of
(b) The marginal effect of
![]()
Consider first the hiring cost. In the proof, we show that an increase in ![]() decreases both
decreases both
![]() and
and
![]() . The impact of
. The impact of ![]() on the growth rate depends on two opposing
effects. First, while in the case of
on the growth rate depends on two opposing
effects. First, while in the case of
![]() the cost of hiring can be equally spread out over
the cost of hiring can be equally spread out over ![]() periods
with certainty, in the case of
periods
with certainty, in the case of
![]() it will be spread out over either
it will be spread out over either ![]() periods or one period,
depending on whether the firm learns in period
periods or one period,
depending on whether the firm learns in period ![]() that it has overhired. Therefore, ex ante a proportionately greater part of
that it has overhired. Therefore, ex ante a proportionately greater part of ![]() is attached to period
is attached to period ![]() in the case of
in the case of
![]() than in the case of
than in the case of
![]() , affecting more
, affecting more
![]() than
than
![]() . This explains the positive effect on growth of
. This explains the positive effect on growth of ![]() for
for
![]() . Second, the hiring cost on
. Second, the hiring cost on
![]() can possibly be spread out over
can possibly be spread out over ![]() periods, while the hiring cost
on
periods, while the hiring cost
on
![]() can only be spread out over
can only be spread out over ![]() periods. This affects more
periods. This affects more
![]() than
than
![]() , and explains why the effect of
, and explains why the effect of ![]() on growth is not necessarily
positive for finite
on growth is not necessarily
positive for finite ![]() . However, as
. However, as ![]() increases the first effect dominates
so that
increases the first effect dominates
so that ![]() decreases
decreases
![]() more than
more than
![]() and growth increases.29
and growth increases.29
With respect to ![]() there is always a positive effect on growth, independently of the lifetime horizon. This occurs because an increase in
there is always a positive effect on growth, independently of the lifetime horizon. This occurs because an increase in ![]() decreases
decreases
![]() and increases
and increases
![]() . This positive effect always dominates the uncertain effect due to the fact that
. This positive effect always dominates the uncertain effect due to the fact that
![]() also decreases with
also decreases with ![]() .
.
When there are both hiring and firing costs and these costs are identical (
![]() ), then an increase in
), then an increase in ![]() has a positive effect on
has a positive effect on
![]() , for sufficiently high
, for sufficiently high ![]() , where the required
, where the required
![]() is lower than in item (a) of proposition 8.
is lower than in item (a) of proposition 8.
5 Calibration/Estimation Under Finite Learning Horizon
In the previous two sections, we developed heuristic and some formal arguments about the effect of adjustment costs on the incentives for firms to start smaller and grow faster after entry. In this section, we assess the contribution of adjustment costs to explain some of the basic facts on firm dynamics found in section 2, both for the overall economy and for the manufacturing and services sectors. To accomplish this, we perform a calibration/estimation of the model using computational methods.
To simulate the infinite learning horizon model we follow the suggestion of Ljungqvist and Sargent (2004) and consider an approximation where firms live forever, but learn their ex post true productivity component,
![]() , with certainty at some age
, with certainty at some age ![]() .30
.30
We assume that
![]() is a power function, i.e.,
is a power function, i.e.,
![]() ,
,
![]() . Under this assumption, when adjustment is costless, optimal employment conditional on survival is a convex function of
. Under this assumption, when adjustment is costless, optimal employment conditional on survival is a convex function of
![]() , so that Jensen's inequality implies growth of employment even if there is no selection. As in the previous section, in order to avoid any growth due to Jensen's
inequality, we take logs of all variables and analyze the effects of adjustment costs on the log-growth rate.
, so that Jensen's inequality implies growth of employment even if there is no selection. As in the previous section, in order to avoid any growth due to Jensen's
inequality, we take logs of all variables and analyze the effects of adjustment costs on the log-growth rate.
Concerning the productivity distribution, we assume that
![]() is lognormally distributed, i.e.,
is lognormally distributed, i.e.,
![]() .31 This assumption is made for computational simplicity, and it seems reasonable on empirical grounds (see Aw et al., 2004) . In addition, this assumption is not critical as the results in section 4 suggest that the distribution of productivity mostly
affects the intensity of the effect of adjustment costs on firm growth, but not the sign. In fact, proposition 8 is derived independently of the particular distribution of
.31 This assumption is made for computational simplicity, and it seems reasonable on empirical grounds (see Aw et al., 2004) . In addition, this assumption is not critical as the results in section 4 suggest that the distribution of productivity mostly
affects the intensity of the effect of adjustment costs on firm growth, but not the sign. In fact, proposition 8 is derived independently of the particular distribution of
![]() . With the log-normal distribution assumption, the transition law for the
. With the log-normal distribution assumption, the transition law for the
![]() s is as follows.
s is as follows.
Let
(a) The posterior distribution of
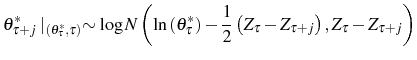 .
.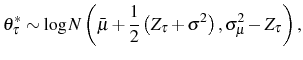
![]()
Since we assume that the firm enters the industry already knowing its ex ante productivity component ![]() (see assumption 1), we will
get a non-degenerate distribution of initial size. This occurs because
(see assumption 1), we will
get a non-degenerate distribution of initial size. This occurs because
![]() , and
, and
![]() has positive variance in the cohort's initial distribution. The next proposition analyzes the properties of the optimization problem after
has positive variance in the cohort's initial distribution. The next proposition analyzes the properties of the optimization problem after ![]() is revealed to the firm in period
is revealed to the firm in period ![]() .
.
If
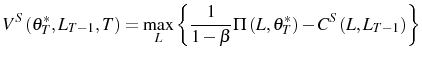 , , |
(11) |
![]()
This result allows a considerable simplification of the computational algorithm, since it implies a finite horizon dynamic programming problem. In appendix B, we present some details concerning the computational algorithm used to simulate and estimate the model. In the following subsections we calibrate and estimate the model and do a sensitivity analysis.
