
Board of Governors of the Federal Reserve System
International Finance Discussion Papers
Number 875, September 2006 --- Screen Reader
Version*
A Bivariate Model of Fed and ECB Main Policy Rates
NOTE: International Finance Discussion Papers are preliminary materials circulated to stimulate discussion and critical comment. References in publications to International Finance Discussion Papers (other than an acknowledgment that the writer has had access to unpublished material) should be cleared with the author or authors. Recent IFDPs are available on the Web at http://www.federalreserve.gov/pubs/ifdp/. This paper can be downloaded without charge from the Social Science Research Network electronic library at http://www.ssrn.com/.
Abstract:
This paper studies when and by how much the Fed and the ECB change their target interest rates. I develop a new nonlinear bivariate framework, which allows for elaborate dynamics and potential interdependence between the two countries, as opposed to linear feedback rules, such as a Taylor rule, and I use a novel real-time data set. A Bayesian estimation approach is particularly well suited to the small data sample. Empirical results support synchronization between the central banks and non-zero correlation between magnitude shocks, but they do not support follower behavior. Institutional factors and inflation represent relevant variables for timing decisions of both banks. Inflation rates are important factors for magnitude decisions, while output plays a major role in US magnitude decisions.
Keywords: Monetary Policy, Copula, Hazard Probability, Bivariate Probit Models
JEL Classification: C11, C3, C52, E52
1 Introduction
This paper focuses on the Federal Reserve (Fed) and the European Central Bank (ECB) interest rate feedback rules. In particular, it develops an econometric model that empirically analyzes when a target rate change is adopted (timing), as well as by how much the rate is changed (magnitude change). While central banks' behavior has typically been described with the use of univariate linear interest-rate feedback rules, such as Taylor rules, I exploit a nonlinear bivariate framework, which allows for elaborate dynamics and for potential interactions between the two central banks.
This study is appealing for several reasons. The most important
way the Fed and the ECB express their monetary policy goals is by
setting, respectively, the Federal Funds Target Rate (FFTR) and the
Main Refinancing Operation (MRO) rate.2 These policy rates are important because
they signal the stance of monetary policy, affect investment
decisions, and often have considerable impact on financial markets.
Understanding the way the two central banks set their target rates
and identifying the variables taken into account in the process is
of great interest. Since it started to operate at the beginning of
1999, the ECB, together with the Fed, has been meticulously
scrutinized in the way it conducts monetary policy. Bartolini and
Prati (2003) analyze the Fed and the ECB with particular attention
to institutional structures, policy frameworks, and operational
procedures. Cecchetti and O'Sullivan (2003) compare the central
banks' approaches to the execution of monetary policy. US and EMU
policy rates followed a roughly similar pattern over the period
January 1![]() , 1998 to
March 25
, 1998 to
March 25![]() , 2005 -
see Figure 1. The EMU rate
fluctuates over a narrower range than the US rate; both rates are
characterized by frequent changes in the first half of the sample
and sporadic changes in the middle part of the sample; the FFTR
displays frequent changes also in the last part of the sample,
while the EMU rate is held constant for a long period of
time.3 In
addition, the size and sign of interest rate changes display some
similarities. My analysis addresses these issues by studying when
interest rate changes are implemented and by examining the size and
sign of those changes, with the idea that the two decisions could
carry distinct information and might be triggered by different
variables.4
, 2005 -
see Figure 1. The EMU rate
fluctuates over a narrower range than the US rate; both rates are
characterized by frequent changes in the first half of the sample
and sporadic changes in the middle part of the sample; the FFTR
displays frequent changes also in the last part of the sample,
while the EMU rate is held constant for a long period of
time.3 In
addition, the size and sign of interest rate changes display some
similarities. My analysis addresses these issues by studying when
interest rate changes are implemented and by examining the size and
sign of those changes, with the idea that the two decisions could
carry distinct information and might be triggered by different
variables.4
Open questions in the monetary policy debate are whether in an open economy interest rate feedback rules should include the exchange rate, in addition to inflation and output, and, more generally, how optimal interest rate feedback rules should be designed within an international framework - see, among others, Clarida et al. (2002), Benigno (2002), and Pappa (2004). While the theoretical literature has focused on optimality issues, this papers introduces a new methodology to provide evidence about the interaction between the Fed and the ECB. It does not address issues related to cooperation or potential gains from cooperation. This paper only provides stylized facts about Fed and ECB interest rate feedback rules, exploring the possibility that interdependence could play a role in describing timing and magnitude of interest rate changes.
Moreover, it is not clear that conventional linear interest rate feedback rules are sufficient to explain the complexity of central banks' behavior, especially in the presence of potential interdependences. I therefore investigate the possibility that a nonlinear model could better describe interest rate decisions.
Methodologically, one novelty of the paper is to provide a
Bivariate Autoregressive Conditional Hazard (BACH) model to study
the timing of interest rate changes and a Conditional Bivariate
Ordered (CBO) Probit model to analyze the magnitude of interest
rate changes. The BACH model extends the Autoregressive Conditional
Hazard (ACH) model of Hamilton and Jordà (2002) in order to
account for interdependence between the two central banks. The
timing/duration framework is based on the Autoregressive
Conditional Duration (ACD) model developed by Engle and Russell
(1998a, 1998b) and Engle (2000). Bergin and Jordà (2003)
analyze empirical evidence of monetary policy interdependence
within a set of 14 OECD countries, making use of the Hamilton and
Jordà (2002) model, but they do not analyze the EMU. They
study interdependence by investigating whether the probability of a
change in the domestic target rate at time ![]() depends on a similar decision by a
`` leading country'' at time
depends on a similar decision by a
`` leading country'' at time ![]() (US, Germany or Japan). This implies a hierarchy
between banks and assumes that the leading central bank's decision
is known by the other central bank. Moreover, their setup does not
allow them to recover a joint hazard probability for the two
central banks. My model differs from Bergin and Jordà (2003)
because it is a truly bivariate model which converts the marginal
hazards to a joint hazard probability through the use of a
conditional discrete copula-type representation. This allows me to
treat the Fed and ECB symmetrically and to study interdependence in
the form of decision synchronization and follower behaviors. The
CBO Probit model represents a special case of a Bivariate Ordered
Probit model, where I rescale the probability mass to condition on
the timing decision. It differs from Bergin and Jordà (2003)
because, by rescaling, I am able to study the exact magnitude of
the change (basis points change) as opposed to merely the direction
of change (strong increase, increase, decrease, strong
decrease).
