
Are Spectral Estimators Useful for Implementing Long-Run Restrictions in SVARs?
Keywords: Structural VAR, long-run identification, non-parametric estimation, spectral factorization
Abstract:
In addition, when combining VAR coefficients with non-parametric estimates of the spectral density, care needs to be taken to consistently account for information embedded in the non-parametric estimates about serial correlation in VAR residuals. This paper uses a spectral factorization to ensure a correct representation of the data's variance. But this cannot overcome the fundamental problems of estimating the long-run dynamics of macroeconomic data in samples of typical length.
JEL Classification: C32, C51, E17, E32
1 Introduction
VARs have been criticized for failures in estimating the responses to long-run shocks. A crucial element for long run identification is the spectral density at zero-frequency, also known as "long-run variance". But OLS estimates of VAR coefficients are concerned with minimizing forecast error variance, not estimating the long run variance. This has motivated Christiano, Eichenbaum, and Vigfusson (2006a; 2006b), henceforth "CEV", to propose a new way of estimating structural VARs using a combination of OLS and a non-parametric estimator. They argue that their estimator virtually eliminates the bias associated with the standard OLS estimator.
This paper shows that non-parametric estimates of the spectral density, henceforth called "spectral estimators", are no panacea for the implementation of long-run restrictions in finite sample. Macroeconomic time series display a fair amount of persistence, posing two serious challenges for long-run identification. First, an accurate representation of the true model typically requires a VAR with a high lag order, much higher than what is affordable in a sample of typical length and resulting in a sizable truncation bias (Chari, Kehoe, and McGrattan 2008, henceforth "CKM"). Second, there is the small sample bias in estimated coefficients known from Hurwicz (1950), which becomes ever more severe the smaller the sample, and the more persistent the data. As will be shown, both issues affect not only VARs in the time domain, but also spectral estimators in the frequency domain.
The conventional VAR technique as well as different combinations with spectral estimators are evaluated in the context of a simple two-shock RBC model, which has also been used by CEV and CKM. When using the various procedures to estimate the response of hours to technology, or to decompose the variance of fluctuations in output or hours, none of the procedures clearly dominates the others.
Furthermore, CEV do not consider some conceptual pitfalls in combining VAR coefficients with spectral estimates. Non-parametric estimates of the spectral density allow for non-![]() residuals
in the finite-order VAR, which is good since the underlying model is likely of infinite order. In what may be called "mixing and matching", the CEV approach plugs these estimates into the standard VAR formula alongside with coefficients from the finite-order VAR. This approach uses the extra
information about omitted lags in the VAR to compute the long-run responses of variables to shocks--but not when mapping these back into impact responses. To retain a consistent representation of the data, that would however be necessary. Otherwise, the total variance of the data is misrepresented.
In the simulations reported here, this misrepresentation is quantitatively relevant. As a related issue, when the relationship between forecast errors and structural shocks is inverted with the CEV coefficients, one obtains a time series which is identical to the shock estimates from OLS up to a
scale factor. All in all, this is of concern for any researcher wanting to adopt the CEV strategy.
residuals
in the finite-order VAR, which is good since the underlying model is likely of infinite order. In what may be called "mixing and matching", the CEV approach plugs these estimates into the standard VAR formula alongside with coefficients from the finite-order VAR. This approach uses the extra
information about omitted lags in the VAR to compute the long-run responses of variables to shocks--but not when mapping these back into impact responses. To retain a consistent representation of the data, that would however be necessary. Otherwise, the total variance of the data is misrepresented.
In the simulations reported here, this misrepresentation is quantitatively relevant. As a related issue, when the relationship between forecast errors and structural shocks is inverted with the CEV coefficients, one obtains a time series which is identical to the shock estimates from OLS up to a
scale factor. All in all, this is of concern for any researcher wanting to adopt the CEV strategy.
The CEV framework is amended here by recognizing that the non-parametric estimate contains information about omitted lags in the VAR. This misspecification has been stressed by CKM, Erceg, Guerrieri, and Gust (2005), Ravenna (2007) and Cooley and Dywer (1998). The adjusted procedure retains the OLS estimates and fills up the omitted lags with a spectral factorization of the spectral density's non-parametric estimate. By construction, this adjusted SVAR--in fact an SVARMA--matches the sample variance of the data just as OLS does. Overall, this corrected procedure suffers from the same basic problems as the other long-run identification methods: truncation and small sample bias.
The remainder of this paper is structured as follows: Section 2 describes the model economy against which the various estimation routines will be evaluated. Section 3 describes the various SVAR methods, including a new spectral factorization procedure. Section 4 presents the Monte Carlo results and Section 5 concludes the paper.
2 A Model Economy
This section describes a simple model economy, which will be used to illustrate and quantify the issues associated with various long-run identification schemes. None of the conceptual concerns related to spectral estimates raised in Section 3 will be specific to this model. The model is identical to the two-shock economy used by CKM and CEV.
The model is a common one-sector RBC economy driven by two shocks: First, a unit root shock to technology, ![]() . This is the permanent shock to be estimated by the VAR. Second, a transitory
non-technology shock,
. This is the permanent shock to be estimated by the VAR. Second, a transitory
non-technology shock, ![]() , which drives a wedge between private household's labor-consumption decision.
, which drives a wedge between private household's labor-consumption decision.
The representative household maximizes his lifetime utility over (per-capita) consumption, ![]() , and labor services,
, and labor services, ![]()
and faces the budget constraint
The non-technology shock ![]() is an exogenous labor tax. As discussed by CKM, it need not be literally interpreted as a tax levy, but stands in for the effects of a variety of
non-technology shocks introduced into second-generation RBC models. Mechanically, it distorts the first-order condition for consumption and labor. It works similar to a stochastic preference shock to the Frisch elasticity of labor supply. Chari, Kehoe, and McGrattan (2007) show how this labor "wedge" can be understood more generally as the reduced form process for more elaborate distortions, such as sticky wages.
is an exogenous labor tax. As discussed by CKM, it need not be literally interpreted as a tax levy, but stands in for the effects of a variety of
non-technology shocks introduced into second-generation RBC models. Mechanically, it distorts the first-order condition for consumption and labor. It works similar to a stochastic preference shock to the Frisch elasticity of labor supply. Chari, Kehoe, and McGrattan (2007) show how this labor "wedge" can be understood more generally as the reduced form process for more elaborate distortions, such as sticky wages.
The production function ![]() is constant returns to scale, where
is constant returns to scale, where ![]() is
labor-augmenting technological progress. Firms are static and maximize profits
is
labor-augmenting technological progress. Firms are static and maximize profits
![]() . Per-capita output equals production,
. Per-capita output equals production,
![]() , and the economy's resource constraint is
, and the economy's resource constraint is
![]() . The exogenous drivers follow linear stochastic processes:
. The exogenous drivers follow linear stochastic processes:
![]()
where
![]() and
and
![]() are
are ![]() standard-normal random variables. They are the technology
shock, respectively labor shock.
standard-normal random variables. They are the technology
shock, respectively labor shock. ![]() measures the persistence of the transitory labor tax. The scale factors
measures the persistence of the transitory labor tax. The scale factors ![]() and
and ![]() determine their relative importance in the model. (
determine their relative importance in the model. (![]() is the drift in log-technology and
is the drift in log-technology and ![]() is the average tax rate.)
is the average tax rate.)
The calibration is identical to the baseline model of CEV, which uses parameter values familiar from the business cycle literature. Utility is specified as
![]() (consistent with balanced growth) and the production function is Cobb-Douglas
(consistent with balanced growth) and the production function is Cobb-Douglas
![]() with a capital share of
with a capital share of ![]() . The labor
preference parameter is set to
. The labor
preference parameter is set to ![]() . On an annualized basis, the calibration sets the depreciation rate to 6%, the rate of time preferences to 2% and population growth to 1%.1 Following CEV, the transitory shock is calibrated as an AR(1) with persistence
. On an annualized basis, the calibration sets the depreciation rate to 6%, the rate of time preferences to 2% and population growth to 1%.1 Following CEV, the transitory shock is calibrated as an AR(1) with persistence ![]() . This calibration is identical to the values used by CKM except for their values of
. This calibration is identical to the values used by CKM except for their values of ![]() and
and ![]() .
.
The model economy is calibrated over different ratios in the variance of transitory to permanent shocks,
![]() , which translate into different assumptions about the share of output fluctuations explained by technology shocks.2 As a benchmark, maximum-likelihood estimates of CEV obtained from fitting the model to U.S. post-war data imply that around two-thirds of the bandpass-filtered variance in output can be attributed to
technology shocks.3 The bandpass filter employed throughout this paper considers only fluctuations with durations between two-and-a-half and eight years, which
is consistent with the NBER definitions of Burns and Mitchell (1946).
