
Lack of Signal Error (LoSE) and Implications for OLS Regression: Measurement Error for Macro Data
Keywords: Measurement error, regression, macroeconomic data
Abstract:
1 Introduction
This paper proposes a simple generalization of the classical measurement error model and studies its implications for ordinary least squares (OLS) regression. The usual model starts with the true variable of interest and adds noise, which we call classical measurement error (CME); see Klepper and Leamer (1984), Griliches (1986), Fuller (1987), Leamer (1987), Angrist and Krueger (1999), Bound, Brown and Mathiowetz (2001) or virtually any econometrics textbook. The generalization discussed here incorporates a different kind of measurement error that subtracts signal from the true variable; this new error term is called the Lack of Signal Error, or LoSE for short. This additional term adds some much-needed flexibility to the classical measurement error model: it allows the mismeasured variable to have either more or less variance than the true variable of interest, in contrast to the classical model, which imposes that the mismeasured variable has higher variance. This restriction does not hold in some important applications in macroeconomics and elsewhere.
The implications of LoSE for OLS regression are opposite the usual intuition about measurement error, which is applicable to CME only. The CME intuition says that measurement error in the dependent variable ![]() of a regression poses no real problems for standard estimation and inference. Parameter estimates are unbiased and consistent, while hypotheses are more difficult to reject because CME increases the variance of regression residuals and thus standard errors. CME in the
explanatory variables
of a regression poses no real problems for standard estimation and inference. Parameter estimates are unbiased and consistent, while hypotheses are more difficult to reject because CME increases the variance of regression residuals and thus standard errors. CME in the
explanatory variables ![]() causes the real problems for OLS regression, namely attenuation bias and inconsistency. However with LoSE these results are reversed. For the baseline case considered
here, LoSE in the explanatory variables
causes the real problems for OLS regression, namely attenuation bias and inconsistency. However with LoSE these results are reversed. For the baseline case considered
here, LoSE in the explanatory variables ![]() produces no bias or inconsistency while increasing standard errors, similar to CME in
produces no bias or inconsistency while increasing standard errors, similar to CME in ![]() . It is LoSE in the dependent variable
. It is LoSE in the dependent variable ![]() that introduces an attenuation-type bias and inconsistency into the regression under some
circumstances (in particular, when the explanatory variables contain some signal missing from the dependent variable). This point is obvious when we consider the extreme case of maximum LoSE in
that introduces an attenuation-type bias and inconsistency into the regression under some
circumstances (in particular, when the explanatory variables contain some signal missing from the dependent variable). This point is obvious when we consider the extreme case of maximum LoSE in ![]() , so
, so ![]() is just a constant equal to its unconditional mean. Then a standard OLS regression of
is just a constant equal to its unconditional mean. Then a standard OLS regression of ![]() on any explanatory variable
on any explanatory variable ![]() with positive variance recovers
with positive variance recovers
![]() , regardless of the true
, regardless of the true ![]() . In addition, LoSE in
. In addition, LoSE in ![]() shrinks the variance of regression residuals, thus shrinking parameter standard errors compared to what they would be without this
type of mismeasurement. The standard errors are zero in our extreme case, and this raises concerns about the robustness of hypothesis tests.
shrinks the variance of regression residuals, thus shrinking parameter standard errors compared to what they would be without this
type of mismeasurement. The standard errors are zero in our extreme case, and this raises concerns about the robustness of hypothesis tests.
Much of the econometrics literature on non-classical measurement error has focused on binary or categorical response data, for which the classical measurement error assumptions cannot hold; see Card (1996), Bollinger (1996), and Kane, Rouse and Staiger (1999). In a more general linear regression
context, Berkson (1950) was an early paper tackling some of the issues addressed here; see the discussion in Durbin (1954), Griliches (1986, section 4), and Fuller (1987, section 1.6.4). Berkson had in mind a regression using "controlled" measurements as the explanatory variable ![]() , readings from a scientific experiment where the unobserved true values of interest
, readings from a scientific experiment where the unobserved true values of interest ![]() fluctuate around the observed controlled measurements in a random way. Berkson showed that if the unobserved fluctuations
fluctuate around the observed controlled measurements in a random way. Berkson showed that if the unobserved fluctuations ![]() are uncorrelated with the measurements
are uncorrelated with the measurements ![]() , then regression parameter estimates are unbiased. The literature following Berkson has generally focused on extending his results to regressions employing non-linear functions of
, then regression parameter estimates are unbiased. The literature following Berkson has generally focused on extending his results to regressions employing non-linear functions of ![]() ; see Geary (1953), Federov (1974), Carroll and Stefanski (1990), Huwang and Huang (2000), and Wang (2003, 2004). This literature has focused less on the implications of "controlled" measurements of
the dependent variable
; see Geary (1953), Federov (1974), Carroll and Stefanski (1990), Huwang and Huang (2000), and Wang (2003, 2004). This literature has focused less on the implications of "controlled" measurements of
the dependent variable ![]() .
.
Other papers discussing different LoSE-related estimation issues include Sargent (1989), Bound, Brown and Mathiowetz (2001), and Kimball, Sahm and Shapiro (2008). Perhaps the closest paper to this one is Hyslop and Imbens (2001), which shows some of the major implications of LoSE, while
simultaneously considering the implications of a different problem, correlation between the measurement error in ![]() and the regression error. In defining the LoSE in a variable as the
difference between its true value and a conditional expectation of that true value, we consider arbitrary conditioning information sets
and the regression error. In defining the LoSE in a variable as the
difference between its true value and a conditional expectation of that true value, we consider arbitrary conditioning information sets ![]() ; Hyslop and Imbens (2001) consider information sets
consisting of only mismeasured
; Hyslop and Imbens (2001) consider information sets
consisting of only mismeasured ![]() and mismeasured
and mismeasured ![]() in a univariate regression
context. Considering general information sets allows us to derive more general results, clarifying under what conditions LoSE produces attenuation bias and what instruments are valid in addressing that bias.
in a univariate regression
context. Considering general information sets allows us to derive more general results, clarifying under what conditions LoSE produces attenuation bias and what instruments are valid in addressing that bias.
A large body of empirical work has now accumulated on mismeasurement of microeconomic survey data, which generally rejects the CME assumptions and points to negative correlation between the measurement errors and the true variables of interest; see Bound and Krueger (1991), Bound, Brown, Duncan and Rodgers (1994), Pishcke (1995), Bollinger (1998), Bound, Brown and Mathiowetz (2001) and the references therein, and Escobal and Laszlo (2008). Such negative correlation is an implication of LoSE, although other measurement error models may generate such a result as well. The empirical work in this paper focuses on a different type of data, namely US macroeconomic quantity data such as gross domestic product (GDP) and gross domestic income (GDI). These data pass through numerous revisions, and the more poorly-measured initial estimates have less variance than the revised estimates, providing a concrete example of measurement error that cannot be CME; see Mankiw and Shapiro (1986).
