
Household Income Uncertainties Over Three Decades
Keywords: Income uncertainty, Great Moderation, precautionary saving
Abstract:
JEL Classification: D31, E21
1 Introduction
Recent studies of aggregate data find that the volatility of U.S. GDP growth declined substantially from the mid-1980s to the mid-2000s, a phenomenon dubbed as the "Great Moderation" in the literature (Kim and Nelson 1999 and McConnell and Perez-Quiros 2000). By contrast, the observation that household income volatility rose over the same period of time has been documented in a distinct line of work (see, for example, Dynan, Elmendorf, and Sichel 2007, Keys 2008, and Jensen and Shore 2010). However, few studies have focused how household income uncertainty evolved during this period. This is somewhat surprising because on the one hand, it is well known that many decisions made by households, such as consumption, savings, investment portfolio choices, and durable goods purchases, crucially depend on the uncertainty they face regarding their future income. On the other hand, though related, the evolution of income volatility does not necessarily speak to the dynamics of household income uncertainties.
Why is income volatility not equivalent to income uncertainty? To be clear, other terms-"instability," "transitory variance," and "year-to-year earnings variability" -have also been used in the literature loosely referring to income volatility. Formally, the distinction between uncertainty and these other terms is the information set upon which they are derived. Intuitively, volatility is largely a variable of macroeconomic interest, characterizing movements in the observed distribution of income, whereas uncertainty is what matters to the individual. As Cunha, Heckman, and Navarro (2005), Blundell, Pistaferri, and Preston (2008), and Shin and Solon (2010) have argued, it is important to distinguish predictable income changes from those unpredictable to households in order to accurately characterize the income risks they face.
Models that try to filter out predictable income changes are often estimated conditional on information concurrent to the realization of the income (as in Carroll and Samwick 1998 and Gottschalk and Moffitt 2008). Income uncertainty, in contrast, should refer to the risks associated with future income perceived by households conditional on the information they have at the time when they make the relevant decision.
This paper addresses these limitations and studies the trend in income uncertainty since the early 1970s using a novel approach introduced by Feigenbaum and Li (2011) that measures income uncertainty as the variance of forecast errors that households appear to face at various future horizons.
This approach makes several key innovations relative to the existing workhorse models that deal with income riskiness. First, although forecast errors are constructed using a linear projection equation, we do not impose any further restrictions on the statistical properties of the forecast errors,
such as how they are correlated across forecast horizons, thereby retaining the highest degree of flexibility in characterizing income uncertainty and how it changes over time. In particular, we do not presume that forecast errors can be parsimoniously decomposed into a permanent and a transitory
component. Instead, we separately construct forecast errors at different future horizons that range from one year ahead to ten years ahead and estimate the variances of the forecast errors and their correlations across forecast horizons. Second, we project time ![]() income using only the information observable at time
income using only the information observable at time ![]() , instead of at
, instead of at ![]() . We also experiment with complementing this information set with selected elements in the information set observable at
. We also experiment with complementing this information set with selected elements in the information set observable at ![]() ,
acknowledging that households may have more information about their own future than an econometrician does concurrently. Although the information set we use still does not fully replicate the true information set the households use in forming the expectations of their future income, we argue that
this is an important step toward studying income risks using feasible information.
,
acknowledging that households may have more information about their own future than an econometrician does concurrently. Although the information set we use still does not fully replicate the true information set the households use in forming the expectations of their future income, we argue that
this is an important step toward studying income risks using feasible information.
Following Carroll and Samwick (1998), we focus on the uncertainty of total family non-capital income because this broad measure of income is presumed to be the most relevant type of income for models of intertemporal optimization and precautionary saving that we revisit later in the paper. Using data from the Panel Study of Income Dynamics, we first present the trends in family non-capital income uncertainty at future horizons up to 10 years ahead from the early 1970s. For example, 2-year-ahead family non-capital income uncertainty, on net, rose about 40 percent from the early 1970s to the early 2000s. In addition, our analysis shows that since the early 1970s, income uncertainty rose more at farther horizons than at nearer horizons but the persistence of forecast errors was little changed, suggesting the increase in income uncertainty cannot be solely accounted for by the increase in variances of transitory income shocks.
We then study whether income uncertainty dynamics over the last three decades demonstrated any patterns that are different based on household economic status or demographic characteristics. We find the rise of income uncertainty is widespread and is not concentrated within any specific subpopulation. Nevertheless, certain groups of households have experienced larger percentage increases in uncertainty than others. Among those groups for which income uncertainty has risen the most (in a relative sense) are single-earner households and households in the top income quartile. Further, we show that the trends we document are robust to a number of alternative model and sample specifications.
We complete our analysis by computing how much of a change in aggregate behavior should have occurred in response to this change in idiosyncratic uncertainty. Our empirical estimates of the dynamics of income uncertainty, though highly flexible, are computationally difficult to be incorporated in a standard model. We therefore solve for the equilibrium in two Aiyagari (1994) economies where the income process is (parsimoniously) calibrated to match the beginning-of-sample and end-of-sample levels of income uncertainty of our estimates, respectively. Our calibration exercise yields clear evidence of an increase in the variances of both the persistent and transitory shocks. We find that aggregate saving is 3% higher in the economy with greater income uncertainty, where the part of the saving due to precautionary reasons is more than 30% higher. This result presents a counterfactual with respect to the aggregate saving rate observed in the data, which decreased appreciably during this period. The difference between the data and the model economy calls for future research to identify other mechanisms that may have potentially discouraged saving over time to a greater degree than precautionary motives should have encouraged saving.
2.1 Evidence of Rising Household Income Volatility
Kim and Nelson (1999) and McConnell and Perez-Quiros (2000) convincingly demonstrate that the volatility of U.S. output growth declined sharply after the early 1980s. Using different statistical approaches, both papers identify the break date was the first quarter of 1984.1 Similarly, Stock and Watson (2002) document that over the four decades between 1960 and 2001, the standard deviation of U.S. GDP growth declined nearly 40 percent, from an average of 2.7 % before the 1984:1 break date to an average of 1.6% after the break date. More recently, Dynan, Elmendorf, and Sichel (2006) report that standard deviations of log differences of the aggregate earnings in the National Income and Product Account (NIPA) decreased by more than 30 percent before and after this break date.