5.1 Calibration and Estimation of Model with Costly Adjustment
We calibrate and estimate our model to match statistics from the 1988 cohort of entering firms, both for the overall economy and the manufacturing and service sectors. We first calibrate parameters related to inputs directly from the data. We then use the simulated method of moments to estimate
the parameters associated with the learning process and the adjustment cost. These estimates are obtained so that the model generated moments match the evolution of firm size, of exit rates, and of the survivor component observed in the data. As discussed in appendix B, we find
the set of parameter values that minimize the method of moments objective function by using a simulated annealing method. This optimization method is robust to local minima, to discontinuities, and to the discretization implemented in order to simulate the model.32 A central element to our estimation strategy is a decomposition of the change in the cohort's average size into a survivor component and a non-survivor component. This decomposition forces the model
to match not only the growth in the cohort's average size but also the contribution of surviving and non-surviving firms to that growth. Similarly to section 2, with
![]() , our decomposition is defined as
, our decomposition is defined as
![\displaystyle E\left[ l_{\tau}\mid S_{\tau}\right] -E\left[ l_{0}\mid S_{0}\right] =\underset{\text{Survivor Component}}{\underbrace{E\left[ l_{\tau}-l_{0}\mid S_{\tau}\right] }}+\underset{\text{Non-Survivor Component}}{\underbrace {\Pr\left( D^{\tau}\mid S_{0}\right) \left\{ E\left[ l_{0}\mid S_{\tau }\right] -E\left[ l_{0}\mid D^{\tau}\right] \right\} }}](img276.gif)
Prior to estimation, we calibrate some parameters. The parameters ![]() and
and ![]() are
calibrated with data from INE (1997) containing the Inquérito Annual às Empresas from 1990 to 1995. These data are considered reliable and cover all firms in the Portuguese economy, with sampling among firms with less than 20
workers. We measure
are
calibrated with data from INE (1997) containing the Inquérito Annual às Empresas from 1990 to 1995. These data are considered reliable and cover all firms in the Portuguese economy, with sampling among firms with less than 20
workers. We measure ![]() as the 1990-1995 average of the cost share of labor in value added, and
as the 1990-1995 average of the cost share of labor in value added, and ![]() as the 1990-1995 average cost per worker. We can also obtain these values at the sectoral level. We deflate all nominal variables using the GDP sectoral price indices available in the updated version of Séries Longas para a Economia Portuguesa in
Banco de Portugal (1997) . The real interest rate is calibrated as the 1990-1995 average of the implicit real interest rate on public debt transactions on the secondary market of the Lisbon Stock Exchange. The data was also taken from Banco de Portugal (1997) . We deflate the nominal interest rates using the December-to-December consumer price index from INE (1990-5) . The discount rate is then obtained as
as the 1990-1995 average cost per worker. We can also obtain these values at the sectoral level. We deflate all nominal variables using the GDP sectoral price indices available in the updated version of Séries Longas para a Economia Portuguesa in
Banco de Portugal (1997) . The real interest rate is calibrated as the 1990-1995 average of the implicit real interest rate on public debt transactions on the secondary market of the Lisbon Stock Exchange. The data was also taken from Banco de Portugal (1997) . We deflate the nominal interest rates using the December-to-December consumer price index from INE (1990-5) . The discount rate is then obtained as
![]() , where
, where ![]() is the average real interest rate.
is the average real interest rate.
The remaining parameters, ![]() ,
,
![]() ,
,
![]() ,
, ![]() ,
, ![]() , and
, and ![]() are estimated using a simulated method of moments estimator, which attempts to make the model match closely the evidence on cohort
dynamics presented in section 2. In particular, the estimates are selected to minimize a weighted sum of the distance between the following moments in the model and the data: (a) the time-series of the mean of log-employment conditional on survival,
are estimated using a simulated method of moments estimator, which attempts to make the model match closely the evidence on cohort
dynamics presented in section 2. In particular, the estimates are selected to minimize a weighted sum of the distance between the following moments in the model and the data: (a) the time-series of the mean of log-employment conditional on survival,
![]() ; (b) the time-series of the cumulative change in the standard deviation of log-employment conditional on survival,
; (b) the time-series of the cumulative change in the standard deviation of log-employment conditional on survival,
![]() ;33 (c) the
time-series of the cumulative exit rate,
;33 (c) the
time-series of the cumulative exit rate,
![]() ; (d) and the time-series of the survivor component, as defined in (12). In estimating the above parameters, the output price is
normalized to
; (d) and the time-series of the survivor component, as defined in (12). In estimating the above parameters, the output price is
normalized to ![]() , and the initial research cost,
, and the initial research cost, ![]() , is obtained by the equilibrium
condition
, is obtained by the equilibrium
condition
![]() .34
.34
The decision to estimate ![]() , instead of calibrating it, deserves some discussion. First, the main purpose of this parameter is to induce endogenous exit as it represents the firm's
opportunity cost of remaining in activity. In Hopenhayn (1992) , the same result is accomplished using a fixed per period operating cost. Since the per period operating cost can be seen as the periodic payment in an annuity with a present discounted value of
, instead of calibrating it, deserves some discussion. First, the main purpose of this parameter is to induce endogenous exit as it represents the firm's
opportunity cost of remaining in activity. In Hopenhayn (1992) , the same result is accomplished using a fixed per period operating cost. Since the per period operating cost can be seen as the periodic payment in an annuity with a present discounted value of
![]() , the two mechanisms are equivalent. Second, because Quadros de Pessoal misses any reliable capital stock variable, we consider the capital decision to be
exogenous. A rough estimate of the magnitude of
, the two mechanisms are equivalent. Second, because Quadros de Pessoal misses any reliable capital stock variable, we consider the capital decision to be
exogenous. A rough estimate of the magnitude of ![]() is the present discounted value of an annuity with annual payments equal to the 1990-1995 average of value added minus labor costs, using the
same deflators as for
is the present discounted value of an annuity with annual payments equal to the 1990-1995 average of value added minus labor costs, using the
same deflators as for ![]() .35 Because the sample is biased
towards surviving firms, this measure overestimates the value of
.35 Because the sample is biased
towards surviving firms, this measure overestimates the value of ![]() , and we cannot use it as a reference to calibrate
, and we cannot use it as a reference to calibrate ![]() . Consequently, we estimate
. Consequently, we estimate ![]() jointly with the remaining parameters in the model.
jointly with the remaining parameters in the model.
We present in table 6 the calibrated and estimated parameters for the three cohorts, both for the model with (AC) and without (NAC) adjustment costs, and in figures 2 and 3 we
plot the data and simulated moments in the estimated AC and NAC models. We start by making some general remarks on our estimates. First, more information is revealed ex post
![]() and there is significant noise in the learning process (
and there is significant noise in the learning process (
![]() ,
,
![]() ). Second, consistently with our expectations, all estimates of
). Second, consistently with our expectations, all estimates of ![]() are below the rough estimates presented in footnote 34. Third, the inferred values for
are below the rough estimates presented in footnote 34. Third, the inferred values for ![]() are close to
are close to ![]() of
of ![]() . Finally, the standard errors of the estimated parameters are relatively small, suggesting that parameters are estimated
with good precision.36
. Finally, the standard errors of the estimated parameters are relatively small, suggesting that parameters are estimated
with good precision.36
For the overall economy cohort, the AC model implies an estimate for the proportional cost of about ![]() of the annual wage. By comparing the estimated
NAC and AC models, in terms of the objective function
of the annual wage. By comparing the estimated
NAC and AC models, in terms of the objective function ![]() and the simulated moments in figure 2, we conclude
that the proportional cost clearly improves the overall fit of the model, with a particularly notable improvement in the fit of the survivor component. Although the NAC model can generate moments on firm size and exit rates that are close to equivalent empirical moments,
it cannot satisfactorily match the empirical survivors' contribution. That is, the NAC model cannot explain the main source of growth in the cohort's average size, since survivors contribute much more to growth in the data than in the NAC
model. This shortcoming is especially intense in the initial years after entry, when the distance between the survivor component in the simulated NAC model and in the data is largest, suggesting that in the absence of adjustment costs learning has a larger initial impact
on the exit of small inefficient firms than on growth of survivors.
and the simulated moments in figure 2, we conclude
that the proportional cost clearly improves the overall fit of the model, with a particularly notable improvement in the fit of the survivor component. Although the NAC model can generate moments on firm size and exit rates that are close to equivalent empirical moments,
it cannot satisfactorily match the empirical survivors' contribution. That is, the NAC model cannot explain the main source of growth in the cohort's average size, since survivors contribute much more to growth in the data than in the NAC
model. This shortcoming is especially intense in the initial years after entry, when the distance between the survivor component in the simulated NAC model and in the data is largest, suggesting that in the absence of adjustment costs learning has a larger initial impact
on the exit of small inefficient firms than on growth of survivors.