, which translate into different assumptions about the share of output fluctuations explained by technology shocks.2 As a benchmark, maximum-likelihood estimates of CEV obtained from fitting the model to U.S. post-war data imply that around two-thirds of the bandpass-filtered variance in output can be attributed to
technology shocks.3 The bandpass filter employed throughout this paper considers only fluctuations with durations between two-and-a-half and eight years, which
is consistent with the NBER definitions of Burns and Mitchell (1946).
Data is simulated for samples of length ![]() , corresponding to 45 years of quarterly data; identical to the simulations of CKM and CEV. Following CEV and CKM, bivariate VARs are estimated
using simulated data of the (log) growth rate of labor productivity and hours worked;
, corresponding to 45 years of quarterly data; identical to the simulations of CKM and CEV. Following CEV and CKM, bivariate VARs are estimated
using simulated data of the (log) growth rate of labor productivity and hours worked;
![]() .4 For each simulated sample, the lag length of the VAR(
.4 For each simulated sample, the lag length of the VAR(![]() ) is chosen by minimizing the Schwartz Information Criterion (SIC),
typically picking small values close to one.5 When computing population moments, a VAR(1) is used. For each calibration, 1,000samples are simulated.
) is chosen by minimizing the Schwartz Information Criterion (SIC),
typically picking small values close to one.5 When computing population moments, a VAR(1) is used. For each calibration, 1,000samples are simulated.
When looking at data simulated from this model, two statistics are of particular interest for this paper: How do hours worked respond to a technology shock? What is the share of fluctuations due to technology shocks? These questions are typically asked by empirical researchers trying to evaluate predictions from business cycle models with SVARs, such as Gali (1999) or Christiano, Eichenbaum, and Vigfusson (2004).
3 Long-Run Identification in VARs
The linearized solution to the model described in the previous section is only one example from a wider class of linear dynamic models to which the SVAR methods discussed here can be applied. None of the issues discussed in this section will be specific to the model described above. An economic
model from this class is supposed to specify a VAR representation for a stationary vector of observable variables6 ![]() :
:
![]()
where ![]() is a polynomial in the lag-operator
is a polynomial in the lag-operator ![]() ,
,
![]() whose roots lie all outside the unit circle and the innovations are
whose roots lie all outside the unit circle and the innovations are ![]() ,
,
![]() .
.
In principle, the model prescribes an infinite order VAR. When ![]() for
for ![]() this nests the case of a finite order VAR. But as noted by Cooley and Dywer (1998), many interesting models have only infinite order VAR representations. In the remainder of this paper the true VAR representation is always assumed to be of infinite
order. The linearized solution to the model described in Section 2 has such an infinite order VAR representation; details are shown in Appendix B.
this nests the case of a finite order VAR. But as noted by Cooley and Dywer (1998), many interesting models have only infinite order VAR representations. In the remainder of this paper the true VAR representation is always assumed to be of infinite
order. The linearized solution to the model described in Section 2 has such an infinite order VAR representation; details are shown in Appendix B.
For the identification of structural shocks, there has to be an invertible one-to-one mapping from innovations ![]() to the structural shocks
to the structural shocks ![]() driving the underlying model--such as technology, monetary policy errors, exogenous government spending etc.:
driving the underlying model--such as technology, monetary policy errors, exogenous government spending etc.:
![]()
where ![]() is square and
is square and ![]() . Fernàndez-Villaverde et al. (2007)
derive conditions when a linear dynamic model has an invertible VAR representation.7 (These are summarized in Appendix B.) This paper considers only cases where these conditions are satisfied, though possibly only in an infinite order VAR representation. The same applies to the situations studied by CKM, CEV as well as Erceg, Guerrieri, and Gust (2005).
Excluding the complications arising from non-invertibilities allows to focus on problems owing to small sample bias and the finite order approximations of the VAR.8
. Fernàndez-Villaverde et al. (2007)
derive conditions when a linear dynamic model has an invertible VAR representation.7 (These are summarized in Appendix B.) This paper considers only cases where these conditions are satisfied, though possibly only in an infinite order VAR representation. The same applies to the situations studied by CKM, CEV as well as Erceg, Guerrieri, and Gust (2005).
Excluding the complications arising from non-invertibilities allows to focus on problems owing to small sample bias and the finite order approximations of the VAR.8
It will be handy to introduce the notation
![]()
for the non-structural moving average (VMA) coefficients of
![]() . The structural moving average representation for
. The structural moving average representation for ![]() is then
is then
![]() with
with
![]() .
.
In the spirit of CEV and CKM, only one of the structural shocks will be identified. For concreteness, let it be the first one, denoted
![]() , and call it "technology shock". Think of the first element of
, and call it "technology shock". Think of the first element of ![]() as being a growth rate (a difference in logs), like the change in labor-productivity Gali (1999) or output growth Blanchard and Quah (1989). The identifying assumption is then that only the technology shock has a permanent effect on the level of the
first element of
as being a growth rate (a difference in logs), like the change in labor-productivity Gali (1999) or output growth Blanchard and Quah (1989). The identifying assumption is then that only the technology shock has a permanent effect on the level of the
first element of ![]() . This restricts the matrix of long-run coefficients,
. This restricts the matrix of long-run coefficients,
![]() :
:
![]()
This restriction holds exactly in the linearized solution to the model described in Section 2.
A key object for implementing this constraint is the spectral density of ![]() . The spectral density at frequency
. The spectral density at frequency ![]() is defined as
is defined as
![]() where
where ![]() is the imaginary unit.9
is the imaginary unit.9 ![]() factors the spectral density of
factors the spectral density of ![]() at frequency zero:
at frequency zero:
![]()
One way to compute the first column of ![]() is by recovering
is by recovering ![]() from the Cholesky
decomposition of
from the Cholesky
decomposition of ![]() . (This is the unique lower triangular factorization of a positive definite matrix.10):
. (This is the unique lower triangular factorization of a positive definite matrix.10):
![]()
CEV show that the restriction in (4) uniquely pins down the first column of ![]() and the Cholesky factorization is one possible implementation.11
and the Cholesky factorization is one possible implementation.11
The long-run coefficients can then be mapped into the matrix of impact responses using the VAR dynamics encoded in the polynomial of lag coefficients ![]() :
:
![]()
3.1 OLS Implementation with Finite-Order VAR
Since the VAR innovations in (1) are assumed to be white noise, they satisfy the OLS normal equations
![]() (
(![]() ). And in principle, the coefficients
). And in principle, the coefficients ![]() could be estimated from least squares projections of
could be estimated from least squares projections of ![]() on its infinite past. In practice,
an empirical implementation can only work with a finite lag length. Henceforth
on its infinite past. In practice,
an empirical implementation can only work with a finite lag length. Henceforth
![]() denotes a lag polynomial of finite order
denotes a lag polynomial of finite order ![]() :
:
![\begin{align} \ensuremath{B(L)^\text{OLS}\xspace} &\equiv \sum_{k=1}^p \ensuremath{B_k^\text{OLS}\xspace} L^{k-1} \notag \ \ensuremath{v_t^\text{OLS}\xspace} &\equiv X_t - \ensuremath{B(L)^\text{OLS}\xspace} X_{t-1} \ \ensuremath{\Omega_v^\text{OLS}\xspace} &\equiv E\;[ \ensuremath{v_t^\text{OLS}\xspace} (\ensuremath{v_t^\text{OLS}\xspace})^T] \notag \ \intertext{where the normal equations are imposed for all lags $k\leq p$ } E X_{t-k} (\ensuremath{v_t^\text{OLS}\xspace})^T &= 0 \end{align}](img93.gif)
The associated VMA is
![]() . Only stable VARs are considered, formally this requires all roots of
. Only stable VARs are considered, formally this requires all roots of
![]() to be outside the unit-circle.
to be outside the unit-circle.
The standard procedure is to assume uncorrelated residuals,
![]() . Following Blanchardand Quah (1989), the long run restriction (4) is implemented based on an estimate of
the spectral density at frequency zero constructed from the OLS estimates. Impact coefficients are computed by plugging these estimates into (6):
. Following Blanchardand Quah (1989), the long run restriction (4) is implemented based on an estimate of
the spectral density at frequency zero constructed from the OLS estimates. Impact coefficients are computed by plugging these estimates into (6):
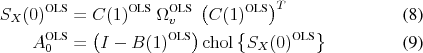
Using a finite-order VAR when the data has been generated from an infinite order process induces a truncation bias into the estimates. In this case, the OLS assumption of uncorrelated forecast errors
![]() is violated, which is an example of what Cooley and Dwyer criticized as an "auxiliary" (but not innocuous) assumption. This
truncation bias arises even when the true population moments of the data generating process were known. Applied to data generated from a business cycle model the truncation bias in SVARs can be substantial, as shown by Cooley and Dwyer (1998), Erceg, Guerrieri, and Gust (2005), Ravenna (2007) or CKM. The truncation bias is also sizable for data from the model described Section 2 as will be seen in Figure 3 below.
is violated, which is an example of what Cooley and Dwyer criticized as an "auxiliary" (but not innocuous) assumption. This
truncation bias arises even when the true population moments of the data generating process were known. Applied to data generated from a business cycle model the truncation bias in SVARs can be substantial, as shown by Cooley and Dwyer (1998), Erceg, Guerrieri, and Gust (2005), Ravenna (2007) or CKM. The truncation bias is also sizable for data from the model described Section 2 as will be seen in Figure 3 below.