As the findings of declines in aggregate volatility proved to be robust and became widely accepted, another consensus emerged in a fast-growing literature that the volatility of household income: instead of having declined with macroeconomic volatility, household-level income volatility has increased substantially since the 1970s. Roughly speaking, there are two statistical approaches used in the literature for studying trends in household income volatility. One approach first filters out the predictable part of income by regressing household income on demographic characteristics concurrent to the income data and assumes the residuals of this regression follow some parameterized statistical process. Typically, these models assume the residuals are the sum of permanent and transitory income shocks. The variances of these shocks can be identified by examining the auto-covariance structure of these residuals in longitudinal data. Such an approach has been widely used in the precautionary saving literature (see, for example, Carroll and Samwick 1997 and Gourinchas and Parker 2002). Using this approach, Moffitt and Gottschalk (2008) find that the transitory variance of household income increased substantially in the 1980s and stayed elevated since then.
Despite its many desirable features, the above approach has certain limitations. Notably, as Shin and Solon (2010) argue, "......the parametric models used in the literature are arbitrary mechanical constructs and the resulting estimates of trends can be sensitive to arbitrary variations in model specification." Indeed, Baker and Solon (2003) reject many restrictions that are routinely imposed on such models.
In light of such concerns, the second approach of studying income volatility takes a more agnostic stand with respect to the underlying data generation process of income shocks. For example, Dynan, Elmendorf and Sichel (2007) and Shin and Solon (2010) both use the cross-sectional dispersions in year-to-year household income growth as a measure of income volatility. The former paper finds that the volatility of various measures of household income all increased substantially since the early 1970s, albeit not at a steady pace. The latter paper, focusing on a more narrowly defined metric of income, finds that the volatility of men's labor earnings did increase in the 1970s but did not show any pronounced increase since then until the 2000s.2
2.2.1 Conceptual Issues
Although these concepts are often interchangeably used, income volatility is not equivalent to uncertainty. Whereas income volatility is a measure of income variability in general, income uncertainty only encompasses future variability that cannot be predicted conditional on currently available
information. Let ![]() denote the logarithm of the future income
denote the logarithm of the future income ![]() periods ahead of
time
periods ahead of
time ![]() . We have
. We have
| (1) |
where
To be clear, income uncertainty formulated in this way is an ex post uncertainty in the sense that the level of uncertainty is estimated only after the realization of income. Later in the paper when solving for the optimal precautionary saving rate, we implicitly assume that the realized uncertainty is consistent with the ex ante perceived uncertainty. However, this assumption may not hold all the time. Two approaches, which are not the focus of this paper, can be used for a more focused study of the ex ante uncertainty. First, one may use the household choice variables to infer income uncertainty perceived by households (Guvenen and Smith 2008), although this requires more assumptions about household behavior than we are willing to make here. Second, some surveys explicitly ask participating households their estimates of the riskiness of future income, providing direct measures of ex ante income uncertainty.
From the above decomposition we have
| (2) |
indicating that the cross-sectional variance is the sum of the variance of the predictable and unpredictable components of income-"uncertainty," as we use them. Taking the difference between
| (3) |
Therefore, changes in the cross-sectional variance are the same as changes in income uncertainty only if the predictability term,
Furthermore, as discussed before, the routinely used approach of filtering out predictable income is to regress the observed income on concurrent household characteristics. Essentially, this is equivalent to regressing ![]() on an information set that is likely observable only at time
on an information set that is likely observable only at time ![]() . But a household predicting its
. But a household predicting its ![]() -period-ahead income at time
-period-ahead income at time ![]() can only use the information available to it at time
can only use the information available to it at time ![]() . Therefore, the residuals from such a regression are more accurately interpreted as the unexplained component, rather than the unpredictable component, of income.
. Therefore, the residuals from such a regression are more accurately interpreted as the unexplained component, rather than the unpredictable component, of income.
2.2.2 Estimation Methodology
To address the limitations of the existing methodology discussed above, this paper studies income uncertainty and its evolution over time using an approach introduced in Feigenbaum and Li (2011) that measures income uncertainty as the cross-sectional variance of forecast errors.4 We construct such forecast errors using a simple linear projection for each future horizon (up to 10 years ahead) and evaluate their variances in each year. For each
future horizon, ![]() , we estimate the following projection equation
, we estimate the following projection equation
where household
3 Household Income Data in the PSID
We use the Panel Study of Income Dynamics (PSID) data in our analysis. The PSID is a nationwide longitudinal survey of households conducted by the Institute of Social Research at the University of Michigan. The first wave of data was collected in 1968. It was an annual survey through 1997, and after that the PSID was restructured to a biennial survey. We use the PSID data from 1970 to 2005. We do not use the data collected in 1968 and 1969 because the exact values of head and wife transfer income, which is a component we use to compute total family non-capital income, were not collected in those two waves. The PSID has an original core nationwide representative sample of nearly 3,000 households and the sample has grown steadily since the survey was launched. An important reason for the growing sample size is that the PSID has a very high retention rate. The vast majority of households surveyed in one year continued to participate in the next wave of the survey. Indeed, there are more than 1,200 households who stayed in the survey for more than 30 years.6
Besides extensive information about work status, employment history and demographic characteristics, the PSID has detailed information on household income. Our study focuses on total family non-capital income. We also present statistics on the dispersion of growth of total family income and head and wife labor earnings uncertainty to facilitate comparison with the NIPA data. Both total family income and head and wife labor earnings are included in each of the PSID public releases.7 Family non-capital income is calculated as the sum of head and wife labor earnings, head and wife transfer income, taxable income from other family members, and transfer income from other members.8
To estimate Equation (4), we need to link the information of household ![]() in year
in year ![]() ,
, ![]() , and
, and ![]() with the information of the same
household in year
with the information of the same
household in year ![]() for various
for various ![]() . The number of waves each household participated
in the PSID survey varies substantially. Consequently, the highly unbalanced panel limits our ability to fully explore certain longitudinal statistical properties of the sample, such as fixed or random effects. We interpret Equation (4) mainly as a statistical projection
equation rather than a structural relationship. Accordingly, without loss of generality, we treat pairs of the same household in different years, such as
. The number of waves each household participated
in the PSID survey varies substantially. Consequently, the highly unbalanced panel limits our ability to fully explore certain longitudinal statistical properties of the sample, such as fixed or random effects. We interpret Equation (4) mainly as a statistical projection
equation rather than a structural relationship. Accordingly, without loss of generality, we treat pairs of the same household in different years, such as ![]() ,
,
![]() etc., as independent observations and pool them together to estimate the equation.9
etc., as independent observations and pool them together to estimate the equation.9
We construct a sample for each projection horizon, ![]() , separately. We deflate our income measures using the CPI index with 1982-84 = 100. We then apply the following sample selection
rules.
, separately. We deflate our income measures using the CPI index with 1982-84 = 100. We then apply the following sample selection
rules.
- We use only the nationwide representative PSID sample and exclude the sample of low-income families and the Latino supplement sample.
