
Household Welfare, Precautionary Saving, and Social Insurance under Multiple Sources of Risk*
Keywords: Income risk, consumption, lifecycle models, precautionary savings, social insurance
Abstract:
This paper assesses the quantitative importance of a number of sources of income risk for household welfare and precautionary saving. To that end I construct a lifecycle consumption model in which household income is subject to shocks associated with disability, health, unemployment, job changes, wages, work hours, and a residual component of household income. I use PSID data to estimate the key processes that drive and affect household income, and then use the consumption model to: (i) quantify the welfare value to consumers of providing full, actuarially fair insurance against each source of risk and (ii) measure the contribution of each type of shock to the accumulation of precautionary savings. I find that the value of fully insuring disability, health, and unemployment shocks is extremely small (well below 1/10 of 1% of lifetime consumption in the baseline model). The gains from insuring shocks to the wage and to the residual component of household income are significantly larger (above 1% and 2% of lifetime consumption, respectively). These two shocks account for more than 60% of precautionary wealth.
1 Introduction
A great deal of attention has been devoted to modeling dynamics and measuring risk in individual and household income. On one front, there is a substantial empirical literature in labor economics which has studied the dynamic properties of labor income.1 On a different front, a large number of studies in macroeconomics and public finance, which require the specification of an income process and measures of income uncertainty, have used a variety of strategies to quantify income risk.2
In spite of these large bodies of work, surprisingly little is known about the specific sources underlying income risk and their importance for households' economic well-being. Almost all existing studies model income risk by means of one or two statistical innovations in a univariate time-series income process. Such innovations are difficult to interpret since they capture variation in income that may be due to a number of rather different factors including unemployment, illness, job changes, unexpected changes in wages and hours of work, etc. It is impossible to tell from such formulations which of the many possible sources drive the unexplained variation in income, or what the relative importance of the different sources is. Yet, identifying the sources of variation and risk is essential for addressing questions about insurance of risk, since most insurance programs-whether public or private-typically address specific risks, as in the case of unemployment insurance and disability insurance.
Identifying the various sources of risk and quantifying their effects on household welfare necessitates extending the usual treatment and modeling of income. First, we need to explicitly account for the fact that households face a large number of risks which are likely to differ in key aspects such as their predictability, insurability, relative importance over the lifecycle, etc. Second, one needs to recognize that households can affect their income by adjusting their behavior along a number of margins, including their labor supply, saving, job-search effort, and timing of retirement. Unfortunately, introducing both multiple risks and multiple choice variables into a decision model as the one considered here makes the computational cost of solving the model too burdensome. This paper thus follows most previous studies in treating income as exogenous, and advances the existing literature by considering a significantly richer specification of income risk.
More specifically, I propose a lifecycle consumption model in which households optimally choose consumption and saving, and where household income is subject to shocks associated with disability, health, unemployment, job changes, wages, hours, and a residual component of household income.3 The specification allows for complex dynamic relationships which are difficult to capture in a simple reduced-form approach. An unemployment shock, for instance, affects household income via several channels: it has a direct negative effect on current earnings operating through work hours; it also has a positive effect on household income which reflects both the labor supply response of other household members as well as unemployment insurance benefits; it affects the new wage of the worker upon finding a new job after the spell of unemployment; and finally, it affects social security benefits during retirement through the effect on lifetime average earnings.
I use PSID data to estimate the processes which govern the joint evolution of variables that drive and affect income. Estimation is complicated by the presence of both discrete and continuous variables, state dependence in several equations, and the need to control for unobserved heterogeneity in all equations. I address these issues by using a variety of estimation techniques including generalized indirect inference.4 The parameterized model is then used to quantify the welfare value to consumers (in terms of the equivalent variation in lifetime consumption) of providing full, actuarially fair insurance against each of the sources of uninsured income risk, and to measure the contribution of each source of uncertainty to the accumulation of precautionary savings.5
Very few previous studies have analyzed the welfare effects of multiple sources of risk in a unified framework. One exception is Low, Meghir, and Pistaferri (2006), who consider a consumption model with endogenous participation and job-mobility decisions, and two sources of uncertainty: unemployment and wage risk. They find that wage risk has important welfare effects but that unemployment risk does not.
One related line of research has examined a variety of mechanisms to insure household consumption, including unemployment insurance (Gruber, 1997; Browning and Crossley, 2001), food stamps (Blundell and Pistaferri, 2003), and Medicaid (Gruber and Yelowitz, 1999).6 Some of the empirical studies in this literature have looked at the effects of specific income shocks and of specific forms of insurance (such as unemployment and unemployment insurance) on the levels of consumption. One important difference between this paper and those studies is that this paper captures, and focuses on, the uncertainty in consumption introduced by specific sources of income risk, rather than on the levels of consumption.
My main findings are as follows. The welfare gains from fully insuring disability, health, and unemployment shocks are extremely small (well below 1/10 of 1% of lifetime consumption in the baseline model). The gains from insuring wage shocks and the additional component of household income are significantly larger (above 1% and 2% of lifetime consumption, respectively). These two shocks account for more than 60% of precautionary wealth.
The paper is organized as follows. The next section presents the lifecycle consumption model and discusses its implementation. Section 3 describes the data. Section 4 presents estimation results and an evaluation of the fit of the model. Section 5 discusses the solution of the parameterized lifecycle model. Section 6 presents the welfare and precautionary saving analysis, and section 7 concludes.
2.1 Overview
This section introduces a lifecycle model of consumption in which households face multiple income shocks. The decision unit is the household and a period corresponds to one year. Households are part of the labor force for ![]() years, retire at an exogenously specified date, and live in retirement for up to
years, retire at an exogenously specified date, and live in retirement for up to ![]() years.7 Years in the model are indexed by the variable
years.7 Years in the model are indexed by the variable ![]() , where
, where ![]() indicates the first period of a worker's career. During working years,
indicates the first period of a worker's career. During working years, ![]() thus represents potential
experience, although sometimes
thus represents potential
experience, although sometimes ![]() will also be referred to as age, especially when refering to the retirement years. After retirement, households face
mortality risk.
will also be referred to as age, especially when refering to the retirement years. After retirement, households face
mortality risk.
The choice problem facing the household is standard: every period, households choose consumption and saving with the objective of maximizing expected discounted utility over their remaining periods of life:
![]() , where
, where
![]() is the expectations operator conditional on information available in period
is the expectations operator conditional on information available in period ![]() ,
,
![]() is the discount factor,
is the discount factor,![]() are conditional survival
probabilities8,
are conditional survival
probabilities8, ![]() is the per-period utility
function satisfying
is the per-period utility
function satisfying
![]() ,
,
![]() , and
, and
![]() ,
,![]() is household consumption, and
is household consumption, and
![]() is the maximum age attainable. The household is assumed to have no bequest motives.
is the maximum age attainable. The household is assumed to have no bequest motives.
The dynamic budget constraint is
![]() , where
, where ![]() is cash on hand,
is cash on hand, ![]() is the real interest rate, and
is the real interest rate, and ![]() is total household nonasset income. Each period, households receive an exogenous stream of nonasset income
is total household nonasset income. Each period, households receive an exogenous stream of nonasset income ![]() . During the working years,
. During the working years, ![]() should be thought of as encompassing all labor and transfer income of the household.9During the
retirement years,
should be thought of as encompassing all labor and transfer income of the household.9During the
retirement years, ![]() consists of social security benefits.10 Nonasset income depends on a number of stochastic variables and shocks:
consists of social security benefits.10 Nonasset income depends on a number of stochastic variables and shocks:
![]() , where
, where
![]() is a vector of shocks and
is a vector of shocks and ![]() is a vector of state
variables which describe household characteristics such as health, employment, wage rate, etc. State variables
is a vector of state
variables which describe household characteristics such as health, employment, wage rate, etc. State variables ![]() evolve stochastically over time according to the law of motion
evolve stochastically over time according to the law of motion
![]() , where
, where
![]() is a vector of shocks. I next describe separately, and in more detail, the problem faced by the household in the working years and in the retirement years.
is a vector of shocks. I next describe separately, and in more detail, the problem faced by the household in the working years and in the retirement years.
2.2 Working Years
During the household's working years, the state variables that affect income and are included in vector ![]() are: (i) an indicator of disability
are: (i) an indicator of disability ![]() ; (ii) an indicator of other health limitations
; (ii) an indicator of other health limitations ![]() ; (iii) an indicator of employment status
; (iii) an indicator of employment status ![]() ; (iv) a persistent component of the wage
; (iv) a persistent component of the wage ![]() ; and (v) a persistent component of
household income
; and (v) a persistent component of
household income ![]() , which captures all residual variation in household income not explained by earnings of the head or state variables
, which captures all residual variation in household income not explained by earnings of the head or state variables ![]() ,
, ![]() , and
, and ![]() . This residual component turns out to play a large role in explaining the variation of household income in the PSID.11Households in the model take into account their current health status, employment status, and non-transitory aspects of wages and household income when forming expectations about uncertain future nonasset income.
. This residual component turns out to play a large role in explaining the variation of household income in the PSID.11Households in the model take into account their current health status, employment status, and non-transitory aspects of wages and household income when forming expectations about uncertain future nonasset income.
The household's decision problem during the working years is:
Maximize
![\displaystyle \mathit{E}_{t}[\sum_{s=t}^{T}\beta^{s-t}\pi_{s}u(c_{s})]](img34.gif)
subject to
Above, equation (1) describes the evolution of the indicator of disability ![]() . The value of
. The value of ![]() depends on age
depends on age ![]() , on whether the household (head) was disabled in the previous period
, on whether the household (head) was disabled in the previous period ![]() , on any other previous-period health limitations
, on any other previous-period health limitations ![]() , and on an
, and on an ![]() shock
shock
![]() . Index
. Index ![]() indicates a specific household type.12 Equation (2) describes the evolution of the health limitations indicator
indicates a specific household type.12 Equation (2) describes the evolution of the health limitations indicator ![]() , which depends on age, lagged disability, lagged health, and an
, which depends on age, lagged disability, lagged health, and an ![]() shock
shock
![]() . In addition,
. In addition, ![]() depends on current disability, since
depends on current disability, since
![]() is defined to be 1 whenever
is defined to be 1 whenever ![]() equals 1. Equation (3) describes the evolution of employment status
equals 1. Equation (3) describes the evolution of employment status ![]() , which depends on potential experience
, which depends on potential experience ![]() , current disability status, current health limitations, previous-period employment status, and a set of
, current disability status, current health limitations, previous-period employment status, and a set of ![]() shocks.13
shocks.13
Equation (4) determines the evolution of the persistent wage component
![]() , which depends on current and previous-period employment status (i.e., on the employment transition between the two periods), on its own lagged value,
on an
, which depends on current and previous-period employment status (i.e., on the employment transition between the two periods), on its own lagged value,
on an ![]() shock
shock
![]() , and on whether there was a job change between periods
, and on whether there was a job change between periods ![]() and
and
![]() .14 Equation (5)
shows the dependence of the persistent component
.14 Equation (5)
shows the dependence of the persistent component
![]() on its own lagged value and a stochastic shock. Equation (6) describes the evolution of cash on hand, making explicit that the value of household nonasset
income
on its own lagged value and a stochastic shock. Equation (6) describes the evolution of cash on hand, making explicit that the value of household nonasset
income ![]() depends on the realizations of variables
depends on the realizations of variables ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,
![]() ,
,
![]() ,
,
![]() , and
, and
![]() .15 Finally, households
cannot borrow more than amount
.15 Finally, households
cannot borrow more than amount
![]() in any given period.
in any given period.
