
The Two-Period Rational Inattention Model:
Accelerations and Analyses
Keywords: Rational inattention, information-processing constraints, numerical optimization
Abstract:
1 Introduction
The Rational Inattention (RI) paradigm introduced in Sims (2003) began the examination of information-processing-constrained economic agents with a model in which agents have quadratic utility and face linear constraints. Sims (2006) extended his earlier work to more general environments by demonstrating how one could think about the information-processing-constrained agent's decision outside the linear-quadratic framework and by providing a numerical solution to the two-period consumption-choice problem of a rationally inattentive agent facing an information-processing-capacity constraint. Such an agent, unlike the capacity unconstrained agent who knows a specific value for the state variable and chooses a corresponding value for the choice variable, knows only a distribution for the state variable and chooses the joint distribution of state and choice variables. This paper seeks to better enable the development of more sophisticated RI problems by giving some guidance on the properties of the models Sims has introduced. It is the author's hope that this paper encourages others to implement RI models and move toward fulfilling the titular goal of Sims (2006), "Rational Inattention: A Research Agenda." It is important to note that Sims' central conclusions are robust to this new formulation of the RI problem: the consumption choices of information-processing-capacity-constrained individuals have a discrete nature even when the wealth distribution is continuous, and more risk averse individuals choose distributions for consumption (given the wealth distribution) that are more disperse at high wealth and more precise at low wealth.
The remainder of the paper is organized as follows: Section 2 examines the two-period problem and a generalization of the standard solution is presented that leads to implementation of the RI version of the two period problem. Section 3 demonstrates that the optimization problem of the rationally inattentive agent in the two-period model is convex and contains a discussion of formulation of the problem relative to that of Sims (2006). Section 4 discusses the use of the AMPL/KNITRO software suite and why it is particularly well-suited to these types of problems; this section also qualitatively replicates the results found in Sims (2006). Section 5 illustrates Sims' critique of RI models that assume the form of the optimal distribution of states and decisions, and shows that the most common parametric approximation not only misrepresents the agent's optimal behavior, but does so by yielding less "stickiness" (one supposed goal of implementing the RI framework) than the true optimal decision does. Section 6 concludes.
2 The Two-Period Model
The two-period model of Sims (2006) highlights the central difference between rational inattention and other information frictions. The choice variable in the model is the form of the joint distribution of consumption and wealth, and the informational "shortage" is one of processing capacity, rather than information availability.
Absent information-processing constraints, Sims' model is a two-period choice of consumption, with an undiscounted, two-period utility function that divides a pool of resources into those consumed now with some probability, and expected consumption in the subsequent time period. This is an
undiscounted "cake-eating" problem in which the agent takes a given amount of wealth, ![]() , and divides it optimally between consuming
, and divides it optimally between consuming ![]() in period one and
in period one and ![]() in period two. That is, for CRRA preferences, the agent solves
in period two. That is, for CRRA preferences, the agent solves
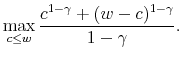 |
The solution to this problem is an optimal decision rule, denoted ![]() , that describes the optimal plan for the choice variable,
, that describes the optimal plan for the choice variable, ![]() , given a value for the state variable,
, given a value for the state variable, ![]() . That is, the solution is a one-to-one mapping from the state-space to the choice-space, described by
. That is, the solution is a one-to-one mapping from the state-space to the choice-space, described by
![]() . The solution to the agent's maximization problem here is given by:
. The solution to the agent's maximization problem here is given by:
that is, the agent should consume half his wealth in each of the two periods. For a given value of ![]() , this describes a corresponding value for
, this describes a corresponding value for ![]() . Even when wealth is characterized by a probability distribution, the optimal
. Even when wealth is characterized by a probability distribution, the optimal ![]() describes a mapping from each potential value of
describes a mapping from each potential value of
![]() to a single corresponding value for
to a single corresponding value for ![]() .
.
2.1 A Generalization
To set the stage for the information-constrained problem, consider a generalization of the cake-eating problem in which the cake (wealth) and bites of the cake (consumption) only come in a finite set of discrete values
![]() and
and
![]() . Suppose further that wealth is characterized by a discrete probability distribution
. Suppose further that wealth is characterized by a discrete probability distribution ![]() . The decision rule,
. The decision rule,
![]() , becomes the method for generating a set of conditional distributions - one for each wealth value. Each of these conditional distributions for consumption is degenerate,
that is, the joint distribution
, becomes the method for generating a set of conditional distributions - one for each wealth value. Each of these conditional distributions for consumption is degenerate,
that is, the joint distribution ![]() describes the same thing as the
describes the same thing as the
![]() : a one-to-one mapping from state space to choice space. The discretized version of the two period model is written:
: a one-to-one mapping from state space to choice space. The discretized version of the two period model is written:
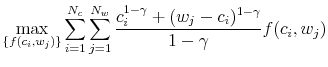
subject to:
 for
for ![]() is the joint distribution of consumption and wealth, and is the choice variable of this optimization problem, while
is the joint distribution of consumption and wealth, and is the choice variable of this optimization problem, while ![]() is the marginal distribution of wealth in the problem (taken as given).
is the marginal distribution of wealth in the problem (taken as given).
The properties of the problem and the optimum are qualitatively unchanged under this generalization; that is, the agent's behavoir is not different in expectation from what it would be under the original problem. Suppose that the marginal distribution of wealth is discrete triangular, meaning
higher levels of wealth have higher probability.1 The optimal decision rule is the joint distribution ![]() that describes the same one-to-one mapping that divides wealth in two. Under the generalization, however, this is accomplished by assigning probability to specific
that describes the same one-to-one mapping that divides wealth in two. Under the generalization, however, this is accomplished by assigning probability to specific ![]() pairs. That is, given a distribution for wealth, the agent disperses the probability weight
pairs. That is, given a distribution for wealth, the agent disperses the probability weight ![]() across the possible values
across the possible values
![]() [equation (3)] such that weight is only allowed where
[equation (3)] such that weight is only allowed where
![]() [equation (4)]. The optimal choice, shown in figure 1, is to place all of the probability of being at wealth node
[equation (4)]. The optimal choice, shown in figure 1, is to place all of the probability of being at wealth node
![]() on the pair
on the pair
![]() , that is,
, that is,
![]() .