3.2 CEV: Combining OLS with Spectral Estimate
CEV propose an alternative estimator for the matrix of impact coefficients. This new estimator uses a mixture of the OLS estimates of ![]() and a non-parametric estimator for
and a non-parametric estimator for ![]() . The procedure is motivated by observing that OLS projections construct
. The procedure is motivated by observing that OLS projections construct
![]() not necessarily with regard to
not necessarily with regard to ![]() but in order to
minimize the forecast error variance
but in order to
minimize the forecast error variance
![]() . Following Sims (1972), the least-squares objective seeks OLS coefficients which minimize the average distance between
themselves and the true
. Following Sims (1972), the least-squares objective seeks OLS coefficients which minimize the average distance between
themselves and the true
![]() , weighted by the spectral density of
, weighted by the spectral density of ![]() , which may or may not be
large at the zero frequency:12
, which may or may not be
large at the zero frequency:12
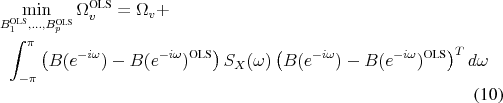
Accordingly, OLS will try to set
![]() close to
close to ![]() only if the data's spectrum is high
at the zero frequency and
only if the data's spectrum is high
at the zero frequency and
![]() need not be the best possible estimate for the spectral density at frequency zero.
need not be the best possible estimate for the spectral density at frequency zero.
Instead of using
![]() , CEV employ a spectral estimator of
, CEV employ a spectral estimator of ![]() to
construct
to
construct ![]() . In Christiano, Eichenbaum, and Vigfusson (2006a), they consider two estimators, one based on Newey and West (1987) and the other on Andrews and Monahan (1992). Both are based on truncated sums of autocovariance matrices. To ensure positive definiteness, these are weighted by a Bartlett kernel. Where Newey-West sums over the (sample) autocovariances of
. In Christiano, Eichenbaum, and Vigfusson (2006a), they consider two estimators, one based on Newey and West (1987) and the other on Andrews and Monahan (1992). Both are based on truncated sums of autocovariance matrices. To ensure positive definiteness, these are weighted by a Bartlett kernel. Where Newey-West sums over the (sample) autocovariances of ![]() ,
,
![\begin{align} \ensuremath{S_X(0)^\text{NW}\xspace} &= \sum_{k=-b}^{b} \left(1 - \frac{\vert k\vert}{b + 1}\right) E \left[{X_t X_{t-k}^T}\right] \end{align}](img106.gif)
Andrews-Monahan uses first the VAR to prewhiten the data and then sums over the residual autocovariances:
![\begin{align} \ensuremath{S_X(0)^\text{AM}\xspace} &= \ensuremath{C(1)^\text{OLS}\xspace} S_v^{NW}(0) \left(\ensuremath{C(1)^\text{OLS}\xspace}\right)^T \ \text{where}\quad \ensuremath{S_v(0)^\text{NW}\xspace} &= \sum_{k=-b}^{b} \left(1 - \frac{\vert k\vert}{b + 1}\right) E \left[{\ensuremath{v_t^\text{OLS}\xspace}(\ensuremath{v_{t-k}^\text{OLS}\xspace})^T}\right] \end{align}](img107.gif)
![]() is a truncation parameter, also known as "bandwidth", which will be discussed in more detail below.13 The Andrews-Monahan estimator nests the OLS case when
is a truncation parameter, also known as "bandwidth", which will be discussed in more detail below.13 The Andrews-Monahan estimator nests the OLS case when ![]() .
.
The new CEV estimator computes the long-run coefficients from the non-parametric density estimate. Combined with the OLS lag coefficients, CEV obtain their impact coefficients as
![]()
Impulse responses are
![]() . Using the Newey-West estimator, impact coefficients are computed as
. Using the Newey-West estimator, impact coefficients are computed as
![]() . For brevity, the remainder of this
section will mostly refer to the Andrews-Monahan estimator, with similar arguments holding for the Newey-West estimator. Section 4 presents simulations using both estimators.
. For brevity, the remainder of this
section will mostly refer to the Andrews-Monahan estimator, with similar arguments holding for the Newey-West estimator. Section 4 presents simulations using both estimators.
The bandwidth choice ![]() is critical in estimating spectra, akin to choosing the lag order of a VAR. Bandwidth choice has been shown to be more important using other weighting schemes than
the Bartlett kernel Newey and West (1994).14 For a consistent estimator,
is critical in estimating spectra, akin to choosing the lag order of a VAR. Bandwidth choice has been shown to be more important using other weighting schemes than
the Bartlett kernel Newey and West (1994).14 For a consistent estimator, ![]() can grow with the sample size but at a smaller rate. CEV use a fixed and fairly large value of
can grow with the sample size but at a smaller rate. CEV use a fixed and fairly large value of ![]() in a sample of
in a sample of ![]() observations.15
observations.15
Theoretically, the prewhitening of Andrews-Monahan is appealing since it removes spikes from the spectral density of ![]() which make spectral estimation difficult (Priestley 1981, Chapter 7). Andrews and Monahan (1992) and Newey and West (1994) find the prewhitening to fare better in Monte Carlo studies than the original Newey-West estimator. Christiano, Eichenbaum, and Vigfusson (2006a) find no clearly superior choice between the two and Christiano, Eichenbaum, and Vigfusson (2006b) proceed to use only the Newey-West estimator.
which make spectral estimation difficult (Priestley 1981, Chapter 7). Andrews and Monahan (1992) and Newey and West (1994) find the prewhitening to fare better in Monte Carlo studies than the original Newey-West estimator. Christiano, Eichenbaum, and Vigfusson (2006a) find no clearly superior choice between the two and Christiano, Eichenbaum, and Vigfusson (2006b) proceed to use only the Newey-West estimator.
To minimize the mean-squared error (MSE) of spectral estimates, the bandwidth selection schemes of Andrews (1991) and Newey and West (1994) can be used. However, constructing an MSE optimal estimator of the spectrum does not necessarily translate into an
MSE optimal estimate of coefficients like
![]() or
or
![]() . Their MSE depends not solely on the MSE of
. Their MSE depends not solely on the MSE of
![]() but--amongst others--on bias and standard error of the spectrum in ways which are specific to the data generating process.16 Hence, the bandwidth selection scheme of Newey and West (1994) may serve as a useful starting point for bandwidth choice, but it is not necessarily optimal for the
purpose of estimating impulse response or variance shares.
but--amongst others--on bias and standard error of the spectrum in ways which are specific to the data generating process.16 Hence, the bandwidth selection scheme of Newey and West (1994) may serve as a useful starting point for bandwidth choice, but it is not necessarily optimal for the
purpose of estimating impulse response or variance shares.
The simulations reported below use both the optimal bandwidth selection scheme of Newey and West (1994) and the large bandwidth choice of CEV. The former tend to pick fairly small bandwidths. For the various calibrations of the model economy considered here, the optimal bandwidth of the Newey-West estimator is typically close to ten, and the average for the Andrews-Monahan estimator is about four. In simulations not reported here, spectral estimates with intermediate bandwidth choices displayed performance characteristics which were intermediate between what is shown here for these two choices here.
3.3 Conceptual Problems with the CEV Procedure
The CEV procedure is motivated by dissatisfaction with
![]() . In conventional SVAR implementations, this estimate is needed for two purposes: First, to construct the long run responses
. In conventional SVAR implementations, this estimate is needed for two purposes: First, to construct the long run responses ![]() as in (9), and second in order to map
as in (9), and second in order to map ![]() back into impact responses
back into impact responses ![]() as in (10). CEV replace
as in (10). CEV replace
![]() with a spectral estimate in the first step, but not in the second. This creates a non-negligible inconsistency in representing the overall dynamics of the
VAR.
with a spectral estimate in the first step, but not in the second. This creates a non-negligible inconsistency in representing the overall dynamics of the
VAR.