2.3 Retirement Years
In all periods following retirement labor income is zero. Retired households receive nonasset income from social security only. The level of social security benefits, ![]() , is determined in the last year of work, according to the formula
, is determined in the last year of work, according to the formula
where
Retired households in the model may additionally face out-of-pocket medical expenditures ![]() , which reduce net income disposable for consumption. The household's decision problem
during the retirement years is thus:
, which reduce net income disposable for consumption. The household's decision problem
during the retirement years is thus:
Maximize
subject to
Above, equation (8) describes the evolution of
![]() , the persistent component of out-of-pocket medical expenditures. Equation (9) describes the evolution of social security benefits. Finally, equation (10) describes the evolution of cash on hand during retirement, reflecting the fact that exogenous nonasset income now comes from social security benefits
, the persistent component of out-of-pocket medical expenditures. Equation (9) describes the evolution of social security benefits. Finally, equation (10) describes the evolution of cash on hand during retirement, reflecting the fact that exogenous nonasset income now comes from social security benefits ![]() and that
there may be out-of-pocket medical expenses
and that
there may be out-of-pocket medical expenses ![]() which would reduce income available for consumption. Additionally, households may receive insurance transfers
which would reduce income available for consumption. Additionally, households may receive insurance transfers ![]() .
.
Transfers for retired households are intended to provide a minimum level of consumption after accounting for medical expenditures. These transfers capture the combined effects of programs such as Food Stamps, Supplemental Security Income, and Medicaid. A common specification for such transfers
is
![]()
![]()
![]() (see Hubbard, Skinner, and Zeldes (1994, 1995) and Scholz, Seshadri, and Khitatrakun (2006)). The introduction of medical expenditures and transfers
(see Hubbard, Skinner, and Zeldes (1994, 1995) and Scholz, Seshadri, and Khitatrakun (2006)). The introduction of medical expenditures and transfers
![]() , however, complicates the solution of the consumption decisions because they introduce nonconvexities which lead to the existence of multiple local maxima in the solution of the
Bellman equation. This problem can be addressed by using a global search in the optimization involved in the solution of the Bellman equation as in Hubbard, Skinner, and Zeldes (1994, 1995), but it increases the computation time required to solve the problem significantly. This will be left for
future research. This version makes the simplifying assumption that medical expenditures can wipe out current income but cannot affect accumulated wealth. This assumption preserves the concavity of the righ-hand-side of the Bellman equation and guarantees that the unique local maximum is also the
global maximum. It also preserves the monotonicity (in wealth) of the consumption policy functions. On the other hand, this simplifying assumption significantly restricts the potential importance of medical expenditures. The treatment of medical expenditures here is thus preliminary and the results
should be interpreted with caution. Several studies suggest that medical expenditures are important for saving behavior and potentially for welfare. Examples include Palumbo (1999) and De Nardi, French, and Jones (2006).
, however, complicates the solution of the consumption decisions because they introduce nonconvexities which lead to the existence of multiple local maxima in the solution of the
Bellman equation. This problem can be addressed by using a global search in the optimization involved in the solution of the Bellman equation as in Hubbard, Skinner, and Zeldes (1994, 1995), but it increases the computation time required to solve the problem significantly. This will be left for
future research. This version makes the simplifying assumption that medical expenditures can wipe out current income but cannot affect accumulated wealth. This assumption preserves the concavity of the righ-hand-side of the Bellman equation and guarantees that the unique local maximum is also the
global maximum. It also preserves the monotonicity (in wealth) of the consumption policy functions. On the other hand, this simplifying assumption significantly restricts the potential importance of medical expenditures. The treatment of medical expenditures here is thus preliminary and the results
should be interpreted with caution. Several studies suggest that medical expenditures are important for saving behavior and potentially for welfare. Examples include Palumbo (1999) and De Nardi, French, and Jones (2006).
2.4 Model Implementation
This section discusses two points about implementing the model presented above. The first point regards index ![]() . As mentioned earlier,
. As mentioned earlier, ![]() indexes the household type. Types can be defined based on observed characteristics (education, race) and unobserved characteristics (unobserved permanent heterogeneity). Different household types will face
different processes (different parameter values) governing the evolution of the various state variables and income. The parameterized lifecycle model will be evaluated here for one specific household type: households whose head is white, who have the mean level of education in the PSID sample, and
who are at the mean of the distribution of the unobserved permanent heterogeneity components. One important assumption maintained throughout the analysis is that unobserved heterogeneity is known at the beginning of a worker's career. Under this assumption, these
permanent components do not constitute risk (i.e., uncertainty).
indexes the household type. Types can be defined based on observed characteristics (education, race) and unobserved characteristics (unobserved permanent heterogeneity). Different household types will face
different processes (different parameter values) governing the evolution of the various state variables and income. The parameterized lifecycle model will be evaluated here for one specific household type: households whose head is white, who have the mean level of education in the PSID sample, and
who are at the mean of the distribution of the unobserved permanent heterogeneity components. One important assumption maintained throughout the analysis is that unobserved heterogeneity is known at the beginning of a worker's career. Under this assumption, these
permanent components do not constitute risk (i.e., uncertainty).
The second point regards the definition of the state variables in the model and their correspondence to variables in the PSID. Most of the variables included in the state vector, such as those refering to health or employment, will refer to characteristics of the household head in the PSID. The reason is that these variables are likely to be the most important determinants and predictors of income. Household income, on the other hand, will refer to a household aggregate in the PSID which includes labor income and transfer income from all members of the household. I use this variable to construct predicted income for a household of the average size and composition in the PSID sample. The household income process is estimated using this predicted income measure (which has been purged from variation due to differences in household size and composition).
2.5 Model Parameterization
All parameters that appear in the parameterized form of transition equations (1) - (5) and (8) are estimated using PSID data. Estimation is discussed in section 4. On the other hand, model parameters such as the coefficient or relative risk aversion, the real interest rate, and the discount factor are chosen based on values found elsewhere in the literature. The sensitivity of results to alternative assumptions about these parameters is examined in a later section.
Preferences are assumed to be of the constant relative risk aversion (CRRA) form,
![]() , where
, where ![]() is the coefficient of
relative risk aversion. The baseline model assumes a value of
is the coefficient of
relative risk aversion. The baseline model assumes a value of
![]() .17The interest rate is assumed to be
fixed at the value
.17The interest rate is assumed to be
fixed at the value ![]() (Gourinchas and Parker, 2002). The discount factor
(Gourinchas and Parker, 2002). The discount factor ![]() is set such that the discount rate equals the interest rate, as in Low, Meghir, and Pistaferri (2006) and many other studies.18Conditional survival probabilities are obtained from the Life Tables published by the Center for Disease and Control Prevention of the U.S. Department of Health and Human Services. Finally, households in the baseline model are assumed to be credit-constrained (
is set such that the discount rate equals the interest rate, as in Low, Meghir, and Pistaferri (2006) and many other studies.18Conditional survival probabilities are obtained from the Life Tables published by the Center for Disease and Control Prevention of the U.S. Department of Health and Human Services. Finally, households in the baseline model are assumed to be credit-constrained (
![]() ).
).
3 Data
Estimation is conducted using data from the PSID. I start here by giving a brief description of the key variables. Appendix 1 provides a detailed explanation of all variables used. The disability indicator ![]() equals 1 if an individual is disabled and 0 otherwise. It is constructed from the respondent's self-reported employment status at the
survey date, where "disabled"is one of the possible answers in the questionnaire. A currently disabled individual is by definition not currently employed. This variable is thus likely to capture severe forms of disability. Indicator
equals 1 if an individual is disabled and 0 otherwise. It is constructed from the respondent's self-reported employment status at the
survey date, where "disabled"is one of the possible answers in the questionnaire. A currently disabled individual is by definition not currently employed. This variable is thus likely to capture severe forms of disability. Indicator ![]() , on the other hand, is constructed based on the survey question: "Do you have any physical or nervous condition that limits the type of work or the amount of work you can do?"
, on the other hand, is constructed based on the survey question: "Do you have any physical or nervous condition that limits the type of work or the amount of work you can do?"![]() equals 1 when a respondent answers "yes", and 0 otherwise. This variable is thus likely to
capture both serious and less serious health limitations, including temporary illness and other conditions that affect work. Additionally,
equals 1 when a respondent answers "yes", and 0 otherwise. This variable is thus likely to
capture both serious and less serious health limitations, including temporary illness and other conditions that affect work. Additionally, ![]() is set to 1 whenever
is set to 1 whenever ![]() equals 1. Employment
equals 1. Employment ![]() , like disability, is based on self-reported employment status at the survey date. It equals 1 for employed and temporarily laidoff workers, and zero for disabled and unemployed individuals. Finally, household income
, like disability, is based on self-reported employment status at the survey date. It equals 1 for employed and temporarily laidoff workers, and zero for disabled and unemployed individuals. Finally, household income ![]() includes all labor and transfer income of the household head and, if present, of the spouse and any other family members. As was discussed in the previous section, I construct and use predicted income for a household of the average size and
composition in the PSID sample, in order to account for heterogeneity in household size and composition which is not present in the consumpion model.
includes all labor and transfer income of the household head and, if present, of the spouse and any other family members. As was discussed in the previous section, I construct and use predicted income for a household of the average size and
composition in the PSID sample, in order to account for heterogeneity in household size and composition which is not present in the consumpion model.
As will be discussed below, estimation is conducted in four parts, where each of the following four subsets of equations is estimated separately: (i) disability; (ii) health; (iii) employment, wage, and household income; (iv) medical expenditures. Some sample restrictions imposed vary slightly across the different estimation samples. Estimation of all equations other than medical expenditures uses data from the 1975-1997 PSID waves. Medical expenditures, on the other hand, use the 1999, 2001, and 2003 waves. The reason is that earlier waves did not contain information on medical expenses (note also that interviews have been conducted only every two years since 1997).
In all cases, the data include members of both the SRC and SEO samples, as well as nonsample members who married PSID sample members. I consider only households with a male head who is living in the household at the time of the interview. Both single and married individuals are included. I exclude a small fraction of person-year observations in which the head reports being a full-time student or "keeping house"at the time of the interview. These observations are discarded because in the lifecycle model household heads cannot be out of the labor force except when disabled. I also exclude individuals who are missing data on education. Only observations where the head is at least 18 years old are used.