.
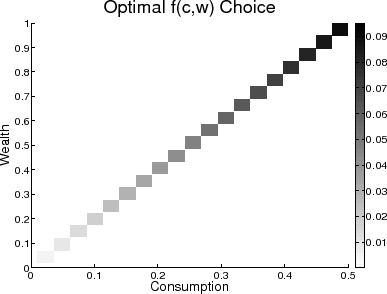
Figure 1 represents the joint distribution of ![]() and
and ![]() over the
over the ![]() interval when the
interval when the ![]() space is discretized. The
darkness of the boxes indicates the weight of probability on that specific
space is discretized. The
darkness of the boxes indicates the weight of probability on that specific ![]() pair. The darker the box, the higher the probability of the agent realizing that consumption-wealth pair. The
boxes get darker as they progress "northeast" because the marginal distribution of wealth,
pair. The darker the box, the higher the probability of the agent realizing that consumption-wealth pair. The
boxes get darker as they progress "northeast" because the marginal distribution of wealth, ![]() , is triangular. The solution,
, is triangular. The solution,
![]() , demonstrates that within this generalization the one-to-one mapping takes the form of creating a set of conditional distributions of
, demonstrates that within this generalization the one-to-one mapping takes the form of creating a set of conditional distributions of ![]() given
given ![]() that are degenerate at
that are degenerate at
![]() .
.
2.2 The Processing-Constrained Problem
The rational inattention framework uses the metric of mutual information (MI) to quantify the amount of information-processing capacity the agent is using to solve his optimization problem.2 By placing a constraint on mutual information, the framework limits the strength of the relationship between ![]() and
and
![]() thus limiting the precision with which either variable can be understood by the agent. As the amount of information the agent can process is reduced from the amount required to produce the
one-to-one relationship described in figure 1, the agent must decide how best to allocate the finite resource of processing capacity across the space of his choice variable.
thus limiting the precision with which either variable can be understood by the agent. As the amount of information the agent can process is reduced from the amount required to produce the
one-to-one relationship described in figure 1, the agent must decide how best to allocate the finite resource of processing capacity across the space of his choice variable.
The agent's optimization problem in the information-processing constrained universe is the same as the one detailed in equations (1) through (4), with the addition of the following constraint on the amount of mutual information in the model:3
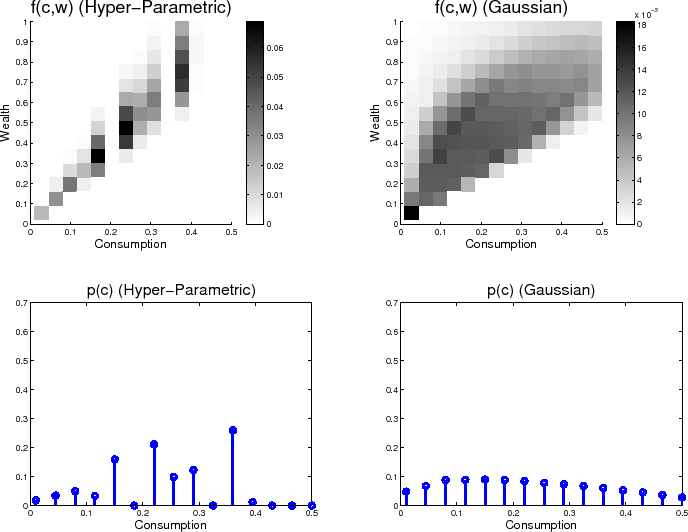
![\displaystyle \sum\limits_{j = 1}^{N_w} \sum\limits_{i = 1}^{N_c} \log[f(c_i,w_j)] \cdot f(c_i,w_j) - \sum\limits_{i = 1}^{N_c} \Bigg( \log\bigg(\sum\limits_{j = 1}^{N_w} f(c_i,w_j) \bigg) \cdot \sum\limits_{j = 1}^{N_w} f(c_i,w_j) \Bigg)](img37.gif)
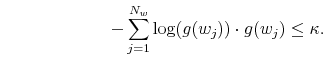
As the amount of information-processing capacity (![]() ) decreases, Sims (2003) notes that the effect on the agent is similar to that of increasing the noise in a
signal-extraction version of the same problem. In the past, economic models have tried to explain the difference between theory and empirical observation in many models by assuming the existence of an exogenous noise that complicates the understanding of the model's state. The rational inattention
framework does something similar to this by describing an environment in which the "noise" is endogenously determined rather than exogenously given: it arises from the agent's inability to accurately assess the state because he does not have the information-processing resources to do so.4
) decreases, Sims (2003) notes that the effect on the agent is similar to that of increasing the noise in a
signal-extraction version of the same problem. In the past, economic models have tried to explain the difference between theory and empirical observation in many models by assuming the existence of an exogenous noise that complicates the understanding of the model's state. The rational inattention
framework does something similar to this by describing an environment in which the "noise" is endogenously determined rather than exogenously given: it arises from the agent's inability to accurately assess the state because he does not have the information-processing resources to do so.4
3 A Convex Problem
RI models represent a potentially large burden on numerical optimization algorithms. Rather than choosing specific values for choice variables given state variables, the optimizer is asked to choose large joint distributions of state and decision variables. It is beneficial to know that this model, though large, is still numerically tractable. It will be shown later that Sims' log-transformation imposes an additional burden in terms of numerical optimization. As a first step, it will be shown that his original, un-transformed problem is, in fact, convex and well suited to numerical optimization.
