
Board of Governors of the Federal Reserve System
International Finance Discussion Papers
Number 914, November 2007 --- Screen Reader
Version*
The Stambaugh Bias in Panel Predictive Regressions
NOTE: International Finance Discussion Papers are preliminary materials circulated to stimulate discussion and critical comment. References in publications to International Finance Discussion Papers (other than an acknowledgment that the writer has had access to unpublished material) should be cleared with the author or authors. Recent IFDPs are available on the Web at http://www.federalreserve.gov/pubs/ifdp/. This paper can be downloaded without charge from the Social Science Research Network electronic library at http://www.ssrn.com/.
Abstract:
This paper analyzes predictive regressions in a panel data setting. The standard fixed effects estimator suffers from a small sample bias, which is the analogue of the Stambaugh bias in time-series predictive regressions. Monte Carlo evidence shows that the bias and resulting size distortions can be severe. A new bias-corrected estimator is proposed, which is shown to work well in finite samples and to lead to approximately normally distributed t-statistics. Overall, the results show that the econometric issues associated with predictive regressions when using time-series data to a large extent also carry over to the panel case. The results are illustrated with an application to predictability in international stock indices.
Keywords: Panel data, pooled regression, predictive regression, stock return predictability
JEL classification: C22, C23, G1
1 Introduction
Predictive regressions are important tools for evaluating and testing economic models. Although tests of stock return predictability, and the related market efficiency hypothesis, are probably the most common application, many rational expectations models can be tested in a similar manner (Mankiw and Shapiro, 1986). Traditionally, forecasting regressions have been evaluated in time-series frameworks. However, with the increased availability of data, in particular international financial and macroeconomic data, it becomes natural to extend the single time-series framework to a panel data setting; for instance, Cohen et al. (2003) and Polk et al. (2006) rely on predictive panel data regressions in some of their analyses.
It is well known that the apparently simple linear regression
model most often used for evaluating predictability in fact raises
some very tough econometric issues. The high degree of persistence
found in many predictor variables, such as the earnings- or
dividend-price ratios in the prototypical stock return forecasting
regression, is at the root of most econometric problems associated
with predictive regressions. The near persistence of the
regressors, coupled with a strong contemporaneous correlation
between the innovations in the regressor and the regressand, causes
standard OLS estimates to suffer from a small sample bias and
normal ![]() tests to have the wrong size; this is the
so-called Stambaugh (1999) bias in predictive regressions.
tests to have the wrong size; this is the
so-called Stambaugh (1999) bias in predictive regressions.
In the panel case, with pooled regressions, it turns out that as long as no fixed effects are included, the pooled estimator is unbiased. However, once one allows for fixed effects in the pooled regression, an analogue of the Stambaugh bias is also present in the panel case. This result can be understood in light of the representation of the bias in predictive regressions derived by Stambaugh. Under the assumption that the predictor variable follows an auto-regressive process, he shows that the bias in the OLS estimate of the slope coefficient in the predictive regression is a function of the bias of the OLS estimate of the auto-regressive coefficient in the predictor variable. It is well known that the bias in the OLS estimator of auto-regressive coefficients is more severe if an intercept is included in the regression equation. Therefore, in the time-series case, the Stambaugh bias is less severe if no intercept is included in the predictive regression. This is, of course, mostly of theoretical interest since in almost all empirical applications an intercept is required. The same idea holds in the panel case; but, rather than differentiating between the case of intercept or no intercept, the relevant cases are now a common intercept or individual intercepts, i.e. fixed effects.
In this paper, I propose a simple bias correction to the fixed effects estimator in pooled predictive regressions. An analogue representation of the time-series Stambaugh bias is also derived. It is shown that the asymptotic bias in the fixed effects estimator in the predictive regression can be expressed as a function of the bias in the pooled fixed effects estimator of the auto-regressive coefficient in the predictor variable. The results in this paper complement those of Hjalmarsson (2007), which also studies the bias in the fixed effects estimator but does not explicitly analyze the connection with the Stambaugh bias in time-series regressions or the direct bias correction procedure suggested here.
The bias-corrected estimator is straightforward to implement. The key parameter on which the bias depends is the auto-regressive root in the regressor variable. The practical implementation of the bias-corrected fixed effects estimator is therefore facilitated by the fact that even though the fixed effects estimator of the auto-regressive coefficient is biased, an alternative unbiased and consistent estimator is readily available. Since the bias-corrected estimator is approximately asymptotically normal, it becomes trivial to perform inference on the slope parameter.
Simulation results show that the bias-corrected estimator works
well in finite samples. These simulations also show the importance
of controlling for the bias in the panel case. The average
rejection rates for the ![]() test corresponding to the
standard fixed effects estimator exceed 75 percent in some cases,
under the null hypothesis of no predictability, and for a nominal
five percent test.
test corresponding to the
standard fixed effects estimator exceed 75 percent in some cases,
under the null hypothesis of no predictability, and for a nominal
five percent test.
As an illustration of the methods derived in this paper, I test for stock return predictability in an international panel of returns from 18 different stock indices using the corresponding dividend- and earnings-price ratios, as well as the book-to-market values, as predictors. The empirical results clearly illustrate the theoretical results in the paper. Based on the results from the standard fixed effects estimator, the evidence in favour of return predictability is very strong, using either of the three predictor variables. However, when using the robust methods developed here, the evidence disappears almost completely. Thus, both the simulation results and the empirical results clearly show that the Stambaugh bias is at least as important in panel regressions as it is in time-series regressions.
The rest of the paper is organized as follows. Section 2 outlines the panel model and shows the Stambaugh bias in panel predictive regressions. Section 3 describes the bias-corrected estimator and Section 4 illustrates the small sample properties of this estimator, as well as those of the pooled estimator without fixed effects. Section 5 shows the results from the empirical application to stock return predictability and offers a brief conclusion. The Appendix outlines the derivations of the main results.