(US, Germany or Japan). This implies a hierarchy
between banks and assumes that the leading central bank's decision
is known by the other central bank. Moreover, their setup does not
allow them to recover a joint hazard probability for the two
central banks. My model differs from Bergin and Jordà (2003)
because it is a truly bivariate model which converts the marginal
hazards to a joint hazard probability through the use of a
conditional discrete copula-type representation. This allows me to
treat the Fed and ECB symmetrically and to study interdependence in
the form of decision synchronization and follower behaviors. The
CBO Probit model represents a special case of a Bivariate Ordered
Probit model, where I rescale the probability mass to condition on
the timing decision. It differs from Bergin and Jordà (2003)
because, by rescaling, I am able to study the exact magnitude of
the change (basis points change) as opposed to merely the direction
of change (strong increase, increase, decrease, strong
decrease).
According to the Taylor-type rule literature, past interest rates, inflation, output gaps, and exchange rate movements are relevant factors in choosing the level of interest rate changes. I analyze whether these variables are important in determining when the Fed and ECB change their interest rates, as well as whether they play a role in explaining the magnitude of the change. Moreover, I study whether the Fed and the ECB synchronize their policies, whether one follows the other, and whether there exists a contemporaneous correlation in the magnitude of their interest rate changes. Timing synchronization of policies is analyzed with the odds ratio, which indicates how much the odds of one bank changing its target rate move when the other bank changes its target. Follower behavior is studied with dummy variables that capture the effect of one country's interest rate decision on the subsequent decisions of the other country. A test on the coefficient of this dummy variable can be interpreted as a test of one country (Granger) causing the other country's interest rate decision, and hence one country following the other country's decision. The correlation between interest rate changes captures the correlation which is left unexplained after traditional explanatory variables have been considered. This paper shows whether the traditional variables that have commonly been used in the literature, are sufficient in explaining timing and magnitude changes of policy rates, and whether the interdependence could be a factor in explaining monetary policies. However, it does not provide a complete answer to the underlying problem about what is in fact the source of the interdependence and whether interdependence is optimal.
Another novel feature of the paper is the empirical application with the use of a real-time data set and the Bayesian estimation. Persuaded that the available information set that central banks observe is of great importance to the decisions they make, I construct and use a real-time data set that includes output and inflation measures, exchange rates and data on target rates and duration between changes. This real time approach to monetary policy has been studied, among others, by Orphanides (2001), who demonstrates that real-time policy recommendations differ from those derived with ex-post revised data.5 Bayesian estimation is not new to monetary policy studies (see Cogley and Sargent 2002, Schorfheide 2006, and Sims and Zha 1998), but, to the best of my knowledge, it has never been applied to ACD- or ACH-type models. The methods used in the paper generally require fairly large samples to produce results. Because of the youth of the ECB and the type of data, the sample used in the paper is small. The Bayesian framework is particularly well suited to this small sample problem, because it allows me to incorporate pre-sample information to better evaluate the available information. I use ten years of data for the Fed and the Bundesbank to elicit the prior, following the view that the German central bank is, among the European central banks, the one that most closely resembles the ECB. Although the Bayesian approach facilitates the estimation, it does not completely eliminate the small sample problem.
Estimation results confirm that ACH-type models need long data samples. However, the timing model results seem to support the hypothesis that institutional factors, such as scheduled meetings of the FOMC and the Governing Council, as well as inflation rates, are important variables in determining timing decisions. Timing synchronization between the two central banks is supported, even after removing the September 2001 coordination attempt. On the other hand, follower behaviors are not supported, rejecting therefore the hypothesis that the ECB follows the Fed or vice versa. Estimation results for the magnitude model illustrate the importance of inflation rates as explanatory variables for both countries. Output turns out to be a major determinant of Fed but not of ECB magnitude decisions, confirming the idea that the ECB's primary objective is to maintain price stability. I find evidence supporting non-zero correlation between the magnitude shocks. The positive correlation suggests that the interest rate feedback rules containing inflation, output, and the exchange rate might not capture the interdependence in the level decisions.
The paper is organized as follows. The next section describes the model. Section 3 describes the data. Section 4 describes the Bayesian implementation and presents empirical results. Section 5 presents a comparison with a traditional Vector Autoregression approach. Section 6 concludes.
2 The Model
For simplicity I refer to the US and the EMU as countries
![]() and
and ![]() . The basic idea is to separate
timing and magnitude of interest rate changes, and to derive a
model capable of accounting for the specific features of both
decisions. I describe timing by binary variables that take the
value one when the target interest rate is changed. Consequently,
magnitude variables take non-zero values only when the timing
binary variable is one.
. The basic idea is to separate
timing and magnitude of interest rate changes, and to derive a
model capable of accounting for the specific features of both
decisions. I describe timing by binary variables that take the
value one when the target interest rate is changed. Consequently,
magnitude variables take non-zero values only when the timing
binary variable is one.
More precisely, let ![]() be a binary variable that takes values
be a binary variable that takes values
![]() according to whether the target rate of country
according to whether the target rate of country
![]() has changed at calendar time
has changed at calendar time
![]()
![$\displaystyle x_{t}^{i}=\left\{ \begin{array}[c]{l} 1\;\;\text{target rate of country }i\;\text{is changed}\\ 0\;\;\text{otherwise} \end{array} \right.$](img23.gif)
|
(1) |
and let
I am interested in studying whether the two central banks decide
to change their target rate (![]() ) and by how much (
) and by how much (![]() ); hence I want to study the joint probability
); hence I want to study the joint probability
![]() , where
, where
![]() is
the information set available at time
is
the information set available at time ![]() . The joint probability can be
rewritten as the product of the marginal distribution of
. The joint probability can be
rewritten as the product of the marginal distribution of
![]() and the conditional
distribution of
and the conditional
distribution of
![]() :
:
| (2) |
so that the resulting log-likelihood can be decomposed into two parts
| (3) |
where
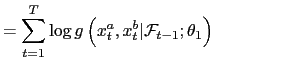 Timing Model
Timing Model |
(4) | |
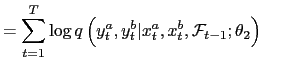 Level Model.