- We restrict the heads of our sample households to be older than 24 in the base year
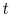 and younger than 65 years old in the forecast year
and younger than 65 years old in the forecast year 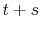 . For example, when forecasting income five years ahead, we keep only those households whose heads are younger than 60 years old.
. For example, when forecasting income five years ahead, we keep only those households whose heads are younger than 60 years old. - We keep only households whose heads reported positive labor income and positive but fewer than 4000 working hours in year
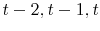 , and . Furthermore, we keep only households whose heads are either
working for pay, temporarily laid off or unemployed in year and , i.e. we remove
the households whose heads are out of the labor force in either the base year or in the forecast year.
, and . Furthermore, we keep only households whose heads are either
working for pay, temporarily laid off or unemployed in year and , i.e. we remove
the households whose heads are out of the labor force in either the base year or in the forecast year. - We keep households whose family non-capital income is positive for
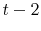 ,
, 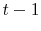 ,
and .
,
and . - Finally, we trim off the top and bottom 2.5 percent of the distribution of income growth between and in order to minimize the bias caused by outliers.10
There are two additional treatments that we apply to the PSID data. First, the PSID does not ask information about race and education in all waves, and in those years information on race and education attainments was collected, it was not carried forward for all observations, creating many blank values. We provide a remedy by replacing the blank data points of race and education with the latest valid data points prior to the blank. Doing so, we increase the sample size noticeably. Second, prior to the 2003 wave, the PSID used the 1970 census occupation and industry codes. In the 2003 and 2005 waves, the 1970 census codes were replaced with the 2000 census codes. We try our best to map the 2000 codes with the 1970 codes.
Our sample covers the PSID data from 1970 to 2005. Recalling that the year-![]() PSID records income earned in year
PSID records income earned in year ![]() , our income data refer to the year of 1969 to 2004. Because Eq. (4) includes two lags of income, our estimated income uncertainty series begins in year 1971. Also, because the PSID became a biennial survey after 1997, the income uncertainty
series of odd-numbered future horizons end earlier than the series of even-numbered future horizons. For example, our estimated one-year ahead uncertainty covers the period from 1971 to 1995, but the two-year ahead uncertainty series covers the period from 1971 to 2002. One additional caveat is
that for the years when the PSID data were collected annually, year-
, our income data refer to the year of 1969 to 2004. Because Eq. (4) includes two lags of income, our estimated income uncertainty series begins in year 1971. Also, because the PSID became a biennial survey after 1997, the income uncertainty
series of odd-numbered future horizons end earlier than the series of even-numbered future horizons. For example, our estimated one-year ahead uncertainty covers the period from 1971 to 1995, but the two-year ahead uncertainty series covers the period from 1971 to 2002. One additional caveat is
that for the years when the PSID data were collected annually, year-![]() income can be merged with the demographic data referring to the same year, even though they were not collected in the same
wave. We do not have a perfect merge after 1997. We then use the demographic data collected in 1999, 2001, and 2003 in estimating Eq. (4) for
income can be merged with the demographic data referring to the same year, even though they were not collected in the same
wave. We do not have a perfect merge after 1997. We then use the demographic data collected in 1999, 2001, and 2003 in estimating Eq. (4) for ![]() = 1998, 2000, and 2002,
respectively. For this reason, the income uncertainty in these years can be underestimated. However, because the gap is only one year and most demographic variables are highly persistent, we argue the bias is likely very small.
= 1998, 2000, and 2002,
respectively. For this reason, the income uncertainty in these years can be underestimated. However, because the gap is only one year and most demographic variables are highly persistent, we argue the bias is likely very small.
Table 1 reports the sizes of the samples we use to estimate Eq. (4) using family non-capital income for
![]() . As indicated, the sample sizes generally shrink as
. As indicated, the sample sizes generally shrink as ![]() becomes bigger
because fewer households continued to participate in the PSID survey over time. Because the PSID became a biennial survey in 1997, we are no longer able to use the last several waves of data when
becomes bigger
because fewer households continued to participate in the PSID survey over time. Because the PSID became a biennial survey in 1997, we are no longer able to use the last several waves of data when ![]() is an odd number. Consequently, the sample for
is an odd number. Consequently, the sample for ![]() is the largest. Note also that the sample contains a comfortably large number of observations even for
is the largest. Note also that the sample contains a comfortably large number of observations even for ![]() =10.
=10.
| 1 Year | 2 Years | 3 Years | 4 Years | 5 Years | |
| 37,769 | 40,215 | 31,655 | 32,870 | 26,864 | |
| 6 Years | 7 Years | 8 Years | 9 Years | 10 Years | |
| 26,814 | 22,742 | 21,587 | 19,140 | 17,246 |
Finally, we present evidence that an aggregate income approximation constructed using the PSID data does exhibit a significant decrease of volatility during the last several decades-an observation consistent with the Great Moderation-reassuring us that the PSID well represents the household sector of the aggregate economy. Following Dynan, Elmendorf and Sichel (2006), we construct the PSID sample mean income and calculate the two-year growth for the period of 1971-2004. We then compute the standard deviation of income growth over two subsamples, 1971-1985 and 1986 - 2004 and compare them with the standard deviation computed using the NIPA total personal income and employee compensations.11 As table 2 shows, volatilities of both the NIPA and the PSID income measures decline appreciably between the earlier and later sample period. The most important discrepancy is that the NIPA total personal income volatility appears to have experienced an even greater decline compared with the PSID total family income.12
| 1971 - 1985 | 1986 - 2004 | Percent of difference | |
| NIPA: Total personal income | 3.9% | 2.4% | -38.8% |
| NIPA: Employee compensation | 5.1% | 2.9% | -42.5% |
| PSID: Total family income | 4.8% | 4.1% | -14.7% |
| PSID: Labor earnings | 4.8% | 2.9% | -40.0% |
4.1 Overview of the Trend in Household Income Uncertainty
We begin by presenting an overview of the trends in family non-capital income uncertainties at both the nearer and farther horizons. Figure 1 plots the estimated 2, 4, 6, 8, and 10-year-ahead income uncertainties and their respective fitted linear trends.13 As we see in the top panel, the uncertainty associated with family non-capital income 2 years ahead rose substantially between 1971 and 2002. Defining the cumulative percentage-increase of
income uncertainty, ![]() , as the growth between the average within the first and the last five-year period of the sample
, as the growth between the average within the first and the last five-year period of the sample
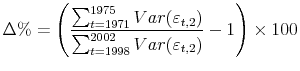 |
(5) |
our estimate suggests that the 2-year-ahead income uncertainty rose nearly 40 percent during the three decades since early 1970s. Moreover, abstracting from year-to-year fluctuations, the upward trend is very persistent and prevails through the entire sample period. The two middle panels plot trends in the middle-term uncertainty of 4 and 6 years ahead. As expected, the 6-year-ahead series is higher than the 4-year-ahead uncertainty series. Similar to the 2-year-ahead uncertainty series, there is a pronounced upward trend in each of the two series. However, a pronounced decline in income uncertainty in the late 1980s is apparent in the two middle-term uncertainty series. Finally, the two bottom panels plot long-term income uncertainty. The variance of forecast errors regarding income eight years ahead rose substantially through the mid-1980s, then declined sharply before rebounding to even higher levels by the mid-1990s, the end of the series. The evolution of the 10-year-ahead income uncertainty is somewhat different. It rose through the mid-1970s, then stayed relatively flat before rising noticeably again in the later 1980s. On net, both the 8- and 10-year-ahead income uncertainty were higher at the end of the sample period than at the beginning of the sample period.