The agent chooses
![]() (hereafter:
(hereafter: ![]() ). The nodes for consumption and wealth are fixed by
the model-designer, rather than the agent, and it is the probabilities
). The nodes for consumption and wealth are fixed by
the model-designer, rather than the agent, and it is the probabilities ![]() that are chosen by the agent. Thus, the objective function [equation (1)] is a
weighted sum and linear. Constraints (2), (3) and (4) are also linear; therefore, in order for the problem to be convex, it must be shown that:
that are chosen by the agent. Thus, the objective function [equation (1)] is a
weighted sum and linear. Constraints (2), (3) and (4) are also linear; therefore, in order for the problem to be convex, it must be shown that:
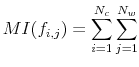
![\displaystyle \Bigg\{\Bigg[\sum\limits_{j= 1} f_{i,j} \Bigg] \cdot \Bigg[ \log \bigg(\sum\limits_{j =1} f_{i,j}\bigg) \Bigg] \Bigg\}](img44.gif)
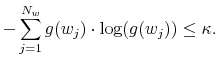
Proof. See Appendix A.
The problem specified in equations (1) through (5) has the requirement that
![]() , rather than
, rather than
![]() . It should also be noted that some
. It should also be noted that some ![]() 's will be zero by the
feasibility constraint (4), thus it is important that
's will be zero by the
feasibility constraint (4), thus it is important that
![]() be considered. What has been demonstrated in the proof of theorem 3.1 is that the
be considered. What has been demonstrated in the proof of theorem 3.1 is that the ![]() constraint is convex on the interior of the feasible set. However, because
constraint is convex on the interior of the feasible set. However, because
![]() , the
, the ![]() constraint is continuous on the
set
constraint is continuous on the
set ![]() . Therefore, since the function is continuous on the closed set
. Therefore, since the function is continuous on the closed set ![]() and
convex on the interior, the function is convex on the closed set. Therefore the problem specified in equations (1) through (5) is a convex programming problem.
and
convex on the interior, the function is convex on the closed set. Therefore the problem specified in equations (1) through (5) is a convex programming problem.
3.1 Differences from Sims (2006)
Three differences exist between what has been done here regarding the numerical optimization and what was done in Sims (2006): First, Sims uses a normalization to eliminate (3), where here it is left explicit. Second, rather than pick a value
for ![]() (the LaGrange multiplier on the capacity constraint) and maximize the LaGrangian for a given multiplier value, a value for the capacity
(the LaGrange multiplier on the capacity constraint) and maximize the LaGrangian for a given multiplier value, a value for the capacity ![]() is chosen, and the constraint remains intact.5 Third, I optimize directly over the
values of
is chosen, and the constraint remains intact.5 Third, I optimize directly over the
values of ![]() rather than their logarithm.
rather than their logarithm.
The first two differences are minor in comparison to the third. The third difference is counter-intuitive, but represents a large element of the difference between the optimization results presented here and the ones in Sims (2006). Sims' reasons for optimizing over
![]() is that because logarithms are undefined at zero, we can use
is that because logarithms are undefined at zero, we can use ![]() to make sure that the problem stays in the region of
to make sure that the problem stays in the region of ![]() values which are well behaved (in terms of the gradient).6When
values which are well behaved (in terms of the gradient).6When ![]() is very large and negative, it is taken to be zero. While the optimization problem is the same
theoretically, it has become much more difficult for numerical optimizers to solve. This transformation is responsible for a large part of the difference in computational times.
is very large and negative, it is taken to be zero. While the optimization problem is the same
theoretically, it has become much more difficult for numerical optimizers to solve. This transformation is responsible for a large part of the difference in computational times.
4 The Solution Procedure
RI problems are inherently large, in terms of the number of variables, relative to their unconstrained counterparts. AMPL (literally: A Mathematical Programming Language) was chosen because it can accommodate problems of a very large size and includes
a differentiation feature that aids in accurately finding the optimum in such a large variable space. AMPL is not an optimizer in itself, but rather a front end, that is, a piece of software designed to allow the user to interact with other software, for a large number of potential
optimization algorithms, each of which has properties suited to specific problems.7![]() 8
8
The key to effective numerical optimization lies in the derivatives, meaning that gradients and Hessians provide the data required to complete the task of the optimizer. Here, these are generated by means of automatic (or algorithmic) differentiation. The speed and accuracy of the optimizer depend on the information available about the hill being climbed. Automatic differentiation (AD) generates the gradients without truncation errors (unlike divided differencing) or the excessive memory usage of symbolic differentiation. AD is best thought of as a close cousin of symbolic differentiation in that both are the result of systematic application of the chain rule. However, in the case of AD, the chain rule is applied not to symbolic expressions but to actual numerical values.9
4.1 Interior-Point Optimization
The optimizer used for this model is called KNITRO. KNITRO implements an interior point optimization algorithm that is exceptionally well suited to the current problem and to RI models in general. Interior point methods approach the boundaries of variable-space in an organized
way, without taking derivatives or evaluating the function at the boundaries. This aspect of the algorithm is important because the derivatives of this problem are infinite at some of the boundaries (that is, derivatives yield ![]() where
where
![]() ), but the optimization problem is continuous on the closed set, meaning that a solution in which a variable would be optimally set to zero can be represented by the optimization
algorithm stopping when a value is within a certain tolerance of zero.10
), but the optimization problem is continuous on the closed set, meaning that a solution in which a variable would be optimally set to zero can be represented by the optimization
algorithm stopping when a value is within a certain tolerance of zero.10
The optimization scheme will guarantee that, to the tolerances set by the user, a local optimum is found. The convexity of the problem demonstrated above guarantees that the optimum will be global. The time that this takes is dramatically shorter than the time (11 minutes) listed in Sims (2006): The computational time for the problem is slightly less than one second for the grid size suggested in Sims (2006) on a 3 GHz Pentium 4 machine with 4 GB of RAM. While 11 minutes is not a long time to wait for a solution, the grid in this model
is fairly small. Controlling for all the constraints, this problem has less than 400 ![]() nodes to optimize. The computational time increases nonlinearly in number of nodes and this time
savings opens the door to more sophisticated models that have more variables, finer grids, or more time periods, such as Lewis (2007).