2 The Stambaugh bias
2.1 Model and assumptions
Consider a panel model with dependent variable ![]() ,
, ![]() ,
, ![]() , and
corresponding regressor,
, and
corresponding regressor, ![]() . Here,
. Here, ![]() represents the cross-sectional dimension (e.g. firm or country) and
represents the cross-sectional dimension (e.g. firm or country) and
![]() represents the time-series dimension. The
behavior of
represents the time-series dimension. The
behavior of ![]() and
and ![]() are
modelled as follows,
are
modelled as follows,
| (1) | |
| (2) |
where
![]() . The auto-regressive root of the
regressor is parameterized as being local-to-unity, which captures
the near unit-root behavior of many predictor variables but is less
restrictive than a pure unit-root assumption (e.g. Cavanagh et al.
1995, and Campbell and Yogo, 2006). The model can be seen as a
panel analogue of the time-series models studied by Mankiw and
Shapiro (1986), Cavanagh et al. (1995), Stambaugh (1999), Lewellen
(2004), and Campbell and Yogo (2006), among others.
. The auto-regressive root of the
regressor is parameterized as being local-to-unity, which captures
the near unit-root behavior of many predictor variables but is less
restrictive than a pure unit-root assumption (e.g. Cavanagh et al.
1995, and Campbell and Yogo, 2006). The model can be seen as a
panel analogue of the time-series models studied by Mankiw and
Shapiro (1986), Cavanagh et al. (1995), Stambaugh (1999), Lewellen
(2004), and Campbell and Yogo (2006), among others.
The innovation processes are assumed to satisfy martingale
difference sequences with finite fourth order moments and the
regressor ![]() is generally endogenous in the
sense that
is generally endogenous in the
sense that ![]() and
and ![]() are
contemporaneously correlated. That is, let
are
contemporaneously correlated. That is, let
![]() and
and
![]() be the filtration generated by the innovation processes. Then, for
all
be the filtration generated by the innovation processes. Then, for
all ![]() , and
, and ![]() ,
,
![]() ,
,
![]() and
and
![]() . Finally, it is assumed that the innovations are cross-sectionally
independent.1
. Finally, it is assumed that the innovations are cross-sectionally
independent.1
Let
![]() denote the limiting
process of the scaled regressor
denote the limiting
process of the scaled regressor ![]() . That is, as
. That is, as
![]() ,
,
![]() , where
, where
![]() , defined in the
Appendix, is the standard asymptotic process for a near unit-root
variable. Also, let
, defined in the
Appendix, is the standard asymptotic process for a near unit-root
variable. Also, let
![]() be
the demeaned version of
be
the demeaned version of ![]() and let
and let
![]() , and
, and
![]() .
.
Following the work of Phillips and Moon (1999), results for the
panel estimators are derived using sequential limits, which implies
first keeping ![]() fixed and letting
fixed and letting ![]() go to infinity, and then letting
go to infinity, and then letting ![]() go to infinity.
Such sequential convergence is denoted
go to infinity.
Such sequential convergence is denoted
![]() .2
.2
2.2 The bias in the fixed effects estimator
Let
![]() denote the overall demeaned data and let
denote the overall demeaned data and let
![]() denote the time-series demeaned data. Define
denote the time-series demeaned data. Define
![]() and
and
![]() analogously. The pooled
estimator of
analogously. The pooled
estimator of ![]() when there are no individual
effects, i.e. when
when there are no individual
effects, i.e. when
![]() for all
for all ![]() , is given by
, is given by
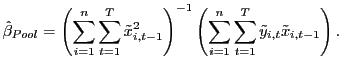
|
(3) |
The fixed effects estimator, allowing for individual effects is given by
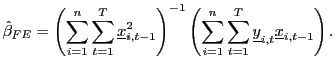
|
(4) |
As shown by Hjalmarsson (2007), and outlined in the Appendix, as
![]() ,
,
| (5) |
under the assumption that
![]() for all
for all ![]() , whereas
, whereas
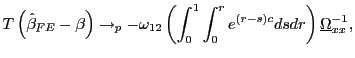
|
(6) |
whenever
![]() .3 Thus, the estimator
without individual effects is asymptotically unbiased and normally
distributed; summing up over the cross-section in the pooled
estimator eliminates the usual near unit-root asymptotic
distributions found in the time-series case. The fixed effects
estimator, on the other hand, suffers from a second order bias; in
practice, this means that the estimator will exhibit a small sample
bias and test statistics will not have standard distributions.
.3 Thus, the estimator
without individual effects is asymptotically unbiased and normally
distributed; summing up over the cross-section in the pooled
estimator eliminates the usual near unit-root asymptotic
distributions found in the time-series case. The fixed effects
estimator, on the other hand, suffers from a second order bias; in
practice, this means that the estimator will exhibit a small sample
bias and test statistics will not have standard distributions.
The intuition behind these results is that when pooling the
data, independent cross-sectional information dilutes the
endogeneity effects and thus potentially alleviates the bias
effects seen in the time-series case; persistent regressors that
are exogenous do not cause any inferential issues. This intuition
holds when no individual intercepts are allowed in the
specification. The bias in the fixed effects estimation arises
because the time-series demeaning induces a correlation between the
innovation processes ![]() and the demeaned
regressors
and the demeaned
regressors
![]() ; intuitively, this
happens because information available after time
; intuitively, this
happens because information available after time ![]() is used in the demeaning of
is used in the demeaning of ![]() .4
.4
2.3 An alternative representation of the fixed effects bias
In the case of a predictive time-series regression, Stambaugh
(1999) shows that the bias in the OLS estimator of the slope
coefficient ![]() in equation (1) is a function
of the bias in the OLS estimator of the
in equation (1) is a function
of the bias in the OLS estimator of the ![]() coefficient
coefficient
![]() in equation (2). Here we derive
an analogue result for the fixed effects estimator in the panel
case.
in equation (2). Here we derive
an analogue result for the fixed effects estimator in the panel
case.