By plugging a spectral estimate into their SVAR computations, CEV have weakened the OLS assumption of uncorrelated residuals without fully accounting for its consequences. As a result, the impact coefficients of CEV will in general not reproduce the forecast error variance of the VAR, which is at the heart of variance computations. These and other consequences are illustrated here. The next sub-section shows how a spectral factorization could be used to incorporate spectral estimates into a VAR model while retaining an internally consistent model of the data.
The spectral estimates embody information about correlation in the VAR residuals
![]() . As can be seen from (14), the Andrews-Monahan estimator is constructed from autocovariances of the VAR residuals
. As can be seen from (14), the Andrews-Monahan estimator is constructed from autocovariances of the VAR residuals
![]() . Obviously,
. Obviously, ![]() expresses a concern about
serially correlated residuals. The Newey-West estimator
expresses a concern about
serially correlated residuals. The Newey-West estimator
![]() also embodies concerns about serially correlated VAR residuals since it implies a spectrum for the VAR residuals, which is generally not constant
across frequencies.17
also embodies concerns about serially correlated VAR residuals since it implies a spectrum for the VAR residuals, which is generally not constant
across frequencies.17
Under the premise that the true model has only an infinite-order representation, it is indeed very plausible that the residuals from a VAR(![]() ) will be correlated. In the spirit of Andrews and Monahan (1992), the VAR could then be viewed as having merely prewhitened the data. But typically, researchers fit the lag length of their VARs until the point where estimated residuals do not display any significant correlation. Employing a spectral estimate
like (14) beyond this point implies a belief that there is still useful information to be gleaned from the estimated residuals--or in other words, it implies a distrust against the lag-selection criteria being chosen for the VAR. By allowing for residual
dynamics poses, a researcher risks of overfitting the data, which may still reduce bias in the estimated spectra, but at the expense of a higher standard error.18 Against this backdrop, the assertion of Christiano, Eichenbaum, and Vigfusson (2006a) that the impulse responses computed from their procedure have "smaller bias, smaller means square error" appear even more striking--and as will be seen, these properties do neither extend
to the wider set of calibrations studied below nor to other SVAR statistics like variance decompositions.
) will be correlated. In the spirit of Andrews and Monahan (1992), the VAR could then be viewed as having merely prewhitened the data. But typically, researchers fit the lag length of their VARs until the point where estimated residuals do not display any significant correlation. Employing a spectral estimate
like (14) beyond this point implies a belief that there is still useful information to be gleaned from the estimated residuals--or in other words, it implies a distrust against the lag-selection criteria being chosen for the VAR. By allowing for residual
dynamics poses, a researcher risks of overfitting the data, which may still reduce bias in the estimated spectra, but at the expense of a higher standard error.18 Against this backdrop, the assertion of Christiano, Eichenbaum, and Vigfusson (2006a) that the impulse responses computed from their procedure have "smaller bias, smaller means square error" appear even more striking--and as will be seen, these properties do neither extend
to the wider set of calibrations studied below nor to other SVAR statistics like variance decompositions.
A researcher adopting the CEV strategy wants
![]() and thus
and thus
![]() .19 As a direct implication, the impact coefficients of CEV do not reproduce the forecast error variance of the VAR,
.19 As a direct implication, the impact coefficients of CEV do not reproduce the forecast error variance of the VAR,
![]() . When computing the total variance of the data by summing over
the conditional variations implied by the SVAR, the CEV procedure would not match the unconditional variance of the data either.20 This mismatch in the
unconditional variances of VAR what is implied by the impulse responses of CEV occurs both in population as well as in small sample. A similar argument applies to the Newey-West variant of the CEV procedure, where a researcher seeks
. When computing the total variance of the data by summing over
the conditional variations implied by the SVAR, the CEV procedure would not match the unconditional variance of the data either.20 This mismatch in the
unconditional variances of VAR what is implied by the impulse responses of CEV occurs both in population as well as in small sample. A similar argument applies to the Newey-West variant of the CEV procedure, where a researcher seeks
![]() and thus
and thus
![]() .
.
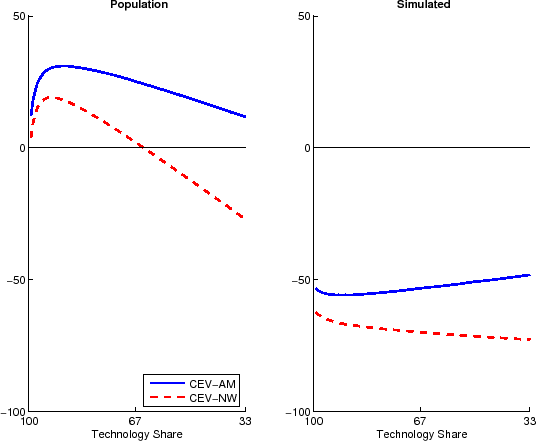 |
For the model economy described in Section 2, Figure 1 illustrates the mismatch in the variance of output growth. In small sample, the variances implied by the CEV procedure are only about half as big as
the OLS sample moments. As can be seen in the right panel of Figure 1, this occurs both when using the Newey-West or the Andrews-Monahan variant of the procedure and regardless of the share of fluctuations explained by technology shocks. As depicted
in the left panel of the figure, the mismatch is qualitatively different, but also sizable when applying the procedure to the population moments of the model while using a lag length of ![]() and spectral bandwidth of
and spectral bandwidth of ![]() .
.
The CEV procedure is motivated by concerns about the ability of OLS estimate to correctly capture the low-frequency dynamics of the data. But implicitly, differences between spectra estimated from OLS and the non-parametric methods are not attributed to misspecified dynamics, but rather to the
VAR's forecast error variance. However, the accuracy of estimating
![]() has so far not been doubted. In fact, getting a good estimate for forecast error variance is precisely the objective of OLS
projections--see (11) above. Still, the CEV procedure deviates from previous contributions to the SVAR literature where identification is defined as a search over the space of matrices
has so far not been doubted. In fact, getting a good estimate for forecast error variance is precisely the objective of OLS
projections--see (11) above. Still, the CEV procedure deviates from previous contributions to the SVAR literature where identification is defined as a search over the space of matrices ![]() satisfying
satisfying
![]() .21
.21
Finally, a researcher might want to re-construct structural shocks based on (2) as
![]() and compare them against
and compare them against
![]() . She will be troubled noticing that the estimated
technology shocks are perfectly correlated:22
. She will be troubled noticing that the estimated
technology shocks are perfectly correlated:22
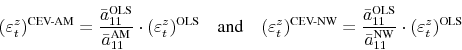
This holds for any pair of matrices ![]() and
and ![]() constructed
from (4) and (6) using
constructed
from (4) and (6) using
![]() and a
and a ![]() satisfying the zero restrictions
(4). Under those conditions the top rows of
satisfying the zero restrictions
(4). Under those conditions the top rows of
![]() ,
,
![]() and
and
![]() are identical up to a scaling.23
are identical up to a scaling.23
Since CEV were only concerned with impulses-responses and ![]() , the problem does not show up in their analysis. The construction of estimated shocks is however often used by researchers, for
instance in order to plot historical decompositions or when identifying several shocks (see for example Altig et al. 2004).
, the problem does not show up in their analysis. The construction of estimated shocks is however often used by researchers, for
instance in order to plot historical decompositions or when identifying several shocks (see for example Altig et al. 2004).
3.4 Correct Identification with Spectral Factorization
To overcome the problems with the CEV procedure discussed above, it is necessary to parse out dynamics of
![]() implied by the spectral estimates. Also when the true model has an infinite order VAR representation, OLS projections of
implied by the spectral estimates. Also when the true model has an infinite order VAR representation, OLS projections of ![]() on a finite number of lags are well defined in the sense of satisfying the projection equations (8) for
on a finite number of lags are well defined in the sense of satisfying the projection equations (8) for ![]() , but the residuals
, but the residuals
![]() are not
are not ![]() . In general, the residuals follow a
moving average representation:
. In general, the residuals follow a
moving average representation:
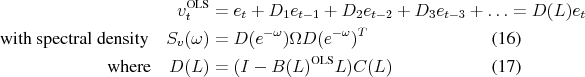
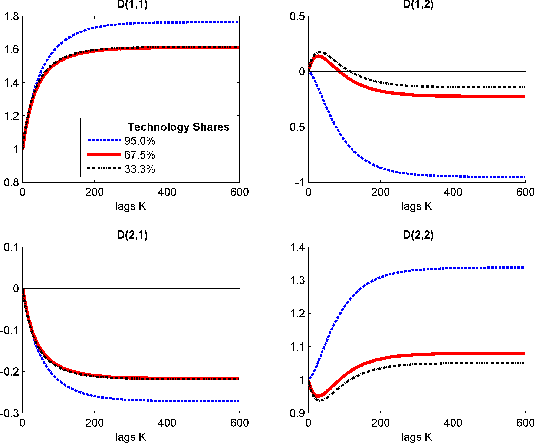 |
CKM and CEV discuss a truncation bias which is hard to detect based on VAR lag-length selection procedures. In terms of the moving average ![]() , their results can be read as finding
, their results can be read as finding
![]() but
but ![]() . This can also be illustrated in the model economy
described in Section 2. Figure 2 plots the population values of the cumulated sums
. This can also be illustrated in the model economy
described in Section 2. Figure 2 plots the population values of the cumulated sums
![]() when
when ![]() for different calibrations of the share of fluctuations in
output explained by technology shocks. (Results are similar for other values of
for different calibrations of the share of fluctuations in
output explained by technology shocks. (Results are similar for other values of ![]() .) At each lag, the increments are small and close to zero, but summing over many lags leads to
.) At each lag, the increments are small and close to zero, but summing over many lags leads to ![]() .