The different patterns of uncertainty dynamics across forecast horizons is partly due to varying samples used to estimate Eq. (4) when ![]() changes. In Section 5 we see that, even using a constant sample, we still find pronounced upward trends in income uncertainty across forecast horizons.
changes. In Section 5 we see that, even using a constant sample, we still find pronounced upward trends in income uncertainty across forecast horizons.
4.2 Changing Persistence or Changing Variances
Assuming the underlying income shocks can be decomposed into a purely transitory component and a more persistent (but not necessarily permanent) component, the observed rise in income uncertainties can be due to increasing transitory shock variances, increasing persistent shock variances, growing persistence of the persistent shocks, or combinations of these factors.14 We first study whether there is any evidence of growing persistence of income shocks. Figure 2 plots the correlations between the 1-year-ahead forecast errors and the 2-, 4- and 10-year-ahead forecast errors across years. If the shock persistence increased, we would expect to see these correlations also increase over time. But this is not observed in the estimated correlation series. Correlations between the 1-year-ahead forecast errors and the forecast errors of all future horizons stay flat through the mid 1990s, when our data for the 1-year-ahead forecast errors end.
Ruling out growing persistence of income shocks, we now focus on the trend in the variances of income shocks. Figure 3 plots the three-year average of the variances of the forecast errors over all future horizons (![]() = 1 - 10) for two periods, 1971-1973 and 1992-1994. We see that the gap between the two curves is much wider at farther horizons than at nearer horizons. This "fanning-out" pattern, holding the level of shock persistence constant, suggests that the increase in
income uncertainty cannot be solely accounted for by an increase in transitory shock variances. Later in the paper, we will calibrate a parameterized income process using our estimated series of forecast error variances to assess the respective changes in the variances of transitory and persistent
shocks.
= 1 - 10) for two periods, 1971-1973 and 1992-1994. We see that the gap between the two curves is much wider at farther horizons than at nearer horizons. This "fanning-out" pattern, holding the level of shock persistence constant, suggests that the increase in
income uncertainty cannot be solely accounted for by an increase in transitory shock variances. Later in the paper, we will calibrate a parameterized income process using our estimated series of forecast error variances to assess the respective changes in the variances of transitory and persistent
shocks.
4.3 Income Uncertainties for Subpopulations
We now address the question of whether the rise in income uncertainties is a widespread phenomenon or is concentrated within a subpopulation. In particular, we are interested in how trends in income uncertainty differ between dual-earner and single-earner households and across income quartiles.
First, we compare the income uncertainty of dual-earner households with that of single-earner households. The estimates of the 2-year-ahead income uncertainty profiles are presented in Figure 4. We define a household as dual-earner if the wife's labor earning is greater than 25 percent of the
head's labor earning in the base year. Here, the forecast errors are constructed from estimating Eq. (4) with the whole sample but the variances of single-earner and dual-earner households are estimated separately. In Section 5 we will see that
estimating Eq. (4) separately using each subpopulation does not change our results materially. As Figure 4 shows, levels of income uncertainty of single-earner and dual-earner households in the early 1970s were quite close but they diverged during the next three decades,
though both series exhibit a pronounced upward trend. By the early 2000s, our cumulative uncertainty increase measure, ![]() , is 33% for dual-earner households but 54% for single-earner
households.
, is 33% for dual-earner households but 54% for single-earner
households.
Figure 5 presents the 2-year-ahead income uncertainty profiles for households differentiated by quartiles of the three-year average of income over ![]() ,
, ![]() ,
, ![]() , where
, where ![]() is the base year. Again, income uncertainty rose for households in all quartiles. However, the households in the highest income quartile experienced the greatest percentage increase in income uncertainty. From the lowest quartile to the highest quartile,
is the base year. Again, income uncertainty rose for households in all quartiles. However, the households in the highest income quartile experienced the greatest percentage increase in income uncertainty. From the lowest quartile to the highest quartile, ![]() are 32%, 42%, 37%, and 60% respectively. Thus the percentage increase for households in the highest income quartile is much greater than other households.
are 32%, 42%, 37%, and 60% respectively. Thus the percentage increase for households in the highest income quartile is much greater than other households.
Although we only presented the estimated 2-year-ahead uncertainty series for each subpopulation in Figures 4 and 5, comparison of trends in uncertainties at other future horizons over subpopulations yields the same results qualitatively. Moreover, the income uncertainty profiles of subpopulation by age (not shown) also all increased appreciably since the early 1970s.
5 Robustness Analysis
In this section, we conduct a series of analyses to ensure that the results presented above are robust to different sample selection rules as well as model specifications.
5.1 Allowing for Structural Changes in Projection Equation Parameters
One possible explanation for the rising estimated income uncertainty is that the projection relationship is not stationary over time. If the underlying true parameters of Eq. (4) change over time, the variances of forecast errors may also demonstrate time-varying patterns. To examine whether the upward trend of income uncertainty is caused by the breaks in projection relationships, we split the sample into two parts, before and after 1985. We then estimate Eq. (4) and compute the forecast error variances separately for each subsample. Although an F-test rejects the hypothesis that all coefficients are the same for each subsample, the differences are economically small. Consequently, the estimated uncertainty profiles (not shown) that allow for structural changes in parameters in the projection equations are essentially the same as those presented in Section 4.
Similarly, we estimate Eq. (4) separately for single-earner and dual-earner households and for households in each income quartile. Again, the implied income uncertainty profiles are very similar to those presented in Figures 4 and 5.