In discussing the results for the manufacturing and services sectors we consider the estimates for the AC model. Manufacturing firms learn relatively less initially about their efficiency than services firms (
![]() is smaller in manufacturing). Moreover, in order to account for the higher survivor component, adjustment costs in manufacturing are larger than in services
(proportional costs amount to
is smaller in manufacturing). Moreover, in order to account for the higher survivor component, adjustment costs in manufacturing are larger than in services
(proportional costs amount to ![]() and
and ![]() of the annual wage, respectively).
Because of larger adjustment costs and lesser relative knowledge about efficiency at entry, manufacturing firms have higher incentives to start relatively small and to gradually adjust to optimal size as they survive and their uncertainty is resolved. In addition, the smaller relative knowledge at
entry in manufacturing explains the lower relative initial research cost (
of the annual wage, respectively).
Because of larger adjustment costs and lesser relative knowledge about efficiency at entry, manufacturing firms have higher incentives to start relatively small and to gradually adjust to optimal size as they survive and their uncertainty is resolved. In addition, the smaller relative knowledge at
entry in manufacturing explains the lower relative initial research cost (![]() is lower in manufacturing) and the higher entry rate (
is lower in manufacturing) and the higher entry rate (
![]() equals
equals ![]() in manufacturing and
in manufacturing and ![]() in services).
in services).
As can be seen from the last row of table 6, while the introduction of adjustment costs improves markedly the fit of the model for the overall economy and manufacturing cohorts, it improves only marginally the fit for the services cohort.37 Therefore, the form of adjustment costs considered in the paper seems more relevant for the average firm in the manufacturing sector and the overall economy than for the average firm in the services
sector. More generally, although the introduction of adjustment costs clearly improves the overall fit of model, especially in what concerns the survivor component, the model cannot explain entirely the path of the survivor component in the data. In fact, in all three cohorts the initial growth of
survivors seems larger than what the AC model can explain. This might be a consequence of the discretization scheme adopted for
![]() in the simulation.38 More importantly, this
might reflect other explanations for firm growth that cannot be captured by adjustment costs in our model, such as some mechanisms through which financing constraints operate.
in the simulation.38 More importantly, this
might reflect other explanations for firm growth that cannot be captured by adjustment costs in our model, such as some mechanisms through which financing constraints operate.
5.2 Sensitivity Analysis
In this subsection we explain some aspects of the calibration/estimation exercise and provide a detailed sensitivity analysis to all parameters in the model. First, we do not attempt to match the level of the cross-sectional variance of log-employment, but only its change over time. This is
because to fit the dispersion in employment, the model would require substantially larger values for both
![]() and
and
![]() . This would allow the model to match
. This would allow the model to match
![]() and
and
![]() but would also imply an excessive rate of growth in
but would also imply an excessive rate of growth in
![]() . However, this shortcoming is not a serious problem. It implies that only a fraction of the observed cohort's employment dispersion can be attributed to
a Bayesian learning process about efficiency. The remaining part could be attributed to heterogeneity in the initial choice of technology.
. However, this shortcoming is not a serious problem. It implies that only a fraction of the observed cohort's employment dispersion can be attributed to
a Bayesian learning process about efficiency. The remaining part could be attributed to heterogeneity in the initial choice of technology.
For instance, consider a model where capital is endogenous and suppose that a firm chooses its initial stock of capital, ![]() , based on the realization of a random variable indexing
technology choice. Assume further that, after selecting
, based on the realization of a random variable indexing
technology choice. Assume further that, after selecting ![]() , the firm keeps its capital stock unchanged for the remainder of its life. If the production function has constant returns to
scale, if the total opportunity cost is proportional to
, the firm keeps its capital stock unchanged for the remainder of its life. If the production function has constant returns to
scale, if the total opportunity cost is proportional to ![]() , i.e.,
, i.e.,
![]() , then we can easily prove that
, then we can easily prove that
![]() , where
, where ![]() is the value function conditional on the chosen
is the value function conditional on the chosen ![]() . Therefore, in this alternative framework, dispersion in
. Therefore, in this alternative framework, dispersion in
![]() would govern the initial dispersion in employment and only the subsequent evolution in employment dispersion would depend on the Bayesian learning process.39 This is the reason why we attempt to match only the evolution of
would govern the initial dispersion in employment and only the subsequent evolution in employment dispersion would depend on the Bayesian learning process.39 This is the reason why we attempt to match only the evolution of
![]() , but not its level. In the estimated models presented in table 6 less than
, but not its level. In the estimated models presented in table 6 less than ![]() of the observed dispersion in the cohort's log-employment can be attributed to the learning process, with the percentage smaller in the manufacturing sector and higher in the services sector.40
of the observed dispersion in the cohort's log-employment can be attributed to the learning process, with the percentage smaller in the manufacturing sector and higher in the services sector.40
Second, the value of
![]() affects the long-run contribution of survivors, since a relatively smaller initial dispersion would make the average size of exiting firms closer to the
average size of surviving firms in the entry period, and in this case most growth would be due to survivors. In the aforementioned extended model with an initial choice over
affects the long-run contribution of survivors, since a relatively smaller initial dispersion would make the average size of exiting firms closer to the
average size of surviving firms in the entry period, and in this case most growth would be due to survivors. In the aforementioned extended model with an initial choice over ![]() , if we had
, if we had
![]() we would have a non-degenerate initial distribution of size, entirely due to the heterogeneity in
we would have a non-degenerate initial distribution of size, entirely due to the heterogeneity in ![]() , but the survivors' component would be
, but the survivors' component would be ![]() in each period. This would occur because the distribution of initial size among exiting firms would be equal
to the distribution of initial size among surviving firms. This also explains why even with heterogeneity over
in each period. This would occur because the distribution of initial size among exiting firms would be equal
to the distribution of initial size among surviving firms. This also explains why even with heterogeneity over ![]() , we would still need to assume
, we would still need to assume
![]() in order to match the empirical facts on the importance of the survivor component.
in order to match the empirical facts on the importance of the survivor component.