Some additional sample restrictions, including restrictions based on potential experience (or age) differ according to the process being estimated. For estimation of the health limitations process, I use observations where potential experience ranges from 1 to 65. The corresponding age range is
18 to 87. This sample has ![]() observations. Table 1A (bottom panel) displays the number of observations and the mean of the health limitations indicator for different levels of potential
experience. The column labeled All t refers to all levels of potential experience, while the next columns report values for the ranges of potential experience indicated in the top row. The overall mean of the
observations. Table 1A (bottom panel) displays the number of observations and the mean of the health limitations indicator for different levels of potential
experience. The column labeled All t refers to all levels of potential experience, while the next columns report values for the ranges of potential experience indicated in the top row. The overall mean of the ![]() indicator is 0.136 and increases from 0.052 for low experience (
indicator is 0.136 and increases from 0.052 for low experience (
![]() ) to 0.497 for high experience (
) to 0.497 for high experience (![]() ).
).
Estimation of disability and of the joint process of employment, wage, and household income excludes retired individuals and observations where age exceeds 64 (the resulting range of potential experience is 1-48, with very few values above 45. Table 1A (top panel) displays the number of observations and the mean of the disability indicator for different levels of potential
experience. The overall mean of the ![]() indicator is 0.022 and increases from
0.022 for
indicator is 0.022 and increases from
0.022 for
![]() to 0.110 for
to 0.110 for ![]() .
.
In addition, for estimation of the employment, wage, and household income equations (which also uses data on work hours and labor earnings, as will be discussed below), I censor reported work hours at 4000, add 200 to reported hours before taking logs to reduce the impact of very low values on the variation in the logarithm, and I restrict observed wage rates and household income (in levels) to increase by no more than 500% and decrease to no less than 20% of their previous-year values.19 I also censor the wage to be no less than $3.50/hour and household income to be no less than $1,000/year in year-2000 dollars.20 Table 1B displays the number of observations, mean, standard deviation, minimum, and maximum values of all key variables used in the estimation of the joint model of income. The second-to-last row displays the raw household income data, while the last row displays the predicted value for a household of the average size and composition, which is the variable actually used in estimation.
Finally, estimation of the out-of-pocket medical expenditures process uses observations where potential experience is above 43, in correspondence with the model's assumption that medical costs are zero during working years. The PSID variable used here consists of all out-of-pocket payments made by the household over the course of the two years prior to the interview year (see Appendix 1). Table 1C provides summary statistics in thousands of year-2000 dollars. The sample consists of 2,831 observations and has a mean of 3.25, a standard deviation of 10.76, a 99th percentile of 38.63, and a maximum value of 317.47.
4 Parameter Estimation
This section presents the parametric models specified for the various transition equations introduced in section 2 and discusses their estimation. As was mentioned above, the estimation strategy involves estimating the various equations of the model in four parts. Specifically, the equations for medical expenditures, health limitations, and disability are estimated separately from the rest of the equations (employment, wage rates, and household income). The reasons for estimating these equations separately are the following: (i) Out-of-Pocket Medical Expenditures: As discussed above, estimation of medical expenditures uses PSID waves 1999, 2001, and 2003, while all other equations use data from waves 1975-1997. (ii) Health: In the lifecycle model, health appears as a state variable both before and after retirement. Estimation of the health process is therefore based on a sample which includes all levels of potential experience (and age). Most other state variables in the consumption model (including disability) relate to the labor market and their estimation therefore excludes high levels of potential experience (and age). (iii) Disability: I initially attempted to estimate the disability process jointly with all other labor market and income processes. However, the fact that the disability indicator in the PSID sample is zero more than 97% of the time introduces numerical instabilities in the implementation of indirect inference.21 Estimating the disability equation individually allows the use of standard maximum likelihood methods and sidesteps the numerical difficulties. The following subsections introduce the parametric forms used and discuss estimation as well as estimation results.
4.1 Disability
The transition equation for the disability indicator ![]() is assumed to have the following form
is assumed to have the following form
where
Table 2A presents estimation results for equation (11). The probability that ![]() is monotonically increasing in experience (the slope of the polynomial is
positive for
is monotonically increasing in experience (the slope of the polynomial is
positive for ![]() between 1 and 40). The coefficient of
between 1 and 40). The coefficient of
![]() on
on ![]() indicates a fairly high degree of state
dependence.22 Unobserved heterogeneity, with an estimated standard deviation of
indicates a fairly high degree of state
dependence.22 Unobserved heterogeneity, with an estimated standard deviation of
![]() , also plays a significant role.
, also plays a significant role.
4.2 Health
The transition equation for the health indicator is assumed to take the form
where
Table 2B presents estimation results (which are conditional on an individual not being disabled). The probability that ![]() increases monotonically with
age. Lagged health limitations have a fairly large and strongly significant effect on the probability of current health limitations (
increases monotonically with
age. Lagged health limitations have a fairly large and strongly significant effect on the probability of current health limitations (
![]() ). Unobserved heterogeneity also plays an important role (
). Unobserved heterogeneity also plays an important role (
![]()
![]() ).
).
4.3 Employment, Wage Rates, and Household Income
Employment, wage rates, and household income are determined jointly by a set of recursive equations. The system also includes an equation for job changes and an equation for work hours. Although job changes and work hours are not state variables in the lifecycle model, they are key variables in the determination of income. Therefore, the lifecycle model includes two shocks which capture job changes and innovations in work hours, respectively. The evolution of job changes and hours, and their effects on income, are thus estimated as part of the recursive system that drives household income. The following subsection presents the joint model of employment, job changes, wage rates, work hours, and household income. Additional details are provided in Appendix 3.
4.3.1 Functional Forms
Employment - Employment Transition
Conditional on being employed, next-period employment is determined by
Employment-employment transitions are thus determined by a latent variable which depends on a quadratic polynomial in potential experience
Unemployment - Employment Transition
Conditional on being unemployed, next-period employment is given by
Transitions from unemployment into employment are thus determined by a latent variable which depends on a quadratic polynomial in potential experience
Disability - Employment Transition
Transitions from disability back into employment are rather infrequent in the PSID sample. These transitions are modeled as
The fact that these transitions are infrequent in the data makes it difficult to estimate their dependence on experience or on permanent unobserved components.
Job Changes
Conditional on being employed in both ![]() and
and ![]() , the occurrence of a job change
between the two periods is determined by
, the occurrence of a job change
between the two periods is determined by
where
Employment-, Unemployment-, and Job Duration
Estimation of equations (13), (14), and (16) controls for duration dependence in employment and job mobility by including the variables ![]() ,
, ![]() , and
, and ![]() , respectively. Here,
, respectively. Here, ![]() is defined as the number of consecutive periods that an employed individual has been employed up to period
is defined as the number of consecutive periods that an employed individual has been employed up to period ![]() ,
, ![]() is the number of consecutive periods that an unemployed individual has been unemployed up to period
is the number of consecutive periods that an unemployed individual has been unemployed up to period ![]() , and
, and ![]() is the number of periods that an employed individual has been at their current job. It would be straightforward to introduce
is the number of periods that an employed individual has been at their current job. It would be straightforward to introduce
![]() ,
, ![]() , and
, and ![]() as state variables in the lifecycle consumption model from section 2. This is not done here because of the computational burden of the additional state variables. Instead, the approach is to control for duration
dependence in estimation, but to set the duration variables to their sample mean (by year of potential experience) when parameterizing the employment and job-change equations. I also experimented with estimating equations (13), (14), and (16)
without controlling for duration dependence. In this case the potential-experience profiles of the transition probabilities do not match the data well, but the results for welfare and precautionary saving are not affected.
as state variables in the lifecycle consumption model from section 2. This is not done here because of the computational burden of the additional state variables. Instead, the approach is to control for duration
dependence in estimation, but to set the duration variables to their sample mean (by year of potential experience) when parameterizing the employment and job-change equations. I also experimented with estimating equations (13), (14), and (16)
without controlling for duration dependence. In this case the potential-experience profiles of the transition probabilities do not match the data well, but the results for welfare and precautionary saving are not affected.
Wage Equation26
Log wages are assumed to follow the process
| (17) |
Hours Equation
Log hours are assumed to follow the process
| (18) |
That is, annual hours of work are allowed to depend on employment status at the survey date, the wage rate, disability, and health. The term
![]() is person-specific and time-invariant, and may be correlated with the unobserved permanent components in the previous equations. The error
is person-specific and time-invariant, and may be correlated with the unobserved permanent components in the previous equations. The error
![]() is
is ![]() .
.
Household Income Equation
Log household income is assumed to follow the process
Permanent Unobserved Heterogeneity
The permanent unobserved components in the above equations are assumed to follow the factor structure
where
4.3.2 Estimates of the Income Model
The employment, job mobility, wage rate, work hours, and household income equations presented above are estimated jointly by generalized indirect inference.30 Appendix 4 describes implementation of the estimation method used here.31 In order to estimate the effects of disability and
health in equations (13) - (19) I simulate ![]() and
and ![]() using the estimates of equations (11) and (12) presented above. Estimation in this section is thus conditional on the estimated parameters of the disability and health processes.
using the estimates of equations (11) and (12) presented above. Estimation in this section is thus conditional on the estimated parameters of the disability and health processes.
Estimation results for equations (13) - (19) are presented in Table 2C. I will not discuss the estimated parameters of all equations here. Instead, I will focus on the main features of the estimates of the wage and household income equations only. The next section will use simulations to provide an informal evaluation of the fit of all estimated equations and will thus illustrate some of the implications of the estimated parameters in the employment, job change, and hours equations.
Panel (d) in Table 2C presents estimates of the wage equation. The most important features of the estimates are the following. Persistence in the wage rate is high but well below unity (the autoregressive coefficient
![]() is 0.939). The standard deviation
is 0.939). The standard deviation
![]() of the wage shock
of the wage shock
![]() for job stayers is fairly large (0.097). When wage shocks
involve a new job (whether the job change involves going through a period of nonemployment or not) the standard deviation of the wage shock more than triples to 0.298 (
for job stayers is fairly large (0.097). When wage shocks
involve a new job (whether the job change involves going through a period of nonemployment or not) the standard deviation of the wage shock more than triples to 0.298 (
![]() ), and the dependence on the lagged wage falls to 0.794 (
), and the dependence on the lagged wage falls to 0.794 (
![]() ). New jobs are thus associated with substantial wage risk. Finally, nonemployment is negatively related to the persistent wage component through the coefficient
). New jobs are thus associated with substantial wage risk. Finally, nonemployment is negatively related to the persistent wage component through the coefficient
![]() .
.
Panel (f) presents the estimated parameters of the household income equation. The most important features of the estimates are the following. Wages and hours have a strong positive association with household income (coefficients
![]() and
and
![]() are 0.592 and 0.454, respectively). Conditional on the wage and hours, disability is positively related to household income (coefficient
are 0.592 and 0.454, respectively). Conditional on the wage and hours, disability is positively related to household income (coefficient
![]() is 0.186). This positive relationship is likely to reflect
transfers from disability insurance but could also reflect a positive labor supply response of a spouse or other family members to disability of the head. In either case, the positive coefficient suggests the presence of substantial insurance against disability shocks.
is 0.186). This positive relationship is likely to reflect
transfers from disability insurance but could also reflect a positive labor supply response of a spouse or other family members to disability of the head. In either case, the positive coefficient suggests the presence of substantial insurance against disability shocks.