After providing a brief introductory motivation for the generalized measurement error model in Section 2 and showing the implications for OLS regression in Section 3, Section 4.1 of the paper discusses the nature of the source data used to compute US macroeconomic quantity data, and points out some reasons why LoSE may be present in the estimates even after they have passed through all their revisions. GDP growth and GDI growth measure the same underlying concept, but use different source data; see Fixler and Nalewaik (2007) and Nalewaik (2007a). Since the two measures are far from equal in the fully-revised quarterly or annual frequency data, some mismeasurement must remain in either GDP or GDI growth. Section 4.2 reviews the evidence in Fixler and Nalewaik (2007) and Nalewaik (2007a,b) supporting the notion that this mismeasurement is largely LoSE in GDP growth. Some simple calculations comparing GDP and GDI growth show that this LoSE in GDP growth is likely substantial: after 1984, at least 30% of the variance of the true growth rate of the economy appears to be missing.
In a wide variety of econometric specifications employed in the macroeconomics and finance, variables like GDP growth, investment growth and consumption growth are regressed on asset prices - interest rates, stock price changes, exchange rate changes, etc. These regressions are of particular interest because asset prices potentially capture some signal missing from the mismeasured quantities, implying attenuation-type biases in the coefficients. Section 4.3 tests for these biases, regressing output growth measures contaminated with different degrees of LoSE on a fixed set of stock or bond prices. In cases where we suspect the dependent variable is contaminated with more LoSE, the regression coefficients are smaller, and the differences across regressions are often statistically significant. For example, the coefficients increase when we switch the dependent variable from the early GDP growth estimates based on limited source data to later GDP growth estimates based on more-comprehensive data. Tellingly, the coefficients increase again when we switch the dependent variable from GDP growth to GDI growth. The hypothesis that measurement error in the dependent variable does not bias OLS regression coefficients, a core piece of conventional wisdom in the profession, is rejected by the data, just as the paper predicts if the measurement error is LoSE.
Section 5 concludes the paper with a review of some of the major implications of substantial LoSE in GDP growth. Implications for econometric practice are discussed, using examples of popular regressions in macroeconomics.
2 A Generalization of the Classical Measurement Error Model
Let ![]() be the true value of the variable of interest,
be the true value of the variable of interest, ![]() be a
mismeasured estimate of that variable, and
be a
mismeasured estimate of that variable, and ![]() be a
be a
![]() vector of possibly stochastic variables used to construct
vector of possibly stochastic variables used to construct ![]() . In many cases a government statistical agency or some other organization computes
. In many cases a government statistical agency or some other organization computes ![]() based on information from surveys, administrative records, and other data sources
(source data for short); then
based on information from surveys, administrative records, and other data sources
(source data for short); then ![]() will be variables drawn from the source data, possibly including non-linear functions of the original source data.
will be variables drawn from the source data, possibly including non-linear functions of the original source data.
Under the classical measurement error model,
The term
Under the generalized model of mismeasurement considered here, the mismeasured estimate ![]() is as in Fixler and Nalewaik (2007):
is as in Fixler and Nalewaik (2007):
| (1) |
The CME term
Define the deviation of the variable of interest from its conditional expectation as:
| (2) |
This deviation represents the information about
| (3) |
Thinking of
Taking variances of (3), the LoSE is clearly correlated with ![]() , with
, with
![]() in fact, so:
in fact, so:
| (4) |
Depending on whether the variance of the LoSE is greater than or less than the variance of the CME, the variance of the estimate
While the generalized model here is less restrictive than the CME model, some restrictions do remain. Writing:
| (5) |
the zero covariance between
In the case of GDP and GDI growth, the model
![]() does not fit the facts, as the discussion of table 3A and 3B in section 4.3 makes clear. In general, an important goal of all creators
of data (government statistical agencies as well as other groups) is to avoid systematic mismeasurement like that described in the previous paragraph. Indeed, their ultimate goal is probably to produce estimates
does not fit the facts, as the discussion of table 3A and 3B in section 4.3 makes clear. In general, an important goal of all creators
of data (government statistical agencies as well as other groups) is to avoid systematic mismeasurement like that described in the previous paragraph. Indeed, their ultimate goal is probably to produce estimates ![]() that are as close as possible to
that are as close as possible to
![]() , with as broad an information set
, with as broad an information set ![]() as
possible given resource constraints. As such, the generalized model (1) is a useful benchmark, and should approximate well the underlying mismeasurement in many situations. It also has the advantage of being mathematically tractable, and the symmetry between adding noise and subtracting signal is
intuitive and appealing.
as
possible given resource constraints. As such, the generalized model (1) is a useful benchmark, and should approximate well the underlying mismeasurement in many situations. It also has the advantage of being mathematically tractable, and the symmetry between adding noise and subtracting signal is
intuitive and appealing.
Before concluding this section, it is worth emphasizing that ![]() need not be an exhaustive information set - i.e. it need not contain all available relevant pieces of information about
unobserved
need not be an exhaustive information set - i.e. it need not contain all available relevant pieces of information about
unobserved ![]() . Resource and other constraints certainly preclude this from being the case, and the sections below considering the implications of LoSE allow for this possibility.
. Resource and other constraints certainly preclude this from being the case, and the sections below considering the implications of LoSE allow for this possibility.
3 Implications for OLS Estimation
Consider ordinary least squares estimation of the relation between a mismeasured variable ![]() and a
and a
![]() set of mismeasured explanatory variables
set of mismeasured explanatory variables ![]() , using a
sample of length
, using a
sample of length ![]() . When stacking together the observations, time subscripts are dropped for convenience:
. When stacking together the observations, time subscripts are dropped for convenience:
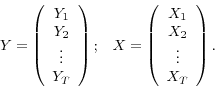 |
Our full set of assumptions follows:
- The CME
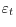 is i.i.d., mean zero, and independent of all conditioning information sets, with
is i.i.d., mean zero, and independent of all conditioning information sets, with
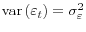 .
. 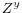 may be partitioned into two sets of variables,
may be partitioned into two sets of variables, 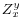 and
and 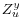 , with variables in independent of
, with variables in independent of 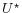 and , and variables in independent of
and , and variables in independent of 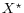 and .
and .- The LoSE
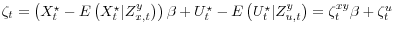 .
. 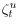 is i.i.d. and mean zero with
is i.i.d. and mean zero with
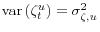 , and
, and
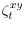 is i.i.d. and mean zero with
is i.i.d. and mean zero with
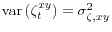 , a
, a
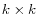 matrix.
matrix.