While we could increase the long-run contribution of survivors by tinkering with the ratio
![]() , without adjustment costs the model cannot match satisfactorily the observed flatness in the path of the survivor component. For any choice of
, without adjustment costs the model cannot match satisfactorily the observed flatness in the path of the survivor component. For any choice of
![]() and
and
![]() , it will always be the case that the survivor component will exhibit a substantially increasing path in the absence of adjustment costs. Note also that the ratio
, it will always be the case that the survivor component will exhibit a substantially increasing path in the absence of adjustment costs. Note also that the ratio
![]() affects both the exit rate and the evolution of the firm size dispersion. If this ratio becomes too small, post-entry exit rates become excessively high and
the size dispersion increases too fast. This is the reason why in the NAC model we cannot find a value for this ratio that attains the long-run contribution of survivors found in the data, and simultaneously matches the behavior of the cumulative exit rate and the
evolution of the size dispersion. Therefore, the value we select for this ratio is disciplined by the exit rates and the evolution of firm size dispersion in the cohort.
affects both the exit rate and the evolution of the firm size dispersion. If this ratio becomes too small, post-entry exit rates become excessively high and
the size dispersion increases too fast. This is the reason why in the NAC model we cannot find a value for this ratio that attains the long-run contribution of survivors found in the data, and simultaneously matches the behavior of the cumulative exit rate and the
evolution of the size dispersion. Therefore, the value we select for this ratio is disciplined by the exit rates and the evolution of firm size dispersion in the cohort.
Third, to show that proportional adjustment costs are crucial to fit the evidence on the contribution of survivors to growth in the cohort's average size, in figure 4 we perform a sensitivity analysis with respect to each parameter in the model. We take as benchmark the
estimated NAC model for the overall economy cohort in table 6. We vary each parameter around its benchmark value and plot the implied cumulative exit rate and survivor component at four different ages of the cohort (ages ![]() ,
, ![]() ,
, ![]() , and
, and ![]() ). We present both the exit rate and the survivor component to show that the essential shortcoming of the NAC model is the inability to
increase the survivor component without an unreasonable increase in exit rates.
). We present both the exit rate and the survivor component to show that the essential shortcoming of the NAC model is the inability to
increase the survivor component without an unreasonable increase in exit rates.
From figure 4, we see that the model with costless adjustment cannot match satisfactorily the contribution of survivors to growth, even if we allow parameters (except for the proportional cost) to vary one by one from their benchmark values. In fact, no other parameter
besides the proportional cost (in the lower-right plot) can increase the survivor component without changing much the exit rate. In addition, adjustment costs imply more than just a mere level effect on the survivor component, as the increase in the survivor component at age ![]() is larger than the increase at age
is larger than the increase at age ![]() , shrinking the distance between the survivor component at
different ages of the cohort. In summary, the main effect of these costs is to put more emphasis on individual firm growth in the initial years of life, when exit of inefficient firms is very intense.41
, shrinking the distance between the survivor component at
different ages of the cohort. In summary, the main effect of these costs is to put more emphasis on individual firm growth in the initial years of life, when exit of inefficient firms is very intense.41
To emphasize the role of the proportional adjustment cost in replicating the evidence on the contribution of survivors, in figure 5 we present the impact of changes in ![]() on the survivor component, using as benchmark the estimates for the AC model in the overall economy cohort. We conclude that allowing for even a small value of
on the survivor component, using as benchmark the estimates for the AC model in the overall economy cohort. We conclude that allowing for even a small value of ![]() has a substantial impact on the survivors' contribution, with a larger effect in the initial years after entry.
has a substantial impact on the survivors' contribution, with a larger effect in the initial years after entry.
6 Conclusion
In this paper, we show that a model with linear adjustment costs and learning about efficiency generates incentives for firms to enter smaller and, if successful, expand faster after entry. For a cohort of entrant firms in the Portuguese economy, we present evidence showing that growth in the cohorts' average size is driven largely by growth of survivors rather than by pruning of small inefficient firms, with rapid growth of survivors in the initial post-entry years and significant cross-sector differences in the contribution of survivors. A calibration and estimation of the model reveals that the proportional cost is the key parameter to explain the high contribution of survivors to growth in the cohorts' average size. Furthermore, due to a higher contribution of survivors, adjustment costs need to be substantially higher in manufacturing than in services.
The empirical success of our model in better approximating the growth of survivors as the main source for growth suggests that adjustment costs do play a significant role in post-entry firm size adjustments. Our results suggest that selection theories are more relevant to explain firm exit than growth of survivors. Our specification of adjustment costs assumes that they are proportional to the adjustment size and apply equally at entry, exit, and during regular job creation and destruction. These costs could capture aspects such as costs to the organization, layout, and optimization of the production process, and hiring and firing costs. Although we have not collected evidence documenting the nature of these costs, we would expect them to be larger in sectors employing more complex technologies, such as in manufacturing industries. Potentially, part of the adjustment costs we estimate could also reflect the impact of financial frictions, although we would expect these to be concentrated in entry costs associated with the acquisition of capital, and not so much in regular job creation and destruction costs.
More generally, financing constraints theories should also play a role in explaining growth of survivors, besides what can possibly be captured by adjustment costs in our model, although there is not much evidence that financing constraints can explain cross-sector differences. Notwithstanding this, Angelini and Generale's (2008) conclusion that financing constraints are not the main determinant behind the evolution of the firm size distribution suggests that any government intervention to eliminate financing constraints might not change the lifetime dynamics of firm size we find in this paper. In addition, this paper suggests that, in sectors where adjustment costs are high and learning is important, government policies aimed at curbing financing constraints might not produce the intended results, as firms under those circumstances have incentives to start smaller and, if successful, expand faster, even if financing constraints are eliminated.
A. Appendix: Proofs
![\displaystyle \theta_{\tau}^{\ast}=g\left( Y_{\tau},\tau\right) =E\left( \xi\left( \eta_{\tau}\right) \mid Y_{\tau},\tau\right) =\nu_{1}+\int_{-\infty} ^{\infty}\left[ 1-F_{\eta}\left( \eta_{\tau}\mid Y_{\tau},\tau\right) \right] d\xi\left( \eta_{\tau}\right)](img324.gif) ,
,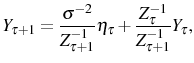
![\displaystyle F\left( \theta_{\tau+1}^{\ast}\mid\theta_{\tau}^{\ast},\tau\right) =F_{\eta }\left[ \frac{Z_{\tau+1}^{-1}}{\sigma^{-2}}g_{Y}^{-1}\left( \theta_{\tau +1}^{\ast},\tau+1\right) -\frac{Z_{\tau}^{-1}}{\sigma^{-2}}g_{Y}^{-1}\left( \theta_{\tau}^{\ast},\tau\right) \mid g_{Y}^{-1}\left( \theta_{\tau}^{\ast },\tau\right) ,\tau\right] \text{,}](img336.gif)
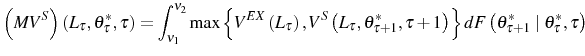 ;
;We prove the proposition in several steps.
- (a.i)
- Existence and Uniqueness: This follows from the Contraction Mapping Theorem and Blackwell's sufficient conditions (see theorems 3.2 and 3.3 in Stokey et al., 1989) .