Contrary to disability, health limitations do not have a positive association with household income conditional on the wage and hours (coefficient
![]() is -0.007). There is thus no evidence of insurance against
health limitations captured by
is -0.007). There is thus no evidence of insurance against
health limitations captured by ![]() . Unemployment does have have a positive relationship, but the coefficient is small (
. Unemployment does have have a positive relationship, but the coefficient is small (
![]() ).
).
The results further indicate that permanent unobserved heterogeneity in household income is important (
![]() ) and negatively correlated with unobserved heterogeneity in the employment, job mobility, wage rate, and hours equations (
) and negatively correlated with unobserved heterogeneity in the employment, job mobility, wage rate, and hours equations (
![]() ). One possible explanation is that households who do permanently better in the labor market may also receive permanently less transfers from public programs. Another
possible explanation is that permanently higher earnings of the head may permanently reduce the labor supply of a spouse if present. Finally, the serially correlated error in household income
). One possible explanation is that households who do permanently better in the labor market may also receive permanently less transfers from public programs. Another
possible explanation is that permanently higher earnings of the head may permanently reduce the labor supply of a spouse if present. Finally, the serially correlated error in household income ![]() (i.e., the residual household income component) has an autoregressive coefficient of
(i.e., the residual household income component) has an autoregressive coefficient of
![]() and a large standard deviation of
and a large standard deviation of
![]() .
.
4.4 Medical Expenditures
Out-of-pocket medical expenditures in old age are assumed to be given by32
Table 2D presents the estimated parameters. The age profile is not very pronounced: the polynomial in ![]() is initially increasing, then decreasing, and then increasing again. Health
limitations have a significant positive relationship with medical expenditures. If one sets the persistent shock
is initially increasing, then decreasing, and then increasing again. Health
limitations have a significant positive relationship with medical expenditures. If one sets the persistent shock
![]() to zero, for instance, expected medical expenditures at
to zero, for instance, expected medical expenditures at ![]() are
are
![]() for someone in good health and
for someone in good health and ![]() for someone in poor health.
Uncertainty in medical expenditures is large (
for someone in poor health.
Uncertainty in medical expenditures is large (
![]() ) and the shocks are fairly persistent (the autoregressive coefficient is
) and the shocks are fairly persistent (the autoregressive coefficient is
![]() ).36
).36
4.5 Evaluation of Fit
This section provides an informal evaluation of the fit of the processes estimated in the previous section by simulating data from the estimated processes, and then comparing sample statistics of the simulated data against sample statistics of the PSID data. I simulate data from the estimated equations for a large number of individuals and then randomly select a subsample of the simulated data in such a way that its demographic pattern matches that of the PSID sample.
Table 3A presents the sample mean of the disability and health limitations indicators for different levels of potential experience. The column under the "Overall" heading displays statistics for all levels of potential experience. The next columns report results for
the level of ![]() indicated in the top row. For each reported level of experience, the results combine data for periods
indicated in the top row. For each reported level of experience, the results combine data for periods ![]() ,
, ![]() , and
, and ![]() . For instance,
. For instance, ![]() uses data for
uses data for ![]() and 6. As the figures show, the simulated data match the PSID data fairly closely. The overall mean of
and 6. As the figures show, the simulated data match the PSID data fairly closely. The overall mean of ![]() is 0.02 in both the PSID and the simulated data. The probability that
is 0.02 in both the PSID and the simulated data. The probability that ![]() equals 1 increases steadily with experience. For health limitations, the overall mean is 0.13 in the PSID and
equals 1 increases steadily with experience. For health limitations, the overall mean is 0.13 in the PSID and ![]() in the simulations. The probability that
in the simulations. The probability that ![]() also increases steadily with experience.
For high levels of experience (
also increases steadily with experience.
For high levels of experience (![]() around 60), these probabilities are
around 60), these probabilities are ![]() in the PSID and 0.54 in the simulated data.
in the PSID and 0.54 in the simulated data.
Table 3B presents similar statistics for all variables used in the estimation of the joint household income process.37 I will not attempt to discuss all statistics here. The main points to notice in Table 3B are the following. (i) The overall fit of the simulated data is good. (ii) The main aspect that is missed by the simulations is a fairly strong and steady increase in the standard deviation of log hours with potential experience. This increase translates into a similar rise in the standard deviation of labor earnings of the head and, to a lesser extent, of household income. This feature of the PSID data appears to reflect the fact that exceptionally low levels of reported hours become more common with large values of potential experience. This, in turn, is likely to be the result of workers retiring gradually and significantly reducing their hours of work prior to full retirement.
Finally, Table 3C presents statistics for the estimated medical expenditures process. Overall, the fit seems fair given the somewhat erratic pattern observed in the data. The overall mean is 1.576 in the PSID and 1.342 in the simulated data. The overall standard deviation is 3.758 in the PSID and 3.519 in the simulations.
5 Solution to the Lifecycle Model
Once parameterized, the lifecycle model is solved by numerical dynamic programming. The model gives rise to three different forms of Bellman equations, corresponding to (i) the working years, (ii) the transition between work and retirement, and (iii) the retirement years, respectively. The Bellman equations are as follows:
Working years
where the expectation, given transition equations (1) - (6), is taken over shocks
Last working year
where the expectation, given transition equations (2), (7), and (10) is taken over shocks
Retirement years
where the expectation, given transition equations (2) and (8) - (10) is taken over
In solving the model, cash on hand ![]() and the persistent wage component
and the persistent wage component ![]() are treated as continuous state variables. Consumption
are treated as continuous state variables. Consumption ![]() is also continuous. State variables
is also continuous. State variables ![]() and
and ![]() are approximated by Markov chains, and
are approximated by Markov chains, and ![]() is also discretized. Since the dynamic programming problem has a finite horizon, the Bellman equations are solved by value function iteration. The largest computational costs of solving the Bellman equations in this model arise from computing the expectations of the
next-period value function. Expectations are computed as follows: For state variables
is also discretized. Since the dynamic programming problem has a finite horizon, the Bellman equations are solved by value function iteration. The largest computational costs of solving the Bellman equations in this model arise from computing the expectations of the
next-period value function. Expectations are computed as follows: For state variables ![]() ,
, ![]() , and
, and ![]() , I use estimated equations (11)-(15), and pseudo-random draws of
, I use estimated equations (11)-(15), and pseudo-random draws of
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() , to simulate the joint behavior of
, to simulate the joint behavior of ![]() ,
, ![]() , and
, and ![]() . From the simulation, I compute matrices of transition probabilities for a
vector
. From the simulation, I compute matrices of transition probabilities for a
vector ![]() ,
, ![]() ,
, ![]() and use these transition matrices to compute the expectations. For state
and use these transition matrices to compute the expectations. For state
![]() , I use the transition probabilities associated with the Markov chain approximation. Finally, I use Gauss-Hermite quadrature to compute expectations with respect to
, I use the transition probabilities associated with the Markov chain approximation. Finally, I use Gauss-Hermite quadrature to compute expectations with respect to
![]() ,
,
![]() , and
, and
![]() .
.
Treating cash on hand and the persistent wage component as continuous requires the use of an interpolation scheme to evaluate next-period's value function at arbitrary values of the continuous state variables. I use bicubic interpolation. This preserves differentiability of the right-hand side of the Bellman equation and allows solving each optimization problem using Newton-Raphson, which is convenient because of its fast (quadratic) convergence. All programs are written in Fortran 90 and parallelized using MPI (Message Passing Interface).
5.1 Optimal Consumption Behavior
This section discusses some of the properties of the solution to the lifecycle consumption model presented above. The data were treated, and the model was parameterized, so that income and consumption are in thousands of year-2000 dollars. The model corresponds to a household of mean size and composition, with mean years of education, whose head is white, and who is at the mean of the distribution of permanent unobserved heterogeneity components. All aggregate risk is abstracted from in the model.38
Figure 1 presents mean experience profiles for household nonasset income and consumption, both simulated from the baseline lifecycle model. The nonasset income profile has a humped shape, with a significant drop at the time of retirement. The drop at retirement is particularly pronounced because the current parameterization of nonasset retirement income in the model uses only social security benefits of the household head.39 The mean profile of (optimal) consumption is also hump-shaped, but smoother than income. Mean consumption in the figure never exceeds mean income. This is because of the presence of borrowing constraints along with the assumption in the simulations that households begin their career with zero initial assets.40
Figures 2 - 5 display optimal consumption rules and their dependence on the value of the various state variables in the model. Figure 2 exhibits optimal consumption as a function of cash on hand for an employed household in good health in period 1 (first year of career) who is at the mean of the
distribution of the persistent wage and household income components
![]() and
and ![]() . At low levels of cash on hand, households are
credit-constrained and consume their entire wealth. Above a certain threshold, households begin to save. This behavior is typical of consumption models with precautionary motives.41
. At low levels of cash on hand, households are
credit-constrained and consume their entire wealth. Above a certain threshold, households begin to save. This behavior is typical of consumption models with precautionary motives.41
Figure 3 illustrates the dependence of optimal consumption on the level of the residual component of household income ![]() in period 1 (first year of career) for an employed
individual in good health who is at the mean of the wage distribution. The figure displays consumption policy functions for values of
in period 1 (first year of career) for an employed
individual in good health who is at the mean of the wage distribution. The figure displays consumption policy functions for values of ![]() ranging from 2 standard deviations above to 2
standard deviations below the mean. The figure indicates that, conditional on having $20,000 in cash on hand in its first year of career, a household with component
ranging from 2 standard deviations above to 2
standard deviations below the mean. The figure indicates that, conditional on having $20,000 in cash on hand in its first year of career, a household with component ![]() two standard
deviations above the mean will spend about $3,000 more on consumption than a household with
two standard
deviations above the mean will spend about $3,000 more on consumption than a household with ![]() two standard deviations below the mean.
two standard deviations below the mean.
Figure 4 shows the dependence of consumption on the persistent wage component ![]() . The figure refers to a household who is employed, in good health, and at the mean of the household
income component
. The figure refers to a household who is employed, in good health, and at the mean of the household
income component ![]() in period 1. A higher current wage leads to a higher level of consumption for a given level of resources. The figure corresponds to values of
in period 1. A higher current wage leads to a higher level of consumption for a given level of resources. The figure corresponds to values of
![]() ranging from 2.8 standard deviations above to 2.8 standard deviations below the mean. Conditional on having $30,000 in total resources in its first year of career, a household
with component
ranging from 2.8 standard deviations above to 2.8 standard deviations below the mean. Conditional on having $30,000 in total resources in its first year of career, a household
with component ![]() 2.8 standard deviations above the mean will spend about $12,000 more on consumption than a household with
2.8 standard deviations above the mean will spend about $12,000 more on consumption than a household with ![]() 2.8 standard deviations below the mean. Figure 5 displays the optimal consumption rule over the entire range of possible realizations that
2.8 standard deviations below the mean. Figure 5 displays the optimal consumption rule over the entire range of possible realizations that ![]() may take in the simulations.42
may take in the simulations.42
The figures give a sense of the effects on optimal consumption of changes in a particular state variable, holding the rest constant. Changes in most state variables, such as a change in employment status, however, lead to same-period changes in other state variables. The next section uses simulations to analyze various implications of the lifecycle model, accounting for all interactions among the different variables.