Note that
![]() and let
and let
![]() . The limiting bias of
. The limiting bias of
![]() is thus given by
is thus given by
![]() . Let the fixed effects estimator of
. Let the fixed effects estimator of ![]() be given
by
be given
by
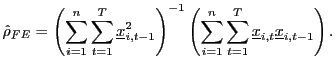
|
(7) |
As shown in Moon and Phillips (2000), the bias in
![]() is in fact equal to
is in fact equal to
![]() . Thus, the limiting bias in the pooled fixed effects estimator of
. Thus, the limiting bias in the pooled fixed effects estimator of
![]() can be written as a function of the
limiting bias in the fixed effects estimator of the auto-regressive
parameter
can be written as a function of the
limiting bias in the fixed effects estimator of the auto-regressive
parameter ![]() . That is,
. That is,
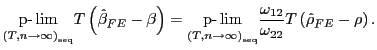
|
(8) |
This is the analogue of the expression for the bias in the
time-series estimator of ![]() given by Stambaugh
(1999). The Stambaugh bias thus carries over directly to pooled
regressions, once fixed effects are included.
given by Stambaugh
(1999). The Stambaugh bias thus carries over directly to pooled
regressions, once fixed effects are included.
In the time-series case, it is well known that standard least squares estimates of auto-regressive coefficients close to unity are much more biased when there is an intercept included in the regression. These effects also carry over to a predictive regression with persistent regressors; if no intercept is included in the regression, the Stambaugh bias will be much smaller. Of course, an intercept is required in almost all time-series applications. The panel data therefore gets us halfway: if only a common intercept is included in the pooled regression, the resulting estimator is well behaved, but once individual intercepts are included the bias shows up in the panel case as well.
3 A bias-corrected estimator
3.1 The infeasible estimator
For a known ![]() , a bias-corrected fixed effects
estimator is given by
, a bias-corrected fixed effects
estimator is given by
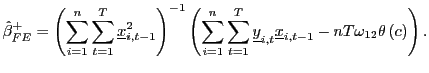
|
(9) |
As shown in the Appendix, as
![]() ,
,
| (10) |
Thus, the bias-corrected estimator
![]() is asymptotically
normally distributed and converges at the same
is asymptotically
normally distributed and converges at the same
![]() rate as the standard pooled
estimator.
rate as the standard pooled
estimator.
3.2 The feasible estimator
In order to implement
![]() in practice, estimates
of
in practice, estimates
of ![]() and
and
![]() are required. The parameter
are required. The parameter
![]() is the average covariance between
the error terms
is the average covariance between
the error terms ![]() and
and ![]() and can be estimated by averaging the estimates of the individual
covariances
and can be estimated by averaging the estimates of the individual
covariances
![]() ; estimates of
; estimates of
![]() can be formed using fitted
residuals from either the pooled or time-series estimates of
equations (1) and
(2).5 In
practice, the implementation of
can be formed using fitted
residuals from either the pooled or time-series estimates of
equations (1) and
(2).5 In
practice, the implementation of
![]() will not be very
sensitive to the exact way of estimating
will not be very
sensitive to the exact way of estimating
![]() . Rather, the crucial parameter is
. Rather, the crucial parameter is
![]() , which is more difficult to estimate
consistently.
, which is more difficult to estimate
consistently.
In the time-series case, consistent estimation of ![]() is not possible. That is,
is not possible. That is, ![]() can be
estimated consistently, but not with enough precision to identify
can be
estimated consistently, but not with enough precision to identify
![]() . This is also the
reason why the Stambaugh bias is difficult to correct in practice
in time-series regressions; for instance, given the lack of precise
knowledge of
. This is also the
reason why the Stambaugh bias is difficult to correct in practice
in time-series regressions; for instance, given the lack of precise
knowledge of ![]() Lewellen (2004) suggests a bias
correction that leads to conservative tests by imposing a maximum
value on the bias under the assumption that
Lewellen (2004) suggests a bias
correction that leads to conservative tests by imposing a maximum
value on the bias under the assumption that ![]() . In the panel data case, it is possible to estimate
. In the panel data case, it is possible to estimate
![]() consistently.
consistently.
As discussed previously, the pooled estimate of ![]() is biased when including fixed effects. This bias
naturally carries over to the estimator of
is biased when including fixed effects. This bias
naturally carries over to the estimator of
![]() as well. However,
as discussed in Moon and Phillips (2000), even when there are fixed
effects in equation (2),
a consistent estimator of
as well. However,
as discussed in Moon and Phillips (2000), even when there are fixed
effects in equation (2),
a consistent estimator of ![]() is obtained by
simply using the plain pooled estimator without any demeaning of
the variables. The estimator of
is obtained by
simply using the plain pooled estimator without any demeaning of
the variables. The estimator of ![]() with
fixed effects is biased for reasons similar to those of the fixed
effects estimator of
with
fixed effects is biased for reasons similar to those of the fixed
effects estimator of ![]() ; by not demeaning the
data, the bias is no longer present. Intuitively, the fixed
effects, or intercepts, in equation (2) can be ignored
in the estimation of
; by not demeaning the
data, the bias is no longer present. Intuitively, the fixed
effects, or intercepts, in equation (2) can be ignored
in the estimation of ![]() because when the root
because when the root
![]() is close to unity, there is
enough variation in
is close to unity, there is
enough variation in ![]() that these
intercepts are of negligible importance. Therefore, let
that these
intercepts are of negligible importance. Therefore, let
![]() be the plain pooled
estimator of
be the plain pooled
estimator of ![]() ,
,
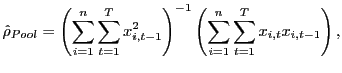
|
(11) |
and define the corresponding estimator of ![]() as
as
![]() Moon and
Phillips (2000) show that this estimator of
Moon and
Phillips (2000) show that this estimator of ![]() is
consistent; again, observe that the data used in estimating
is
consistent; again, observe that the data used in estimating
![]() is not time-series demeaned and that
demeaning the data in the time-series dimension will lead to a bias
in the estimator. A feasible version of
is not time-series demeaned and that
demeaning the data in the time-series dimension will lead to a bias
in the estimator. A feasible version of
![]() is thus given by
substituting
is thus given by
substituting
![]() with
with
![]() in equation
(9).
in equation
(9).