- The CME
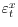 is i.i.d., mean zero, independent of
and all conditioning information sets, with
is i.i.d., mean zero, independent of
and all conditioning information sets, with
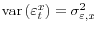 , a
matrix.
, a
matrix. - The variables in
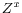 are independent of and
are independent of and 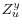 .
. - The LoSE
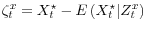 is i.i.d. and mean zero with
is i.i.d. and mean zero with
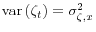 , a
matrix.
, a
matrix. - As
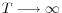 :
:
-
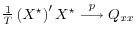
-
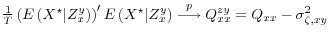
-
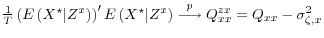
-
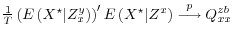
-
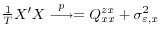 .
.
-
The assumptions imposed on the information sets ![]() and
and ![]() regarding
partitioning and independence allow us to factor the joint distribution of the relevant variables as follows:
regarding
partitioning and independence allow us to factor the joint distribution of the relevant variables as follows:
Without these assumptions, the conditioning may introduce correlation between the measurement error in
Given assumption 1, ![]() can be written as:
can be written as:
| (6) | |||
The OLS regression estimator is:
| (7) |
Consider the sources of bias and inconsistency in this estimate. It is well known that the CME in
| (8) | |||
| (9) |
The usual attenuation bias and inconsistency from CME in
The inconsistency of
![]() can be corrected by instrumenting with a
can be corrected by instrumenting with a
![]() set of instruments
set of instruments ![]() , with
, with ![]() , if the instruments meet the following set of assumptions:
, if the instruments meet the following set of assumptions:
| (10) |
and
where
The first two terms converge in probability to
3.1 X Mismeasured, Y Not Mismeasured: No LoSE Problems
Given the traditional focus on mismeasurement in ![]() on regression estimation, we begin with this subsection making the following assumption, in addition to assumption 1:
on regression estimation, we begin with this subsection making the following assumption, in addition to assumption 1:
Not all of the true variation in
The OLS regression estimator in this case is:
Since
Of course, the CME in ![]() produces the usual attenuation bias. By way of review, and for comparison with later results:
produces the usual attenuation bias. By way of review, and for comparison with later results:
| (11) | |||
| (12) |
Instruments uncorrelated with the CME in
To focus more tightly on the implications of LoSE, the remainder of this subsection considers the case of no CME in ![]() :
:
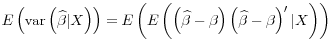 |
|||
Asymptotically, the analogous distributional results hold, as:
and
3.2 Y Mismeasured, X Not Mismeasured,
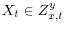 : Shrunken Standard Errors
: Shrunken Standard Errors
In addition to assumption 1, this subsection makes the following assumptions:
Since
![]() , we have:
, we have:
![]() in this case. The LoSE impacts only
in this case. The LoSE impacts only ![]() , so
, so
![]() , and
, and
![]() . The OLS regression estimates
. The OLS regression estimates
![]() as:
as:
LoSE in
The standard errors around the point estimates are more interesting. For the variance of the point estimates,
![]() since
since
![]() = 0, and:
= 0, and:
since
Power is typically considered an unambiguous good thing, so is the LoSE in ![]() the type of measurement error we want? To understand some of the issues here, consider a fable. An
econometrician regresses
the type of measurement error we want? To understand some of the issues here, consider a fable. An
econometrician regresses ![]() on
on ![]() , estimating
, estimating
![]() , but cannot reject the hypothesis of interest,
, but cannot reject the hypothesis of interest,
![]() , because the standard errors are too large. Instead of stopping there, the econometrician decides to employ some other variables at his disposal, a list of variables
, because the standard errors are too large. Instead of stopping there, the econometrician decides to employ some other variables at his disposal, a list of variables
![]() that are orthogonal to
that are orthogonal to ![]() but related to
but related to ![]() . The econometrician then employs a two-stage procedure: (1) regressing
. The econometrician then employs a two-stage procedure: (1) regressing ![]() on
on ![]() and some subset of
and some subset of ![]() , computing predicted values which he calls
, computing predicted values which he calls ![]() , and then (2) regressing
, and then (2) regressing ![]() on
on ![]() , testing hypotheses about the relation between
, testing hypotheses about the relation between ![]() and
and ![]() using standard errors from this second regression. The test rejects
using standard errors from this second regression. The test rejects
![]() using the shrunken standard errors. The econometrician submits the paper to a top econometrics journal, and it is accepted to great acclaim, as it shows how to reject all
false hypotheses. End of fable.
using the shrunken standard errors. The econometrician submits the paper to a top econometrics journal, and it is accepted to great acclaim, as it shows how to reject all
false hypotheses. End of fable.
In reality, such a two-step procedure would be unacceptable to any reasonable econometrician. Unfortunately, many macroeconomics papers employing LoSE-contaminated data like GDP growth may have unwittingly engaged in the second stage of this two-stage procedure, with a government statistical
agency generating the LoSE in ![]() in the first stage. Either way, lack of robustness is a major concern. If we consider a case where the regression estimates are biased and inconsistent, with
in the first stage. Either way, lack of robustness is a major concern. If we consider a case where the regression estimates are biased and inconsistent, with
![]() correlated with
correlated with ![]() , then arbitrarily shrinking the
regression standard errors leads to a higher rate of rejection of hypotheses that are true. The system of hypothesis testing is designed to minimize such type I errors, and LoSE in
, then arbitrarily shrinking the
regression standard errors leads to a higher rate of rejection of hypotheses that are true. The system of hypothesis testing is designed to minimize such type I errors, and LoSE in ![]() increases
the risk of such errors in cases where the model is misspecified.
increases
the risk of such errors in cases where the model is misspecified.
In applications where variances themselves are the object of interest, the problems imposed by LoSE in ![]() are more straightforward. For example, in a regression forecasting context, the
variance of the out-of-sample forecasting errors is often a key measure. The actual variance of the out-of-sample forecast error for the true variable of interest,
are more straightforward. For example, in a regression forecasting context, the
variance of the out-of-sample forecasting errors is often a key measure. The actual variance of the out-of-sample forecast error for the true variable of interest,
![]() , with
, with
![]() estimated using mismeasured
estimated using mismeasured ![]() , is
, is
![]() . LoSE reduces this
variance by
. LoSE reduces this
variance by
![]() , and if that is the predominant source of measurement error, the variance of the forecast errors computed using mismeasured
, and if that is the predominant source of measurement error, the variance of the forecast errors computed using mismeasured ![]() give a misleading sense of precision: the deviations of
give a misleading sense of precision: the deviations of
![]() from the forecasts are larger, on average, than those mismeasured forecast errors indicate.
from the forecasts are larger, on average, than those mismeasured forecast errors indicate.