6 Simulation Analysis
This section uses simulations to investigate the implications of the consumption and income models for the importance of the various sources of income risk for household welfare and precautionary saving. The analysis is based on numerically solving and then simulating the consumption model for a large number of households under a variety of scenarios. The scenarios differ in the number and type of shocks facing the households, who behave optimally under each scenario. In all simulations, households are assumed to begin their career with zero initial assets. The determination of initial conditions for the key simulated processes is discussed in more detail in Appendix 3.
6.1 Welfare Gains of Insuring Specific Sources of Risk
This subsection evaluates the welfare gains to the household from fully insuring against each specific source of income risk. We will consider two different insurance schemes. In the first, which will be called the unadjusted case, full insurance means the following: For any given shock, an insured household is compensated (by a lumpsum transfer) upon the realization of the shock in such a way that the realization of the shock has no effect on the realization of income. For instance, insuring unemployment risk means that in the event of unemployment the household receives a transfer that exactly offsets the income lost due to the unemployment shock. Thus, income after the insurance transfer is exactly the same as it would have been had the worker remained employed. As another example, fully insuring wage risk means that the insured household's income after the transfer will be the same, regardless of the actual realization of the wage shock, as it would have been had the realization of the wage shock been zero.
Insuring risk in this way has two effects. First, insurance reduces the variance (uncertainty) in income associated with a particular source of risk. Second, insurance may also affect the mean of income.43 This bring us to the second insurance scheme, which will be called the adjusted case. In this case, mean income in the insured scenario will be adjusted so that it equals mean income in the uninsured scenario for each year in the lifecycle. That is, the household is required to pay an actuarially fair premium for insurance, and as a result expected household income is the same under both the insured and uninsured scenarios. In this sense the insurance considered here is actuarially fair. Insurance is also full or complete in that it eliminates all uncertainty in income created by the presence of a particular source of risk. Most of the discussion that follows will focus on the adjusted case, although for completeness, I will also present results for the unadjusted case (where mean income in the insured scenario is allowed to be different from mean income in the uninsured scenario).
Two additional points about the insurance experiment and welfare analysis are worth stressing. First, the insurance considered here is in addition to already existing insurance mechanisms which are captured by the household nonasset income process estimated on PSID data.44 Second, in all cases, households in the model adjust their behavior optimally to the provision of the additional insurance.
The welfare gains of insurance are calculated in terms of the "equivalent compensating variation" in consumption. That is, the welfare calculations ask the following question: What percentage of current lifetime consumption would households be willing to pay in order to be fully insured against a particular source of risk? The metric used for welfare comparisons is expected lifetime utility at time zero. This is the expected lifetime utility right before an individual begins their career and before any uncertainty (other than the household's type) is resolved. This metric is given by:
![\displaystyle W=\mathit{E}_{0}[\sum_{t=1}^{T}\beta^{t-1}\pi_{t}u(c^{\ast}(\Omega_{t}% ))]=\int[\sum_{t=1}^{T}\beta^{t-1}\pi_{t}u(c^{\ast}(\Omega_{t}))]d\Phi,](img274.gif) |
(25) |
where
![]() is the state vector,
is the state vector,
![]() is the consumption policy function, which prescribes the optimal level of consumption at any given point in the state space (i.e., at any possible contingency that the
household may encounter), and
is the consumption policy function, which prescribes the optimal level of consumption at any given point in the state space (i.e., at any possible contingency that the
household may encounter), and ![]() denotes the joint distribution of the random state vector
denotes the joint distribution of the random state vector
![]() .45
.45
6.1.1 Results
Table 4 presents results for the welfare gains of insuring each source of risk for the baseline consumption model. Panel (a) presents adjusted results (the case of actuarially fair insurance), while panel (b) shows unadjusted results. The
entries in columns (1), (2), and (3) of panel (a) indicate that the welfare gains of fully insuring disability, health, and unemployment risk are extremely small. According to the table, households are willing to pay no more than 0.04 of ![]() of lifetime consumption in exchange for full insurance against these risks. The welfare value of insurance is small even if one does not
adjust for the effect of insurance on mean income. As panel (b) shows, the value of insuring disability and health risks in the unadjusted case is still no larger than 0.04 of
of lifetime consumption in exchange for full insurance against these risks. The welfare value of insurance is small even if one does not
adjust for the effect of insurance on mean income. As panel (b) shows, the value of insuring disability and health risks in the unadjusted case is still no larger than 0.04 of ![]() of lifetime consumption. The value of insuring unemployment in the unadjusted case is 0.62 of
of lifetime consumption. The value of insuring unemployment in the unadjusted case is 0.62 of ![]() of lifetime consumption.
of lifetime consumption.
Column (5) displays the results for wage shocks. These shocks are innovations in the hourly wage which are not related to changes in employment status or in employer. As the table shows, households in the baseline model would be willing to pay up to ![]() of their lifetime consumption in order to be insured against such shocks.
of their lifetime consumption in order to be insured against such shocks.
Columns (6), (7), and (8) present the gains of insuring shocks associated with job changes, hours of work, and the residual component of household income. The equivalent compensating variation in these cases is ![]() ,
, ![]() , and
, and ![]() , respectively.46 I don't discuss the results for medical expenditures here, as these are preliminary (see discussion in section 2).
, respectively.46 I don't discuss the results for medical expenditures here, as these are preliminary (see discussion in section 2).
6.1.2 Discussion
Overall, the results in Table 4 indicate that the value of insuring most sources of risk in the model is small. Particularly striking is how minuscule consumers' willingness to pay for insurance against disability, health, and unemployment risks turns out to be. It is also remarkable how much more valuable insurance against wage shocks is. These results, however, are consistent with Low, Meghir, and Pistaferri (2006), who study the welfare effects of unemployment and wage shocks, and find that wage risk is important, but that unemployment risk is not.
The shock to the residual component of household income turns out to play a very important role. This is perhaps not surprising, considering that this shock captures all variation in household income which is not explained by earnings, disability, health, or unemployment of the head, and that household income includes spousal labor income and all transfer income.47 An important part of this residual component is thus likely to capture factors that are not really risk, but rather reflect choice, such as spousal labor supply. The approach used here does not allow to determine what part of a given shock actually represents risk. It is interesting, nevertheless, that the shock to residual household income turns out to play the largest role of all shocks in the welfare analysis, which suggests that this component constitutes an important part of the shock estimated in simple univariate models of household income, where income is driven by a single shock to the income process.
Regarding the very small welfare value of insuring disability, health, and unemployment risk, it should be stressed again that all insurance considered here is insurance over and above existing insurance provided by government transfers (already included in the household income process), self-insurance provided by saving, and insurance within the family (also included in the household income process). The results from Table 4 thus seem to suggest that existing insurance mechanisms do a good job of protecting households against the sources of risk considered here. They also suggest that even a small deadweight loss created by additional insurance would be sufficient to wipe out much of the gains of such additional insurance.
One important caveat that should be emphasized is that the value of insurance is measured here from an ex-ante point of view, that is, before any uncertainty other than a household's type is realized. Measuring the value of insurance conditional on, for instance, being disabled or unemployed would yield higher benefits of additional insurance.
Still, the value of insuring some of these risks may seem surprisingly low in light of the estimation results, which would appear to imply that their effects are important. In the case of disability, for instance, the estimates presented in Table 2C suggest that becoming disabled has a very
strong negative effect on earnings (![]() enters the equation of log work hours with coefficient
enters the equation of log work hours with coefficient
![]() and the persistent wage equation with coefficient
and the persistent wage equation with coefficient
![]() ).48
).48
However, even if disability has a large effect on income when it occurs, it is still a low-probability event and hence, from an ex-ante point of view, it does not account for much of the variation in lifetime income and does not contribute greatly to income uncertainty. The same is true of unemployment. Health limitations, as measured here, are on the other hand more frequent, but their estimated effect on income is rather small. It should also be noted that the framework used here only considers the effects of disability and health on income and abstracts from direct effects on utility. Such effects are likely to be important for welfare.
One additional reason that helps explain the small value of insurance obtained and which should be mentioned here is that for the broad measure of household income taken from the PSID, income very rarely falls below ![]() (in year-2000 dollars). Consequently, income shocks in the lifecycle model are discretized in such a way that household income in the model can never fall below
(in year-2000 dollars). Consequently, income shocks in the lifecycle model are discretized in such a way that household income in the model can never fall below ![]() . This is important for welfare because under constant relative risk aversion (CRRA) utility the really painful events occur when consumption drops to extremely low levels. The presence of an income floor effectively provides a consumption floor, ruling out situations where
consumption is near zero. The view taken here is that the floor of
. This is important for welfare because under constant relative risk aversion (CRRA) utility the really painful events occur when consumption drops to extremely low levels. The presence of an income floor effectively provides a consumption floor, ruling out situations where
consumption is near zero. The view taken here is that the floor of ![]() per year used in the calculations is very conservative, given that people have access to a wide array of
transfers. Thus, a more precise way to interpret the results in this paper may be that, if one is willing to assume that constant relative risk aversion utility is a reasonable representation of preferences and that existing safety nets provide a minimum level of income and consumption as low as
per year used in the calculations is very conservative, given that people have access to a wide array of
transfers. Thus, a more precise way to interpret the results in this paper may be that, if one is willing to assume that constant relative risk aversion utility is a reasonable representation of preferences and that existing safety nets provide a minimum level of income and consumption as low as
![]() a year, then the value of insuring risk over and above already existing insurance is small.
a year, then the value of insuring risk over and above already existing insurance is small.
It may also be worth mentioning that ignoring some margins of choice in the model, such as labor supply, has an ambiguous impact on the value of insurance. In the simulated model, treating labor supply as fixed forces consumption to take on the full effects of the shocks, which thus turn out to be more painful than they would otherwise be. However, keeping labor supplied fixed in estimation of the income process also affects the estimates of risk. A given observed variation in income may reflect demand shocks that are partially absorbed and offset by an adjustment in labor supply, and this adjustment has a welfare cost. Thus, allowing for flexible labor supply in the estimation and in the simulation could make the results change either way.
Finally, Table 7A presents results obtained under alternative assumptions regarding the household's degree of risk aversion and patience. Panel (a) (second row) displays results for households with a coefficient of relative risk aversion of 5.0.49 As should be expected, the higher degree of risk aversion increases the value of insurance for all sources of risk. However, the increase in the coefficient of relative risk aversion to a value as high as 5.0 does not change any of the main results or conclusions drawn from the analysis above. In particular, the value of insuring disability, health, and unemployment risk remains minuscule, and the relative importance of the various sources of risk does not change. Panel (b) displays results for different values of the discount factor. The numbers in the table suggest that the importance of the residual component of household income increases as impatience increases, while the wage component appears to become less important. One possible reason for this is that the wage affects social security benefits, and thus may affect future periods more than the residual component of household income does. Most importantly, the results regarding disability, health, and unemployment do not change significantly. Overall, we conclude that the most important features of the results are robust to alternative, empirically plausible assumptions about household preferences.