5.2 Alternative Samples
When constructing the baseline sample, we trimmed off the top and bottom 2.5% of the distribution of income growth between ![]() and
and ![]() . To what extent are the trends in income uncertainty affected by the tails being trimmed off? To answer this question we estimate the uncertainty profiles with two alternative samples, constructed by applying more aggressive (top and bottom
5%) and more conservative trimming thresholds (top and bottom 0.5%). Figure 6 contrasts the 2-year-ahead income uncertainty profiles derived from these two alternative samples with the baseline results. Clearly, the sample constructed with more conservative trimming yields a higher and steeper
income uncertainty profile than the baseline results, whereas the sample constructed with more aggressive trimming yields a lower and flatter income uncertainty profile than the baseline results, suggesting the income uncertainty experienced by households in the tails of the income growth
distribution increased more than those in the center of the distribution. However, even the inner-90% sample yields a significant upward trend, with
. To what extent are the trends in income uncertainty affected by the tails being trimmed off? To answer this question we estimate the uncertainty profiles with two alternative samples, constructed by applying more aggressive (top and bottom
5%) and more conservative trimming thresholds (top and bottom 0.5%). Figure 6 contrasts the 2-year-ahead income uncertainty profiles derived from these two alternative samples with the baseline results. Clearly, the sample constructed with more conservative trimming yields a higher and steeper
income uncertainty profile than the baseline results, whereas the sample constructed with more aggressive trimming yields a lower and flatter income uncertainty profile than the baseline results, suggesting the income uncertainty experienced by households in the tails of the income growth
distribution increased more than those in the center of the distribution. However, even the inner-90% sample yields a significant upward trend, with
![]() = 32%. In contrast,
= 32%. In contrast,
![]() = 66%.
= 66%.
Recalling that the size of the sample used in estimating Eq. (4 ) varies with ![]() , we then assess how sensitive our results are with respect to such sample variation.
Specifically, we estimate the income uncertainty profiles using only the households in the sample used to estimate the 10-year-ahead forecast equation, the households that have stayed in the survey for more than 10 years. We find the results derived from these alternative samples are very similar
to our baseline results. For example, as shown in Figure 7, the 2-year-ahead income uncertainty estimated using the baseline and the alternative sample are very close for the overlapping sample period (1971 - 1994). The cumulative increase for this period is 24% for the baseline sample and 23% for
the alternative sample.
, we then assess how sensitive our results are with respect to such sample variation.
Specifically, we estimate the income uncertainty profiles using only the households in the sample used to estimate the 10-year-ahead forecast equation, the households that have stayed in the survey for more than 10 years. We find the results derived from these alternative samples are very similar
to our baseline results. For example, as shown in Figure 7, the 2-year-ahead income uncertainty estimated using the baseline and the alternative sample are very close for the overlapping sample period (1971 - 1994). The cumulative increase for this period is 24% for the baseline sample and 23% for
the alternative sample.
5.3 Allowing for Superior Information
Acknowledging that households may have additional information about their future selves at ![]() in addition to the information observable at
in addition to the information observable at ![]() , we study the residuals from the following model
, we study the residuals from the following model
| (6) |
where
Bearing these caveats in mind, our goal is to evaluate to what extent omitting possible household superior information may bias the estimated trend in household income uncertainty. As shown in Figure 8, though the levels of income uncertainty estimated under the alternative information set are lower than our baseline results at both the nearer and farther horizons, they do share a very similar trend during our sample period.
6 Calibration of the Income Process
Thus far we have considered how various second-order moments of forecast errors of future income have evolved over time. To interpret these measures of uncertainty dynamics, we calibrate a parsimonious model of income shocks that is common in the literature. Doing so also helps us quantitatively assess the extent to which precautionary saving should have changed in response to changes in income uncertainty in the context of a standard model with incomplete markets under rational expectations. Since we are looking at time trends in expectations of the variances of future income shocks, it would be quite difficult to construct one time-consistent model of the income process that could be inserted in a rational expectations model to solve for the equilibrium transition path during this evolution of uncertainty.15 Instead, we estimate a series of income processes, one for each base year in our sample.
We assume the logarithm of ![]() -period ahead income,
-period ahead income, ![]() , is expected as of time
, is expected as of time
![]() to follow the process
to follow the process
where
where
The ![]() -period ahead income can be represented as
-period ahead income can be represented as
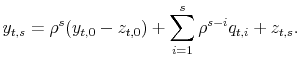
The
![\displaystyle V[y_{t,s}\vert\mathcal{I}_{t}]=\frac{1-\rho ^{2s}}{1-\rho ^{2}}\sigma _{p,t}^{2}+(1+\rho ^{2s})\sigma _{z,t}^{2}.](img53.gif)
The covariance between
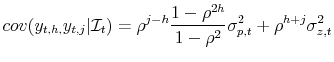 .
.The calibration is done by minimizing a quadratic loss function of the distance between the volatility and correlation matrices predicted for a given set of parameters and the matrix elements estimated from the data.17 Note that this calibration procedure is the same for the two cases
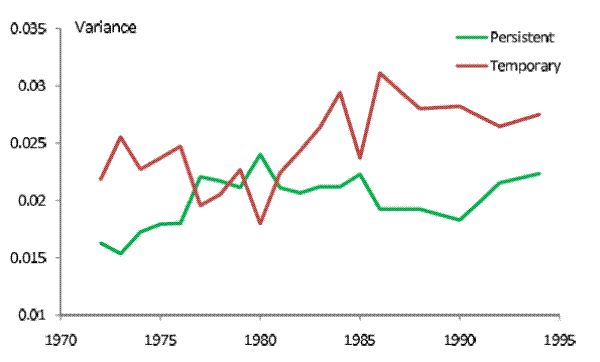
The calibration result suggests that
![]() , while Figure 9 plots the variances
, while Figure 9 plots the variances
![]() and
and
![]() for this calibration. Consistent with most studies, we find that the persistent shocks have a smaller variance (on an annual basis) than the temporary shocks. The variance of the
persistent shocks averages to 0.020 while the standard deviation of the temporary shocks averages to 0.025. Both time series trend upward, albeit noisily, with a net increase of 37% (from 0.016 to 0.022) for the persistent shocks and of 26% (from 0.022 to 0.028) for the temporary shocks. The
variability of the persistent shocks increased sharply during the 70s, fell off slightly during the 80s, and then rebounded in the 90s. The temporary shocks lost variability during the 70s, saw a sharp increase in the early 80s, and declined marginally afterwards.
for this calibration. Consistent with most studies, we find that the persistent shocks have a smaller variance (on an annual basis) than the temporary shocks. The variance of the
persistent shocks averages to 0.020 while the standard deviation of the temporary shocks averages to 0.025. Both time series trend upward, albeit noisily, with a net increase of 37% (from 0.016 to 0.022) for the persistent shocks and of 26% (from 0.022 to 0.028) for the temporary shocks. The
variability of the persistent shocks increased sharply during the 70s, fell off slightly during the 80s, and then rebounded in the 90s. The temporary shocks lost variability during the 70s, saw a sharp increase in the early 80s, and declined marginally afterwards.