.
Many moving average representations can be consistent with a given spectrum. But only one of them is invertible. As will be shown next, ![]() is invertible and can be uniquely identified
with a spectral factorization of
is invertible and can be uniquely identified
with a spectral factorization of ![]() .
.
![\begin{prp} % latex2html id marker 680 [Invertibility of D(L)] When the underlying model has a fundamental VAR representation as in (\ref{GOPHER:eq:VARmodel}), and the OLS-VAR is stable, the moving average polynomial $D(L)$\ defined in (\ref{GOPHER:eq:DLdef}) has all its roots outside the unit-circle. \end{prp}](img160.gif)

It is straightforward to recover ![]() from
from ![]() with a spectral
factorization. The "canonical spectral factorization" is a classic theorem in linear quadratic control, assuring existence and uniqueness of an invertible
with a spectral
factorization. The "canonical spectral factorization" is a classic theorem in linear quadratic control, assuring existence and uniqueness of an invertible ![]() and a positive definite
and a positive definite
![]() consistent with (17).
consistent with (17).
![\begin{theorem}[Spectral Factorization, \cite{Hannan:1970:timeseriesbook}] Supp... ..._{k=1}^q D_k z^k$ which has all its roots outside the unit circle. \end{theorem}](img162.gif)
The theorem factors a spectrum constructed from a finite number of autocovariances into a finite-order MA. For an empirical application, a finite ![]() has of course to be chosen. But when
applying the spectral factorization to the population objects of the true model (1), it remains to consider that
has of course to be chosen. But when
applying the spectral factorization to the population objects of the true model (1), it remains to consider that ![]() is in general an MA(
is in general an MA(![]() ). However, since the processes for
). However, since the processes for ![]() and
and
![]() are stationary, their autocovariances and MA-coefficients vanish for large lags (Hamilton 1994, Chapter 3.A). Analogous to Sims (1972), a spectral factorization with an arbitrarily large but finite
are stationary, their autocovariances and MA-coefficients vanish for large lags (Hamilton 1994, Chapter 3.A). Analogous to Sims (1972), a spectral factorization with an arbitrarily large but finite ![]() can arbitrarily well approximate the true spectrum and true
can arbitrarily well approximate the true spectrum and true ![]() . Alternatively the true
. Alternatively the true ![]() can be thought of as being the limit of applying Theorem 3.4 to an ever increasing sequence of
can be thought of as being the limit of applying Theorem 3.4 to an ever increasing sequence of ![]() 's.
's.
For a correct identification of the structural shocks, the true impact coefficients (6) can be written in terms
![]() and
and ![]() as
as
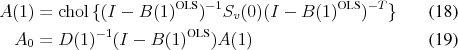
CEV construct
![]() according to (19) while using the spectral estimate
according to (19) while using the spectral estimate
![]() . But they ignore the residual dynamics captured by
. But they ignore the residual dynamics captured by ![]() in (20) when mapping
in (20) when mapping
![]() back into the impact coefficients. As illustrated in Figure 2,
back into the impact coefficients. As illustrated in Figure 2, ![]() is typically not a diagonal matrix in the model economy, far from equal to the identity matrix. Ignoring the residual captured by
is typically not a diagonal matrix in the model economy, far from equal to the identity matrix. Ignoring the residual captured by ![]() is the source of the variance misrepresentation discussed in the previous subsection.
is the source of the variance misrepresentation discussed in the previous subsection.
To combine VAR coefficients and spectral estimates in an internally consistent fashion, a spectral factorization must be used. The spectral factorization of
![]() yields a unique and invertible MA(
yields a unique and invertible MA(![]() ),
denoted
),
denoted
![]() , and an innovations variance matrix
, and an innovations variance matrix
![]() . The superscript "SF-AM" indicates that these are calculated from the residual spectrum employed by the Andrews-Monahan estimator
. The superscript "SF-AM" indicates that these are calculated from the residual spectrum employed by the Andrews-Monahan estimator
![]() . Impact coefficients are then
. Impact coefficients are then
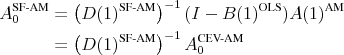
Sayed and Kailath (2001) survey a number of different algorithms for performing spectral factorizations. The computations reported here use a reliable and efficient algorithm from Li (2005), based on a state space
representation of the moving average process of
![]() . (Details are given in Appendix A.)
. (Details are given in Appendix A.)
In contrast to the CEV procedure, the spectral factorization is consistent with the variance of the data, in sample as well as in population.
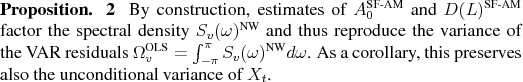
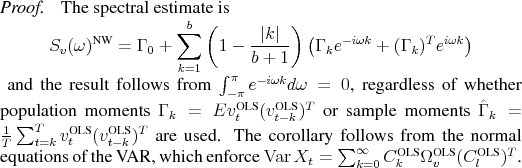
A spectral factorization can also be applied directly to the Newey-West estimate of the data's spectrum,
![]() , yielding coefficients for the VMA of
, yielding coefficients for the VMA of ![]() ,
,
![]() and innovation variance
and innovation variance
![]() . Following (6), impact coefficients and impulse responses can then be computed as
. Following (6), impact coefficients and impulse responses can then be computed as
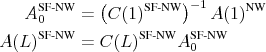
These impulse responses do not involve any VAR coefficients. Analogously to Proposition 3.4, their construction preserves the variance of the data.
4 SVARs applied to Data from Lab Economy
The previous section described several schemes for imposing the long-run restriction (4) on the data. The conventional method, going back to Blanchard and Quah (1989), uses OLS estimates of a VAR. The recently proposed procedure of CEV combines this with a non-parametric estimate of the spectral density at frequency zero. This procedure has been criticized above for its lack of internal consistency. Finally, this paper proposed a new method, combining OLS estimates and spectral estimators in an internally consistent way. This method relies on a spectral factorization ("SF") to uncover the dynamics implied by the non-parametric spectral estimators.
These procedures are applied here to data simulated from the model economy described in Section 2. The same data generating process has also been used by CEV and CKM.24 For the CEV and SF methods, there are two variants depending on whether the spectral estimators of Newey and West (1987) or Andrews and Monahan (1992) are used. This section reports results for both.
Mimicking conditions faced by empirical researchers, "small" samples with 180 observations are simulated. In small sample, two distinct issues arise. First, there is truncation bias in VARs and spectral estimators arising from the need to specify a finite lag length ![]() , respectively a finite bandwidth
, respectively a finite bandwidth ![]() . As discussed in Section 2, lag length is determined individually for each draw with an information criterion and spectral bandwidth is fixed at 150. In addition, alternative results are reported using the bandwidth selection procedure of Newey and West (1994) for Newey-West
spectra. (See Section 3.2 for further discussion of bandwidth selection.)
. As discussed in Section 2, lag length is determined individually for each draw with an information criterion and spectral bandwidth is fixed at 150. In addition, alternative results are reported using the bandwidth selection procedure of Newey and West (1994) for Newey-West
spectra. (See Section 3.2 for further discussion of bandwidth selection.)