Formally, the asymptotic normality of
![]() is shown only for the
infeasible version of the estimator, which is based on the true
(unknown) value of
is shown only for the
infeasible version of the estimator, which is based on the true
(unknown) value of ![]() . Although it is outside the
scope of this paper to derive the exact limiting distribution of
the feasible version of the estimator, the simulation results below
show that inference based on the assumption of normality works well
also in this case.
. Although it is outside the
scope of this paper to derive the exact limiting distribution of
the feasible version of the estimator, the simulation results below
show that inference based on the assumption of normality works well
also in this case.
3.3 Practical inference
Finally, in order to perform feasible inference using either
![]() or
or
![]() , one only needs
estimates of
, one only needs
estimates of
![]() ,
,
![]() , and
, and
![]() . Natural estimators of
. Natural estimators of
![]() and
and
![]() are given by
are given by
![]() and
and
![]() , respectively. Let
, respectively. Let
![]() be the fitted residuals and
be the fitted residuals and
![]() .6 An estimate of the variance of
.6 An estimate of the variance of
![]() is thus given by
is thus given by
![]() .
.
Similarly, the natural estimator of
![]() is given by
is given by
![]() . However, this estimator of
. However, this estimator of
![]() suffers from the
drawback that it is not necessarily positive. Furthermore,
subtracting off the term coming from the bias correction of the
estimator, without controlling for the possibility that the
feasible bias correction induces additional variance in the
estimator of
suffers from the
drawback that it is not necessarily positive. Furthermore,
subtracting off the term coming from the bias correction of the
estimator, without controlling for the possibility that the
feasible bias correction induces additional variance in the
estimator of ![]() through the sampling error in
through the sampling error in
![]() , may lead to too low an estimate of
the variance of the feasible version of
, may lead to too low an estimate of
the variance of the feasible version of
![]() . That is, as mentioned
above, the exact limiting distribution of the feasible estimator is
unknown, and it therefore seems reasonable to use an estimator that
is more robust. Thus, I propose to use the estimator
. That is, as mentioned
above, the exact limiting distribution of the feasible estimator is
unknown, and it therefore seems reasonable to use an estimator that
is more robust. Thus, I propose to use the estimator
![]() , and estimate the variance of
, and estimate the variance of
![]() by
by
![]() ; this
will result in a more conservative, i.e. larger, estimate of the
variance. In both the pooled and fixed effects cases, therefore,
standard estimators can be used to estimate the variance of the
estimators.
; this
will result in a more conservative, i.e. larger, estimate of the
variance. In both the pooled and fixed effects cases, therefore,
standard estimators can be used to estimate the variance of the
estimators.
Since the distributions of
![]() and
and
![]() are (approximately)
asymptotically normal, implementing tests on the slope coefficient
becomes trivial. The
are (approximately)
asymptotically normal, implementing tests on the slope coefficient
becomes trivial. The ![]() statistic for the estimator
statistic for the estimator
![]() , for instance, will
satisfy
, for instance, will
satisfy
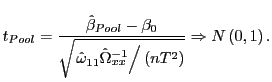
|
(12) |
The ![]() statistic
statistic
![]() corresponding to
corresponding to
![]() is constructed in an
analogous manner using
is constructed in an
analogous manner using
![]() instead of
instead of
![]() . In the simulations and
empirical illustrations below, we also consider the properties of
the
. In the simulations and
empirical illustrations below, we also consider the properties of
the ![]() statistic corresponding to the standard
fixed effects estimator,
statistic corresponding to the standard
fixed effects estimator, ![]() , which again is
identical to
, which again is
identical to ![]() with
with
![]() replaced by
replaced by
![]() ; given the
above discussion,
; given the
above discussion, ![]() will not be standard
normally distributed unless
will not be standard
normally distributed unless
![]() . However, inference using
. However, inference using
![]() and
and ![]() under the normality assumption provides a useful
illustration of the biases that occur if one ignores the issues
resulting from the endogeneity and persistence of the regressor.
under the normality assumption provides a useful
illustration of the biases that occur if one ignores the issues
resulting from the endogeneity and persistence of the regressor.
4 Simulation evidence
To evaluate the small sample properties of the panel data
estimators proposed in this paper, a Monte Carlo study is
performed. In the first experiment, the properties of the point
estimates are considered. Equations (1) and (2) are simulated
for the case with a single regressor. The innovations
![]() are drawn
from normal distributions with mean zero, unit variance, and
correlations
are drawn
from normal distributions with mean zero, unit variance, and
correlations
![]() and
and ![]() . The slope parameter
. The slope parameter ![]() is set equal
to
is set equal
to ![]() and the local-to-unity parameter
and the local-to-unity parameter
![]() is set to
is set to ![]() . The sample
size is given by
. The sample
size is given by ![]()
![]() . The
small value of
. The
small value of ![]() is chosen in order to reflect
the fact that most forecasting regressions are used to test a null
of
is chosen in order to reflect
the fact that most forecasting regressions are used to test a null
of ![]() , and any plausible alternative is
often close to zero. The intercepts
, and any plausible alternative is
often close to zero. The intercepts
![]() are all set equal to zero. All
results are based on 10,000 repetitions.
are all set equal to zero. All
results are based on 10,000 repetitions.