nodes to optimize. The computational time increases nonlinearly in number of nodes and this time
savings opens the door to more sophisticated models that have more variables, finer grids, or more time periods, such as Lewis (2007).
4.2 Results
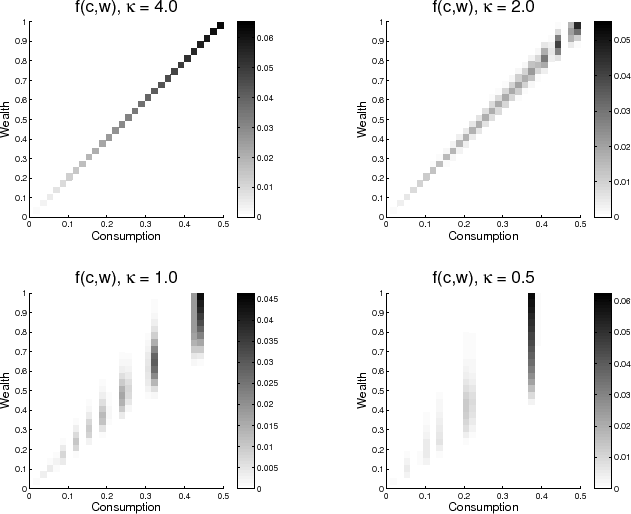
The results are qualitatively the same as Sims (2006). In figure 2, the progressive tightening of the capacity constraint and its effect on the choice of the consumption-wealth joint distribution is seen. First, note that because the
information processing constraint is left explicit, values for ![]() that do not bind the information-processing constraint can be chosen. In fact, this enables the discovery of the value of
that do not bind the information-processing constraint can be chosen. In fact, this enables the discovery of the value of
![]() for which the information-processing constraint does not bind. Here, the darkness of the box within the joint distribution indicates the level of probability of being at that
particular consumption-wealth pair. The values for
for which the information-processing constraint does not bind. Here, the darkness of the box within the joint distribution indicates the level of probability of being at that
particular consumption-wealth pair. The values for ![]() that are small or large depend on the size of the grid and the "complexity" of the wealth distribution. The value
that are small or large depend on the size of the grid and the "complexity" of the wealth distribution. The value
![]() , in the case of figure 2, is the level of information processing capacity required to make a one-to-one decision, making it a value that produces
the same decision as the unrestricted case shown in figure 1. This means that the constraint is ineffective for values of
, in the case of figure 2, is the level of information processing capacity required to make a one-to-one decision, making it a value that produces
the same decision as the unrestricted case shown in figure 1. This means that the constraint is ineffective for values of
![]() . Four nats of information processing may seem small, but the reality is that the level of
. Four nats of information processing may seem small, but the reality is that the level of ![]() required to make one-to-one decisions can be made to be arbitrarily high by the model designer. As the number of nodes increases, the amount of possible combinations of consumption and wealth increase and the value of
required to make one-to-one decisions can be made to be arbitrarily high by the model designer. As the number of nodes increases, the amount of possible combinations of consumption and wealth increase and the value of ![]() required to get the result in the upper-left-hand corner of figure 2 increases rapidly. An area of potential benefit for this literature would be to adopt a new constraint convention that
states everything in terms of the percentage of "one-to-one-decision-making capacity". That is, in figure 2,
required to get the result in the upper-left-hand corner of figure 2 increases rapidly. An area of potential benefit for this literature would be to adopt a new constraint convention that
states everything in terms of the percentage of "one-to-one-decision-making capacity". That is, in figure 2,
![]() , 2, 1 and 0.5 would be replaced with
, 2, 1 and 0.5 would be replaced with
![]() , 0.5, 0.25, and 0.125. This convention could avoid future conversations about the reasonableness the size of
, 0.5, 0.25, and 0.125. This convention could avoid future conversations about the reasonableness the size of ![]() when comparing across models.
when comparing across models.
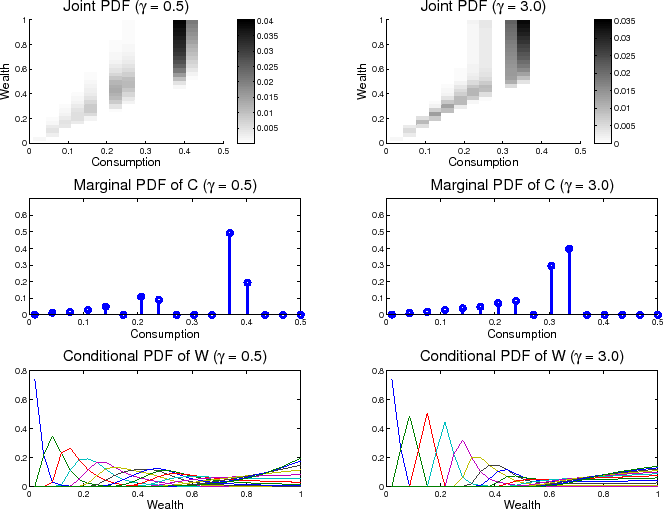
Next, a comparison regarding risk aversion is made. The differences between figure 3 below and its counterparts in Sims (2006) are curious, but in the final analysis, minimal. The point of Sims' figures was to demonstrate how risk aversion
impacts the choice of the joint density of consumption and wealth. This impact - that as risk aversion increases the agent prefers to give up some precision in decision making over a larger range of consumption and wealth in favor of more accuracy where it matters most, at low wealth levels, and
less where it matter less, at higher wealth levels - is still seen here, where the information processing capacity is fixed at 0.85 bits, and the risk aversion parameter, ![]() , is
changed.