Level Model. |
(5) |
As pointed out by Engle (2000), if
![]() and
and
![]() have no
parameters in common and are variation free, the maximization of
have no
parameters in common and are variation free, the maximization of
![]() is
equivalent to maximizing
is
equivalent to maximizing
![]() and
and
![]() separately.
separately.
I refer to the first part of the likelihood as the Timing Model and to the second part as the Level Model. The former is characterized as a Bivariate Autoregressive Conditional Hazard (BACH) model, while the latter is a Conditional Bivariate Ordered (CBO) Probit model.
I describe both models below.
2.1 Bivariate Autoregressive Conditional Hazard (BACH) Model
The Timing model hinges on the joint
probability of type ![]() and
and
![]() events occurring,
where type
events occurring,
where type ![]() event
occurring means that country
event
occurring means that country
![]() , has decided to change
its target rate. Marginal probability distributions for individual
interest rate decisions have been modeled in the literature with
Autoregressive Conditional Hazard (ACH) models - see Hamilton and
Jordà (2002). The ACH model is derived from the
Autoregressive Conditional Duration (ACD) model proposed by Engle
and Russell (1998a, 1998b) and Engle (2000). The ACD model is
developed in event time6and aims to
explain the duration of spells between events (between two
consecutive trades or quotes, for example). It is called
autoregressive conditional duration because the conditional
expectation of the duration depends upon past durations. Within
this duration framework, bivariate models have been studied, but
none of them is suitable to the present framework. Engle and Lunde
(2003), for example, model the joint likelihood function for trade
and quote arrivals, but they include the possibility that an
intervening trade censors the time between a trade and the
subsequent quote.7 Thus their
model does not serve my purpose. Moreover, unlike them, I adopt
calendar time because it readily allows me to incorporate updated
explanatory variables.
, has decided to change
its target rate. Marginal probability distributions for individual
interest rate decisions have been modeled in the literature with
Autoregressive Conditional Hazard (ACH) models - see Hamilton and
Jordà (2002). The ACH model is derived from the
Autoregressive Conditional Duration (ACD) model proposed by Engle
and Russell (1998a, 1998b) and Engle (2000). The ACD model is
developed in event time6and aims to
explain the duration of spells between events (between two
consecutive trades or quotes, for example). It is called
autoregressive conditional duration because the conditional
expectation of the duration depends upon past durations. Within
this duration framework, bivariate models have been studied, but
none of them is suitable to the present framework. Engle and Lunde
(2003), for example, model the joint likelihood function for trade
and quote arrivals, but they include the possibility that an
intervening trade censors the time between a trade and the
subsequent quote.7 Thus their
model does not serve my purpose. Moreover, unlike them, I adopt
calendar time because it readily allows me to incorporate updated
explanatory variables.
I develop a bivariate model which converts the marginal distribution information, modelled following Hamilton and Jordà (2002), into a joint distribution, by using a conditional discrete copula-type representation.
2.1.1 Marginal Hazard Rates
Define
![]() and
and
![]() to be,
respectively, the cumulative number of country
to be,
respectively, the cumulative number of country ![]() and
and ![]() events as of time
events as of time ![]() , i.e. the number of target rate changes of country
, i.e. the number of target rate changes of country
![]() and
and ![]() as of time
as of time ![]() .
.![]() Following Hamilton and Jordà (2002), I
rewrite the
Following Hamilton and Jordà (2002), I
rewrite the ![]() model
from Engle and Russel (1998) as
model
from Engle and Russel (1998) as
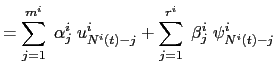
|
(6) | |
where
Define the hazard rate ![]() as the probability of a country
as the probability of a country ![]() event occurring at time
event occurring at time ![]() (the probability that the central
bank of country
(the probability that the central
bank of country ![]() decides to change its target rate), given the information available
up until time
decides to change its target rate), given the information available
up until time ![]() , i.e.
, i.e.
![]() .
The country
.
The country ![]() marginal
hazard rate can be written as
marginal
hazard rate can be written as
| (7) | ||
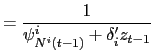
|
where
| (8) | ||
Using the above marginal distributions for the Bernoulli
variables
![]() I want
to construct a joint distribution for
I want
to construct a joint distribution for
![]() . The following section
gives some theoretical background about the discrete copula-type
representation that will allow me to recover the joint hazard of
countries
. The following section
gives some theoretical background about the discrete copula-type
representation that will allow me to recover the joint hazard of
countries ![]() and
and
![]()
2.1.2 Conditional Discrete Copula-Type Representation and Joint Hazard Rates
When marginal distributions are continuous, a joint distribution can be recovered from the marginal distributions with the use of a copula. The beauty of a copula is that for bivariate (multivariate) distributions, the univariate marginals and the dependence structure can be separated, with the copula containing all the dependence information. Since the marginals considered here are discrete, problems arise since copulas are not unique in this case. The way I solve the problem follows Tajar et al. (2001). As the copula contains the dependence information, Tajar et al. disentangle the dependence structure from the Bernoulli marginals.
In addition, I extend the existing results to allow for
conditioning variables. For the purpose of exposition I will assume
below that
![]() represents
the conditioning set (it might contain one or more variables).
represents
the conditioning set (it might contain one or more variables).
Let
![]() be random Bernoulli
variables for which the marginal conditional distributions
be random Bernoulli
variables for which the marginal conditional distributions
![]() and
and
![]() are known.
Associate
are known.