3.3 Y Mismeasured, X Not Mismeasured,
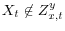 : Biased Point Estimates
: Biased Point Estimates
In addition to assumption 1, this subsection makes the following assumptions:
Bias and inconsistency are evidently issues here.
| (13) | |||
| (14) | |||
The inconsistency of
Instruments ![]() that meet the conditions of assumption 2 in this case are those for which
that meet the conditions of assumption 2 in this case are those for which
![]() converges in probability to zero, for example if
converges in probability to zero, for example if
![]() , so that
, so that ![]() is independent of the information about
is independent of the information about
![]() missing from
missing from ![]() . Instruments typically thought of as valid based on
other considerations may not meet this condition. The asymptotic distribution of the IV regression estimates
. Instruments typically thought of as valid based on
other considerations may not meet this condition. The asymptotic distribution of the IV regression estimates
![]() is:
is:
with
3.4 Both X and Y Mismeasured: Illuminating Special Cases
Again for simplicity, and to focus on the effects of LoSE, this section considers the case of no CME in ![]() , so assumption 4 holds, as well as assumption 1. Three special cases are
illuminating. The first is where the information sets used to construct
, so assumption 4 holds, as well as assumption 1. Three special cases are
illuminating. The first is where the information sets used to construct ![]() and
and ![]() coincide in the universe of variables correlated with
coincide in the universe of variables correlated with ![]() , so
, so
![]() . Then
. Then
![]() , so their difference in (8) and (9) disappears, leaving unbiased and consistent regression parameter estimates. The
variance and asymptotic distribution of
, so their difference in (8) and (9) disappears, leaving unbiased and consistent regression parameter estimates. The
variance and asymptotic distribution of
![]() , and the probability limit of
, and the probability limit of ![]() , are as in subsection 3.2. The
main concern under these circumstances is the shrinking effect of LoSE on standard errors.
, are as in subsection 3.2. The
main concern under these circumstances is the shrinking effect of LoSE on standard errors.
The second illuminating case is where
![]() , so
, so ![]() contains all the information about
contains all the information about ![]() in
in ![]() , plus additional information. The difference
, plus additional information. The difference
![]() is uncorrelated with
is uncorrelated with ![]() ; substituting this difference for
; substituting this difference for
![]() in subsection 3.3 then leaves the results of that section unchanged. The estimate
in subsection 3.3 then leaves the results of that section unchanged. The estimate
![]() is biased and inconsistent, with the bias towards zero; some variation in measured
is biased and inconsistent, with the bias towards zero; some variation in measured ![]() that appears in
that appears in ![]() is missed by measured
is missed by measured ![]() , biasing down
the covariance between
, biasing down
the covariance between ![]() and
and ![]() . Valid instruments must be in the information set used
to compute the more-poorly measured
. Valid instruments must be in the information set used
to compute the more-poorly measured ![]() .
.
The last illuminating case is where ![]() contains all the information about
contains all the information about ![]() in
in ![]() plus additional information, so
plus additional information, so
![]() . Then
. Then
![]() is uncorrelated with
is uncorrelated with ![]() and
and ![]() , and if this difference replaces
, and if this difference replaces ![]() in subsection
3.1, the results in that subsection carry over to this case, except LoSE in
in subsection
3.1, the results in that subsection carry over to this case, except LoSE in ![]() shrinks the error and parameter variances. The estimates are unbiased and consistent.
shrinks the error and parameter variances. The estimates are unbiased and consistent.
These cases should help provide some intuition about the potential effects of LoSE in particular regression applications where the econometrician has some knowledge of the relative degree of LoSE mismeasurement in the explanatory and dependent variables. For each application, whether
![]() ,
,
![]() , or
, or
![]() provides the best description of reality determines which results are most relevant, those from subsection 3.1 (augmented with LoSE in
provides the best description of reality determines which results are most relevant, those from subsection 3.1 (augmented with LoSE in ![]() ), 3.2, or 3.3. For example, the extent of any bias in the parameter estimates depends on the degree to which the mismeasured explanatory variables contain signal missing from the dependent variable.
), 3.2, or 3.3. For example, the extent of any bias in the parameter estimates depends on the degree to which the mismeasured explanatory variables contain signal missing from the dependent variable.
4.1 Discussion of U.S. Macro Quantity Data
Each estimated growth rate of a macro quantity such as gross domestic product (GDP) is an attempt at measuring the growth in the value of all relevant economic transactions, in the entire economy, from one fixed time period to the next. For an entity as large as the U.S. economy, this is a daunting, almost mind-boggling task, as the number of transactors and transactions is typically enormous, with little or no information recorded about many of them at high frequencies. Attempts to measure changes in these macro quantities are much more ambitious than attempts to measure similar changes for a single person, household, or even company. Simply due to their broad, universal nature, estimates of macro quantities are likely to miss more information - i.e. be contaminated with more LoSE - than are estimates of micro quantities.2
Of course, the nature of the available source data determines the information content of the macro variable of interest, and frequency is important in this regard in the case of data from the U.S. National Income and Product Accounts (NIPA).3The most comprehensive data on GDP and other major NIPA aggregates are only available at the quinquennial frequency (every five years), at the time of the major economic censuses. Even then, resource constraints make true census counts impossible. Many transactions in the underground economy remain unobserved and must be estimated, and some "above-ground" transactions are simply missed by any census.4
At the annual frequency, the GDP source data are typically samples drawn from the census universe. These samples can be quite large, capturing a sizeable fraction of the relevant value of transactions, but they are typically skewed towards measuring the transactions of larger businesses. As such, they may miss variation arising from the transactions of small companies and from businesses starting, shutting down, and operating in the underground economy. The underrepresentation of these segments of the economy may add or subtract variance to the official estimates, depending on the relation of the poorly-measured segments to the better-measured segments, but this type of mismeasurement has the potential to add some LoSE to the data. More worrisome, usable data on the value of transactions at the annual frequency is unavailable for a substantial share of the NIPA aggregates; many of the services categories of personal consumption expenditures (PCE) lack usable source data, for example. It is difficult to imagine how this lack of hard information would not introduce some LoSE into the estimates. At the annual frequency, and also at the quarterly frequency to some extent, government tax and administrative records are used as an additional source of information about the value of transactions, especially on the income side of the accounts in the components of GDI. These data can be informative, but underreporting makes them less than fully comprehensive.