7 Precautionary Saving
Finally, to assess the quantitative importance of the changes in income uncertainty on household behavior, we consider how aggregate saving would change in a stylized general-equilibrium model based on Aiyagari (1994).18 Specifically, we compare the level of precautionary savings implied by the 1972 level of income uncertainty and the 1994 level of income uncertainty.
A continuum of infinitely-lived households of unit measure maximize expected utility
![\displaystyle E\left[ \sum_{t=0}^{\infty }\beta ^{t}u(c_{t};\gamma )\right] ,](img65.gif)
where
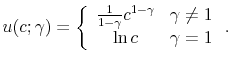
Each household enjoys an idiosyncratic, uninsurable stream of labor productivity
There is one risk-free asset that pays gross interest
![\displaystyle v(x_{t},l_{t})=\max_{0\leq c_{t}\leq x_{t}+\frac{wL_{1}}{r}}u(c_{t})+\beta E[v(wl_{t+1}+R(x_{t}-c_{t}),l_{t+1})\vert l_{t}],](img74.gif)
where cash on hand
To close the model, we assume there is a production sector with the Cobb-Douglas production function
where
and
In equilibrium, the labor supply is the average of productivity of workers (since they have unit measure)
and the capital stock is the average of their demand for assets
Aggregate consumption is mean consumption
To complete the calibration, we set the share of capital to
![]() . To match the macroeconomic targets
. To match the macroeconomic targets ![]() and
and ![]() , we set the depreciation rate to
, we set the depreciation rate to
![]() and the discount factor to
and the discount factor to
![]() . This leaves the risk aversion parameter, which we set to
. This leaves the risk aversion parameter, which we set to ![]() .
This is within the range of values typically considered in the literature, and it also works well for matching properties of the lifecycle profile of consumption (Feigenbaum (2008)).
.
This is within the range of values typically considered in the literature, and it also works well for matching properties of the lifecycle profile of consumption (Feigenbaum (2008)).
Because the process for cash on hand ![]() is highly persistent, a large number of simulations is necessary to achieve sufficient convergence of the sample average. We compute aggregate
variables for steady state equilibria using simulations of a representative agent over ten billion periods. The results are given in Table 3 for different choices of
is highly persistent, a large number of simulations is necessary to achieve sufficient convergence of the sample average. We compute aggregate
variables for steady state equilibria using simulations of a representative agent over ten billion periods. The results are given in Table 3 for different choices of
![]() and
and
![]() . In line 1, we set
. In line 1, we set
![]() and
and
![]() , consistent with the estimated income uncertainty at the beginning of the sample period (1972). In line 4, we set
, consistent with the estimated income uncertainty at the beginning of the sample period (1972). In line 4, we set
![]() and
and
![]() , consistent with the estimated income uncertainty at the end of the sample period (1994). The contrast between lines 1 and 4 informs us of the total changes due to the
increases in income uncertainty. To better understand the contribution of the increases in persistent and transitory shocks variances, in lines 2 and 3 respectively, we alter only one of
, consistent with the estimated income uncertainty at the end of the sample period (1994). The contrast between lines 1 and 4 informs us of the total changes due to the
increases in income uncertainty. To better understand the contribution of the increases in persistent and transitory shocks variances, in lines 2 and 3 respectively, we alter only one of
![]() and
and
![]() relative to line 1. Thus, the comparison between lines 1 and 2 indicates the net contribution of the increase in persistent shock variance, while the comparison between lines 1
and 3 shows the effects of greater transitory shock variances.
relative to line 1. Thus, the comparison between lines 1 and 2 indicates the net contribution of the increase in persistent shock variance, while the comparison between lines 1
and 3 shows the effects of greater transitory shock variances.
We focus on aggregate precautionary saving, the portion ![]() of the capital stock that would not arise in the corresponding model without uncertainty, i.e. where
of the capital stock that would not arise in the corresponding model without uncertainty, i.e. where
![]() . Contrasting lines 1 and 4, we find that the steady state level of capital stock due to precautionary saving increases from 0.440 when income uncertainty is
low to 0.586 when income uncertainty is high, a 33% increase. Comparing line 1 with lines 2 and 3 respectively, we notice that the increase in the variance of persistent shocks alone accounts for 32 percentage points of the increase, while the increase in the variance of transitory income shocks
alone would contribute only a fraction of a percentage point. Thus it is really only the change in the persistent shock that will impact consumer behavior in the aggregate.
. Contrasting lines 1 and 4, we find that the steady state level of capital stock due to precautionary saving increases from 0.440 when income uncertainty is
low to 0.586 when income uncertainty is high, a 33% increase. Comparing line 1 with lines 2 and 3 respectively, we notice that the increase in the variance of persistent shocks alone accounts for 32 percentage points of the increase, while the increase in the variance of transitory income shocks
alone would contribute only a fraction of a percentage point. Thus it is really only the change in the persistent shock that will impact consumer behavior in the aggregate.
The increase in the total capital stock, ![]() , along with the other macroeconomic variables
, along with the other macroeconomic variables ![]() and
and ![]() is small relative to the increase in income uncertainty because only the saving for precautionary motives responds to changes in uncertainties, and precautionary
saving only accounts for a small fraction of the total saving.
is small relative to the increase in income uncertainty because only the saving for precautionary motives responds to changes in uncertainties, and precautionary
saving only accounts for a small fraction of the total saving.
|
|
|
||||||
| (1) 1972 calibration | 0.016 | 0.022 | 0.440 | 4.918 | 1.712 | 1.302 | 3.413% |
| (2) higher
|
0.016 | 0.028 | 0.442 | 4.920 | 1.712 | 1.302 | 3.411% |
| (3) higher
|
0.022 | 0.022 | 0.582 | 5.060 | 1.728 | 1.307 | 3.195% |
| (4) 1994 calibration | 0.022 | 0.028 | 0.585 | 5.063 | 1.729 | 1.307 | 3.190% |
- Notes:
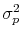 and
and
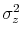 denote the variance of persistent and transitory shocks, respectively.
denote the variance of persistent and transitory shocks, respectively. 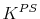 denotes the capital stock due to precautionary reasons.
denotes the capital stock due to precautionary reasons.