- (a.ii)
- Continuity in
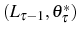 : Let
: Let
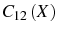 be the space of bounded functions on
be the space of bounded functions on 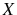 which are continuous in
. This is clearly a closed subset of
which are continuous in
. This is clearly a closed subset of
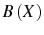 , the space of bounded functions
, the space of bounded functions
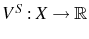 . Since
with the sup norm
. Since
with the sup norm
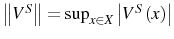 is a Banach space, then
is also a Banach space. Now consider
is a Banach space, then
is also a Banach space. Now consider
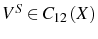 . Because
. Because
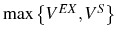 is also continuous and
is also continuous and
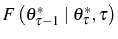 satisfies the Feller property (see lemma 2), then
satisfies the Feller property (see lemma 2), then  is continuous in
is continuous in
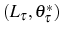 (see lemma 9.5 in Stokey et al., 1989) . Since
(see lemma 9.5 in Stokey et al., 1989) . Since
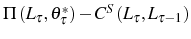 is continuous, then
is continuous, then
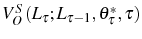 is continuous in
is continuous in
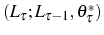 . Therefore, applying the maximum theorem, we conclude that
. Therefore, applying the maximum theorem, we conclude that
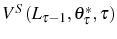 is continuous in
. Note that the set of admissible values for employment can be made compact. First, only non-negative values are acceptable for employment.
Second, we can choose a value for
is continuous in
. Note that the set of admissible values for employment can be made compact. First, only non-negative values are acceptable for employment.
Second, we can choose a value for 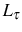 high enough, say
high enough, say 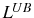 , such that
, such that
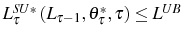 , for all
, for all
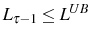 , so that all values of interest are considered. is
finite since
, so that all values of interest are considered. is
finite since
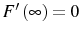 , and is bounded. Therefore,
, and is bounded. Therefore, 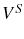 as defined by (4) is continuous in
.
as defined by (4) is continuous in
. - (a.iii)
- Strict Monotonicity in
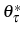 : From lemma 2 (the transition function associated with
: From lemma 2 (the transition function associated with
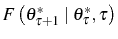 is monotone) if
is monotone) if
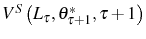 is weakly increasing in
is weakly increasing in
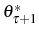 , then
, then
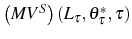 is also weakly increasing in
. Then, because
is also weakly increasing in
. Then, because
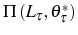 is strictly increasing in
(and the constraint set is not affected by
),
is strictly increasing in
(see theorem 9.11 in Stokey et al., 1989) .
is strictly increasing in
(and the constraint set is not affected by
),
is strictly increasing in
(see theorem 9.11 in Stokey et al., 1989) . - (b)
- Exit Policy: The exit policy is determined by the condition
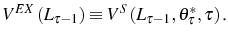 Because, for each
Because, for each
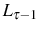 ,
, 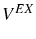 is constant and is strictly increasing in
, then it is obvious that
is constant and is strictly increasing in
, then it is obvious that
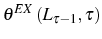 is a unique function defined by the value of
is a unique function defined by the value of
![\theta^{\ast}\in\left[ \nu_{1},\nu_{2}\right]](img369.gif) that satisfies the above equation, if it exists, or by
that satisfies the above equation, if it exists, or by 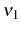 , when
, when
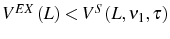 , or by
, or by  , when
, when
 . Because both and are continuous functions, then
. Because both and are continuous functions, then
 is also a continuous function in
is also a continuous function in 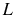 .
.
Let
Proof of proposition 5. We prove this by induction. In period
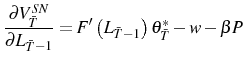 .
We conclude that
.
We conclude that
Now consider a generic period
Proof of proposition 6. For given
If it is optimal for the firm to adjust upwards, then we must solve
![\displaystyle A_{SU}=\left[ F^{\prime}\left( L_{\tau}^{\ast}\right) \theta_{\tau}^{\ast }-\left( w+P\right) \right] +\beta\frac{\partial\left( MV^{S}\right) \left( L_{\tau}^{\ast},\theta_{\tau}^{\ast},\tau\right) }{\partial L}=0\text{,}](img414.gif) and if it is optimal for the firm to adjust downwards, we must solve
and if it is optimal for the firm to adjust downwards, we must solve
![\displaystyle A_{SD}=\left[ F^{\prime}\left( L_{\tau}^{\ast}\right) \theta_{\tau}^{\ast }-\left( w-P\right) \right] +\beta\frac{\partial\left( MV^{S}\right) \left( L_{\tau}^{\ast},\theta_{\tau}^{\ast},\tau\right) }{\partial L}=0](img415.gif) Now, the derivative can be rewritten as
Now, the derivative can be rewritten as
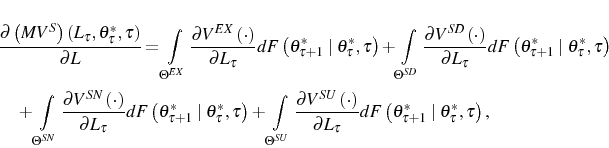
where some of the regions might be empty, and in separating the integrals we have taken into account the continuity of the integrand in
For each of the above derivatives we have
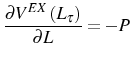 ,
,
![\displaystyle \left. \frac{\partial V^{SD}\left( \cdot\right) }{\partial L}\right\vert _{\theta_{\tau+1}^{\ast}\in\Theta^{SD}\left( L_{\tau},\tau+1\right) }=-P=\left[ F^{\prime}\left( L_{\tau+1}^{\ast}\right) \theta_{\tau+1} ^{\ast}-w\right] +\beta\frac{\partial\left( MV^{S}\right) \left( L_{\tau+1}^{\ast},\theta_{\tau+1}^{\ast},\tau+1\right) }{\partial L}\text{,}](img418.gif)
![\displaystyle \frac{\partial V^{SN}\left( \cdot\right) }{\partial L_{\tau}}=\left[ F^{\prime}\left( L_{\tau}\right) \theta_{\tau+1}^{\ast}-w\right] +\beta\frac{\partial\left( MV^{S}\right) \left( L_{\tau},\theta_{\tau +1}^{\ast},\tau+1\right) }{\partial L}\text{,}](img419.gif)