At the quarterly and monthly frequency,5 reliance on samples is more pronounced, and the samples are less comprehensive. Smaller samples introduce larger sampling errors, which have traditionally been thought of as introducing CME into the estimates. The samples are typically random, so part of the difference between the population and sample moments is likely random variation uncorrelated with the variation in the population moments. However smaller samples may introduce some LoSE as well; if the samples are not fully representative, they may miss variation arising from some segments of the population.6And, a greater fraction the NIPA aggregates lacks hard data on the value of transactions at frequencies higher than annual, with the services categories of personal consumption expenditures (PCE) again particularly vulnerable to this criticism.7 Quarterly and monthly growth rates are typically interpolated using related indicators, or estimated as "trend extrapolations." The lack of hard information again seems highly likely to introduce some LoSE into the estimates.
4.2 GDP growth, GDI growth and LoSE
Our first example of measurement error in macroeconomic quantity data that appears to be LoSE comes from examining the numerous revisions to US GDP and GDI growth. These revisions incorporate more comprehensive and higher-quality source data, and so plausibly reduce measurement error in the estimates. For example, suitable source data is unavailable for many components of the "advance" current quarterly GDP estimate released about a month after the quarter ends. Source data for some of those components is incorporated into the revised "final" current quarterly estimate released about two months later, and higher-quality data are incorporated at subsequent annual and benchmark revisions, likely bringing the estimate closer to its true value.8 Then an early estimate of GDP growth or GDI growth can be modelled as a later revised estimate plus a measurement error term that disappears with revision. Table 1 shows that the initial estimates have less variance than the revised estimates, violating the variance restrictions of the CME model.9 The generalized model here implies that the bulk of the measurement error is LoSE, as noted by Mankiw and Shapiro (1986).
Our second example of LoSE in macroeconomic quantity data comes from examining the fully-revised estimates of GDP and GDI growth. Some users of quarterly or annual US GDP growth and its major subcomponents think the measurement error in the data is negligible after it has passed through all the revisions. But GDI growth measures the same underlying concept as GDP growth, so if the two diverge, at least one of them must be mismeasured. Table 2 shows variances and covariances of the estimates, before and after 1984, when the variance of the estimates appears to have fallen dramatically (see McConnell and Perez-Quiros (2000)). Prior to 1984, the variance of each estimate is close to the covariance between the two; the estimates diverge little, providing minimal evidence of mismeasurement. However after 1984, the covariance falls more than the variances, on average; this is especially true for the quarterly growth rates, where the correlation between the estimates falls from 0.93 to 0.68.10Interestingly, the variance of GDI growth also increases relative to the variance of GDP growth. Under the generalized CME model of section 2, this relatively large GDI variance may stem from some combination of two possible sources: (1) a relatively large amount of CME in GDI growth, boosting its variance, and (2) a relatively large amount of LoSE in GDP growth, damping its variance. The evidence favors the latter as the more important source of mismeasurement.
First, consider the results in Nalewaik (2007a), who estimates a two-state bivariate Markov switching model where the means of quarterly GDP and GDI growth switch with the state; the low-growth states identified by the model encompass NBER-defined recessions. The conditional variance of GDI in that model, conditional on the estimated state of the world, is actually slightly lower than the conditional variance of GDP, even though its unconditional variance is higher. The higher unconditional variance stems from GDI growing faster than GDP in high-growth periods, on average, and slower than GDP in slow-growth periods in and around recessions. In other words, GDI growth appears to contain more signal about the state of the world than GDP growth: the larger spread between its high- and low-growth means implies greater informativeness about the state. Greater signal in GDI growth implies relatively more LoSE in GDP growth.
Second, table 1 shows that the variance of GDI growth becomes relatively large only after the data pass through annual and benchmark revisions. In the earlier estimates, the variance of GDP growth actually slightly exceeds the variance of GDI growth. Since the revisions plausibly bring the estimates closer to their true values, they must either reduce LoSE, adding variance, or reduce CME, subtracting variance. Then the relatively large increase in variance of GDI must from a relatively large drop in LoSE. The revisions appear to add more signal to GDI growth than GDP growth, which in turn suggests that GDI growth has greater signal overall, since the pre-revision estimates started with roughly equal variance.11 Fixler and Nalewaik (2007) discuss the revisions evidence in more detail, testing the hypothesis that the idiosyncratic variation in GDI growth is purely CME and rejecting at conventional significance levels. This again implies some LoSE in GDP growth.
To get a sense of the magnitude of the potential variance missing from GDP growth due to LoSE, assume that the CME variance in each estimate is negligible, so the differences between GDP and GDI growth stem entirely from differential LoSE:
Taking variances as in (4) yields:
The idiosyncratic variance of one estimate (its variance minus its covariance with the other estimate) is then proportional to the LoSE in the other estimate:
The information missed by both estimates is
| (15) | |||
The last column of table 2 uses this equation to set an upper bound on the fraction of variance of
Going forward, if these post-1984 variances and covariances are the norm, the implications of a potentially non-trivial amount of LoSE in macro data such as GDP growth should be taken seriously. For estimation and inference, the post-1984 portion of many samples will become increasingly large and important.
4.3 Regression Evidence of LoSE in GDP growth
Beyond careful study of the second moments in tables 1 and 2, section 3.3 provides a strategy for constructing regression tests for LoSE in GDP growth, if we can identify variables that plausibly capture some of its missing variaton. In this subsection we consider stock and bond prices. Of course, some variation in these asset prices likely arises from misinformation, rational or irrational bubbles, and other factors unrelated to fundamentals, but this does not imply that more-informative variation is not present as well. Dynan and Elmendorf (2001) and Fixler and Grimm (2006) show that asset prices predict revisions to GDP growth, evidence that asset prices contain information missed by the initial government estimates. Asset prices may contain information missed by the fully-revised estimates as well, and that information may appear in asset prices in at least two ways.
First, information about the state of the economy that is not fully incorporated into GDP growth, but is publicly available and thus observable by the vast majority of asset market participants, is likely incorporated into asset prices. The source data used to compute GDI appears to be part of this information, which does move financial markets; see Faust et al (2003).
Second, asset prices aggregate the private information of vast numbers of market participants, private information that is likely correlated with current or future economic activity. For example, the stock price of a company may reflect numerous pieces of private information about that company's cash flow prospects. Aggregating across all firms, the idiosyncratic variation in firms' stock prices averages out, so an aggregate stock market index contains the signal about aggregate economic activity dispersed in all the pieces of private information.12 Stock and bond prices are fundamentally tied to economic activity, with market participants placing bets with real money about current and future economic prospects.13
To test for LoSE in GDP growth, consider a regression of several of our quarterly output growth measures on current and lagged growth rates of the Wilshire 5000 stock price index.14 Fama (1990) studied a similar specification, which can be motivated theoretically in a number of ways.15 For our purposes here,
it suffices that a relation between true output growth ![]() and stock prices
and stock prices ![]() does exist, governed by a true parameter vector
does exist, governed by a true parameter vector ![]() .