6.2 Precautionary Saving
This section investigates the contribution of the various sources of uncertainty to the accumulation of precautionary savings. Figure 6 displays the mean level of assets held by simulated households, by year of potential experience. The upper curve represents mean asset holdings under the full-uncertainty scenario, while the lower curve displays mean asset holdings under no uncertainty. The mean profile of net income is identical under both scenarios. The difference between the two curves is mean precautionary wealth, that is, the mean level of assets held only because of the presence of uncertainty. Figure 7 displays this difference.50
Figure 8 displays mean precautionary wealth as a fraction of total wealth. The figure shows that precautionary savings make up the entirety of savings for the first 11-12 years of a worker's career. Workers start saving for lifecycle reasons (retirement) only after this point. Even 20 years into a worker's career, precautionary wealth continues to make up 50% or more of total savings. The exact point at which retirement saving begins to matter will depend on how substantial the drop in income at retirement is. The current version of the lifecycle model analyzed here does not account for defined benefit pensions or social security benefits received by family members other than the household head. As a result, income drops significantly at retirement and workers start saving for retirement relatively early in their career.
Table 5 decomposes precautionary wealth into components attributable to various sources of risk. Specifically, the table calculates the difference between mean precautionary wealth under full uncertainty and mean precautionary wealth under a scenario in which one particular source of risk is
fully insured, and then expresses this difference as a percentage of mean precautionary wealth. Contributions are normalized to sum to 100% of precautionary wealth51. The results in the table show that the largest contribution by far is made by shocks to the residual component of household income (![]() of precautionary
wealth). Wage shocks are also very important, contributing almost
of precautionary
wealth). Wage shocks are also very important, contributing almost ![]() of precautionary wealth. Together, these two sources thus account for about
of precautionary wealth. Together, these two sources thus account for about ![]() . The individual contribution of all other shocks is below
. The individual contribution of all other shocks is below ![]() . Among these, job-mobility shocks make the largest
contribution (
. Among these, job-mobility shocks make the largest
contribution (![]() ) and disability shocks the smallest (
) and disability shocks the smallest (![]() ).
).
Table 7B presents results from a similar decomposition under alternative assumptions about the coefficient of relative risk aversion and discount factor. As above, Panel (a) considers households with a coefficient of risk aversion of 5.0, while Panel (b) considers households with an increasing degree of impatience. As the numbers in the table show, the relative importance of the various sources of risk for the accumulation of precautionary saving does not appear to be sensitive to alternative assumptions about risk aversion and patience. More generally, the results for precautionary saving seem consistent with the welfare results from the previous section, and the general discussion presented in that section also applies here.
7 Conclusions and Research Agenda
This paper uses a lifecycle consumption model to quantify the effects of a number of sources of income risk on household welfare and precautionary saving. The model includes income shocks associated with disability, health, unemployment, job changes, wages, work hours, and a residual component of household income. I estimate the processes driving the evolution of these variables using PSID data, accounting for permanent unobserved heterogeneity -which is assumed to be known at the beginning of a worker's career- and a rich set of dynamic interactions among the variables. I then use the consumption model to quantify the welfare value of providing full, actuarially fair insurance against each source of risk and measure the contribution of each shock to the accumulation of precautionary savings.
The main findings are that: (i) the value of insuring disability, health, and unemployment shocks is extremely small (well below 1/10 of 1% of lifetime consumption in the baseline model); (ii) the gains from insuring shocks to the wage and to the residual component of household income are significantly larger (above 1% and 2% of lifetime consumption, respectively); and (iii) the latter two shocks account for more than 60% of precautionary wealth.
The insurance evaluated in this paper is insurance over and above existing insurance provided by government transfers, self-insurance through saving, and insurance within the family, all of which are already captured in the baseline model. The results thus seem to suggest that existing insurance mechanisms do a good job of protecting households against the sources of risk considered here. They also suggest that even a small deadweight loss created by additional insurance would be sufficient to wipe out much of the gains of such additional insurance.
It should be noted, however, that the value of insurance is measured from an ex-ante point of view, that is, before any uncertainty other than a household's type is realized. Measuring the value of insurance conditional on, for instance, being disabled or unemployed should yield higher benefits. Even more importantly, the model analyzed in this paper corresponds to households who are at the mean of the distribution of the permanent unobserved components. Although the framework developed here permits analyzing households over the entire distribution of these components, this is left for future research because of the computational costs of these calculations. It is important to bear in mind, however, that a clear understanding of the role of heterogeneity is required in order to draw definitive conclusions.
An interesting question that arises from the results presented here regards the value and relative role of different existing insurance mechanisms. For instance, to what extent are transfers from disability insurance and unemployment insurance responsible for the small welfare effects of disability and unemployment risk? This particular question may be addressed using this paper's framework in the following way: (i) remove payments received from disability insurance (alternatively, unemployment insurance) from the income data constructed from the PSID; (ii) estimate the household income equation presented in section 4 using the modified household income data; (iii) solve the lifecycle consumption model using the new estimated income process and perform a welfare analysis. An analysis of the role of these and other sources of insurance is left for future research.
One potentially important source of risk that is only partially addressed in this paper is the risk associated with catastrophic medical-expenditure shocks in old age. As discussed earlier, the treatment in this paper does not allow medical-expenditure shocks to wipe out a household's accumulated wealth. Some studies, including Palumbo (1999) and De Nardi, French, and Jones (2006), suggest that the risk of catastrophic medical expenditures may be important for saving behavior and welfare. A more flexible treatment of medical expenditures and their effects on accumulated wealth will be pursued in future work.
8 Appendix 1: Definition of PSID Variables
Potential Experience: Potential labor market experience is defined as
![]() 10)-5 where
10)-5 where ![]() is years of education. Labor market experience obtained with less than 10 years of education (which is unusual in the data and typically corresponds to very young individuals) is not counted as work experience.
is years of education. Labor market experience obtained with less than 10 years of education (which is unusual in the data and typically corresponds to very young individuals) is not counted as work experience.
Employment Status: The employment indicator ![]() is constructed from the reported employment status of the head of household at the survey date. The "employment
status" PSID variable has eight possible categories: (1) working now; (2) only temporarily laid off, sick leave or maternity leave; (3) looking for work, unemployed; (4) retired; (5) permanently disabled; temporarily disabled; (6) keeping house; (7) student; (8) other; "workfare"; in prison or
jail. Indicator
is constructed from the reported employment status of the head of household at the survey date. The "employment
status" PSID variable has eight possible categories: (1) working now; (2) only temporarily laid off, sick leave or maternity leave; (3) looking for work, unemployed; (4) retired; (5) permanently disabled; temporarily disabled; (6) keeping house; (7) student; (8) other; "workfare"; in prison or
jail. Indicator ![]() is set to 1 for categories (1) and (2); it is set to
0 otherwise.
is set to 1 for categories (1) and (2); it is set to
0 otherwise.
Disability: The disability indicator ![]() is also based on reported employment status at the survey date. Indicator
is also based on reported employment status at the survey date. Indicator ![]() is set to 1 whenever employment status is (5) and it is set to 0 otherwise.
is set to 1 whenever employment status is (5) and it is set to 0 otherwise.
Health Limitations: The health limitations indicator ![]() is constructed from the survey question: "Do you have any physical or nervous condition that limits the
type of work or the amount of work you can do?"Indictor
is constructed from the survey question: "Do you have any physical or nervous condition that limits the
type of work or the amount of work you can do?"Indictor ![]() is set to 1 when a
respondent answers "yes" to the above question, and it is set to 0 otherwise.
is set to 1 when a
respondent answers "yes" to the above question, and it is set to 0 otherwise.
Wage: For hourly workers, the wage variable used is the reported hourly wage at the survey date. For salaried workers, the variable is constructed from reported weekly, monthly, or yearly salary, divided by an appropriate standard number of hours. The measure used here further accounts for the fact that the PSID variable is capped at $9.98 per hour prior to 1978. This is done by replacing capped values for the years 1975-1977 with predicted values constructed by Altonji and Williams (2005). Predicted values are based on a regression of the log of the reported wage on a constant and the log of annual earnings divided by annual hours using the sample of individuals in 1978 for whom the reported wage exceeds $9.98.
Hours: The hours variable is the reported total annual hours of work (in all jobs).
Household income: Household income is defined as the sum of (i) total labor income of the head; (ii) total labor income of the wife; (iii) total transfer income of the head and wife; (iv) taxable income of others; and (v) total transfers of others. In most waves, the PSID does not separately report labor and asset income of other family unit members.
Out-of-Pocket Medical Expenditures: Total out-of-pocket medical expenditures are the sum of out-of-pocket payments for (i) nursing home and hospital bills; (ii) doctor, outpatient surgery, dental bills; and (iii) prescriptions, in-home medical care, special facilities, and other services. The payments refer to the two-year period prior to the survey year. Detailed medical expenditures data are provided by the PSID starting with the 1999 wave.
9 Appendix 2: Determination of Social Security Benefits
This appendix describes the determination of the level of social security benefits. Social security benefits in the model are determined in the last year of work according to the formula:
where ![]() stands for principal insurance amount and
stands for principal insurance amount and ![]() stands for average lifetime earnings. Households are assumed to receive a level of benefits equal to their
stands for average lifetime earnings. Households are assumed to receive a level of benefits equal to their ![]() .
. ![]() and
and ![]() are determined as follows.
are determined as follows.
Average Lifetime Earnings:
In the last working year, the state variables are used to predict average lifetime earnings according to a forecasting equation. The coefficients of the forecasting equation are determined by simulations of the income (earnings) model using the following procedure:
1. Use the model of disability, health, employment, job changes, wages and hours (which imply earnings) to simulate a large number of careers.
2. Use the simulated earnings data to compute average lifetime earnings for each simulated career as calculated by the Social Security Administration. In particular, yearly earnings are censored from above to the maximum yearly earnings subject to the social security tax. In 1996, for instance,
the maximum taxable yearly amount was $62,700. ![]() are then computed as the average of such censored earnings over the 35 years of highest earnings.
are then computed as the average of such censored earnings over the 35 years of highest earnings.
3. Regress ![]() against all (simulated) variables that would be known to the agent in the last year of career in the lifecycle model. These include all state
variables in the last working year (disability, health, employment, persistent wage, persistent household income) as well as all permanent heterogeneity components (which define the household type). This regression uses a flexible specification which includes a number of higher-order terms and
interactions among the different variables. Several alternatives specifications were tried and the regression with the best fit was selected as the forecasting equation. Estimation results for this forecasting regression are presented in Table 6. Notice in particular the high
against all (simulated) variables that would be known to the agent in the last year of career in the lifecycle model. These include all state
variables in the last working year (disability, health, employment, persistent wage, persistent household income) as well as all permanent heterogeneity components (which define the household type). This regression uses a flexible specification which includes a number of higher-order terms and
interactions among the different variables. Several alternatives specifications were tried and the regression with the best fit was selected as the forecasting equation. Estimation results for this forecasting regression are presented in Table 6. Notice in particular the high ![]() in the regression (0.88).
in the regression (0.88).