Associate
![]() to a random
couple
to a random
couple
![]() with
discrete uniform marginals such that
with
discrete uniform marginals such that
![$\displaystyle \Pr\left[ u^{a}=0\vert\mathcal{F}\right] =\Pr\left[ u^{a}=1\vert\mathcal{F}\right] =\Pr\left[ u^{b}=0\vert\mathcal{F}\right] =\Pr\left[ u^{b}=1\vert\mathcal{F} \right] =\frac{1}{2}.$](img89.gif)
|
(9) |
Therefore the joint distributions of
![]() and
and
![]() can be
written as follows
can be
written as follows
![$\displaystyle \begin{tabular}[c]{\vert c\vert c\vert c\vert c\vert}\hline $x_{\vert\mathcal{F}}^{a}\mathcal{\ }\diagdown\ x_{\vert\mathcal{F}}^{b}$\ & $0$\ & $1 $ & \\ \hline $0$\ & $h_{00\vert\mathcal{F}}$\ & $h_{01\vert\mathcal{F}}$\ & $1-h_{\vert\mathcal{F}}^{a} $\\ \hline $1$\ & $h_{10\vert\mathcal{F}}$\ & $h_{11\vert\mathcal{F}}$\ & $h_{\vert\mathcal{F}}^{a} $\\ \hline & $1-h_{\vert\mathcal{F}}^{b}$\ & $h_{\vert\mathcal{F}}^{b}$\ & \\ \hline \end{tabular}$](img91.gif)
|
(10) |
![$\displaystyle \begin{tabular}[c]{\vert c\vert c\vert c\vert c\vert}\hline $u_{\vert\mathcal{F}}^{a}\diagdown\ u_{\vert\mathcal{F}}^{b}$\ & $0$\ & $1$\ & \\ \hline $0$\ & $\gamma_{00\vert\mathcal{F}}$\ & $\gamma_{01\vert\mathcal{F}}$\ & $1/2$\\ \hline $1$\ & $\gamma_{10\vert\mathcal{F}}$\ & $\gamma_{11\vert\mathcal{F}}$\ & $1/2$\\ \hline & $1/2$\ & $1/2$\ & \\ \hline \end{tabular} .$](img92.gif)
|
(11) |
The joint probabilities of
![]() and
and
![]() are such
that
are such
that
| (12) |
where
I compute the
![]() s from the
marginals as
s from the
marginals as
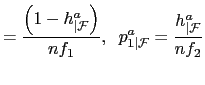
|
(13) | |
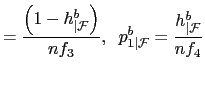
|
(14) |
where
Let the odds ratio
![]() be
be
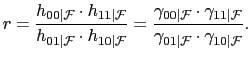
|
(15) |
The odds ratio is a measure of association for binary random
variables. For ease of interpretation, it can be rewritten as
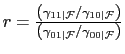 , where the numerator gives the `` odds'' of country
, where the numerator gives the `` odds'' of country
![]() event occurring versus
not occurring given that country
event occurring versus
not occurring given that country ![]() event occurs, while the denominator gives the ``
odds'' of country
event occurs, while the denominator gives the ``
odds'' of country ![]() event
occurring given that country
event
occurring given that country ![]() event does not occur. Thus the odds ratio indicates
how much the odds of country
event does not occur. Thus the odds ratio indicates
how much the odds of country ![]() changing its target rate increase when country
changing its target rate increase when country
![]() changes its target.
Independence is
changes its target.
Independence is ![]()
For a pair of binary random variables with uniform marginals the following property holds:
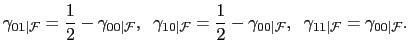
|
(16) |
Therefore,
| (17) |
Hence
This copula-type representation allows me to construct the joint hazard rates to be used in the likelihood.
Some assumptions must be made. First, in my setup, both
marginals depend on ![]() .
According to equation (15), the odds ratio
should also depend on
.
According to equation (15), the odds ratio
should also depend on ![]() I instead assume that
I instead assume that
![]() .
Second, I define the conditioning set
.
Second, I define the conditioning set
![]() as the
information available as of time
as the
information available as of time ![]() The conditioning set must be the same for both
marginal distributions.10
The conditioning set must be the same for both
marginal distributions.10
Therefore, the joint probability of events ![]() and
and ![]() occurring (given
occurring (given
![]() is:
is:
| (18) | ||
where
![$\displaystyle \mathcal{L}_{1}\left( \theta_{1}\right) =\sum_{t=1}^{T}\left\{ \begin{array}[c]{c} \emph{1}\left[ x_{t}^{a}=0,x_{t}^{b}=0\right] \;\log\left( h_{00,t\vert t-1} \right) \\ +\emph{1}\left[ x_{t}^{a}=1,x_{t}^{b}=0\right] \;\log(h_{10,t\vert t-1})\\ +\emph{1}\left[ x_{t}^{a}=0,x_{t}^{b}=1\right] \;\log(h_{01,t\vert t-1})\\ +\emph{1}\left[ x_{t}^{a}=1,x_{t}^{b}=1\right] \;\log(h_{11,t\vert t-1}) \end{array} \right\} .$](img126.gif)
|
(19) |
2.2 Conditional Bivariate Ordered (CBO) Probit
I use a special bivariate ordered Probit model to analyze the
interest rate magnitude changes
![]() and
and
![]() .
.
My framework is a special case of the standard bivariate ordered
Probit, because I am interested in the distribution of ![]() and
and ![]() conditioned on the
information set
conditioned on the
information set
![]() and
conditioned on the timing decision
and
conditioned on the timing decision
![]()
Assume there are two latent variables, one for each country, representing the optimal (but unobserved) target change
| (20) | ||
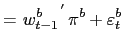
|
(21) |
where
![\begin{displaymath}\Sigma=\left[ \begin{array}[c]{ll} 1 & \rho\ \rho & 1 \end{array}\right] .\end{displaymath}](img143.gif)
If the observable target change ![]() could assume the discrete values
could assume the discrete values
![]() measured in
basis points (bps),
measured in
basis points (bps), ![]() ,
then it would be related to the unobservable optimal target change,
so that
,
then it would be related to the unobservable optimal target change,
so that
![$\displaystyle y_{t}^{i}=\left\{ \begin{array}[c]{ll} s_{1}=-50 & \text{if }\widetilde{y}_{t}^{i}\in(-\infty=c_{0}^{i},c_{1}^{i}]\\ s_{2}=-25 & \text{if }\widetilde{y}_{t}^{i}\in(c_{1}^{i},c_{2}^{i}]\\ s_{3}=0 & \text{if }\widetilde{y}_{t}^{i}\in(c_{2}^{i},c_{3}^{i}]\\ s_{4}=25 & \text{if }\widetilde{y}_{t}^{i}\in(c_{3}^{i},c_{4}^{i}]\\ s_{5}=50 & \text{if }\widetilde{y}_{t}^{i}\in\left( c_{4}^{i},c_{5} ^{i}=\infty\right) . \end{array} \right.$](img146.gif)
|
(22) |
I observe ![]() and
and
![]() and am
interested in the conditional distribution of
and am
interested in the conditional distribution of ![]() and
and ![]() given
given ![]() and
and ![]() . The questions I want to
address are: what is the joint probability of
. The questions I want to
address are: what is the joint probability of ![]() and
and
![]() taking
values
taking
values
![]() ,
respectively, given
,
respectively, given
![]() and given
and given
![]() ?