.
Employing the post-1984 sample, the first column of results in table 3 uses the time series of "advance" GDP growth as the dependent variable of the regression, while the second column uses the latest available estimates. Note that each standard error in the second regression exceeds its
counterpart in the first (these are Newey-West (1987) corrected for heteroskedasticity and second-order autocorrelation). It seems the LoSE in "advance" GDP growth shrinks the standard errors, as discussed in section 3.2. More importantly, most of the regression coefficients in the first
regression appear biased down relative to the second. We must be a little careful here, since intuition about univariate attenuation bias does not necessarily hold for all coefficients in a multivariate setting, but
![]() is close to diagonal since
is close to diagonal since
![]() is approximately serially uncorrelated, so that intuition is roughly correct. The last row of the table reports the sum of the coefficients and its standard error for ease of
interpretation. The difference between the sums in the first two regressions, 0.072, is statistically significant, with a standard error of 0.036 correcting for cross-correlation and second-order cross-autocorrelation between the two sets of residuals. We reject the hypothesis that the measurement
error in "advance" GDP growth does not bias down the regression coefficients. This downward bias of about two-thirds is roughly in line with to the ratio of the variances in table 1, about three-fourths.
is approximately serially uncorrelated, so that intuition is roughly correct. The last row of the table reports the sum of the coefficients and its standard error for ease of
interpretation. The difference between the sums in the first two regressions, 0.072, is statistically significant, with a standard error of 0.036 correcting for cross-correlation and second-order cross-autocorrelation between the two sets of residuals. We reject the hypothesis that the measurement
error in "advance" GDP growth does not bias down the regression coefficients. This downward bias of about two-thirds is roughly in line with to the ratio of the variances in table 1, about three-fourths.
The third column of results in table 3 uses latest GDI growth as the dependent variable. The large increase in some of the regression coefficients is striking, with the sum of the coefficients increasing by 0.116 compared to the regression using latest GDP growth, with a standard error of 0.040. It is tempting to conclude that GDI growth is more informative about true output growth than GDP growth, leading to a greater LoSE-induced attenuation bias in regressions using GDP growth. However, a couple of alternate interpretations must be addressed, related to the fact that direct measures of corporate profits are included in GDI.
One alternate interpretation is that estimates of corporate profits are noisy, and stock prices react to some of that noise. Then
![]() is positively correlated with
is positively correlated with ![]() in regressions using GDI growth as the
dependent variable, biasing the coefficients up. If this were the case, the problem should be more severe for the early estimates of GDI growth, since the market reacts to these initial estimates in real time. Yet the fourth column of results in table 3 shows that the sum of the coefficients using
the early "final" estimates of GDI growth is less than half the sum of the coefficients using the revised estimates released several years later. This noise interpretation does not fit the facts. A second alternate interpretation is that GDI growth contains superior information about corporate
profits but not output growth, and stock prices are responding to that profits information. This hypothesis can be examined most directly by regressing the growth rate of GDI minus corporate profits (deflated by the GDP deflator) on the stock price changes. If this interpretation is correct,
stripping out profits should reduce the sum of the coefficients, but the last column of the table shows that the sum of the coefficients actually increases. We are left with the conclusion that, compared to GDP growth, GDI growth contains superior information about true output growth.
in regressions using GDI growth as the
dependent variable, biasing the coefficients up. If this were the case, the problem should be more severe for the early estimates of GDI growth, since the market reacts to these initial estimates in real time. Yet the fourth column of results in table 3 shows that the sum of the coefficients using
the early "final" estimates of GDI growth is less than half the sum of the coefficients using the revised estimates released several years later. This noise interpretation does not fit the facts. A second alternate interpretation is that GDI growth contains superior information about corporate
profits but not output growth, and stock prices are responding to that profits information. This hypothesis can be examined most directly by regressing the growth rate of GDI minus corporate profits (deflated by the GDP deflator) on the stock price changes. If this interpretation is correct,
stripping out profits should reduce the sum of the coefficients, but the last column of the table shows that the sum of the coefficients actually increases. We are left with the conclusion that, compared to GDP growth, GDI growth contains superior information about true output growth.
Digging a little deeper, table 3A examines a univariate regression where the explanatory variable is the average stock price change over the current and six previous quarters; table 3B then reverses the regression, using the average stock price change as the dependent variable. Interestingly,
the coefficient using GDP growth as the explanatory variable is about three-fourths the size of the coefficient using GDI growth, suggesting some noise in GDP growth (although the 0.146 difference between the slopes has a relatively large standard error of 0.088). Assuming that one-fourth of the
variance of GDP growth is in fact noise, then GDP growth captures at most 64 percent of the variance of true output growth, recomputing the upper bound on
![]() using (15). In this case, the
variance of the signal in GDP growth is about equal to its covariance with GDI growth, and the ratio of this signal variance to the variance of GDI growth gives the upper bound. If all information about output growth is contained in GDI growth, so
using (15). In this case, the
variance of the signal in GDP growth is about equal to its covariance with GDI growth, and the ratio of this signal variance to the variance of GDI growth gives the upper bound. If all information about output growth is contained in GDI growth, so
![]() , this bound holds and the coefficients in the third columns of table 3, 3A and 3B are the true parameter vector
, this bound holds and the coefficients in the third columns of table 3, 3A and 3B are the true parameter vector ![]() . However, if some information about true output growth is missing from GDI growth, these coefficients are themselves biased down, and unfortunately we do not know the size of this downward bias.
. However, if some information about true output growth is missing from GDI growth, these coefficients are themselves biased down, and unfortunately we do not know the size of this downward bias.
Evidence from the forward and reverse regressions does not support the measurement error model discussed at the end of section 2,
![]() . Supposing that model were true for a moment, the results in tables 3 and 3A require a larger
. Supposing that model were true for a moment, the results in tables 3 and 3A require a larger ![]() for GDI growth than for GDP growth. But then in the reverse regression in table 3B, the larger
for GDI growth than for GDP growth. But then in the reverse regression in table 3B, the larger ![]() implies
the coefficient on GDI growth should be smaller than the coefficient on GDP growth. Noise in GDP growth may lower the latter coefficient, of course, but half the variance of GDP growth must be noise to make this particular model consistent with the point estimates in tables 3A and 3B, with
none of that noise appearing in GDI growth.16 Given that the covariance between GDP growth and GDI growth accounts for more than half the variance of GDP
growth, this seems unlikely. Indeed, a test of the hypothesis that the covariance between GDP and GDI growth (about 3.1) is half the variance of GDP growth (about 4.2) rejects with a p-value of about 0.01.
implies
the coefficient on GDI growth should be smaller than the coefficient on GDP growth. Noise in GDP growth may lower the latter coefficient, of course, but half the variance of GDP growth must be noise to make this particular model consistent with the point estimates in tables 3A and 3B, with
none of that noise appearing in GDI growth.16 Given that the covariance between GDP growth and GDI growth accounts for more than half the variance of GDP
growth, this seems unlikely. Indeed, a test of the hypothesis that the covariance between GDP and GDI growth (about 3.1) is half the variance of GDP growth (about 4.2) rejects with a p-value of about 0.01.