Second, there is the small sample bias in estimated parameters known from Hurwicz (1950).25 To isolate the pure truncation effects from the Hurwicz bias, the identification procedures are not only applied to simulated data, but also to VARs and spectral estimates constructed from the model's true population moments.26
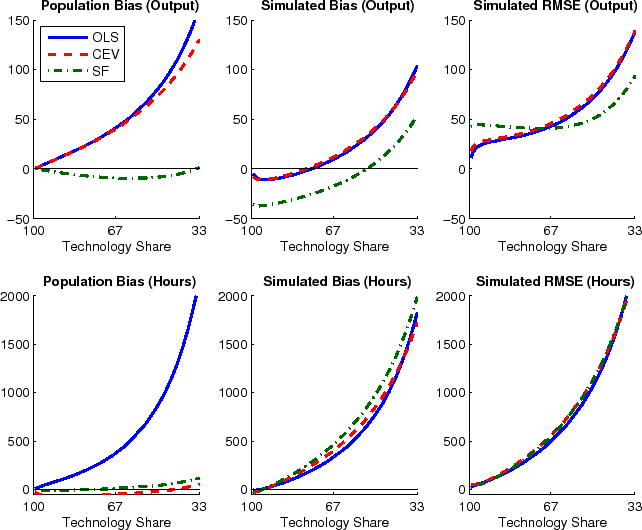
The procedures are evaluated in terms of of their capability to uncover two statistics typically of interest to applied researchers. Following CKM and CEV, estimates of the response of hours to a technology shock are computed. For brevity, the discussion is limited on impact coefficients
![]() , since all methods compute impulse responses from
, since all methods compute impulse responses from
![]() and their estimates of
and their estimates of ![]() (except when
factorizing
(except when
factorizing
![]() ). In addition, the share of fluctuations in output and hours due to technology shocks is estimated. As it is typical in the business cycle literature,
these shares are computed after filtering out any fluctuations which do not correspond to cycles with a duration between two-and-a-half and eight years.27
Two criteria are reported to assess the goodness of estimates: Bias and Root Mean Square Error (RMSE), both expressed as percentages relative to the true value known from the model.28
). In addition, the share of fluctuations in output and hours due to technology shocks is estimated. As it is typical in the business cycle literature,
these shares are computed after filtering out any fluctuations which do not correspond to cycles with a duration between two-and-a-half and eight years.27
Two criteria are reported to assess the goodness of estimates: Bias and Root Mean Square Error (RMSE), both expressed as percentages relative to the true value known from the model.28
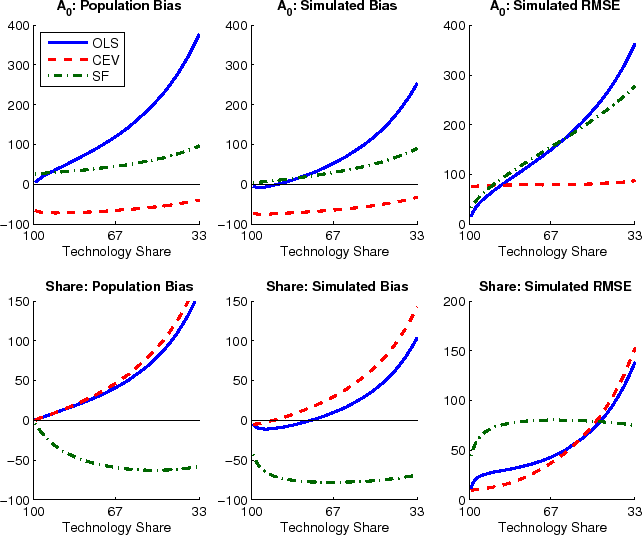
The results show that all procedures are subject to substantial truncation and small biases and none works like a panacea. Different methods display different strengths and weaknesses. The claims by Christiano, Eichenbaum, and Vigfusson (2006a) of "smaller bias, smaller means square error" associated with their procedure do neither generalize to a wider range of model calibrations nor do they extend from the estimation of impact responses to variance shares.
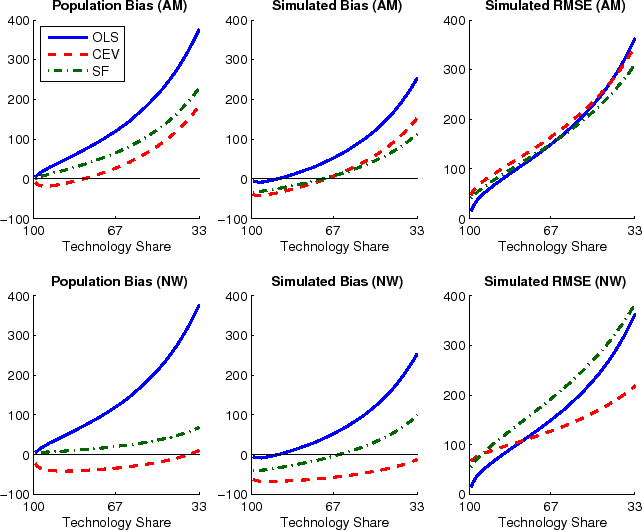 |
Effects from the truncation and the small sample bias can offset each other. This is the case when estimating the impact of technology on hours. The left column in Figure 3 shows how impact responses are overestimated in population whereas the simulated bias shown in the middle column of the figure is lower (more negative). This simulated bias displays the total effect from truncation and Hurwicz bias. The OLS method has the largest population bias and it is only partially offset by the Hurwicz bias. The two spectral methods suffer from substantially smaller truncation bias, and depending on the simulated importance of technology shocks, the total bias can be either negative or positive. Coincidentally, the upwards bias in SF-AM and SF-NW is exactly offset around technology shares of about two thirds, corresponding to the range of MLE estimates of CEV and CKM for U.S. data. (Similarly for CEV-AM, but not CEV-NW.) However, results are different for other calibrations of the technology share, which cautions strongly against extrapolating from a particular result to different data sets and different applications.
Unless the true share of technology shocks is very large, the RMSE of estimated impact coefficients are very large, often surpassing more than 100% of the true value. Interestingly, the RMSE do not differ much across the different methods, as can be seen in the right-most column of Figure 3. If anything, SF-NW is outperforming CEV-NW on bias, at the expense of a worse RMSE. This is likely due to an overfitting of the residual dynamics by SF-NW.
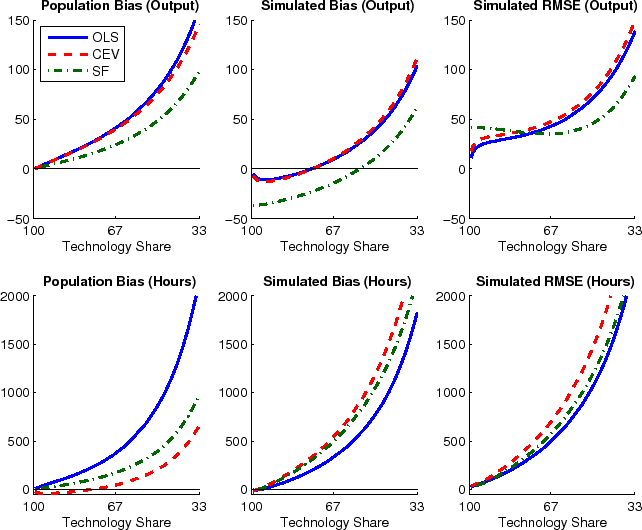 |
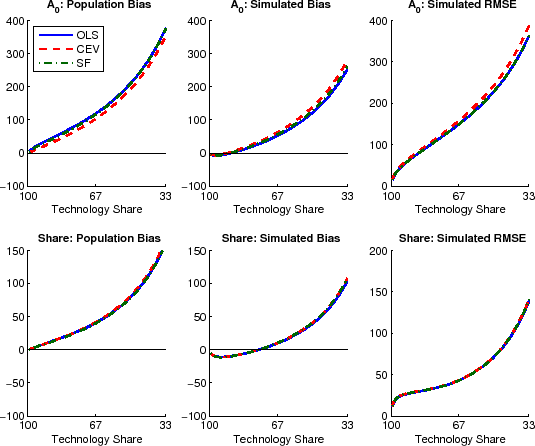
Turning to the estimated variance shares of output and hours shown in Figure 4, the relative performance of the various methods looks quite different. The panels in the top row of the figure show bias and RMSE for variance decompositions of output, the bottom row for variance decompositions of hours. For this figure, spectral densities have been estimated with the Andrews-Monahan estimator. Results are broadly similar when using the Newey-West estimator (see Figure A.1 in the separate appendix with additional results.)
Strikingly, for technology shares in output, bias and RMSE are very similar when using either OLS or CEV. The mismatch in total variance discussed in Section 3.3, does not seem to distort the computations of relative variance measures in this case. But, the two methods differ when decomposing the variance of hours. Bias and RMSE in the variance decomposition of hours are an order of magnitude larger than for output, cautioning very strongly against neglecting small sample issues when comparing SVAR estimates against model predictions. Moreover, the variance decompositions of hours provide a useful counterexample against disregarding OLS methods altogether, since OLS dominates the spectral methods both in terms of simulated bias and RMSE for all calibrations considered here. All in all, these results underline how truncation and Hurwicz bias interact with the different methods in ways which are hard to anticipate for an empirical researcher who does not know the true dynamics of the data.