Principal Insurance Amount
Once average lifetime earnings ![]() have been determined, the principal insurance amount
have been determined, the principal insurance amount ![]() is determined by the rules of the Social Security Administration. I use "bend points" for the year 1996 (the last year of the sample used in estimation). The 1996 monthly "bend points", in current dollars, are
is determined by the rules of the Social Security Administration. I use "bend points" for the year 1996 (the last year of the sample used in estimation). The 1996 monthly "bend points", in current dollars, are ![]() and
and ![]() . The corresponding yearly bend points in thousands of year-2000 dollars are
. The corresponding yearly bend points in thousands of year-2000 dollars are
![]() and
and
![]() . The
. The ![]() , in thousands of year-2000 dollars, is then calculated as
, in thousands of year-2000 dollars, is then calculated as
10 Appendix 3: Further Details of Model Specification and Estimation - Employment, Job Changes, Wage, Hours, and Household Income
This appendix provides some additional details about the joint model of employment, job changes, wage rate, work hours, and household income, its estimation, and its relation to the income process in the lifecycle model.
First Stage Regression and Household Income in Levels
Recall that log household income is given by
Initial Conditions
Initial conditions in employment, job changes, the wage, hours, and household income are explicitly modeled and estimated. For a discussion of related models and further details about estimation, see Altonji, Smith, and Vidangos (2008).
Employment: Initial employment status is assumed to be determined by
![]() where
where
![]() ,
,
![]() ,
,
![]() and
and
![]() are defined as before,
are defined as before,
![]() , and
, and
![]() is the coefficient estimate from a Probit of
is the coefficient estimate from a Probit of ![]() on a
constant estimated on PSID data for
on a
constant estimated on PSID data for![]() . I use the first three years here rather than just the first year because there are relatively few observations when
. I use the first three years here rather than just the first year because there are relatively few observations when ![]() .
.
Wages: The initial condition of the persistent wage component is modeled as
![]() where
where
![]() is a free parameter estimated with GII and
is a free parameter estimated with GII and
![]() where
where
![]() is set such that
is set such that
![]() equals the variance of the residual of regression for low levels of
equals the variance of the residual of regression for low levels of ![]() .
.
Household Income: The initial condition of the residual component of household income is determined as
![]() where
where
![]() is a free parameter estimated with GII and
is a free parameter estimated with GII and
![]() where
where
![]() is set such that
is set such that
![]() equals the variance of the residual of regression for low levels of
equals the variance of the residual of regression for low levels of ![]() .
.
Measurement Error
Estimation accounts for measurement error in wages, hours, earnings, and household income. The treatment of measurement error here follows the treatment in Altonji, Smith, and Vidangos (2008). For household income, measurement error is set to account for 25% of the variance of the first difference in observed household income, after accounting for the effect of measurement error in earnings. Since earnings are a component of household income, one additionally needs to account for the effect of measurement error in earnings on observed household income. Altonji, Smith, and Vidangos (2008) shows that there is a residual component in earnings which is not accounted for by wages and hours. This component is assumed here to consist entirely of measurement error. The system estimated by generalized indirect inference includes an auxiliary equation of earnings in order to identify this component. Estimates of the household income process account for the effect of this measurement error component.
11 Appendix 4: Estimation Mechanics - GII
The equations that determine the evolution of employment, job changes, wage, hours, and household income are estimated by generalized indirect inference (GII). The implementation of GII used here is akin to that used in Altonji, Smith, and Vidangos (2008), which provides a detailed discussion. This appendix gives some further details of the implementation used in this paper. The auxiliary model consists of a system of seemingly unrelated regressions (SUR) with 8 equations and 27 covariates that are common to all 8 equations. The model is implemented under the assumption that the errors follow a multivariate normal distribution with unrestricted covariance matrix. The auxiliary model effectively used52 may be written as
| (26) |
where
| (27) | ||
and
| (28) | |
Above, ![]() is an indicator of unemployment defined as
is an indicator of unemployment defined as
![]() . All other variables are defined as before.
. All other variables are defined as before.
| All t | 1 |
11 |
21 |
31 |
41 |
51 |
61 |
|
|---|---|---|---|---|---|---|---|---|
| Disability: Obs. | 76,075 | 15,950 | 28,908 | 17,234 | 9,833 | 4,150 | ||
| Disability: Mean | 0.020 | 0.002 | 0.009 | 0.025 | 0.045 | 0.095 | ||
| Health: Obs. | 88,928 | 17,376 | 30,009 | 18,067 | 11,039 | 8,230 | 3,736 | 471 |
| Health: Mean | 0.137 | 0.053 | 0.083 | 0.128 | 0.190 | 0.316 | 0.418 | 0.495 |
| Variable | Obs. | Mean | StDev | Min | Max |
|---|---|---|---|---|---|
| E |
41,840 | 0.94 | 0.24 | 0 | 1 |
| J |
41,840 | 0.09 | 0.28 | 0 | 1 |
| wage |
39,337 | 16.80 | 9.07 | 3.50 | 145.20 |
| hours |
41,840 | 2101 | 646 | 0 | 4000 |
| earnings |
41,840 | 38.84 | 25.43 | 0 | 785.83 |
| income |
41,840 | 56.77 | 33.11 | 0 | 809.75 |
| income |
41,840 | 48.77 | 24.20 | 0.65 | 618.53 |
| Obs. | Mean | St. Dev. | Min | Max |
|---|---|---|---|---|
| 2,831 | 3.25 | 10.76 | 0.00 | 317.47 |
| Percentiles: 1% | Percentiles: 5% | Percentiles: 10% | Percentiles: 25% | Percentiles: 50% | Percentiles: 75% | Percentiles: 90% | Percentiles: 95% | Percentiles: 99% |
|---|---|---|---|---|---|---|---|---|
| 0.00 | 0.00 | 0.00 | 0.25 | 1.10 | 2.92 | 6.47 | 10.21 | 38.63 |
| Variable | cons | t+1 | (t+1)2/100 | D |
H |
|
|---|---|---|---|---|---|---|
| Parameter | ||||||
| Estimate | -3.6580 | 0.0377 | -0.0195 | 2.2043 | 0.9579 | 0.4748 |
| SE | (0.1197) | (0.0081) | (0.0146) | (0.0719) | (0.0423) | (0.0497) |
| Obs. | 76,075 |
| Variable | cons | t+1 | (t+1)2/100 | H |
|
|---|---|---|---|---|---|
| Parameter | |||||
| Estimate | -2.6763 | 0.0267 | 0.0203 | 1.1244 | 0.9657 |
| SE | (0.0449) | (0.0029) | (0.0048) | (0.0203) | (0.0198) |
| Obs. | 88,928 |
| Variable | cons | t | t2/100 | H |
ED |
||
|---|---|---|---|---|---|---|---|
| Parameter | |||||||
| Estimate | 2.3858 | 0.0327 | -0.0482 | -0.0622 | -0.0337 | 0.8720 | -0.6124 |
| SE | (0.0682) | (0.0089) | (0.0206) | (0.0045) | (0.0595) | (0.0568) | (0.0514) |
| Variable | cons | t | t2/100 | H |
UD |
||
|---|---|---|---|---|---|---|---|
| Parameter | |||||||
| Estimate | 0.9398 | 0.0090 | -0.0480 | -0.0456 | -0.0556 | 0.7598 | 0.4925 |
| SE | (0.0737) | (0.0011) | (0.0350) | (0.0263) | (0.0448) | (0.1138) | (0.1014) |