These results using stock prices are largely confirmed by regressions of the different output growth measures on bond prices, as shown in table 4. The explanatory variables are TERM, the difference in yield between 10-year and 2-year US treasury notes, and DEF, the difference in yield between corporate bonds and 10-year treasury notes.17 Numerous papers have used similar variables to forecast output growth; see Chen (1991) and Estrella and Hardouvelis (1991), for example. The table examines regressions at forecasting horizons ranging from one- to eight-quarters ahead; DEF has substantial explanatory power at shorter horizons, while TERM shows some explanatory power at longer horizons. All of the coefficients except one and all of the standard errors increase when we switch from "advance" GDP as the dependent variable to latest GDP. Switching from latest GDP to latest GDI, the coefficients again all increase, except for TERM at the one- and two-quarter ahead horizons when its statistical significance and marginal explanatory power are weakest. The last column reports p-values from an F-test of equal coefficients from the GDP and GDI regressions; equality is rejected at the three- and four- quarter ahead horizons. The evidence here again suggests that LoSE in GDP growth biases down these regression coefficients.
Similar results obtained from univariate regressions using either TERM or DEF, although the standard errors around the TERM coefficients were large, making definitive statements from those regressions difficult. Using DEF as the dependent variable in reverse regressions, coefficients were
smaller using GDP growth as the explanatory variable than using GDI growth, supporting evidence of some noise in GDP growth. The coefficients using GDP growth were between 12 and 42 percent smaller, depending on horizon. The magnitudes of the coefficients from these forward and reverse regressions
at several horizons are again inconsistent with the model
![]() .
.
5 Conclusions and Implications
The canonical classical measurement error (CME) model is too restrictive to handle important cases of mismeasurement, including mismeasurement in some widely-used macroeconomic time series. The paper discusses a simple generalization of the CME model that is mathematically tractable, embeds the CME model as a special case, and adds useful flexibility. Instead of just allowing mismeasurement that adds noise to the true variable of interest, the generalization permits mismeasurement that subtracts signal; I label this reduction of signal from mismeasurement the Lack of Signal Error, or LoSE for short.
In some ways, this generalization of the CME model provides the second half of the story about errors in variables and their effect on ordinary least squares (OLS) regression, as the results here exhibit a symmetry that is intuitively pleasing. CME in the dependent variable of a regression
![]() does not bias parameter estimates and increases standard errors; in the baseline case, LoSE in the explanatory variables
does not bias parameter estimates and increases standard errors; in the baseline case, LoSE in the explanatory variables ![]() has the same effect. CME in the explanatory variables
has the same effect. CME in the explanatory variables ![]() does bias regression parameter estimates, of course, towards zero in the univariate case;
LoSE in the dependent variable
does bias regression parameter estimates, of course, towards zero in the univariate case;
LoSE in the dependent variable ![]() introduces a similar attenuation-type bias under some circumstances, namely, when some of the signal missing from the dependent variable
introduces a similar attenuation-type bias under some circumstances, namely, when some of the signal missing from the dependent variable ![]() is captured by the explanatory variables
is captured by the explanatory variables ![]() . LoSE in
. LoSE in ![]() also shrinks the variance of the regression residuals, raising concerns about the robustness of hypothesis tests.
also shrinks the variance of the regression residuals, raising concerns about the robustness of hypothesis tests.
The paper reviews evidence in Fixler and Nalewaik (2007) and Nalewaik (2007a,b) that US GDP growth is mismeasured with LoSE. The initial estimates of GDP growth are contaminated with a particularly large amount of LoSE, but the estimates that have passed through the BEA's long sequence of revisions remain contaminated with LoSE. A separate estimate of output growth produced by the BEA, GDI growth, appears to be contaminated with less LoSE than GDP growth, and a comparison of the two shows that, since the mid-1980s, GDP growth at the annual or quarterly frequency has captured at most 70% of the variance of the true output growth. US GDP growth and its subcomponents like consumption growth have served as the dependent variables in many regression studies in macroeconomics and finance; the potential for biases in these regressions stemming from mismeasurement of the dependent variable has not been contemplated in a serious way prior to this paper.
Asset prices are a set of variables that may capture some of the signal missing from GDP growth and its subcomponents, implying attenuation-type biases in regressions of the mismeasured quantities on those prices. The empirical results here confirm that. In regressions of different measures of output growth (initial GDP growth, revised GDP growth, and GDI growth) on either stock prices or bond prices, the measures of output growth that appear contaminated with more LoSE have smaller coefficients, and the changes in the coefficients across regressions are often statistically significant. The set of explanatory variables is fixed from regression to regression; the only thing changing is the degree of measurement error in the dependent variable. We reject the CME intuition that measurement error in the dependent variable does not bias regression coefficients.
Some implications of significant LoSE in GDP growth and its major subcomponents follow immediately. First, those variables are simply less informative than many macroeconomists currently believe, given the common but incorrect presumption that the fully-revised estimates are measured with little error. Second, in a macro forecasting context, true forecast errors are larger, on average, than forecast errors computed using data mismeasured with LoSE. Estimated forecast error variances overstate the accuracy of the forecasts for the true variable, usually the object of interest in forecasting.
For estimating the parameters of structural economic models on macroeconomic data, LoSE clearly poses some serious problems as well. For example, in estimating parameters underlying the permanent income hypothesis (PIH) with regressions of consumption on income, LoSE in the macroeconomic
consumption data is likely to bias those parameters down and shrink their standard errors, risking rejection of hypotheses that are true. A large fraction of consumption lacks source data at the quarterly and even the annual frequency, so this component of GDP is likely to be particularly
contaminated with LoSE. As another example, consider Euler equation estimates of the relation between macro consumption growth
![]() and interest rates
and interest rates ![]() ; see Campbell and Mankiw (1989). True
consumption growth may have substantial covariance with interest rates, but mismeasured consumption growth likely misses some of this variation, biasing the OLS regression coefficient towards zero. Lagged interest rates are almost universally assumed to be valid instruments in estimating the Euler
equation, and they may be valid for dealing with expectational errors and some other forms of endogeneity. However if interest rates contain information about actual contemporaneous consumption growth missed by measured consumption growth, lagged interest rates likely contain just as much if not
more of this missing information, since interest rates are basically forward-looking. Lagged interest rates are not valid instruments, and the instrumental variables parameter estimates remain biased towards zero.