The results presented in Figures 3 and 4 are based on a large and fixed spectral bandwidth of ![]() . A separate
appendix with additional results shows that the results are similar for Newey-West spectra when their bandwidth has been chosen by the automatic bandwidth selection procedure of Newey and West (1994). Compared to the case of a large and fixed bandwidth, only two differences stand
out. Estimating technology shares from a direct factorization of the Newey West spectrum perform worse compared to the large bandwidth case, both in terms of bias and RMSE, unless technology accounts for less than two thirds of business cycle fluctuations in output (see Figure A.1 in the appendix). Furthermore, the RMSE of impact coefficients estimated with CEV-NW is almost flat at around two thirds of the true value, independently of the true technology share (Figure A.2). Applying the automatic
bandwidth selection for the residual spectra of the Andrews-Monahan estimator yields bandwidths close to zero, such that the results are mostly indistinguishable from the OLS estimates (Figure A.3).
. A separate
appendix with additional results shows that the results are similar for Newey-West spectra when their bandwidth has been chosen by the automatic bandwidth selection procedure of Newey and West (1994). Compared to the case of a large and fixed bandwidth, only two differences stand
out. Estimating technology shares from a direct factorization of the Newey West spectrum perform worse compared to the large bandwidth case, both in terms of bias and RMSE, unless technology accounts for less than two thirds of business cycle fluctuations in output (see Figure A.1 in the appendix). Furthermore, the RMSE of impact coefficients estimated with CEV-NW is almost flat at around two thirds of the true value, independently of the true technology share (Figure A.2). Applying the automatic
bandwidth selection for the residual spectra of the Andrews-Monahan estimator yields bandwidths close to zero, such that the results are mostly indistinguishable from the OLS estimates (Figure A.3).
5 Conclusions
In finite sample, truncation bias and Hurwicz bias pose fundamental problems when identifying structural shocks from restrictions on the long-run behavior of the data. These issues are present in the time domain when working with a VAR, as well as in the frequency domain when working with spectral estimators. Basically, the same estimates of the data's autocovariances are employed for constructing non-parametric estimates of the spectrum as well as for computing OLS coefficients. In both cases, truncation bias arises since there are only as many sample autocovariances as there are data points. And due to the Hurwicz bias, variance estimates tend to be biased downwards the smaller the sample and the larger the persistence of the data--again affecting both OLS estimates of VAR coefficients as well as non-parametric estimates of the spectral density.
Thus, spectral estimates offer no panacea against the truncation and small sample problems known from OLS. At best, by allowing for additional dynamics, they might improve upon OLS in terms of bias, but by overfitting the data, this comes at the expense of increasing RMSE.
The performance of different estimators appears to be very specific to the underlying model and its calibration, making it hard to predict, which procedure would do well in future applications using new data. Even for a given calibration, when a method performs better in terms of one model statistic, say impact coefficients, this does not necessarily translate into better performance for another statistic, like a variance share. Going forward, it would be more suitable to compare SVAR estimates (from any procedure), against the small sample predictions, not the true moments, of a specific model as in Cogley and Nason (1995), Kehoe (2006), Dupaigne, Feve, and Matheron (2007) and Dupaigne and Feve (2009).
1 Spectral Factorization Method
Spectral factorization has a long tradition in the fields of linear quadratic control, robust estimation and control as surveyed for example by Whittle (1996).29 Theorem 3.4 has been adapted from Hannan (1970, p. 66). The original theorem allows for unit roots in ![]() . The version stated above has been slightly strengthened by excluding the case of zero power in the spectral density at zero-frequency, to ensure the invertibility of the MA(
. The version stated above has been slightly strengthened by excluding the case of zero power in the spectral density at zero-frequency, to ensure the invertibility of the MA(![]() ).30
).30
In the context of this paper, ![]() will be the spectral density of
will be the spectral density of
![]() where
where
![]() . We will be using non-parametric estimates of
. We will be using non-parametric estimates of ![]() based on weighted sums of the sample autocovariance function as described in Section 3.2.31
based on weighted sums of the sample autocovariance function as described in Section 3.2.31
Theorem 3.4 requires ![]() to be non-singular. This can be understood as requiring that the autocovariances need to decay sufficiently fast in relation
to the number of MA lags. For example, in the scalar case and with
to be non-singular. This can be understood as requiring that the autocovariances need to decay sufficiently fast in relation
to the number of MA lags. For example, in the scalar case and with ![]() , the first-order autocorrelation to be matched with a MA(1) cannot be larger than 0.5 in absolute value.32
, the first-order autocorrelation to be matched with a MA(1) cannot be larger than 0.5 in absolute value.32
Algorithms for implementing the factorization go back to Whittle (1963) and have recently been surveyed by Sayed and Kailath (2001). The simulations reported here use the algorithm of Li (2005), which is based on a state space representation of ![]() and performed very reliably.33 The remainder of this appendix describes the algorithm in more detail.
and performed very reliably.33 The remainder of this appendix describes the algorithm in more detail.
Suppose ![]() follows an MA(
follows an MA(![]() ) as above. To represent it in a state space system,
define the state vector
) as above. To represent it in a state space system,
define the state vector
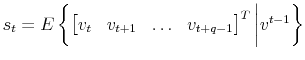 where
where ![]() is the entire history of realizations of
is the entire history of realizations of ![]() up to time
up to time ![]() . Li then constructs the following state space system
. Li then constructs the following state space system
![]()
where ![]() and
and ![]() are the
are the ![]() identity matrix, respectively the
identity matrix, respectively the ![]() zero matrix.
zero matrix.
What is needed is a mapping from the autocovariances of ![]() ,
, ![]() , to the
state space objects. The objects of interest are the matrix
, to the
state space objects. The objects of interest are the matrix ![]() containing the stacked MA coefficients
containing the stacked MA coefficients ![]() as well as the variance
as well as the variance
![]() of the innovations process. To obtain this mapping, it is useful to stack the autocovariances into a matrix
of the innovations process. To obtain this mapping, it is useful to stack the autocovariances into a matrix
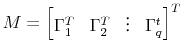
Li (2005), Theorem 2 shows that the variance-covariance matrix of the states
![]() solves the Riccati equation
solves the Riccati equation
![]() and that the MA(
and that the MA(![]() ) coefficients can be recovered as
) coefficients can be recovered as
![]() and
and
![]() . As shown by Li (2005), the above Riccati equation can be solved recursively, starting from
. As shown by Li (2005), the above Riccati equation can be solved recursively, starting from
![]() and iterating over
and iterating over
![]() since
since
![]() and
and
![]() .
.
At the end of each factorization computed for this paper, it has been verified that the factorization produces an invertible MA(![]() ) polynomial, which matches the original spectral density.
In all simulations, this held up to machine accuracy.
) polynomial, which matches the original spectral density.
In all simulations, this held up to machine accuracy.
2 VARs Implied by Lab Economy
This section outlines how to derive the following: First, values from the lab economy for true VAR objects like ![]() ,
, ![]() ,
, ![]() , and the autocovariances of
, and the autocovariances of ![]() . Second,
population coefficients of finite-order VARs implied by the lab economy.34
. Second,
population coefficients of finite-order VARs implied by the lab economy.34
The linearized solution to the lab economy described in Section 2 yields a state space model for labor productivity growth and hours
![]()
State vector and shock vector are:
![]()
where ![]() is the log-deviation of detrended capital from its steady state,
is the log-deviation of detrended capital from its steady state, ![]() and
and
![]() are the labor wedge and the growth rate in technology. (
are the labor wedge and the growth rate in technology. (![]() includes
also lagged variables due to the presence of labor productivity growth in
includes
also lagged variables due to the presence of labor productivity growth in ![]() .)
.)
The computation of the matrices ![]() ,
, ![]() and
and ![]() is straightforward, please see CKM for a detailed presentation.
is straightforward, please see CKM for a detailed presentation.
True VAR objects The decomposition in section 4 uses the following objects of the true process: ![]() ,
, ![]() ,
, ![]() as well as the autocovariances of
as well as the autocovariances of ![]() . Their computation from the state space is straightforward since true impulse responses and spectrum are given by
. Their computation from the state space is straightforward since true impulse responses and spectrum are given by
![]() and
and
![]() . The impact coefficients
. The impact coefficients
![]() are apparent from (21). Recalling equation (2), this also pins down the covariance matrix
of the forecast errors
are apparent from (21). Recalling equation (2), this also pins down the covariance matrix
of the forecast errors
![]() .
.
In order to map forecast errors into structural shocks, ![]() must obviously be square and invertible. Furthermore, Fernandez-Villaverde, Rubio-Ramirez, and Sargent (2005) show that invertibility requires
the eigenvalues of
must obviously be square and invertible. Furthermore, Fernandez-Villaverde, Rubio-Ramirez, and Sargent (2005) show that invertibility requires
the eigenvalues of
![]() to be strictly less than one in modulus, which is satisfied for all calibrations considered here.
to be strictly less than one in modulus, which is satisfied for all calibrations considered here.