8 Concluding Remarks
This paper documents a substantial increase in household income uncertainties during the last three decades. Our approach does not impose any restrictions on the statistical properties of the underlying income shocks. In addition, the unpredictable component of future income is estimated using only the information available to households when expectations are formed. In contrast to the dramatic decline in the volatility of output growth observed in aggregate data, household income uncertainty, estimated as the variance of forecast errors, exhibited a large increase from the early 1970s to the early 2000s. For example, near term family non-capital income uncertainty rose by 40 percent. The rise is observed for various income measures across time and for all subpopulations. However, some groups that historically enjoyed lower levels of income uncertainty, such as the high-income households, experienced the largest percentage increase.
Solving a general-equilibrium consumption optimization model we find that such an increase in income uncertainty would call for precautionary saving to increase by more than 30 percent and aggregate capital stock to increase by 3 percent. These results are somewhat counterfactual because the personal saving rate in the U.S. has, on net, declined over the same period. Two factors potentially account for the discrepancy between what the model predicts and what is observed in data. First, social insurance may have improved during this period, reducing the precautionary motive for saving (Krueger and Perri (2001)). Second, households may have underestimated the income uncertainty and consequently have saved less than the optimal amount. Quantifying the roles played by these factors is the next topic on our research agenda.
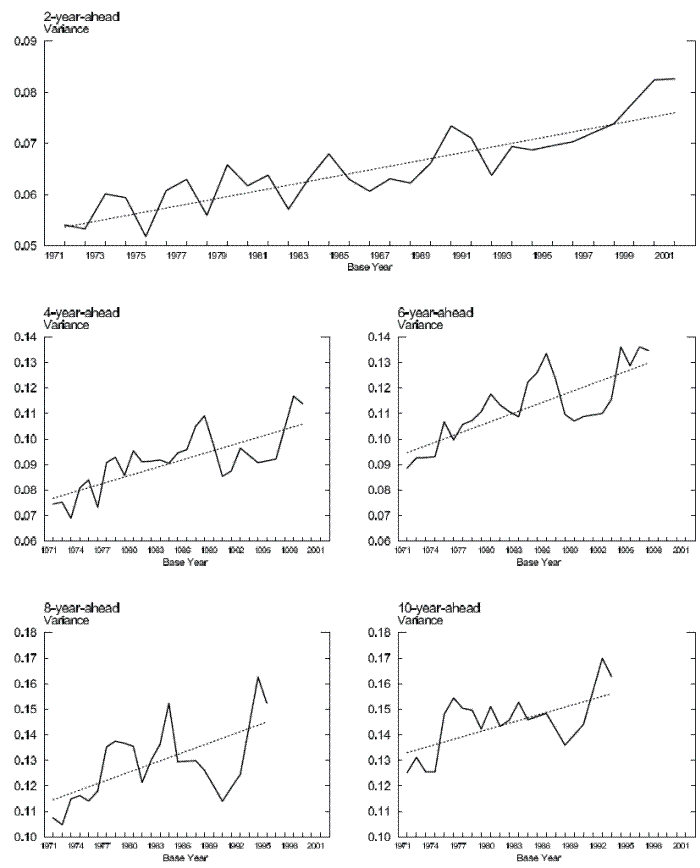
Note: Income uncertainty is measured as the cross-sectional variances of the forecast errors in Eq. (4) in the text.
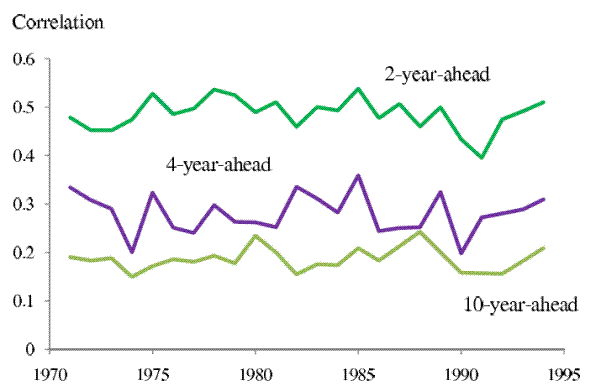
Note: The three series are the coefficients of correlation, estimated in each year from 1971 to 1994, between the 1-year-ahead forecast errors and the 2-, 4-, and 10-year ahead forecast errors, respectively. The correlations between the 1-year-ahead forecast errors and the forecast errors at other horizons (not shown) also remained stable during this period.
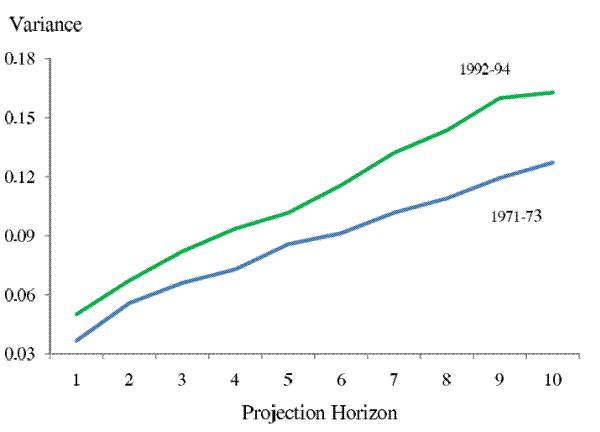
Note: The upper curve shows the average of the family non-capital income uncertainty profile of all horizons (![]() = 1 - 10) estimated for years 1992, 93, and 94. The lower curve shows the
average of the family non-capital income uncertainty profile of all horizons (
= 1 - 10) estimated for years 1992, 93, and 94. The lower curve shows the
average of the family non-capital income uncertainty profile of all horizons (![]() = 1 - 10) estimated for year 1992, 93, and 94. Comparing the two curves, we see the growth of forecast errors'
variances is greater at farther horizons than at nearer horizons, suggesting that the variance of persistent income shocks had increased during this period.
= 1 - 10) estimated for year 1992, 93, and 94. Comparing the two curves, we see the growth of forecast errors'
variances is greater at farther horizons than at nearer horizons, suggesting that the variance of persistent income shocks had increased during this period.
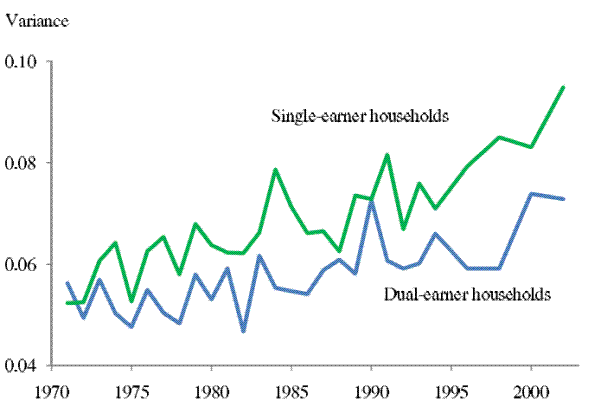
Note: The two series plot the 2-year-ahead income uncertainty for single-earner and dual-earner households, respectively. Dual-earner households are defined as those for which wife's labor earnings is greater than 25% of the head's labor earnings in the base year.