Three different estimators are considered: the pooled estimator
with no fixed effects,
![]() , the fixed effects
estimator,
, the fixed effects
estimator,
![]() , and the bias-corrected
fixed effects estimator,
, and the bias-corrected
fixed effects estimator,
![]() . The bias-correction
term in the estimator
. The bias-correction
term in the estimator
![]() is estimated by
is estimated by
![]() , where
, where
![]() is the panel estimate of the
local-to-unity parameter and
is the panel estimate of the
local-to-unity parameter and
![]() is estimated as
is estimated as
![]() with
with
![]() the covariance between
the residuals from a time-series estimation of equation (1) and the
residuals from the pooled estimation of equation (2).7
the covariance between
the residuals from a time-series estimation of equation (1) and the
residuals from the pooled estimation of equation (2).7
The results are shown in Figure 1.
![]() and
and
![]() are virtually unbiased
whereas
are virtually unbiased
whereas
![]() exhibits a rather
substantial bias when the absolute value of the correlation
exhibits a rather
substantial bias when the absolute value of the correlation
![]() is large. The bias-corrected
estimator,
is large. The bias-corrected
estimator,
![]() , has a slightly less
peaked distribution than the standard pooled estimator,
, has a slightly less
peaked distribution than the standard pooled estimator,
![]() , but overall the bias
correction appears to produce good point estimates.
, but overall the bias
correction appears to produce good point estimates.
The second part of the Monte Carlo study concerns the size and
power of the pooled ![]() tests. The same setup as
above is used, but, in order to calculate the power of the tests,
the slope coefficient
tests. The same setup as
above is used, but, in order to calculate the power of the tests,
the slope coefficient ![]() now varies between
now varies between
![]() and
and ![]() . The tests are
evaluated under the assumption that the limiting distributions are
standard normal; i.e. the null is rejected for absolute test values
greater than
. The tests are
evaluated under the assumption that the limiting distributions are
standard normal; i.e. the null is rejected for absolute test values
greater than ![]() . Panel A in Table 1 shows the
average sizes of the nominal five percent tests under the null
hypothesis of
. Panel A in Table 1 shows the
average sizes of the nominal five percent tests under the null
hypothesis of ![]() for the two sided
for the two sided ![]() tests corresponding to the three different estimators
considered above. Figure 2 shows the
average rejection rates of the five percent two-sided
tests corresponding to the three different estimators
considered above. Figure 2 shows the
average rejection rates of the five percent two-sided ![]() tests, evaluating a null of
tests, evaluating a null of ![]() for
different values of the true
for
different values of the true ![]() ; that is, the
power curves of the tests. Again, the results are based on 10,000
repetitions.
; that is, the
power curves of the tests. Again, the results are based on 10,000
repetitions.
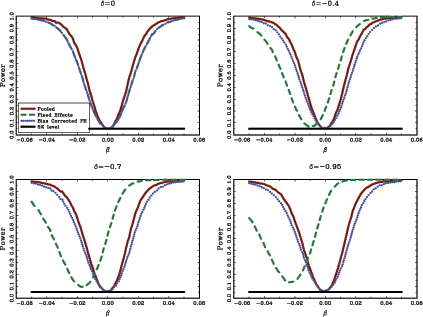
Apart from the test based on the standard fixed effects estimator, the other two tests perform very well in terms of size, with actual rejection rates very close to five percent in the nominal five percent test. Table 1 and the power curves in Figure 2 clearly show the effects of the second order bias in the fixed effects estimator. The test based on the bias-corrected fixed effects estimator has similar power properties to the test based on the standard pooled estimator.
In practice, the assumption that ![]() is
identical for all
is
identical for all ![]() , i.e. that the regressors
all have the same persistence, may seem restrictive. I therefore
briefly analyze the robustness of the bias-correction method
proposed here to deviations from this assumption. In particular,
identical size simulations as those reported in Panel A of Table
1 are shown in
Panel B when the individual local-to-unity parameters,
, i.e. that the regressors
all have the same persistence, may seem restrictive. I therefore
briefly analyze the robustness of the bias-correction method
proposed here to deviations from this assumption. In particular,
identical size simulations as those reported in Panel A of Table
1 are shown in
Panel B when the individual local-to-unity parameters, ![]() , are drawn from a uniform distribution with support
, are drawn from a uniform distribution with support
![]() . As is seen, the
results are very similar, and the bias correction appears fairly
robust to this generalization. The standard pooled estimator should
not be affected, since the assumption of a common parameter
. As is seen, the
results are very similar, and the bias correction appears fairly
robust to this generalization. The standard pooled estimator should
not be affected, since the assumption of a common parameter
![]() is not needed in deriving its asymptotic
result.
is not needed in deriving its asymptotic
result.
In summary, the simulation evidence shows the importance of controlling for the bias arising from fitting individual intercepts in the pooled regression. The bias correction of the fixed effects estimator appears to work well, producing nearly unbiased results and correctly sized tests with good power. In cases where individual effects are not present, the pooled estimator performs well also when the regressors are highly endogenous, as the theory would predict.