What is the probability of
?
What is the probability of ![]() being equal to
being equal to
![]() when
when
![]() (no change
for country
(no change
for country ![]() occurs)?
What is the probability of
occurs)?
What is the probability of ![]() being equal to
being equal to
![]() when
when
![]() ?
?
Thus, starting from the bivariate normal distribution that
characterizes
![]() , I want to retrieve
, I want to retrieve
![]() Conditional on
Conditional on ![]() and
and ![]() , the bivariate normal density that
characterizes the distributions of
, the bivariate normal density that
characterizes the distributions of
![]() and
and
![]() is rewritten so as to redistribute the probability mass. Figure
3 contains a visual illustration of the
necessary rescaling.
is rewritten so as to redistribute the probability mass. Figure
3 contains a visual illustration of the
necessary rescaling.
The log likelihood relative to the magnitude decision can be written as
![$\displaystyle \mathcal{L}_{2}\left( \theta_{2}\right) =\sum_{t=1}^{T}\left\{ \begin{array}[c]{c} \emph{1}\left[ x_{t}^{a}=1,x_{t}^{b}=0\right] \;\log P_{10}\\ +\emph{1}\left[ x_{t}^{a}=0,x_{t}^{b}=1\right] \;\log P_{01}\\ +\emph{1}\left[ x_{t}^{a}=1,x_{t}^{b}=1\right] \;\log P_{11} \end{array} \right\}$](img161.gif)
|
(23) |
where ![]() denotes the probability of
denotes the probability of ![]() being equal to
being equal to
![]() when
when
![]() (no change
for country
(no change
for country ![]() occurs),
once I have rescaled to condition on the timing decision
occurs),
once I have rescaled to condition on the timing decision
![]() A similar
interpretation is given to
A similar
interpretation is given to ![]() and
and ![]() 11 A
detailed derivation of these probabilities is presented in the
appendix.
11 A
detailed derivation of these probabilities is presented in the
appendix.
3 Data
The raw data that I use to analyze Fed and ECB decisions are the
dates and size of changes in the FFTR and the MRO rate. Table
1 displays the FFTR level, dates on which
it was changed, and the size of the change. Table 2
displays similar data for the Eurosystem.
Dummies for FOMC and Governing Council meetings have also been
included. Due to the youth of the EMU, my sample spans the period
January 1![]() , 1999 to
March 25
, 1999 to
March 25![]() 2005
for a total of 325 weeks.
2005
for a total of 325 weeks.
As is clear from both table 1 and table 2, the Fed has changed rates more frequently than the ECB. The average duration for the US is about 89 days as opposed to 108 in the EMU. Figure 2 shows that there have been a total of 26 changes in the US and 15 in the EMU. In the US, nine were -50 bps changes, four were -25 bps changes, twelve were +25 bps changes, and one was a +50 bps change. In the EMU, five were -50 bps changes, three were -25 bps changes, five were +25 bps changes, and two were +50 bps changes.
Table 2 deserves a few comments. The
first three dates refer to the period in which the market was
adapting to the new system. In order to limit volatility, the
corridor was narrowed from 250 basis points to 50 basis points on
January 4![]() , 1999.
On January 22
, 1999.
On January 22![]() , the
corridor was set again at 250 bps, but since April 9
, the
corridor was set again at 250 bps, but since April 9![]() , it has been kept at 200 bps.
Main refinancing operations which settled before June
28
, it has been kept at 200 bps.
Main refinancing operations which settled before June
28![]() , 2000 were
conducted on the basis of fixed-rate tenders, in which the ECB
would specify the interest rate in advance and participating
counterparties would bid the amount of money (volume) they were
willing to transact at that rate. A side effect of the system was
chronic overbidding by financial institutions On June 8
, 2000 were
conducted on the basis of fixed-rate tenders, in which the ECB
would specify the interest rate in advance and participating
counterparties would bid the amount of money (volume) they were
willing to transact at that rate. A side effect of the system was
chronic overbidding by financial institutions On June 8![]() 2000, the ECB announced that,
starting with the operation to be settled on June 28
2000, the ECB announced that,
starting with the operation to be settled on June 28![]() , 2000, the main refinancing
operations would be conducted as variable-rate tenders, in which
counterparties would specify both the amount and the interest rate
at which they want to transact.
, 2000, the main refinancing
operations would be conducted as variable-rate tenders, in which
counterparties would specify both the amount and the interest rate
at which they want to transact.
Together with these key policy rates, I create dummy variables
to control for the FOMC schedule in the United States and the
Governing Council schedule in the EMU. These dummies are important
since the majority of interest rate changes happen on these
scheduled meetings. The Fed has made three inter-meeting changes
(January, April and September 2001), while the ECB has changed
rates on a non-meeting day only once, in the immediate aftermath of
September 11![]() ,
2001.
,
2001.
Moreover, I construct a weekly real time data set.12 US variables include the CPI and GDP deflator as inflation measures, GDP growth, industrial production and the unemployment rate as output measures, and the euro/dollar exchange rate. EMU variables include the euro-zone CPI13 and GDP deflator as inflation measures, GDP growth, industrial production and the unemployment rate as output measures, and the euro/dollar exchange rate - see Table 3.14 I take weekly average exchange rate data. Notice that some of these variables are released at a frequency which is lower than weekly, and therefore the latest number can potentially be quite old and stale. This might explain why variables that are updated more frequently, such as the CPI, IP and the unemployment rate, will be preferred to GDP and GDP deflator in the estimation results. Evans (2005) and Aruoba et al. (2006), among others, have focused on deriving daily or weekly estimates of GDP and other macroeconomic variables. Including those `` sophisticated'' variables might be a way to overcome this problem, but it goes beyond the scope of this paper.