![\displaystyle \left. \frac{\partial V^{SU}\left( \cdot\right) }{\partial L}\right\vert _{\theta_{\tau+1}^{\ast}\in\Theta^{SU}\left( L_{\tau},\tau+1\right) }=P=\left[ F^{\prime}\left( L_{\tau+1}^{\ast}\right) \theta_{\tau+1}^{\ast }-w\right] +\beta\frac{\partial\left( MV^{S}\right) \left( L_{\tau +1}^{\ast},\theta_{\tau+1}^{\ast},\tau+1\right) }{\partial L}\text{,}](img420.gif)
where we have used the fact that
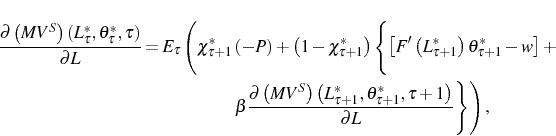
Using the law of iterated expectations, we can rewrite the above as
![\displaystyle \frac{\partial\left( MV^{S}\right) \left( L_{\tau}^{\ast},\theta_{\tau }^{\ast},\tau\right) }{\partial L}=\sum_{s=1}^{\infty}E_{\tau}\beta ^{s-1}\left\{ \tilde{\chi}_{\tau+s}^{\ast}\left( -P\right) +\hat{\chi }_{\tau+s}^{\ast}\left[ F^{\prime}\left( L_{\tau+s}^{\ast}\right) \theta_{\tau+s}^{\ast}-w\right] \right\} \text{,}](img424.gif) The result now follows by plugging this expression in
The result now follows by plugging this expression in Proof of corollary 7. We can rewrite the LHS of (6) and (7) as follows
![\begin{multline*} MB_{\tau}=\left( F^{\prime}\left( L_{\tau}^{\ast}\right) \thet... ...ast}\right) \theta_{\tau+1+s}^{\ast}-w\right) \right] \right\} . \end{multline*}](img427.gif)
Taking into account that
Proof proposition 8. With proportional costs, optimal employment at entry is determined by
![\begin{multline*} F^{\prime}\left( L_{1}\right) \theta_{1}^{\ast}-\left( w+P^{H}\right) +\beta\left( \int_{\nu_{1}}^{\theta^{SD}}-P^{F}dF_{\theta_{1}^{\ast}}\left( \theta_{2}^{\ast}\right) +\right. \ \left. \int_{\theta^{SD}}^{\theta^{SU}}\left\{ \delta_{\bar{T}}\left[ F^{\prime}\left( L_{1}\right) \theta_{2}^{\ast}-w\right] -\beta^{\bar{T} -1}P^{F}\right\} dF_{\theta_{1}^{\ast}}\left( \theta_{2}^{\ast}\right) +\int_{\theta^{SU}}^{\nu_{2}}P^{H}dF_{\theta_{1}^{\ast}}\left( \theta _{2}^{\ast}\right) \right) =0 \end{multline*}](img432.gif)
(a) In the case of a proportional hiring cost, assuming
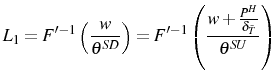 ,
, |
|
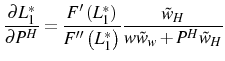 , , |
|
After some algebra we get
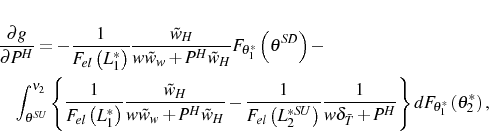
where
![\begin{multline*} \frac{\partial g}{\partial P^{H}}=\left( 1-\alpha\right) ^{-1}\left( \frac{\tilde{w}_{H}}{w\tilde{w}_{w}+P^{H}\tilde{w}_{H}}\left\{ F_{\theta _{1}^{\ast}}\left( \theta^{SD}\right) +\left[ 1-F_{\theta_{1}^{\ast} }\left( \theta^{SU}\right) \right] \right\} -\right. \ \left. \frac{1}{w\delta\left( \bar{T}\right) +P^{H}}\left[ 1-F_{\theta _{1}^{\ast}}\left( \theta^{SU}\right) \right] \right) \text{,} \end{multline*}](img441.gif)
which is positive when
(b) In the case of a proportional firing cost, assuming
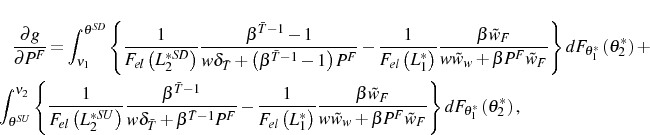
where
Under the assumption that marginal productivity is always positive, we need
![\begin{multline*} \frac{\partial g}{\partial P^{H}}=\left( 1-\alpha\right) ^{-1}... ...1-F_{\theta_{1}^{\ast}}\left( \theta^{SU}\right) \right] \right) \end{multline*}](img447.gif)
which is positive for all
For the distribution of
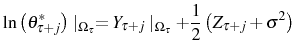 |
|
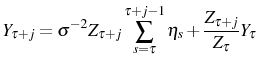 , , |
|
so that, in the end, we get
![\displaystyle E\left[ \ln\left( \theta_{\tau+j}^{\ast}\right) \mid\Omega_{\tau}\right] =Y_{\tau}+\frac{1}{2}\left( Z_{\tau+j}+\sigma^{2}\right)](img457.gif) ,
, |
|
From here the result follows by noting that
For the unconditional distribution, just note that
![]() is a sum of normal random variables, and that
is a sum of normal random variables, and that
![\displaystyle E\left[ \ln\left( \theta_{\tau}^{\ast}\right) \right] =\bar{\mu}+\frac {1}{2}\left( Z_{\tau}+\sigma^{2}\right)](img461.gif) |
|
![\begin{multline*} V^{S}\left( \theta_{T}^{\ast},L_{s-1},T\right) =\max_{L_{s}\geq0,\chi_{s} \in\left\{ 0,1\right\} }\left\{ \left[ \Pi\left( L_{s},\theta_{T}^{\ast }\right) -C^{S}\left( L_{s},L_{s-1}\right) \right] +\right. \ \left. \beta\left\{ \chi_{s}\left[ W-C^{EX}\left( L_{\tau+s}\right) \right] +\left( 1-\chi_{s}\right) V^{S}\left( \theta_{T}^{\ast} ,L_{s},T\right) \right\} \right\} \text{.} \end{multline*}](img467.gif)
Consider a firm that is in the industry at time
Therefore, at time
We now prove that the firm does not exit at time ![]() after remaining in the industry at time
after remaining in the industry at time ![]() ,
, ![]() . Because the firm stays at time
. Because the firm stays at time ![]() , then
, then
![]() . Now assume that in period
. Now assume that in period ![]() the firm exits, so that
the firm exits, so that
which is a contradiction
B. Appendix: Simulation and Estimation Algorithm
- (i) Discretization and transition probability matrices associated with
 :
: - We discretize
with a uniform discrete approximation (with
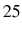 mass points) to the distribution
mass points) to the distribution 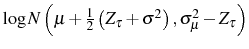 .
.
We then use Tauchen's (1986) method to build the transition matrices, computing integrals via Gauss-Legendre quadrature. - (ii) Discretization of
- Based on the decision rules for problem (11) we consider
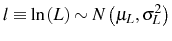 ,
,
![\displaystyle \mu_{L}=\frac{1}{1-\alpha}\left\{ \bar{\mu}+\frac{1}{2}\sigma^{2}+\ln\left( \frac{\alpha p}{\sqrt{\left[ w+P^{SU}+\beta P^{EX}\right] \left[ w-\left( 1-\beta\right) P^{SD}\right] }}\right) \right\}](img485.gif) ,
,
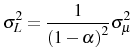 .
.
For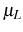 we assume that at the upper end of the grid the firm decreases employment, and at the lower end of the grid the firm increases employment and exits next period. We then discretize similarly to (with
we assume that at the upper end of the grid the firm decreases employment, and at the lower end of the grid the firm increases employment and exits next period. We then discretize similarly to (with 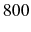 mass points) using a unique grid for all periods.
mass points) using a unique grid for all periods. - (iii) Choice for
- We choose
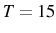 , and display results until period
, and display results until period 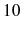 .
. - (iv) Model simulation
- For a given set of parameters we numerically compute the optimal entry, employment, and exit policy rules.