, is
changed.
The small differences in results between Sims (2006) and here are potentially attributable to several factors. First, any replication that involves optimization depends on tolerances, and that is certainly possible here. Second, different optimization algorithms are
used. However, the biggest difference is in the log-normalization, so optimization was performed over the log-transformed model using an optimization algorithm called CONOPT, which is more similar to the optimizer implemented by Sims. The results are largely the same as previous figures,
but simply take more time. For example, the CONOPT/![]() model produced qualitatively identical results to those of the interior-point KNITRO algorithm working on the
model produced qualitatively identical results to those of the interior-point KNITRO algorithm working on the
![]() 's themselves, but instead of taking one to two seconds, the CONOPT/
's themselves, but instead of taking one to two seconds, the CONOPT/![]() version takes almost 7 minutes. This serves to illustrate the reality that the problem is theoretically the same, but much harder numerically. In addition to the excellent numerical qualities of the un-transformed model, this 200-fold increase in speed allows us to examine a
richer class of models using the current computing technology, as in Lewis (2007).11
version takes almost 7 minutes. This serves to illustrate the reality that the problem is theoretically the same, but much harder numerically. In addition to the excellent numerical qualities of the un-transformed model, this 200-fold increase in speed allows us to examine a
richer class of models using the current computing technology, as in Lewis (2007).11
5 The Importance of Non-Parametric Choices for
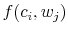
Following Sims (2003), a number of information-processing-constrained-agent models were introduced into the economics and finance literature. The issue, as per Sims (2006), is that most of these models included an approximate solution method. By
incorporating the "Gaussian-in, Gaussian-out" framework of the linear-quadratic setup of Sims (2003), model designers used a parametric version of the joint distribution of state and choice variables (in this model, ![]() ). That is, in order to simplify the structure of the model, the designers approximated the utility-maximizing form of the joint distribution of states and choices with a joint Gaussian process, and optimized over the parameters (means and
covariances) of the corresponding distribution.
). That is, in order to simplify the structure of the model, the designers approximated the utility-maximizing form of the joint distribution of states and choices with a joint Gaussian process, and optimized over the parameters (means and
covariances) of the corresponding distribution.
A famous G.E.P. Box quote notes that: "All models are wrong but some are useful." While all models are approximations, this model can be used to examine the implications of assuming Gaussianity as an approximation to the truly optimal (non-parametric) choice.12 This will indicate whether the assumption of Gaussianity, which has been demonstrated to dramatically ease analysis of more dynamic models, damages the model's ability to accurately predict agent behavior relative to the "true model." What is discovered is that the model produces drastically different implications for agent behavior when the nature of the ex-post uncertainty is assumed, rather than derived.
This effect is demonstrated in the two-period model by requiring (ceteris paribus) that ![]() be a bivariate Gaussian distribution. To this end, a Gaussian wealth distribution (
be a bivariate Gaussian distribution. To this end, a Gaussian wealth distribution (
![]() ,
,
![]() ) is used, and the optimizer is required to respect the processing constraints (
) is used, and the optimizer is required to respect the processing constraints (
![]() ) while choosing
) while choosing ![]() ,
, ![]() and
and ![]() to form
to form ![]() . The results of the choice can be seen in figure 4. Clearly, the consumption behavior depicted by this restricted model is different from its unrestricted partner. The utility of the agent is approximately 4% lower when restricted to making
Gaussian choices, and it is seen that this is clearly the result of being forced to use a smoother dispersion of probability across the consumption-wealth grid.
. The results of the choice can be seen in figure 4. Clearly, the consumption behavior depicted by this restricted model is different from its unrestricted partner. The utility of the agent is approximately 4% lower when restricted to making
Gaussian choices, and it is seen that this is clearly the result of being forced to use a smoother dispersion of probability across the consumption-wealth grid.
Aside from the lower utility achieved by restricting the form of ![]() , it is clear that the consumption behavior itself has been changed quite dramatically. By insisting on the smooth form of
the Gaussian distribution, note that the agent is forced to choose a single highest probability point and smoothly decrease the probability away from that mode. This means that the agent's risk preferences cannot be taken into account as well as they can in the non-parametric version. The agent is
able to "discretize" his or her consumption in the unrestricted model. That is, they are able to choose more than one mode for the resulting marginal distribution of cosumption and they can surround consumption values they would like the give high probability with consumption levels they can give
very little probability. The Gaussian approximation rule is actually likely to produce less stickiness than the more appropriate non-parametric specification. By forcing the consumption marginal to take such a smooth shape, the model designer is forcing the agent to place probability where they
would prefer not to, and choose a much smoother reaction function of consumption choices to states than is suggested by the non-parametric model that fully incorporates the agent's risk attitude into this reaction function. To see this, examine the scales of the colorbars on the sides of the plots
in figure 4. Note that the agent would like to have essentially no probability weight on
, it is clear that the consumption behavior itself has been changed quite dramatically. By insisting on the smooth form of
the Gaussian distribution, note that the agent is forced to choose a single highest probability point and smoothly decrease the probability away from that mode. This means that the agent's risk preferences cannot be taken into account as well as they can in the non-parametric version. The agent is
able to "discretize" his or her consumption in the unrestricted model. That is, they are able to choose more than one mode for the resulting marginal distribution of cosumption and they can surround consumption values they would like the give high probability with consumption levels they can give
very little probability. The Gaussian approximation rule is actually likely to produce less stickiness than the more appropriate non-parametric specification. By forcing the consumption marginal to take such a smooth shape, the model designer is forcing the agent to place probability where they
would prefer not to, and choose a much smoother reaction function of consumption choices to states than is suggested by the non-parametric model that fully incorporates the agent's risk attitude into this reaction function. To see this, examine the scales of the colorbars on the sides of the plots
in figure 4. Note that the agent would like to have essentially no probability weight on ![]() , while the nodes directly to the right and left of that value
are among the most heavily weighted. By enforcing Gaussianity, the agent must choose to be essentially indifferent across those three nodes. The tractable nature of the Gaussian-In-Gaussian-Out assumption is a siren-call that leads not just to a different result, but simply incorrect predictions
about the consumer's optimal behavior. Thus, it is a poor approximation to the full RI framework as it fails to accurately incorporate the agent's preferences.