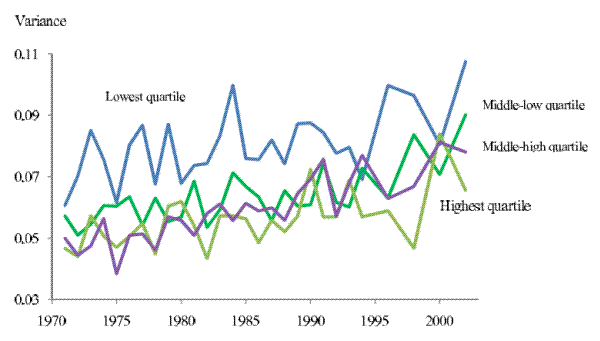
Note: The four series plot the 2-year-ahead income uncertainty for the households in each income quartile, respectively. Income quartile is defined according to the average family non-capital income in year ![]() ,
, ![]() , and
, and ![]() .
.
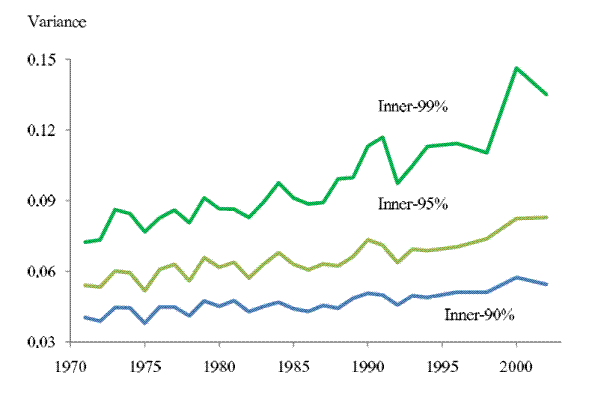
Note: The top curve plots the 2-year-ahead income uncertainty across years using a sample constructed after trimming off the top and bottom 0.5% of the distribution of income growth between ![]() and
and ![]() . The middle curve replicates the curve in the top panel in Figure 1. The bottom curve plots the 2-year-ahead income uncertainty across years using a sample
constructed after trimming off the top and bottom 5% of the distribution of income growth between
. The middle curve replicates the curve in the top panel in Figure 1. The bottom curve plots the 2-year-ahead income uncertainty across years using a sample
constructed after trimming off the top and bottom 5% of the distribution of income growth between ![]() and
and ![]() .
.
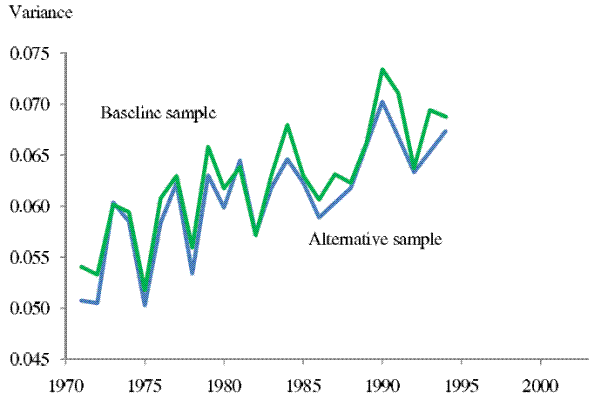
Note: The upper curve replicates the curve in the top panel in Figure 1. The lower curve is the 2-year-ahead income uncertainty series estimated using a sample of households that are in the sample for estimating eq. (4) for ![]() = 10.
= 10.
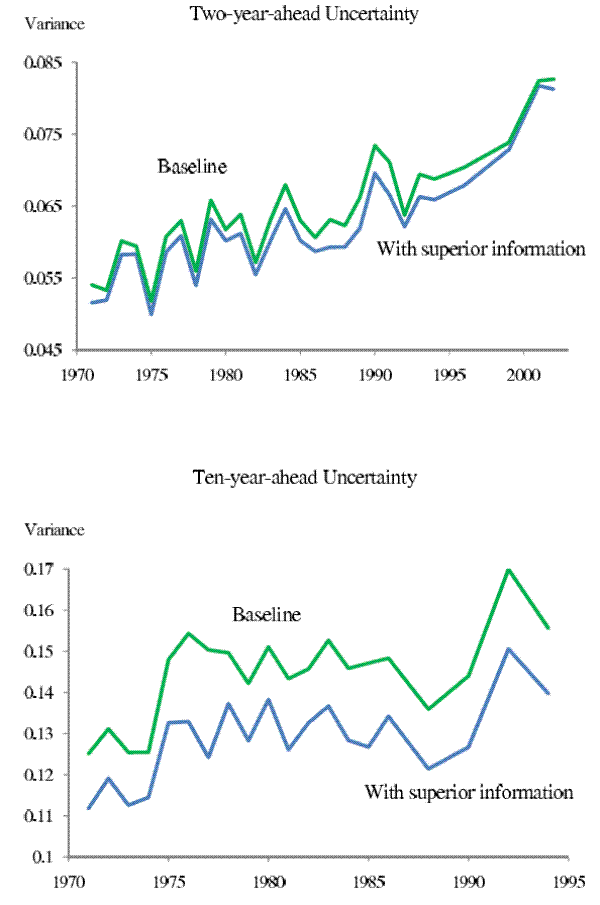
Note: The upper curve in the top panel replicates the curve in the top panel in Figure 1. The lower curve in the top panel is the 2-year-ahead income uncertainty series estimated assuming that the households in year ![]() know their family size, marital status, industry and occupation in year
know their family size, marital status, industry and occupation in year ![]() . The upper curve in the bottom panel replicates the curve in the bottom-right
panel in Figure 1. The lower curve in the top panel is the 10-year-ahead income uncertainty series estimated assuming that the households in year
. The upper curve in the bottom panel replicates the curve in the bottom-right
panel in Figure 1. The lower curve in the top panel is the 10-year-ahead income uncertainty series estimated assuming that the households in year ![]() know their family size, marital status,
industry and occupation in year
know their family size, marital status,
industry and occupation in year ![]() .
.
Footnotes
For helpful comments, we thank Karen Dynan, Michael Palumbo, and seminar participants at the Econometric Society North American Summer Meetings, the Federal Reserve Board, Midwest Macro Meetings, NBER Summer Institute, and the Society of Economic Dynamics Annual Meetings. All remaining errors are our own. Return to Text