The aim of collecting real-time data is to consider all the
available information that the ECB and the Fed have at the
beginning of week ![]() I am
interested in knowing all estimates, provisional or final data
released up until the end (Friday) of week
I am
interested in knowing all estimates, provisional or final data
released up until the end (Friday) of week ![]() In order to construct the
Euro-zone GDP and CPI series, I make use of actual released data as
well as flash estimates. Euro-zone CPI15 data for month
In order to construct the
Euro-zone GDP and CPI series, I make use of actual released data as
well as flash estimates. Euro-zone CPI15 data for month ![]() are released in the second half of
month
are released in the second half of
month ![]() The same release
schedule also applies to the United States. CPI flash estimates
represent a considerable enhancement in the available information
because they are released within
The same release
schedule also applies to the United States. CPI flash estimates
represent a considerable enhancement in the available information
because they are released within ![]() to
to ![]() days
from the end of month
days
from the end of month ![]() Thus I include flash estimates as soon as they become available and
substitute those with final data when they are released. Whereas in
the United States GDP data for the quarter ending in month
Thus I include flash estimates as soon as they become available and
substitute those with final data when they are released. Whereas in
the United States GDP data for the quarter ending in month
![]() become available as
early as the end of month
become available as
early as the end of month ![]() , in the euro area they used to become available at
the beginning of month
, in the euro area they used to become available at
the beginning of month ![]() . Flash estimates improve the available information
because flash GDP estimates are now released as early as the middle
of month
. Flash estimates improve the available information
because flash GDP estimates are now released as early as the middle
of month ![]() Flash
estimates for the CPI started being released in November 2001, for
the October 2001 CPI. Flash estimates for GDP only began in May
2003, for 2003:Q1 GDP.16
Unemployment data relative to month
Flash
estimates for the CPI started being released in November 2001, for
the October 2001 CPI. Flash estimates for GDP only began in May
2003, for 2003:Q1 GDP.16
Unemployment data relative to month![]() are released in the first week of month
are released in the first week of month ![]() in the United States and in the
first week of month
in the United States and in the
first week of month ![]() in
the EMU.
in
the EMU.
I also construct two decision dummy variables that will be used to assess interdependence in timing decisions. The United States dummy variable takes the value one from the last EMU interest rate change until the first FOMC meeting. The EMU dummy variable takes the value one from the last US interest rate change until the second subsequent Governing Council meeting. The asymmetry comes from the fact that Governing Council meetings are more frequent than FOMC meetings (especially in the first part of the sample, when the Governing Council was meeting every two weeks; the FOMC meets only eight times a year), and I want to allow sufficient time for both central banks to react to policy changes.
4 Estimation Strategy and Empirical Results
4.1 Bayesian Implementation17
I conduct the estimation in a Bayesian framework. A Bayesian
model is characterized by the probability distribution of the data,
![]() ,
and by the prior distribution
,
and by the prior distribution
![]() . I look at the probability of
. I look at the probability of
![]() given the
realized
given the
realized ![]() :
:
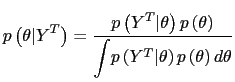
|
(24) |
so that the parameters
I use the posterior odds test to select between models. Let
![]() be the null
hypothesis with prior probability
be the null
hypothesis with prior probability
![]() The
posterior odds of
The
posterior odds of ![]() versus
versus ![]() are
are
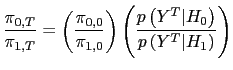
|
(25) |
where
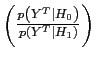 is the Bayes factor containing the sample evidence and
is the Bayes factor containing the sample evidence and
4.1.1 Choice of Priors
I choose the priors for the parameters according to a number of considerations. I assume parameters are a priori independent of each other. Parameter restrictions are implemented by appropriately truncating the distribution or by redefining the parameters to be estimated.
Table 4 describes the distributional form, means and 90 confidence intervals of the BACH model priors. According to the Taylor rule literature, policy rates depend on their lagged values, on some measures of inflation and output deviations, and on exchange rate depreciation. Thus I assume that the probability of a rate change depends on the absolute deviation of inflation and output from a norm, and on the absolute exchange rate depreciation. I take absolute deviations because I want the probability of an interest rate change to increase with large deviations, regardless of their signs.
Let
![]() and
and ![]() be, respectively, the
interest rate, inflation rate, a measure of output growth, and
nominal exchange rate depreciation. Also, let
be, respectively, the
interest rate, inflation rate, a measure of output growth, and
nominal exchange rate depreciation. Also, let
![]() and
and
![]() be the
optimal level of inflation and output growth, and
be the
optimal level of inflation and output growth, and
![]() be
the smoothing term. Then we can write the Taylor rule as22
be
the smoothing term. Then we can write the Taylor rule as22
| (26) |
I should also include the lagged interest rate among the covariates. However, the duration in the model generates the dynamics that a lagged interest rate would normally generate. I will, however, verify that this is in fact the case. FOMC and Governing Council meeting dummies have also been included as covariates, following Hamilton and Jordà (2002).
I choose priors for ![]() ,
, ![]() and the constant
and the constant ![]() in
equation 8, so that the marginal hazard rate,
when all the covariates are at their average value,23 matches the probability of an interest
rate change over the ten-year pre-sample period January
1
in
equation 8, so that the marginal hazard rate,
when all the covariates are at their average value,23 matches the probability of an interest
rate change over the ten-year pre-sample period January
1![]() , 1989 to December
31
, 1989 to December
31![]() ,
,![]() 1998. I approximate this
probability by dividing the number of changes by the number of
periods. Since I do not have any pre-sample data for the ECB, I use
information about the German Lombard rate. I choose
1998. I approximate this
probability by dividing the number of changes by the number of
periods. Since I do not have any pre-sample data for the ECB, I use
information about the German Lombard rate. I choose ![]() ,
, ![]() and
and ![]() such that
such that
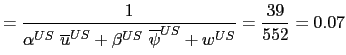
|
(27) | |
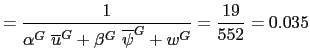
|
(28) |
where
I choose priors for the covariates ![]() using the following
relationships:
using the following
relationships:
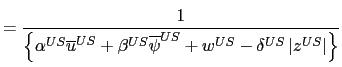
|
(29) | |
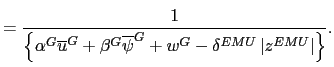
|
(30) |
In particular, assuming all the other variables are at their
average value, the prior for US inflation implies a ![]() increase in the probability
(from
increase in the probability
(from ![]() to
to ![]() ) when the inflation rate
increases or decreases by
) when the inflation rate
increases or decreases by ![]() basis points.24
Similarly, the prior on the output growth implies that a
basis points.24
Similarly, the prior on the output growth implies that a
![]() basis point change
increases the probability by
basis point change
increases the probability by ![]() These probability changes might seem small
compared to the Taylor rule coefficients that have been used in the
literature. However, due to the non-linearity in the model, when
taken together, they have a considerable effect. The asymmetry in
treating inflation and output is justified by the fact that
inflation always has a greater coefficient in the Taylor rule
literature. Very similar priors are given to EMU inflation and
output. The meeting dummy coefficients
These probability changes might seem small
compared to the Taylor rule coefficients that have been used in the
literature. However, due to the non-linearity in the model, when
taken together, they have a considerable effect. The asymmetry in
treating inflation and output is justified by the fact that
inflation always has a greater coefficient in the Taylor rule
literature. Very similar priors are given to EMU inflation and
output. The meeting dummy coefficients
![]() are not treated equally in the two countries, due to the greater
number of EMU meetings. Notice that, since I expect all the
coefficients to be positive,25 I
parameterized them as Gamma distributions.