, while the nodes directly to the right and left of that value
are among the most heavily weighted. By enforcing Gaussianity, the agent must choose to be essentially indifferent across those three nodes. The tractable nature of the Gaussian-In-Gaussian-Out assumption is a siren-call that leads not just to a different result, but simply incorrect predictions
about the consumer's optimal behavior. Thus, it is a poor approximation to the full RI framework as it fails to accurately incorporate the agent's preferences.
6 Conclusion
The rational inattention framework is unique in that it is presently the only paradigm with the capability to quantify, constrain, and optimally allocate the scarce resource of information-processing capacity. While other information frictions restrict when attention is paid and information is acquired, the RI framework allows the agent to optimally allocate his or her pool of attention thus giving control over not only when, but how much attention is paid.
The Sims (2006) model, while simplified, demonstrates the power of the framework by showing how the agent's preferences, combined with their information-processing constraint, result in the optimal allocation of the "attention resource." This paper demonstrates that
this problem is convex and can be solved very quickly using certain tools, thus demonstrating that the computational intensity of this smaller problem is far less than originally perceived and opening the door to more complex and dynamic problems of interest in both macro- and microeconomic
literatures. This paper also illustrates the importance of optimally deriving the non-parametric decision rule ![]() , rather than assuming a Gaussian form. Gaussian assumptions, which lend
considerable tractability in certain dynamic frameworks, are shown to produce behavior on the part of the agent that is dramatically at odds with the optimally derived behavior--in fact lessening inertial effects of information-processing constraints by reducing the "discreteness" of the behavior
of the RI agent. It is hoped that by illustrating the importance of the fully-optimal approach to attention-allocation problems, and by demonstrating that solutions can be quickly and accurately found, that further research in this paradigm will be encouraged.
, rather than assuming a Gaussian form. Gaussian assumptions, which lend
considerable tractability in certain dynamic frameworks, are shown to produce behavior on the part of the agent that is dramatically at odds with the optimally derived behavior--in fact lessening inertial effects of information-processing constraints by reducing the "discreteness" of the behavior
of the RI agent. It is hoped that by illustrating the importance of the fully-optimal approach to attention-allocation problems, and by demonstrating that solutions can be quickly and accurately found, that further research in this paradigm will be encouraged.
Bibliography
"Automatic Differentiation of Nonlinear AMPL Models," AT&T Bell Labratories Numerical Analysis Manuscript, 91-05. Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, no. 19 in Frontiers in Applied Mathematics. Society for Industrial and Applied Mathematics. "The Life-Cycle Effects of Information-Processing Constraints," mimeo. "Verifying the Solution from a Nonlinear Solver: A Case Study," American Economic Review. Automatic Differentiation: Techniques and Applications, vol. 120 of Lecture Notes in Computer Science. Springer-Verlag. "Implications of Rational Inattention," Journal of Monetary Economics, 50(3), 665-690. "Rational Inattention: A Research Agenda," Working paper, Princeton University.
A. Proof of the Convexity of the Mutual Information Constraint
![\displaystyle \Bigg\{\Bigg[\sum\limits_{j= 1} f_{i,j} \Bigg] \cdot \Bigg[ \log \bigg(\sum\limits_{j =1} f_{i,j}\bigg) \Bigg] \Bigg\} \cr](img74.gif)
Proof. Because ![]() is fixed, attention can be limited to
is fixed, attention can be limited to
![\displaystyle MI_1(f_{i,j}) = \sum\limits_{i = 1}^{N_c}\sum\limits_{j = 1}^{N_w} f_{i,j}\cdot\log(f_{i,j}) - \sum\limits_{i =1}^{N_c}\left\{\Bigg[\sum\limits_{j = 1}^{N_w} f_{i,j} \Bigg] \cdot \Bigg[ \log \bigg(\sum\limits_{j = 1}^{N_w} f_{i,j} \bigg)\Bigg]\right\}.](img75.gif)
To begin, simplify the remaining problem by separating the ![]() and
and ![]() summations.
summations.