First, for each grid point, we compute optimal employment in
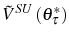
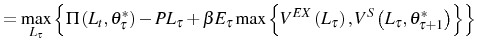 ,
,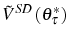
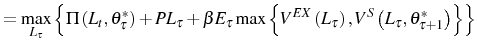 ,
,
as these do not depend on. We first find the maximizer on the grid for and then use a golden section
method to obtain a more precise maximizer.44 Second, we get 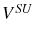 and
and 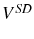 , determine the inaction regions, and get . Third,
we compute all endogenous decisions associated with each realization of the
, determine the inaction regions, and get . Third,
we compute all endogenous decisions associated with each realization of the
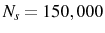 random lifetime histories of
random lifetime histories of
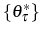 . Fourth, we compute the (simulated) moments.
. Fourth, we compute the (simulated) moments. - (v) Moments used in estimation
- Let
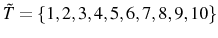 . We consider four sets of moments:
. We consider four sets of moments: - (a) Exit rate: For
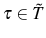 ,
, 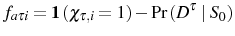
- (b) Average current size conditional on survival: For
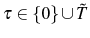 ,
, ![\displaystyle f_{b\tau i}=l_{\tau,i}\mathbf{1}\left( \chi_{\tau,i}=0\right) -E\left[ l_{\tau}\mid S_{\tau}\right] \Pr\left( S_{\tau}\mid S_{0}\right)](img500.gif)
- (c) Relative change in variance of current size conditional on survival: For ,45
![\begin{multline*} f_{c\tau i}=\left\{ l_{\tau,i}-E\left[ l_{\tau}\mid S_{\tau}\right] \right\} ^{2}\mathbf{1}\left( \chi_{\tau,i}=0\right) -\left\{ l_{0,i} ^{2}-E\left[ l_{0}\mid S_{0}\right] ^{2}\right\} \times\ \left\{ E[l_{\tau}^{2}\mid S_{\tau}]-E\left[ l_{\tau}\mid S_{\tau}\right] ^{2}\right\} \Pr\left( S_{t}\mid S_{0}\right) /\left\{ E[l_{0}^{2}\mid S_{0}]-E\left[ l_{0}\mid S_{0}\right] ^{2}\right\} \end{multline*}](img502.gif)
- (d) Average entry size conditional on survival: For ,46
![\displaystyle f_{d\tau i}=l_{0,i}\mathbf{1}\left( \chi_{\tau,i}=0\right) -E\left[ l_{0}\mid S_{\tau}\right] \Pr\left( S_{\tau}\mid S_{0}\right)](img504.gif)
- (vi) Weighting matrix
The weighting matrix is estimated as the sample covariance matrix of the moments in (v), adjusted for the simulation size
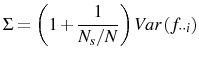
![\displaystyle f_{\cdot\cdot i}=[f_{a\cdot i}^{\prime}~~f_{b\cdot i}^{\prime }~~f_{c\cdot i}^{\prime}~~f_{d\cdot i}^{\prime}]^{\prime}](img506.gif)
- (vii) Estimation method
We use a simulated annealing method to search for the set of parameter values
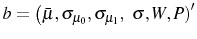 that minimizes the method of moments objective function,47
that minimizes the method of moments objective function,47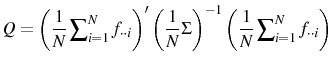