are not treated equally in the two countries, due to the greater
number of EMU meetings. Notice that, since I expect all the
coefficients to be positive,25 I
parameterized them as Gamma distributions.
I compute the mean of the odds ratio prior
![]() by
using the pre-sample proportions for scenarios
by
using the pre-sample proportions for scenarios ![]() ,
, ![]() ,
, ![]() and
and ![]() , over the
period January 1
, over the
period January 1![]() 1989 to December 31
1989 to December 31![]() 1998. Again, I use Germany instead of the EMU.
The pre-sample odds ratio is about
1998. Again, I use Germany instead of the EMU.
The pre-sample odds ratio is about ![]() .
.
I also choose priors for the Conditional Bivariate Ordered
Probit based on pre-sample information. The means of the cut points
are those that I would expect if I were to estimate an ordered
Probit with no covariates, based on the data 1989-1998 for US and
Germany. The first cut point
![]() , hence the
Normal distribution. The other coefficients are appropriately
redefined so as to guarantee that the cut points are ordered.
Priors for US inflation and output coefficients are centered at
values that have been commonly estimated for Taylor-type rules -
see equation 26. Table 5
describes the distributional form, means and 90%
confidence intervals of the priors of the CBO Probit model.
, hence the
Normal distribution. The other coefficients are appropriately
redefined so as to guarantee that the cut points are ordered.
Priors for US inflation and output coefficients are centered at
values that have been commonly estimated for Taylor-type rules -
see equation 26. Table 5
describes the distributional form, means and 90%
confidence intervals of the priors of the CBO Probit model.
4.2 BACH Estimates
I estimate a number of different specifications in order to
asses which variables are in fact relevant for US and EMU timing
decision. Table 3 shows the covariates I
have considered. The basic specification I have selected includes
meeting dummies, and inflation and unemployment absolute
deviations.26 Table
6 reports 90% posterior probabilities
intervals and posterior means as point estimates. Figure 4 shows prior and posterior densities. As expected,
the estimates confirm the need of a longer sample for ACD-type
models,27 showing
that the information contained in the data is not always adequate
to significantly amend the prior. Duration and expected duration
parameters (
![]() and
and
![]() ), in particular, confirm this
result. While tables 6 and 8 display means and posterior probability
intervals for
), in particular, confirm this
result. While tables 6 and 8 display means and posterior probability
intervals for ![]() and
and
![]() , figure 4 exhibits their prior and posterior densities
under a parameterization that shows the relevance of both
coefficients in terms of duration persistence.28 The constant parameters for both the
US and the EMU turn out to have a higher value compared to the
prior means, possibly meaning a lower average probability over the
sample. The increased value of the constant terms goes together
with a smaller value for the coefficients of the other covariates.
Nevertheless, the FOMC meeting dummy has a bigger coefficient than
the Governing Council meeting dummy (
, figure 4 exhibits their prior and posterior densities
under a parameterization that shows the relevance of both
coefficients in terms of duration persistence.28 The constant parameters for both the
US and the EMU turn out to have a higher value compared to the
prior means, possibly meaning a lower average probability over the
sample. The increased value of the constant terms goes together
with a smaller value for the coefficients of the other covariates.
Nevertheless, the FOMC meeting dummy has a bigger coefficient than
the Governing Council meeting dummy (![]() ): given that FOMC meetings are less frequent than
Governing Council meetings, I expect a bigger increase in the
probability of a rate change when the FOMC meets. For both
countries inflation seems to play a bigger role than unemployment
in determining the timing of a rate change.
): given that FOMC meetings are less frequent than
Governing Council meetings, I expect a bigger increase in the
probability of a rate change when the FOMC meets. For both
countries inflation seems to play a bigger role than unemployment
in determining the timing of a rate change.
An interesting by-product of the BACH model is that it generates persistence in the interest rate without including past interest rates. The basic specification with meeting dummies, inflation and output has been tested against a specification that also includes lagged interest rates, and the former has been selected.29 I have also tested for a specification that includes exchange rate data in the covariates. Once again the specification with meeting dummies, inflation and output has been favoured.30Finally, unemployment is favoured over industrial production and GDP growth as a measure of output, and the CPI is preferred to the GDP deflator as a measure of inflation (results omitted).
4.3 Conditional Bivariate Ordered Probit Estimates
The basic specification of the CBO Probit model that I estimate includes inflation, output and exchange rates. Table 7 reports 90 posterior probabilities intervals and posterior means as point estimates, figure 5 shows prior and posterior densities of the estimated parameters. Exchange rates do not play a very significant role. On the other hand, inflation and industrial production results exhibit interesting features. While inflation was a major factor in explaining US interest rate timing decisions, it is industrial production that seems to play the foremost role in explaining the size of changes in the US interest rate. Industrial production and inflation posterior means are, respectively 1.67 and 0.82. EMU magnitude results show that, as for the timing results, inflation is crucial and industrial production has a minor role. This is expected in view of the fact that the ECB primary objective is to maintain price stability; a policy of targeting output growth would probably be more problematic, given the intrinsic differences in the economies of the EMU countries. The correlation coefficient has a posterior mean of 0.28, with a 90% interval equal to [ 0.13, 0.55 ].