| Variable | cons | t | t2/100 | JD |
||
|---|---|---|---|---|---|---|
| Parameter | ||||||
| Estimate | -0.6054 | -0.0111 | -0.0374 | -0.1034 | -0.3882 | 0.2828 |
| SE | (0.0553) | (0.0051) | (0.0166) | (0.0120) | (0.0433) | (0.0310) |
| Variable | H |
p |
J |
1-E |
|
|||
|---|---|---|---|---|---|---|---|---|
| Parameter | ||||||||
| Estimate | -0.0015 | 0.9389 | -0.1538 | 0.0197 | -0.1400 | 0.0160 | 0.0975 | 2.0535 |
| SE | (0.0421) | (0.0029) | (0.0093) | (0.0045) | (0.0089) | (0.0019) | (0.0020) | (0.2766) |
| Variable | cons | E |
w |
D |
H |
|
||
|---|---|---|---|---|---|---|---|---|
| Parameter | ||||||||
| Estimate | -0.5258 | 0.5921 | -0.1948 | -0.8957 | -0.1085 | 0.2436 | 0.1284 | 0.2269 |
| SE | (0.0089) | (0.0080) | (0.0160) | (0.0192) | (0.0065) | (0.0093) | (0.0114) | (0.0014) |
| Variable | cons | w |
h |
D |
H |
U |
p |
|
||
|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | ||||||||||
| Estimate | 0.1447 | 0.5919 | 0.4535 | 0.1862 | -0.0068 | 0.0269 | 0.2478 | 0.4486 | 0.1677 | -0.1478 |
| SE | (0.0046) | (0.0096) | (0.0113) | (0.0327) | (0.0024) | (0.0085) | (0.0877) | (0.0965) | (0.0088) | (0.0134) |
| Variable | cons | t+1 | (t+1)2 | (t+1)3 | H |
Family Size | year 2001 | year 2003 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Parameter | ||||||||||
| Estimate | -19.9013 | 1.1011 | -0.0209 | 0.0001 | 0.4394 | -0.1266 | 0.1391 | 0.2520 | 0.7455 | 0.9356 |
| SE | (7.5830) | (0.3903) | (0.0066) | (0.0000) | (0.0612) | (0.0367) | (0.0712) | (0.0715) | ||
| Obs. | 2,426 | |||||||||
| Adj R-squared | 0.09 |
| Sample Statistic | Overall | t=5 | t=10 | t=20 | t=30 | t=40 | t=50 | t=60 |
|---|---|---|---|---|---|---|---|---|
| Mean Disability PSID | 0.02 | 0.001 | 0.004 | 0.016 | 0.030 | 0.075 | ||
| Mean Disability Simulated | 0.02 | 0.002 | 0.004 | 0.014 | 0.034 | 0.090 | ||
| Mean Health Limitations PSID | 0.13 | 0.05 | 0.06 | 0.11 | 0.14 | 0.24 | 0.37 | 0.50 |
| Mean Health Limitations Simulated | 0.14 | 0.05 | 0.06 | 0.10 | 0.17 | 0.27 | 0.40 | 0.54 |
| Sample Statistic | Overall | t=5 | t=10 | t=20 | t=30 | t=40 |
|---|---|---|---|---|---|---|
| Mean Employment PSID | 0.93 | 0.94 | 0.94 | 0.94 | 0.94 | 0.88 |
| Mean Employment Simulated | 0.93 | 0.93 | 0.94 | 0.93 | 0.92 | 0.86 |
| Mean Emp. To Emp. Transition PSID | 0.97 | 0.98 | 0.97 | 0.97 | 0.98 | 0.96 |
| Mean Emp. To Emp. Transition Simulated | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.93 |
| Mean Unemp. To Emp. Transition PSID | 0.55 | 0.56 | 0.59 | 0.55 | 0.46 | 0.42 |
| Mean Unemp. To Emp. Transition Simulated | 0.53 | 0.57 | 0.58 | 0.57 | 0.47 | 0.37 |
| Mean Job Change if Employed PSID | 0.08 | 0.21 | 0.15 | 0.07 | 0.05 | 0.04 |
| Mean Job Change if Employed Simulated | 0.10 | 0.18 | 0.15 | 0.09 | 0.05 | 0.02 |
| Mean Employment Duration PSID | 11.87 | 4.21 | 6.61 | 12.49 | 17.34 | 21.22 |
| Mean Employment Duration Simulated | 14.49 | 5.05 | 8.78 | 15.57 | 20.85 | 22.55 |
| Mean Unemployment Duration PSID | 1.88 | 1.65 | 1.82 | 2.11 | 1.75 | 1.70 |
| Mean Unemployment Duration Simulated | 1.35 | 1.68 | 1.73 | 1.42 | 1.07 | 0.68 |
| Mean Job Duration PSID | 9.60 | 3.00 | 4.78 | 9.88 | 14.98 | 19.26 |
| Mean Job Duration Simulated | 9.35 | 2.44 | 4.53 | 9.73 | 15.18 | 18.14 |
| St. Dev. Log Wage PSID | 0.39 | 0.35 | 0.37 | 0.40 | 0.40 | 0.41 |
| St. Dev. Log Wage Simulated | 0.41 | 0.39 | 0.40 | 0.41 | 0.41 | 0.42 |
| St. Dev. Log Hours PSID | 0.49 | 0.35 | 0.42 | 0.49 | 0.55 | 0.75 |
| St. Dev. Log Hours Simulated | 0.45 | 0.43 | 0.43 | 0.44 | 0.48 | 0.57 |
| St. Dev. Log Earnings PSID | 0.78 | 0.55 | 0.68 | 0.79 | 0.85 | 1.09 |
| St. Dev. Log Earnings Simulated | 0.70 | 0.63 | 0.66 | 0.70 | 0.75 | 0.82 |
| St. Dev. Log Household Nonasset PSID | 0.49 | 0.45 | 0.47 | 0.50 | 0.51 | 0.56 |
| Income Simulated | 0.48 | 0.45 | 0.47 | 0.49 | 0.49 | 0.50 |
| Sample Statistic | Overall | 44 |
49 |
54 |
59 |
64 |
|---|---|---|---|---|---|---|
| Mean PSID | 1.576 | 1.446 | 1.290 | 1.651 | 1.904 | 1.886 |
| Mean Simulated | 1.342 | 1.397 | 1.352 | 1.266 | 1.260 | 1.436 |
| Standard Deviation PSID | 3.758 | 2.260 | 1.781 | 4.266 | 5.847 | 4.494 |
| Standard Deviation Simulated | 3.519 | 3.540 | 3.916 | 3.117 | 3.363 | 3.606 |
| Insured Source of Risk | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res. Income |
|---|---|---|---|---|---|---|---|---|
| Equivalent Variation (% of Lifetime Consumption) | 0.02% | 0.00% | 0.04% | 0.01% | 1.20% | 0.72% | 0.45% | 2.19% |
| Insured Source of Risk | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res. Income |
|---|---|---|---|---|---|---|---|---|
| Equivalent Variation (% of Lifetime Consumption) | 0.04% | 0.01% | 0.62% | 0.24% | 0.62% | -0.35% | -0.13% | 0.28% |
| Source of Risk | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res. Income |
|---|---|---|---|---|---|---|---|---|
| Contribution | 2.34% | 8.56% | 3.77% | 5.57% | 19.13% | 9.34% | 8.15% | 43.14% |
| Variable | cons | ( |
( |
( |
p |
(p |
(p |
D |
H |
E |
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | 3.358 | -0.003 | -0.016 | -0.006 | -0.015 | -0.007 | 0.357 | -0.038 | 0.005 | 0.149 | -0.007 | 0.240 | 0.008 | -0.018 | -0.108 | 0.000 | -0.040 | -0.011 |
| SE | (0.004) | (0.001) | (0.001) | (0.000) | (0.001) | (0.001) | (0.002) | (0.001) | (0.000) | (0.001) | (0.001) | (0.004) | (0.005) | (0.004) | (0.005) | (0.003) | (0.004) | (0.004) |
| Obs. | 48,030 | |||||||||||||||||
| Root MSE | 0.184 | |||||||||||||||||
| Adj R-squared | 0.88 |
| Source of Risk: | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res.Income |
|---|---|---|---|---|---|---|---|---|
| 0.02% | 0.00% | 0.04% | 0.01% | 1.20% | 0.72% | 0.45% | 2.19% | |
| 0.03% | 0.01% | 0.07% | 0.02% | 1.95% | 1.17% | 0.72% | 4.79% |
| Source of Risk: | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res.Income |
|---|---|---|---|---|---|---|---|---|
| 0.02% | 0.00% | 0.04% | 0.01% | 1.20% | 0.72% | 0.45% | 2.19% | |
| 0.01% | 0.00% | 0.05% | 0.02% | 0.97% | 0.75% | 0.44% | 3.15% | |
| 0.01% | 0.00% | 0.05% | 0.02% | 0.73% | 0.77% | 0.42% | 4.19% |
| Source of Risk: | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res.Income |
|---|---|---|---|---|---|---|---|---|
| 2.34% | 8.56% | 3.77% | 5.57% | 19.13% | 9.34% | 8.15% | 43.14% | |
| 2.26% | 8.14% | 3.21% | 5.11% | 19.71% | 9.37% | 8.16% | 44.04% |
The table presents the contribution of individual sources of risk to the accumulation of precautionary wealth (see Table 4.5A) for different values of the coefficient of risk aversion
| Source of Risk: | Disability | Health | Unemp. | MedCosts | Wage | Job Change | Hours | Res.Income |
|---|---|---|---|---|---|---|---|---|
| 2.34% | 8.56% | 3.77% | 5.57% | 19.13% | 9.34% | 8.15% | 43.14% | |
| 2.14% | 10.44% | 2.93% | 8.77% | 16.82% | 6.91% | 8.03% | 43.96% | |
| 2.03% | 10.79% | 2.80% | 8.81% | 15.62% | 7.61% | 7.86% | 44.48% |
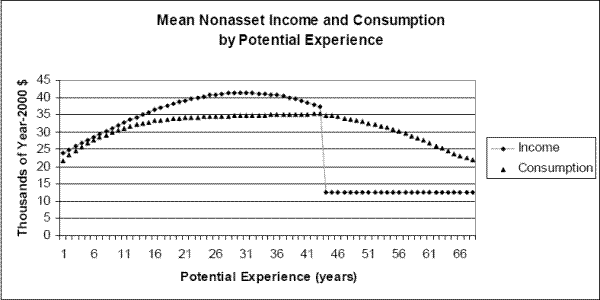
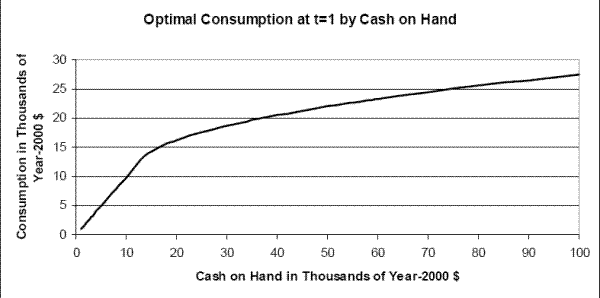
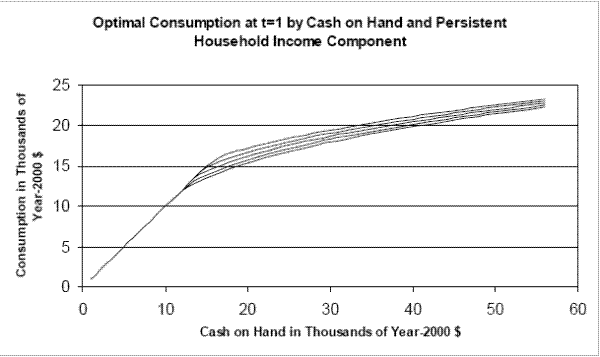
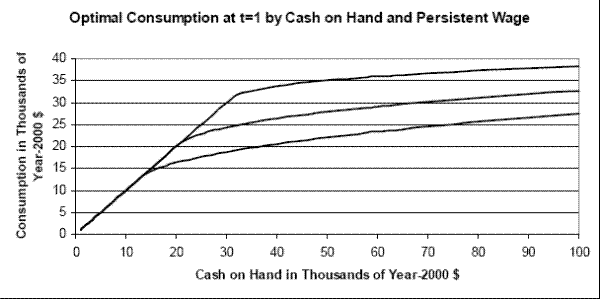
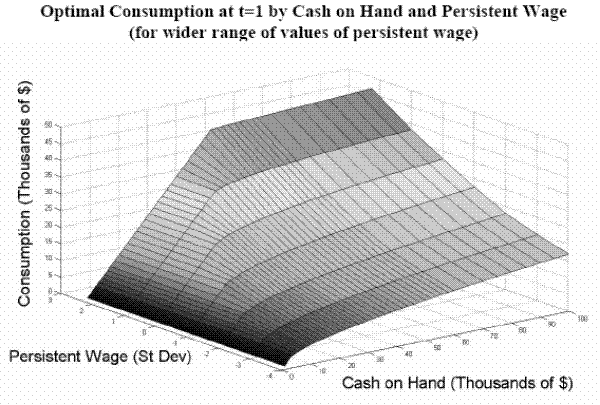
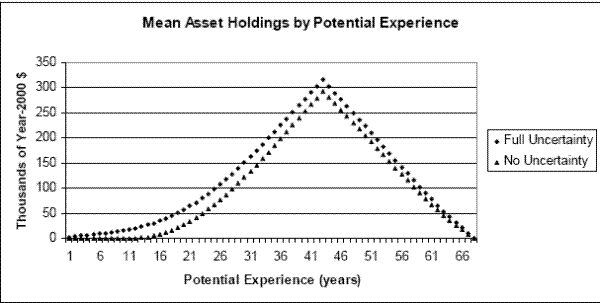
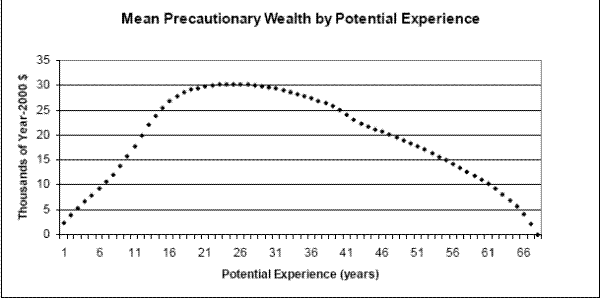
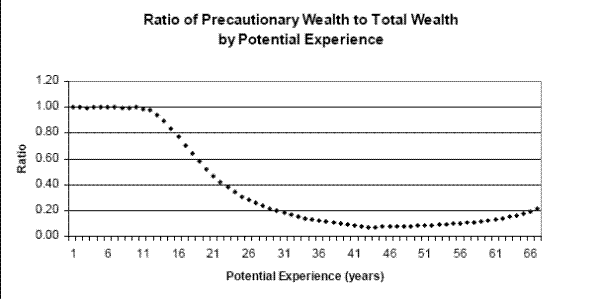
Footnotes
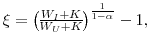 where
where