; see Campbell and Mankiw (1989). True
consumption growth may have substantial covariance with interest rates, but mismeasured consumption growth likely misses some of this variation, biasing the OLS regression coefficient towards zero. Lagged interest rates are almost universally assumed to be valid instruments in estimating the Euler
equation, and they may be valid for dealing with expectational errors and some other forms of endogeneity. However if interest rates contain information about actual contemporaneous consumption growth missed by measured consumption growth, lagged interest rates likely contain just as much if not
more of this missing information, since interest rates are basically forward-looking. Lagged interest rates are not valid instruments, and the instrumental variables parameter estimates remain biased towards zero.
On a positive note, the results derived here provide some clear prescriptions for handling different types of mismeasurement, in terms of choice of instruments, and also choice of which variable is dependent ![]() , and which is explanatory
, and which is explanatory ![]() . In the Euler equation case, since consumption growth is mismeasured with LoSE, and the interest rate is largely free from mismeasurement, the
results here recommend using the interest rate as the dependent variable, opposite the current conventional wisdom in the profession.18 The
generalized measurement error model with LoSE is likely applicable in a wide variety of econometric specifications beyond the few considered here, and our results should provide helpful insights for making appropriate modifications to econometric practice.
. In the Euler equation case, since consumption growth is mismeasured with LoSE, and the interest rate is largely free from mismeasurement, the
results here recommend using the interest rate as the dependent variable, opposite the current conventional wisdom in the profession.18 The
generalized measurement error model with LoSE is likely applicable in a wide variety of econometric specifications beyond the few considered here, and our results should provide helpful insights for making appropriate modifications to econometric practice.
| Vintage |
|
|
|---|---|---|
| Current Quarterly, "Advance" | 3.1 | . |
| Current Quarterly, "Final" | 4.1 | 4.0 |
| Latest Vintage Available | 4.2 | 4.8 |
|
|
|
|
Upper bound on:
|
|
|---|---|---|---|---|
| Quarterly, 1947-1984Q2 | 24.1 | 24.1 | 22.4 | 0.93 |
| Annual, 1947-1984 | 8.2 | 8.5 | 8.2 | 0.97 |
| Quarterly, 1984Q3-2004 | 4.2 | 4.8 | 3.1 | 0.70 |
| Annual, 1985-2004 | 1.6 | 2.6 | 1.9 | 0.69 |
| Measure: |
|
|
|
|
|
|---|---|---|---|---|---|
| Vintage: | "Advance" | Latest | Latest | "Final" | Latest |
| 0.012 | 0.014 | 0.032 | 0.031 | 0.003 | |
| (0.019) | (0.027) | (0.026) | (0.023) | (0.025) | |
| 0.048 | 0.054 | 0.084 | 0.038 | 0.083 | |
| (0.018) | (0.024) | (0.023) | (0.023) | (0.030) | |
| 0.021 | 0.065 | 0.056 | 0.036 | 0.059 | |
| (0.024) | (0.027) | (0.027) | (0.027) | (0.028) | |
| 0.058 | 0.057 | 0.067 | 0.044 | 0.093 | |
| (0.017) | (0.022) | (0.023) | (0.020) | (0.031) | |
| 0.011 | 0.015 | 0.051 | 0.024 | 0.064 | |
| (0.023) | (0.028) | (0.029) | (0.024) | (0.028) | |
| -0.003 | -0.007 | 0.038 | -0.019 | 0.070 | |
| (0.025) | (0.026) | (0.022) | (0.022) | (0.028) | |
| 0.002 | 0.023 | 0.008 | 0.002 | 0.032 | |
| (0.016) | (0.017) | (0.027) | (0.018) | (0.030) | |
|
|
0.149 | 0.221 | 0.337 | 0.156 | 0.403 |
|
|
(0.055) | (0.060) | (0.069) | (0.069) | (0.079) |
| Measure: |
|
|
|
|---|---|---|---|
| Vintage: | "Advance" | Latest | Latest |
| 0.142 | 0.214 | 0.325 | |
| (0.060) | (0.068) | (0.073) |
| Measure: |
|
|
|
|---|---|---|---|
| Vintage: | "Advance" | Latest | Latest |
| 0.411 | 0.454 | 0.600 | |
| (0.194) | (0.182) | (0.169) |
| Measure: |
|
|
|
|
|
|
p-val., equal |
|---|---|---|---|---|---|---|---|
| k=1 | 0.20 | -0.50 | 0.31 | -0.61 | 0.23 | -0.79 | 0.10 |
| k=1 (standard error) | (0.26) | (0.13) | (0.26) | (0.13) | (0.29) | (0.10) | |
| k=2 | 0.42 | -0.44 | 0.48 | -0.53 | 0.43 | -0.69 | 0.13 |
| k=2 (standard error) | (0.26) | (0.12) | (0.31) | (0.12) | (0.33) | (0.13) | |
| k=3 | 0.58 | -0.38 | 0.60 | -0.40 | 0.68 | -0.65 | 0.00 |
| k=3 (standard error) | (0.30) | (0.12) | (0.36) | (0.15) | (0.37) | (0.15) | |
| k=4 | 0.62 | -0.23 | 0.57 | -0.28 | 0.70 | -0.50 | 0.01 |
| k=4 (standard error) | (0.32) | (0.15) | (0.39) | (0.17) | (0.40) | (0.17) | |
| k=5 | 0.59 | -0.19 | 0.67 | -0.29 | 0.75 | -0.41 | 0.40 |
| k=5 (standard error) | (0.35) | (0.14) | (0.38) | (0.14) | (0.44) | (0.19) | |
| k=6 | 0.72 | -0.27 | 0.76 | -0.32 | 0.92 | -0.39 | 0.54 |
| k=6 (standard error) | (0.35) | (0.10) | (0.38) | (0.13) | (0.41) | (0.16) | |
| k=7 | 0.73 | -0.19 | 0.81 | -0.20 | 0.96 | -0.39 | 0.14 |
| k=7 (standard error) | (0.35) | (0.10) | (0.36) | (0.13) | (0.38) | (0.15) | |
| k=8 | 0.66 | -0.10 | 0.72 | -0.15 | 0.94 | -0.27 | 0.27 |
| k=8 (standard error) | (0.34) | (0.13) | (0.36) | (0.14) | (0.37) | (0.15) |