5 Empirical illustration and conclusion
To illustrate the methods developed in this paper, I consider
the question of stock return predictability in an international
data set. The data are obtained from the MSCI database and consist
of a panel of total returns for stock markets in 18 different
countries and three corresponding forecasting variables: the
dividend- and earnings-price ratios as well as the book-to-market
values. With varying success, all three of these variables have
been used extensively in tests of stock return predictability for
U.S. data (e.g. Lewellen, 2004, and Campbell and Yogo, 2006), and
to a lesser degree in international data (e.g. Ang and Bekaert,
2007). All three of these forecasting variables are highly
persistent, and since they are all valuation ratios, their
innovations are likely to be highly correlated with the innovations
to the returns process. The data are on a monthly basis and the
returns data span the period 1970.1 to 2002.12, though not all
forecasting variables or all countries are available for this whole
time-period. In particular, I have data for stock indices in the
following countries: Australia, Austria, Belgium, Canada, Denmark,
France, Germany, Hong Kong, Italy, Japan, the Netherlands, Norway,
Singapore, Spain, Sweden, Switzerland, the UK, and the USA.8 The
dividend price ratio
![]() is available for all
countries except Hong Kong and for the entire sample period from
1970.1 onwards. The earnings price ratio
is available for all
countries except Hong Kong and for the entire sample period from
1970.1 onwards. The earnings price ratio
![]() is available for all
countries except Italy and Switzerland, from 1974.12 onwards. The
book-to-market value
is available for all
countries except Italy and Switzerland, from 1974.12 onwards. The
book-to-market value
![]() is available for all
countries from 1974.12 onwards. All returns are expressed in U.S.
dollars, and the dependent variable in the predictive regressions
is given by the excess return over the 1-month U.S. T-bill rate.
Finally, all data are log-transformed.
is available for all
countries from 1974.12 onwards. All returns are expressed in U.S.
dollars, and the dependent variable in the predictive regressions
is given by the excess return over the 1-month U.S. T-bill rate.
Finally, all data are log-transformed.
The results from the pooled forecasting regressions are shown in
Table 2. The estimates
of ![]() and the correlation between the
innovations in the returns and predictor processes show that the
forecasting variables are clearly near unit-root processes and
highly endogenous. The standard pooled fixed effects estimator,
and the correlation between the
innovations in the returns and predictor processes show that the
forecasting variables are clearly near unit-root processes and
highly endogenous. The standard pooled fixed effects estimator,
![]() , delivers highly
significant estimates and clearly rejects the null-hypothesis of no
predictability. Given the high persistence and endogeneity found in
the data, however, these results are likely to be upward biased. As
seen from the estimates based on the bias-corrected fixed effects
estimator,
, delivers highly
significant estimates and clearly rejects the null-hypothesis of no
predictability. Given the high persistence and endogeneity found in
the data, however, these results are likely to be upward biased. As
seen from the estimates based on the bias-corrected fixed effects
estimator,
![]() , significance
disappears when controlling for the bias induced by the time-series
demeaning in the fixed effects estimator;
, significance
disappears when controlling for the bias induced by the time-series
demeaning in the fixed effects estimator;
![]() is implemented in a
manner identical to that described in the simulation section above.
Overall, the case for stock return predictability in this
international data set, using either of the three predictor
variables, must be considered very weak.
is implemented in a
manner identical to that described in the simulation section above.
Overall, the case for stock return predictability in this
international data set, using either of the three predictor
variables, must be considered very weak.
These results are in line with the extensive study of stock return predictability in international data by Hjalmarsson (2007), which suggests that the predictive power of valuation ratios is typically weak in international data. Ang and Bekaert (2007) also find in a smaller international sample, covering France, Germany, the UK and the USA over a similar sample period, that the predictive ability of the dividend-price ratio is very weak in all four of these countries.9
The empirical results illustrate well the difficulties of performing inference in regressions with persistent and endogenous variables, and that these difficulties also prevail when a panel of data, rather than a single time-series, is available. Indeed, judging by the vast difference between the estimates and test statistics resulting from the standard fixed effects estimator and those from the robust estimators, it is clear that the bias effects can be as large in panel estimations as in time-series regressions.
Appendix A: The asymptotic properties of
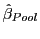 ,
,
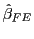 , and
, and
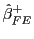
Hjalmarsson (2007) derives the asymptotic properties of
![]() and
and
![]() in a similar setting to the
one considered here, although he does not consider the
bias-corrected estimator
in a similar setting to the
one considered here, although he does not consider the
bias-corrected estimator
![]() . The following
derivations therefore primarily recollect those found in
Hjalmarsson (2007).
. The following
derivations therefore primarily recollect those found in
Hjalmarsson (2007).
Given the conditions on ![]() and
and
![]() , as
, as
![]() ,
,
![]() , where
, where
![]() denotes a two-dimensional Brownian motion. As
denotes a two-dimensional Brownian motion. As
![]() ,
,
![]() , where
, where
![]() . Analogous results hold for the time-series demeaned data,
. Analogous results hold for the time-series demeaned data,
![]() , with
, with ![]() replaced by
replaced by
![]()
First note that
![]() so that the overall demeaning has no asymptotic effects. By
standard results as
so that the overall demeaning has no asymptotic effects. By
standard results as
![]() ,
,
![]() and
and
![]() . Since
. Since ![]() and
and ![]() are
are
![]() across
across ![]() and
and
![]() ,
it follows that as
,
it follows that as
![]() ,
,
![]() and
and
![]() where
where
![$ \Phi_{ux}\equiv E\left[ \left( \int_{0}^{1}dB_{1,i}J_{i}\right) ^{2}\right] $](img248.gif) , by the weak law of large numbers and the central limit theorem,
respectively. Thus, as
, by the weak law of large numbers and the central limit theorem,
respectively. Thus, as
![]()
![]() and
and
![]() . It follows that
. It follows that
![]() . By the Itô isometry,
. By the Itô isometry,
![]() and thus
and thus
![]()
Similarly,
![]() , as
, as
![]() .
However, simple calculations yield that
.
However, simple calculations yield that
![]() , and it follows that
, and it follows that
![]() as
as
![]() .
Thus,
.
Thus,
![]() as
as
![]() .
.