![\displaystyle MI_1(f_{i,j}) = \sum\limits_{i = 1}^{N_c} \left\{ \sum\limits_{j = 1}^{N_w} f_{i,j} \log \big( f_{i,j} \big) - \Bigg[ \sum\limits_{j = 1}^{N_w} f_{i,j} \Bigg] \cdot \Bigg[ \log \bigg( \sum\limits_{j = 1}^{N_w} f_{i,j} \bigg) \Bigg] \right\}](img78.gif)
The outermost summation in equation (A.3) is over the ![]() index, meaning that concentration can be focused only on the inner summations, over
index, meaning that concentration can be focused only on the inner summations, over ![]() (due the convexity of the sum of convex functions). Now, the goal becomes to prove that
(due the convexity of the sum of convex functions). Now, the goal becomes to prove that
![\displaystyle MI_2(f_{i,j}) = \sum\limits_{j = 1}^{N_w} f_{i,j} \log(f_{i,j}) - \left[ \sum\limits_{j = 1}^{N_w} f_{i,j} \right] \cdot \left[ \log \bigg(\sum\limits_{j = 1}^{N_w} f_{i,j} \bigg) \right]](img79.gif)
is convex for a given ![]() . To this end, the following notational substitutions are made:
. To this end, the following notational substitutions are made:
![\displaystyle f_{i,j} = x_k , \hskip0.25in x = [x_1, x_2, \dots, x_N]^T , \hskip0.25in X = \left[\begin{matrix}x_1 & 0 & \cdots & 0 0 & x_2 & & \vdots \vdots & &\ddots & 0 0 & \cdots & 0 & x_N \end{matrix}\right]](img80.gif)
where ![]() . Also, define
. Also, define ![]() to be a column vector of ones of length
to be a column vector of ones of length
![]() , and
, and ![]() =
= ![]() . With this new notation, the problem reduces to demonstrating that
. With this new notation, the problem reduces to demonstrating that
is convex. To this end, it will be shown that the Hessian of ![]() is positive semi-definite.
is positive semi-definite.
![\displaystyle \nabla h(x) = \left[ \begin{matrix}\log(x_1) \log(x_2) \vdots \log(x_N) \end{matrix} \right] - \left[ \begin{matrix}\log(u^T x) \log(u^T x) \vdots \log(u^T x) \end{matrix} \right] \; , \; \nabla^2 h(x) = X^{-1} - \frac{1}{u^T x} U](img88.gif) |
For the Hessian to be positive semi-definite, it needs to be shown that, for all non-zero
![]() ,
,
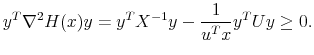 |
Breaking this into two pieces, address the right-most element first:
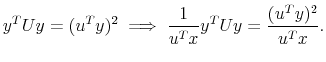 |
The remaining part of the equation can be simplified to:
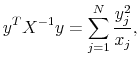 |
and thus, it remains to be shown that
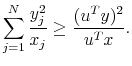
In order to demonstrate (A.5), two additional assumptions will be made:
The reason that this assumption can be made without loss of generality is that replacing ![]() with
with
![]() will only increase
will only increase ![]() while leaving
while leaving ![]() unchanged. Implicitly, this uses the fact that requiring
unchanged. Implicitly, this uses the fact that requiring
![]() does nothing to aid in the proof.
does nothing to aid in the proof.
This assumption is allowed because the sign of
![]() is invariant with respect to a scaling of
is invariant with respect to a scaling of ![]() and
and ![]() is impossible when
is impossible when ![]() and
and ![]() .
.
Before taking advantage of the two assumptions, note that
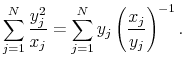 |
Therefore, show:
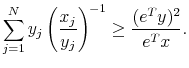 |
To this end,
- Define
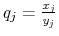 ,
, - Recall that
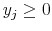 for
for
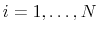 and
and
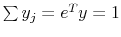 ,
, - Note that
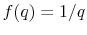 is a convex function.
is a convex function.
Therefore
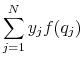 |
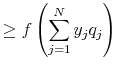 |
|
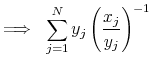 |
![\displaystyle \ge \left[ \sum\limits_{j=1}^N y_j \bigg( \frac{x_j}{y_j} \bigg) \right]^{-1} = \frac{1}{u^T x} = \frac{(u^T y)^2}{u^T x}.](img114.gif) |
Therefore,
![]() is positive semi-definite. This means that equation (A.4) is convex for a given
is positive semi-definite. This means that equation (A.4) is convex for a given ![]() , and thus that the sum over
, and thus that the sum over ![]() in equation (A.3) is convex making equation (A.2) convex, meaning that the
mutual information constraint, equation (A.1), is convex for
in equation (A.3) is convex making equation (A.2) convex, meaning that the
mutual information constraint, equation (A.1), is convex for
![]() .
.
B. The Iterative Procedure
There is an alternative solution procedure for the two-period RI problem. This problem lends itself to a semi-analytical approach based on iteration on the first-order conditions of the optimization problem. As was noted earlier, the use of solution methods where
![]() will produce qualitatively identical results because
will produce qualitatively identical results because
![]() , meaning the that solution has no discontinuities at
, meaning the that solution has no discontinuities at
![]() and therefore the results where some
and therefore the results where some ![]() 's
's
![]() where
where
![]() is very small (say
is very small (say ![]() ) will incorporate the properties of the
truly optimal result. The first order conditions for
) will incorporate the properties of the
truly optimal result. The first order conditions for
![]() are:
are:
![\displaystyle U_{i,j} - \lambda \left[\log(f_{i,j}) - \log \Bigg(\sum\limits_{j = 1}^{N_w} f_{i,j} \Bigg) \right] - \omega_j = 0](img121.gif) |
where
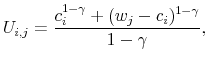 |
Specifying a value for ![]() (the multiplier on the information-processing constraint, equation (5)) is identical to choosing a
(the multiplier on the information-processing constraint, equation (5)) is identical to choosing a ![]() (as expected, different parameterizations result in different
(as expected, different parameterizations result in different ![]() 's for the same value of
's for the same value of ![]() ). The utility function and
). The utility function and ![]() are known, so elimination of
are known, so elimination of ![]() (the multiplier on the constraint requiring the joint distribution to conform to the properties of the exogenous wealth distribution, equation (3), for a specific
(the multiplier on the constraint requiring the joint distribution to conform to the properties of the exogenous wealth distribution, equation (3), for a specific
![]() ) is all that is required before solving for the probabilities. This is done by taking advantage of the log-properties inherited from the entropic constraint.