The non-structural moving average representation of ![]() is
is
![]() . From (3), the coefficients of the non-structural VAR(
. From (3), the coefficients of the non-structural VAR(![]() ) representation of the model can be obtained by inverting this moving average, yielding
) representation of the model can be obtained by inverting this moving average, yielding
![]() .
.
The autocovariances ![]() can be directly computed from the state space model. The covariance matrix of the states
can be directly computed from the state space model. The covariance matrix of the states
![]() is obtained as the solution to a discrete Lyapunov equation:
is obtained as the solution to a discrete Lyapunov equation:
![]() and the autocovariances of
and the autocovariances of ![]() are
are
![]() .
.
VAR(![]() ) coefficients in population Finite-order VAR(
) coefficients in population Finite-order VAR(![]() ) can be computed as
projections of
) can be computed as
projections of ![]() on a finite number of its past values,
on a finite number of its past values,
![]() . In line with the notation of the main text, population coefficients of a VAR(
. In line with the notation of the main text, population coefficients of a VAR(![]() ) are denoted with a superscript "
) are denoted with a superscript "![]() ".
".
![]()
The coefficients of the lag polynomial
![]() solve the OLS normal equations
solve the OLS normal equations
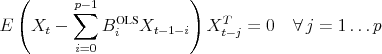
which are evaluated using the autocovariance matrices of ![]() whose computations are described in the preceding paragraph. For instance if
whose computations are described in the preceding paragraph. For instance if ![]() ,
,
![]() . Detailed formulas for higher VARs can be found in Fernandez-Villaverde, Rubio-Ramirez, and Sargent (2005).
. Detailed formulas for higher VARs can be found in Fernandez-Villaverde, Rubio-Ramirez, and Sargent (2005).
Chari, Kehoe, and McGrattan (2005), Proposition 1 show that the VAR representation of ![]() in the model is of infinite order and residuals from a VAR(
in the model is of infinite order and residuals from a VAR(![]() ) will not be martingales. By construction, the projection residuals
) will not be martingales. By construction, the projection residuals
![]() are orthogonal to
are orthogonal to ![]() , ...,
, ..., ![]() , but they are not orthogonal to the complete history of
, but they are not orthogonal to the complete history of ![]() . The moving average
representation of the forecast errors
. The moving average
representation of the forecast errors
![]() is easily constructed from
is easily constructed from
![]() .
.
Variance equation Even though the VAR(![]() ) residuals
) residuals
![]() are not
are not ![]() , the usual variance equation is still
applicable. For notational convenience, take the case of a VAR(1),
, the usual variance equation is still
applicable. For notational convenience, take the case of a VAR(1),
![]() . The normal equations imply
. The normal equations imply
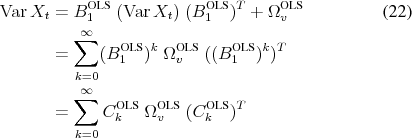
The second line is obtained by recursive substitution of ![]() and the third line follows from the construction of moving-average coefficients of a VAR(1),
and the third line follows from the construction of moving-average coefficients of a VAR(1),
![]() . The argument is easily extended to VARs with higher lag orders by using their companion form.
. The argument is easily extended to VARs with higher lag orders by using their companion form.
3 Bandpass-Filtered Variance Share from SVARs
This appendix describes how to compute the share of bandpass-filtered fluctuations attributed to technology shocks from a set of SVAR parameters, ![]() and
and ![]() . The bandpass filter employed here considers only cycles with a duration between two-and-a-half and eight years. Denoting the bandpass-filtered level of (log) output
. The bandpass filter employed here considers only cycles with a duration between two-and-a-half and eight years. Denoting the bandpass-filtered level of (log) output ![]() , its variance can be easily computed from the transfer function
, its variance can be easily computed from the transfer function
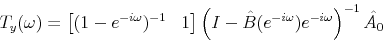
Depending on the identification scheme, ![]() corresponds to
corresponds to ![]() (true value)
or
(true value)
or
![]() ,
,
![]() ,
,
![]() ,
,
![]() or
or
![]() and
and ![]() corresponds to the true (infinite
order) polynomial
corresponds to the true (infinite
order) polynomial ![]() or its finite-order counterpart
or its finite-order counterpart
![]() . When using the spectral factorization of
. When using the spectral factorization of
![]() , the inverse of
, the inverse of
![]() is replaced by
is replaced by
![]() .
.
Using
![]() and
and
![]() the bandpass-filtered variance is
the bandpass-filtered variance is
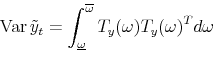
and the share of fluctuations attributed to technology shocks is the ratio
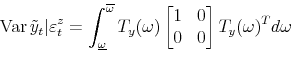
Similar computations yield the variance shares for hours, when using the transfer function
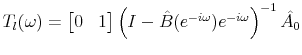 .
.
Northwestern University, mimeo.
Econometrica 59 (3): 817-58 (May).
Econometrica 60 (4): 953-66 (July).
The American Economic Review 79 (4): 655-673 (September).
NBER.
Journal of International Economics 59 (1): 77-100 (January).
Staff Report 364, Federal Reserve Bank of Minneapolis.
Econometrica 75 (3): 781-836 (May).
Journal of Monetary Economics 55 (8): 1337-1352 (November).
Working Paper 9819, NBER.
Journal of the European Economic Association 2 (2-3): 381-395 (April-May).
Journal of the European Economic Association 2 (2-3): 475-483 (April-May).
Chapter 1 of NBER Macroeconomics Annual 2006.
MIT Press.
The American Economic Review 85 (3): 492-511.
Journal of Econometrics 83 (1-2): 57-88 (March-April).
Review of Economic Dynamics, forthcoming.
Review of Economic Dynamics 10 (2): 238-255 (April).
Journal of the European Economic Association 3 (6): 1237-1278 (December).
Carnegie-Rochester Conference Series on Public Policy 49 (December): 207-244.
Technical Working Paper 0308, NBER.
American Economic Review 97 (3): 1021-1026 (June).
The American Economic Review 89 (1): 249-271.
NBER Working Paper 10636.
Journal of the European Economic Association 4 (2-3): 455-465 (April-May).
Princeton, NJ: Princeton University Press.
Wiley Series in Probability and Mathematical Statistics.
John Wiley & Sons.
unpublished Manuscript.
Princeton University Press.
Chapter XV of Statistical Inference in Dynamic Economic Models, 365-383.
John Wiley & Sons, Inc.
Staff Report 379, Federal Reserve Bank of Minneapolis.
Journal of Multivariate Analysis 96 (2): 425-438 (October).
Wiley Series in Probability and Statistics.
John Wiley & Sons.
mimeo.
Federal Reserve Bank of Minneapolis, mimeo.
Review of Economic Studies 61 (4): 631-53.
Econometrica 55:703-708.
International Economic Review 47 (3): 837-894 (August).
Probability and Mathematical Statistics.
Amsterdam: Elsevier Academic Press.
Journal of Monetary Economics 54 (7): 2048-2064 (October).
Numerical Linear Algebra with Applications 8:467-496.
Journal of the American Statistical Association 67 (337): 169-175 (March).
Econometrica 76 (1): 175-194 (January).
Journal of Monetary Economics 52 (2): 381-419 (March).
Chapter 1 of NBER Macroeconomics Annual 2006.
MIT Press.
Biometrika 50 (1/2): 129-134 (June).
Wiley-Interscience Series in Systems and Optimization.
Chichester: John Wiley & Sons.
List of Figures
- 1. Percentage Errors in Variance of Output Growth Computed from CEV Procedure
- 2. D (1) ≠ I
- 3. Impact Response of Hours to Technology Shock
- 4. Technology Shares in Fluctuations of Output and Hours
- A.1. Technology Shares in Fluctuations of Output and Hours (Newey-West)
- A.2. Simulations with Automatic Bandwidth Selection (Newey-West)
- A.3. Simulations with Automatic Bandwidth Selection (Andrews-Monahan)
ADDITIONAL RESULTS
 |
 |
 |
Footnotes
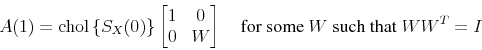
In the lab economy described later, the VAR will be bivariate and the forecast errors
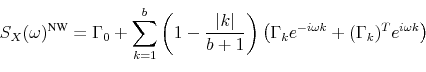
and the implied spectrum of VAR residuals is
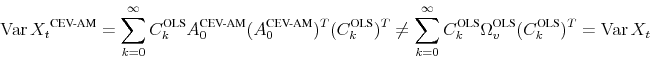
The last step holds because of the normal equations (8) regardless of whether
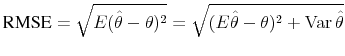 and it is converted into a percentage error using
and it is converted into a percentage error using