By removing the mean of the term
![]() in the
bias-corrected estimator
in the
bias-corrected estimator
![]() , the central limit
theorem once more applies and, by the same arguments as for
, the central limit
theorem once more applies and, by the same arguments as for
![]() ,
,
![]() where
where
![$ \underline{\Phi}_{ux}=E\left[ \left( \int_{0}^{1}dB_{1,i}\underline{J} _{i}-E\left[ \int_{0}^{1}dB_{1,i}\underline{J}_{i}\right] \right) ^{2}\right] =E\left[ \left( \int_{0}^{1}dB_{1,i}\underline{J}_{i} -\omega_{12}\theta\left( c\right) \right) ^{2}\right] $](img266.gif) . By the Itô isometry, it follows that
. By the Itô isometry, it follows that
![]() and
and
![]() .
.
References
Ang, A., and G. Bekaert, 2007. Stock Return Predictability: Is it There? Review of Financial Studies 20, 651-707.
Campbell, J.Y., and M. Yogo, 2006. Efficient Tests of Stock Return Predictability, Journal of Financial Economics 81, 27-60.
Cavanagh, C., G. Elliot, and J. Stock, 1995. Inference in Models with Nearly Integrated Regressors, Econometric Theory 11, 1131-1147.
Cohen, R., C. Polk, and T. Vuolteenaho, 2003. The Value Spread, Journal of Finance 58, 609-641.
Hjalmarsson, E., 2007. Predicting Global Stock Returns, Working Paper, Federal Reserve Board.
Lewellen, J., 2004. Predicting Returns with Financial Ratios, Journal of Financial Economics, 74, 209-235.
Mankiw, N.G., and M.D. Shapiro, 1986. Do We Reject Too Often? Small Sample Properties of Tests of Rational Expectations Models, Economics Letters 20, 139-145.
Moon, H.R., and P.C.B. Phillips, 2000. Estimation of Autoregressive Roots near Unity using Panel Data, Econometric Theory 16, 927-998.
Phillips, P.C.B., and H.R. Moon, 1999. Linear Regression Limit Theory for Nonstationary Panel Data, Econometrica 67, 1057-1111.
Polk, C., S. Thompson, and T. Vuolteenaho, 2006. Cross-Sectional Forecasts of the Equity Premium, Journal of Financial Economics 81, 101-141.
Stambaugh, R., 1999. Predictive Regressions, Journal of Financial Economics 54, 375-421.
Thompson, S.B., 2006. Simple Formulas for Standard Errors that Cluster by Both Firm and Time, Working Paper, Harvard University.
Table 1: Size Results from the Monte Carlo Study - Panel A (![]() )
)
The table shows the average rejection rates under the null
of ![]() , for the two-sided
, for the two-sided ![]() tests corresponding to the respective estimators; the
nominal size of the tests are
tests corresponding to the respective estimators; the
nominal size of the tests are ![]() percent. The
differing values of
percent. The
differing values of ![]() are given in the top
row of the table and the results are based on
are given in the top
row of the table and the results are based on ![]() repetitions. The sample size used is
repetitions. The sample size used is ![]() and
and ![]() . In Panel A, the local-to-unity
parameter,
. In Panel A, the local-to-unity
parameter, ![]() , is set equal to
, is set equal to ![]() . In Panel B, separate local-to-unity parameters
. In Panel B, separate local-to-unity parameters
![]() are drawn for each
are drawn for each ![]() from a uniform distribution with support [-20,-2].
from a uniform distribution with support [-20,-2].
Estimator | ||||
|---|---|---|---|---|
| | 0.050 | 0.051 | 0.054 | 0.050 |
| | 0.052 | 0.211 | 0.546 | 0.807 |
| | 0.054 | 0.052 | 0.056 | 0.054 |
Table 1: Size Results from the Monte Carlo Study - Panel B (
![]() )
)
Estimator | ||||
|---|---|---|---|---|
| | 0.053 | 0.051 | 0.053 | 0.053 |
| | 0.056 | 0.150 | 0.362 | 0.584 |
| | 0.056 | 0.054 | 0.059 | 0.064 |
Table 2: Results from the Empirical Regressions
The table shows the point estimates and corresponding
![]() statistics (in parentheses) from the
pooled regressions of excess stock returns onto either the dividend
price ratio
statistics (in parentheses) from the
pooled regressions of excess stock returns onto either the dividend
price ratio ![]() , the earnings price ratio
, the earnings price ratio
![]() , or the book-to-market value
, or the book-to-market value
![]() . The first column indicates which of
the three forecasting variables is used and the second and third
columns give the size of the panel used in the regression. The next
two columns give the results for the standard fixed effects
estimator and the bias-corrected fixed effects estimator,
respectively. The final two columns give the estimate of the
local-to-unity parameter in the regressors and the average
correlation between the innovations to the returns and the
regressors, respectively.
. The first column indicates which of
the three forecasting variables is used and the second and third
columns give the size of the panel used in the regression. The next
two columns give the results for the standard fixed effects
estimator and the bias-corrected fixed effects estimator,
respectively. The final two columns give the estimate of the
local-to-unity parameter in the regressors and the average
correlation between the innovations to the returns and the
regressors, respectively.