- (viii) Standard errors
The standard errors of the estimated parameters are obtained as follows
![\displaystyle std(\hat{b})=\left[ \left( \frac{\partial\left( N^{-1}\sum_{i=1} ^{N}f_{\cdot\cdot i}\left( \hat{b}\right) \right) }{\partial b^{\prime} }\right) ^{\prime}\left( \frac{1}{N}\Sigma\right) ^{-1}\left( \frac{\partial\left( N^{-1}\sum_{i=1}^{N}f_{\cdot\cdot i}\left( \hat {b}\right) \right) }{\partial b^{\prime}}\right) \right] ^{-1}\text{,}](img510.gif)
where the matrix of derivatives is computed numerically.
References
| Year | CumEx | AvEmp | CGrEmp | SurComp |
| 1988 | 1.11 | |||
| 1989 | 15.6 | 1.27 | 15.2 | 69.5 |
| 1990 | 24.4 | 1.36 | 24.8 | 70.4 |
| 1991 | 30.8 | 1.43 | 31.2 | 69.7 |
| 1992 | 35.4 | 1.46 | 34.2 | 69.3 |
| 1993 | 40.0 | 1.46 | 34.6 | 68.9 |
| 1994 | 43.4 | 1.47 | 35.3 | 69.1 |
| 1995 | 46.7 | 1.48 | 36.1 | 68.7 |
| 1996 | 49.9 | 1.49 | 37.4 | 67.2 |
| 1997 | 52.7 | 1.51 | 39.6 | 68.5 |
| 1998 | 55.5 | 1.52 | 40.7 | 68.3 |
| 1999 | 58.5 | 1.54 | 43.0 | 68.9 |
| Sector | EmpSh 88 | CumEx 89 | CumEx 92 | CumEx 99 | AvEmp 88 | CGrEmp 89 | CGrEmp 92 | CGrEmp 99 | SurComp 88-89 |
|---|---|---|---|---|---|---|---|---|---|
| All | 100.0 | 15.6 | 35.4 | 58.5 | 1.11 | 15.2 | 34.2 | 43.0 | 69.0 |
| Manu | 41.8 | 14.6 | 35.9 | 58.9 | 1.58 | 17.4 | 38.7 | 45.5 | 82.8 |
| Serv | 20.1 | 17.1 | 36.6 | 58.0 | 0.99 | 11.7 | 30.8 | 40.2 | 61.7 |
| Sector | ||||||
|---|---|---|---|---|---|---|
|
All |
7.9 | 43.0 | 13.7 | 13.7 | 45.3 | 17.1 |
| Manu | 10.8 | 31.5 | 20.7 | 20.9 | 33.4 | 24.6 |
| Serv | 7.3 | 47.7 | 11.8 | 11.3 | 50.3 | 15.0 |
| Parameter | All NAC | All AC | Manu NAC | Manu AC | Serv NAC | Serv AC |
|---|---|---|---|---|---|---|
| 0.56 | 0.56 | 0.57 | 0.57 | 0.73 | 0.73 | |
| 0.956 | 0.956 | 0.956 | 0.956 | 0.956 | 0.956 | |
| 11.8 | 11.8 | 13.1 | 13.1 | 7.5 | 7.5 | |
| 2.923 | 3.196 | 3.368 | 3.755 | 2.393 | 2.419 | |
| (0.016) | (0.038) | (0.032) | (0.012) | (0.018) | (0.014) | |
|
|
0.245 | 0.188 | 0.236 | 0.083 | 0.133 | 0.123 |
|
|
(0.005) | (0.008) | (0.009) | (0.004) | (0.006) | (0.006) |
|
|
0.319 | 0.250 | 0.296 | 0.186 | 0.166 | 0.154 |
|
|
(0.005) | (0.008) | (0.010) | (0.006) | (0.006) | (0.006) |
| 0.884 | 0.661 | 0.707 | 0.440 | 0.436 | 0.402 | |
| (0.016) | (0.036) | (0.034) | (0.016) | (0.021) | (0.018) | |
| 767.5 | 815.2 | 1294.5 | 1494.2 | 200.2 | 198.7 | |
| (5.2) | (8.2) | (18.6) | (21.9) | (3.1) | (3.5) | |
| 0 | 0.74 | 0 | 2.17 | 0 | 0.06 | |
| (0.05) | (0.07) | (0.02) | ||||
| 89.1 | 64.0 | 167.6 | 90.0 | 19.8 | 17.8 | |
| 1866.9 | 1516.9 | 700.0 | 423.9 | 356.1 | 351.5 |
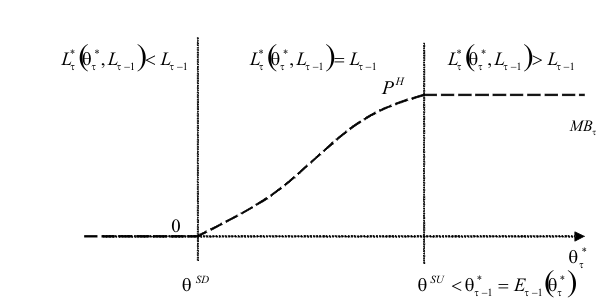
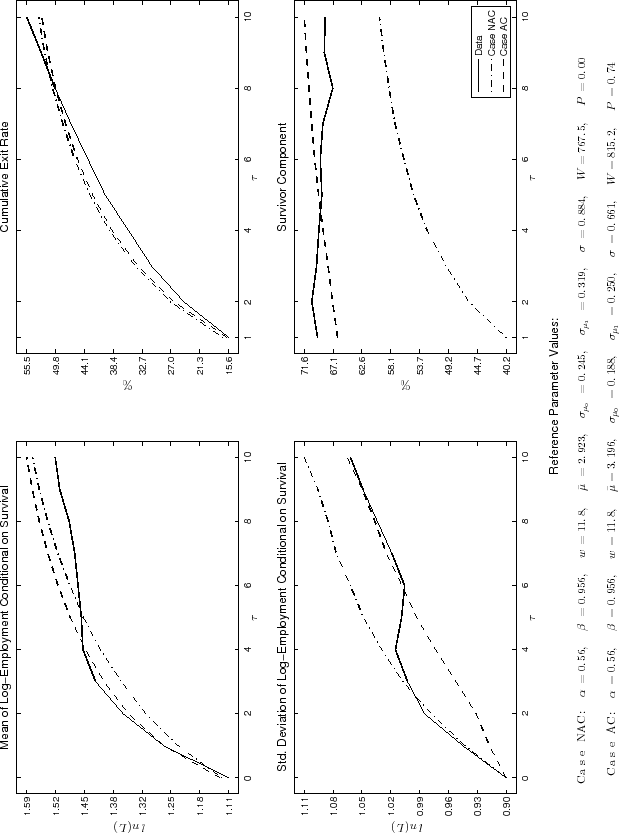
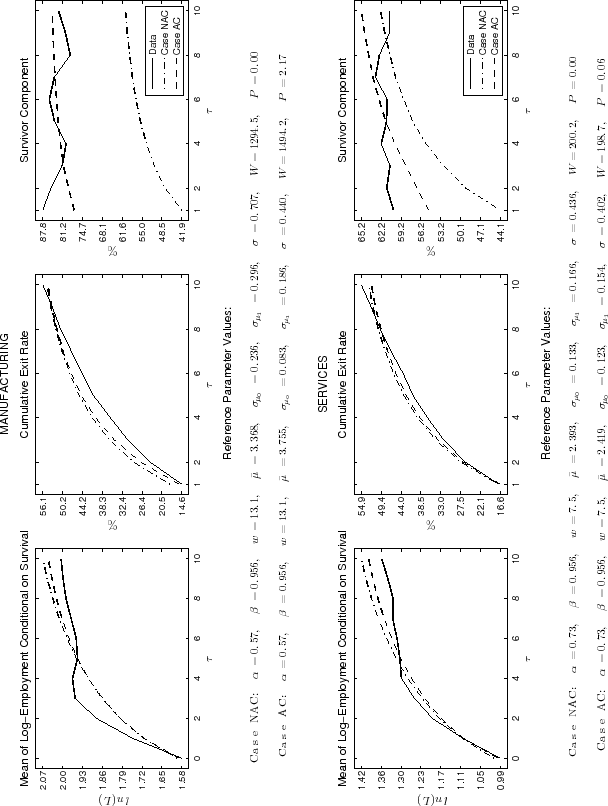
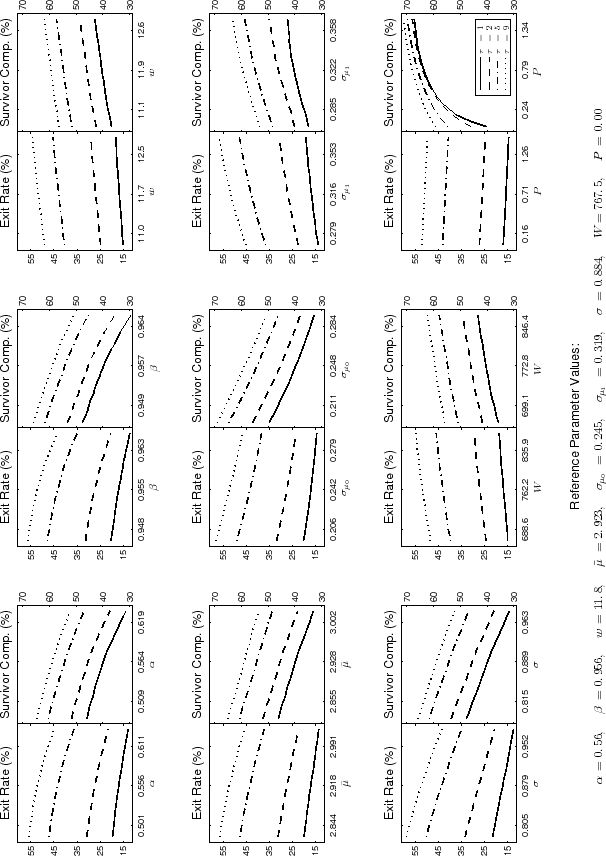
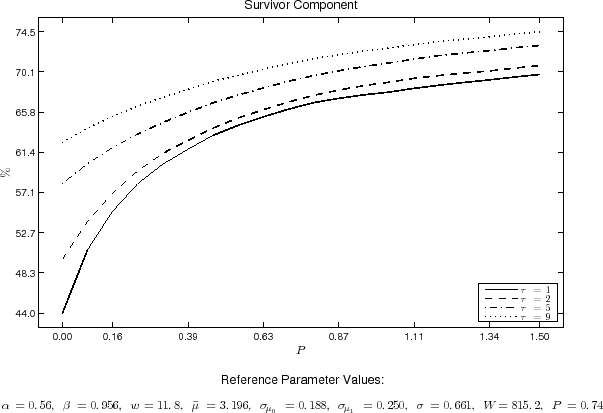
Footnotes