) is all that is required before solving for the probabilities. This is done by taking advantage of the log-properties inherited from the entropic constraint.
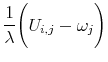
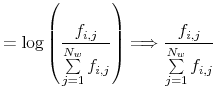
At this point, it should be noted that the denominator of the LHS of (B.1) represents the marginal probability of ![]() , which is called
, which is called ![]() . Thus,
. Thus,
![\displaystyle f_{i,j} = \exp \left[ (1/\lambda) (U_{i,j} - \omega_j) \right] p(c_i) = \frac{\exp[(1/\lambda) U_{i,j}]}{\exp[\omega_j/\lambda]} p(c_i).](img129.gif) |
Equation (3) yields that:
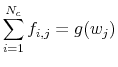 |
![\displaystyle = \frac{1}{\exp[\omega_j/\lambda]} \sum\limits_{i = 1}^{N_c} \exp[(1/\lambda)U_{i,j}] p(c_i) \cr \Longrightarrow \;\; \frac{1}{\exp[\omega_j/\lambda]}](img131.gif) |
![\displaystyle = \frac{g(w_j)}{\sum\limits_{i = 1}^{N_c} \exp[(1/\lambda)U_{i,j}] p(c_i)}.](img132.gif) |
Therefore, a solution (almost) for the probabilities is given as:
![\displaystyle f_{i,j} = \frac{\exp[(1/\lambda)U_{i,j}] p(c_i) g(w_j)}{\sum\limits_{i=1}^{N_c} \exp[(1/\lambda)U_{i,j}] p(c_i)}.](img133.gif)
Equation (B.2) is the solution, but recall that
![]() .13 The
procedure is completed via iteration on
.13 The
procedure is completed via iteration on ![]() . Starting with a random
. Starting with a random ![]() matrix and
generating a marginal distribution over
matrix and
generating a marginal distribution over ![]() by summing, one can use these values to construct the solutions for
by summing, one can use these values to construct the solutions for
![]() , then sum the rows of the
, then sum the rows of the ![]() matrix to form the next iteration of
matrix to form the next iteration of
![]() , and continue until subsequent
, and continue until subsequent ![]() distributions are arbitrarily close to each
other, giving us
distributions are arbitrarily close to each
other, giving us
![]() values which satisfy (B.2). This procedure appears to converge on the same distribution for any starting
values which satisfy (B.2). This procedure appears to converge on the same distribution for any starting ![]() distribution. Successive iterations are within
distribution. Successive iterations are within ![]() of each other within 60 seconds when done using MATLAB on a 3
GHz Pentium 4 running Windows XP.
of each other within 60 seconds when done using MATLAB on a 3
GHz Pentium 4 running Windows XP.
Equation (B.2) shows that the heart of the RI framework is interaction between the information-processing constraint (recall that ![]() is the LaGrange multiplier
on that constraint) and the agent's preferences. The agent chooses how much attention to pay, and where, based on that interaction. That the agent's risk tolerance affects what he or she observes has the potential to open up several new avenues of reseach in the future.
is the LaGrange multiplier
on that constraint) and the agent's preferences. The agent chooses how much attention to pay, and where, based on that interaction. That the agent's risk tolerance affects what he or she observes has the potential to open up several new avenues of reseach in the future.
It should be noted that this procedure derives identical solutions to the procedure outlined above using AMPL, and without using sophisticated optimizers, but also that it is slower. Additionally, this problem has an undiscounted utility function and it's static nature make FOC-based analysis possible.
B.1 Theory vs. Computation
The quasi-analytical approach of this appendix yields an equation for the probability of consuming ![]() at wealth level
at wealth level ![]() driven by
driven by
![]() . While this theoretical result is central to RI theory (that the probability is driven by the interaction of the utility of that
. While this theoretical result is central to RI theory (that the probability is driven by the interaction of the utility of that ![]() pair and the processing capacity), this equation represents a potential numerical pitfall. The problem is one of computer accuracy: when the absolute value of
pair and the processing capacity), this equation represents a potential numerical pitfall. The problem is one of computer accuracy: when the absolute value of
![]() is large for all
is large for all ![]() combinations, the theory will predict a
smooth, descriptive function of
combinations, the theory will predict a
smooth, descriptive function of ![]() while the computer will return either zero or
while the computer will return either zero or ![]() for all
for all ![]() pairs (If the utility is negative, zero; if positive,
pairs (If the utility is negative, zero; if positive, ![]() ). The
). The
![]() problem is purely an artifact of the computer's inability to deal with very large or small numbers, but it is dramatically exacerbated in this exponential
situation.14 The bad news is that
problem is purely an artifact of the computer's inability to deal with very large or small numbers, but it is dramatically exacerbated in this exponential
situation.14 The bad news is that
![]() is central to RI theory and therefore present in analytically represented RI model-solutions in general. The good news is that it is easy to identify: utility
and
is central to RI theory and therefore present in analytically represented RI model-solutions in general. The good news is that it is easy to identify: utility
and ![]() values can be determined, and model-designers can plan to work around, or find model-specific solutions to, this issue.
values can be determined, and model-designers can plan to work around, or find model-specific solutions to, this issue.
B.2 Results Compared to AMPL/KNITRO
Because of the first-order-conditions-based approach of the iterative method, this technique requires that
![]() , which, as seen above, is not reasonable. Due to the interior-point nature of the KNITRO solver, the results are identical up to the error introduced by the stopping
tolerances of the iterative scheme.
, which, as seen above, is not reasonable. Due to the interior-point nature of the KNITRO solver, the results are identical up to the error introduced by the stopping
tolerances of the iterative scheme.