Variable | ||||||
|---|---|---|---|---|---|---|
| d - p | 17 | 396 | 0.007 (3.840) | -0.002 (-1.254) | -0.004 | -0.771 |
| e - p | 16 | 337 | 0.011 (4.924) | 0.000 (-0.089) | 0.091 | -0.697 |
| b - p | 18 | 337 | 0.008 (4.016) | 0.002 (0.948) | -1.538 | -0.835 |
Figure 1: Estimation results from the Monte Carlo study
The graphs show the kernel density
estimates of the estimated slope coefficients, for samples with
![]() and
and ![]() . The solid
lines, labeled Pooled in the legend, show the results for the
standard pooled estimator without individual intercepts,
. The solid
lines, labeled Pooled in the legend, show the results for the
standard pooled estimator without individual intercepts,
![]() ; the long dashed lines,
labeled Fixed Effects, show the results for the standard fixed
effects estimator,
; the long dashed lines,
labeled Fixed Effects, show the results for the standard fixed
effects estimator,
![]() ; the dotted lines, labeled
Bias Corrected FE, show the results for the bias-corrected fixed
effects estimator,
; the dotted lines, labeled
Bias Corrected FE, show the results for the bias-corrected fixed
effects estimator,
![]() . All results are based
on 10,000 repetitions.
. All results are based
on 10,000 repetitions.
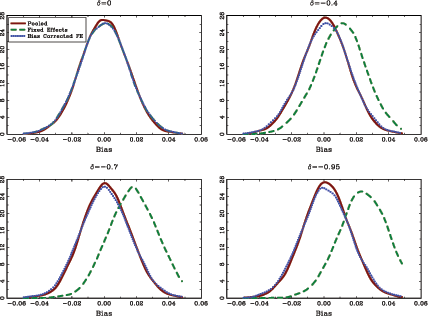
Figure 2: Power Results from the Monte Carlo Study
The graphs show the average rejection rates
for a two-sided ![]() percent
percent ![]() test of
the null hypothesis of
test of
the null hypothesis of ![]() for samples with
for samples with
![]() , and
, and ![]() . The
. The
![]() axis shows the true value of the parameter
axis shows the true value of the parameter
![]() , and the
, and the ![]() axis
indicates the average rejection rate. The solid lines, labeled
Pooled, give the results for the
axis
indicates the average rejection rate. The solid lines, labeled
Pooled, give the results for the ![]() test corresponding
to the standard pooled estimator without individual intercepts,
test corresponding
to the standard pooled estimator without individual intercepts,
![]() ; the long dashed lines, labeled
Fixed Effects, show the results for the
; the long dashed lines, labeled
Fixed Effects, show the results for the ![]() test
corresponding to the standard fixed effects estimator,
test
corresponding to the standard fixed effects estimator,
![]() ; the dotted lines, labeled
Bias Corrected FE, show the results for the
; the dotted lines, labeled
Bias Corrected FE, show the results for the ![]() test
corresponding to the bias-corrected fixed effects estimator,
test
corresponding to the bias-corrected fixed effects estimator,
![]() . The flat lines
indicate the 5% rejection rate. All results are
based on 10,000 repetitions.
. The flat lines
indicate the 5% rejection rate. All results are
based on 10,000 repetitions.
Footnotes
* Helpful comments have been provided by Lennart Hjalmarsson, Randi Hjalmarsson, and George Korniotis, as well as seminar participants at the European Summer Meeting of the Econometric Society in Vienna. Tel.: +1-202-452-2426; fax: +1-202-263-4850; email: [email protected]. The views in this paper are solely the responsibility of the author and should not be interpreted as reflecting the views of the Board of Governors of the Federal Reserve System or of any other person associated with the Federal Reserve System. Return to text
1. In order to highlight the effects of
the Stambaugh bias in panel regressions, the effects of
cross-sectional dependence are not considered. In certain
applications it may be desirable to allow for clustering of the
errors either across time for a given individual ![]() ,
or across individuals (i.e. cross-sectional correlation). As shown
by Thompson (2006), it is straightforward to construct standard
error estimators that control for such clustering across both time
and individuals. His framework could easily be used in the current
context and the details are omitted. Return to text
,
or across individuals (i.e. cross-sectional correlation). As shown
by Thompson (2006), it is straightforward to construct standard
error estimators that control for such clustering across both time
and individuals. His framework could easily be used in the current
context and the details are omitted. Return to text
2. Subject to potential rate restrictions,
such as
![]() , these results can generally
be shown to hold as
, these results can generally
be shown to hold as ![]() and
and ![]() go to
infinity jointly; technical proofs of such joint convergence is not
pursued in the current study, however. Return to text
go to
infinity jointly; technical proofs of such joint convergence is not
pursued in the current study, however. Return to text
3. In the special case of
![]() , it follows easily that
, it follows easily that
![]() is also asymptotically
normally distributed with convergence rate
is also asymptotically
normally distributed with convergence rate ![]() . Return to text
. Return to text
4. Polk et al. (2006) make the same conjecture regarding inference in pooled predictive regressions, namely that independent cross-sectional information dilutes the endogeneity effects, but do not recognize that this intuition fails in the presence of fixed effects. Their regressor is nearly exogenous however, and their empirical conclusions should therefore still be fairly accurate. Return to text
5. Recall that although both the
time-series and pooled fixed effects estimators of ![]() and
and ![]() are generally biased in finite
samples, they are still consistent estimators. Estimators of the
covariance
are generally biased in finite
samples, they are still consistent estimators. Estimators of the
covariance
![]() based on the fitted residuals
will therefore be consistent. Return to
text
based on the fitted residuals
will therefore be consistent. Return to
text
6. Alternatively, the estimator of
![]() could be replaced by a robust
variance estimator to allow for heteroskedasticity in the error
terms. Return to text
could be replaced by a robust
variance estimator to allow for heteroskedasticity in the error
terms. Return to text
7. As mentioned before, the exact
estimation procedure for the
![]() does not play a crucial role
in the properties of
does not play a crucial role
in the properties of
![]() . Return to text
. Return to text
8. Hong Kong is, of course, not a country. Return to text
9. Ang and Bekaert (2007) do argue that the dividend-price ratio has some predictive ability when considered jointly with the short interest rate. Return to text
This version is optimized for use by screen readers. Descriptions for all mathematical expressions are provided in LaTex format. A printable pdf version is available. Return to text