4.4 Interdependence
The interdependence test of US and EMU timing decisions is
twofold: on the one hand, I am interested in assessing ``
contemporaneous'' interdependence, after controlling for each
countries' macroeconomic conditions, which I refer to as
synchronization; on the other hand I
investigate the possibility of follower
behaviors, after controlling for each countries'
macroeconomic conditions. Assessing synchronization involves testing whether the odds
ratio is different from ![]() (
(![]() meaning independence).
The odds ratio indicates how much the odds of one country changing
its target rate increase when the other country changes its target.
Columns four and five in table 6
displays the estimation results for the independence setup. Setting
the odds ratio to 1 does not significantly affect the other
coefficients: both means and 90% probability intervals are very
similar to the basic specification. However, as shown in table
9, the posterior odds of the null
hypothesis
meaning independence).
The odds ratio indicates how much the odds of one country changing
its target rate increase when the other country changes its target.
Columns four and five in table 6
displays the estimation results for the independence setup. Setting
the odds ratio to 1 does not significantly affect the other
coefficients: both means and 90% probability intervals are very
similar to the basic specification. However, as shown in table
9, the posterior odds of the null
hypothesis ![]()
![]() versus
the alternative, shows some evidence against the null. Thus the
model seems to give some indication in favour of synchronization
between the two target rates, after controlling for each countries'
macroeconomic conditions. There was in fact a clear attempt at
coordination after September 11
versus
the alternative, shows some evidence against the null. Thus the
model seems to give some indication in favour of synchronization
between the two target rates, after controlling for each countries'
macroeconomic conditions. There was in fact a clear attempt at
coordination after September 11![]() , 2001, episode after which both the Fed and the
ECB lowered their target rates by 50 basis points.
, 2001, episode after which both the Fed and the
ECB lowered their target rates by 50 basis points.
Follower behaviors are studied by including the two decision dummies to account for the effect of the other country's decisions (see chapter 3 for a more detailed explanation of the dummy variables). Table 8 shows that estimation results are not affected significantly by including the two dummy variables. Table 9 suggests that the posterior odds ratio supports the null hypothesis of no follower behaviors. I obtain the same results by including only one dummy variable at a time. Table 9 displays the posterior odds ratio for these models.
I analyze interdependence in the CBO Probit framework by testing whether the correlation coefficient between the latent variables in equations (20) and (21) is different from zero. Table 7 presents the estimation results for this scenario. The posterior odds ratio in table 10 shows strong evidence against the model specification in which the correlation is set to zero. The correlation coefficient measures the correlation between the shocks31 in the unobservable variable equations - the omitted factors. The positive correlation seems to suggest that the interest rate feedback rules containing past interest rates, inflation, output, and the exchange rate might not capture the interdependence in the level decisions.
The BACH model with the odds ratio set to ![]() and the CBO Probit Model with
and the CBO Probit Model with
![]() can be thought
of as the Hamilton and Jordà (2002) univariate model
estimated for both the Fed and the ECB. Please note that results
for the US cannot be compared because the sample is different in
term of length and included variables. Moreover Hamilton and
Jordà (2002) do not use a real time data set.
can be thought
of as the Hamilton and Jordà (2002) univariate model
estimated for both the Fed and the ECB. Please note that results
for the US cannot be compared because the sample is different in
term of length and included variables. Moreover Hamilton and
Jordà (2002) do not use a real time data set.
4.5 Omitting September 11th
After the terrorist attack of September 11![]() , 2001, both the Fed and the ECB,
as well as other central banks, lowered their target interest rates
by 50 basis points on a non-meeting day, Monday September
17
, 2001, both the Fed and the ECB,
as well as other central banks, lowered their target interest rates
by 50 basis points on a non-meeting day, Monday September
17![]() , 2001. In my
sample, the Fed has made three inter-meeting changes (January,
April and September 2001), while the ECB has changed rates on a
non-meeting day only in this particular occasion. Given the
extraordinary nature of the event that triggered the September
17
, 2001. In my
sample, the Fed has made three inter-meeting changes (January,
April and September 2001), while the ECB has changed rates on a
non-meeting day only in this particular occasion. Given the
extraordinary nature of the event that triggered the September
17![]() rate cuts, it
makes sense to check for robustness of the results by excluding the
September 2001 change, which simply represented a contemporaneous
reaction to a common shock.
rate cuts, it
makes sense to check for robustness of the results by excluding the
September 2001 change, which simply represented a contemporaneous
reaction to a common shock.
Results for the BACH model are displayed in table 11. All parameters have posterior means and 90% intervals very similar to those of the original data set (with 9/17). The odds ratio displays a lower value, as expected from removing the 9/17 episode. However, the posterior odds ratio still shows some evidence in favour of a model with positive dependence.
Results for the CBO Probit also suggest a lower correlation once we exclude the September 2001 inter-meeting change from the sample. However the model with positive correlation is still favoured to a model with zero correlation - see table 12.
5 A Vector Autoregression Comparison
To check the goodness of fit of the model described in the paper, I compare it with a linear reduced form vector autoregression (VAR) of the form:
| (31) | ||
| (32) |
where
To make the VAR structure in (31)
comparable to the BACH-CBO Probit model, an identification scheme
that resembles the specification underlying the BACH-CBO Probit
equations should be implemented. This would require the interest
rate shock in country ![]() to affect the interest rate in country
to affect the interest rate in country ![]() and vice
versa, consistent with the assumption in the BACH Model that
there could be some contemporaneous relation between the two
interest rates. I also implement exclusion restrictions in the VAR
in equation (31), so that it resembles
closely the specification of the BACH and CBO Probit
models.33 The
reduced form that I estimate is:
and vice
versa, consistent with the assumption in the BACH Model that
there could be some contemporaneous relation between the two
interest rates. I also implement exclusion restrictions in the VAR
in equation (31), so that it resembles
closely the specification of the BACH and CBO Probit
models.33 The
reduced form that I estimate is:
| (33) | ||
That is, US (Euro-zone) inflation, US (Euro-zone) output, and the exchange rate are included in the US (Euro-zone) interest rate equation together with the other country's lagged interest rate. US (Euro-zone) inflation and output only depend on past values of US (Euro-zone) variables and on the exchange rate. The latter follows an AR(1) process.
The VAR model can be cast in the form of a seemingly unrelated regression equations (SURE) model as
![$\displaystyle \underset{\widetilde{x}}{\underbrace{\left[ \begin{array}[c]{c} \widetilde{x}^{1}\\ \\ \widetilde{x}^{7} \end{array} \right] }}$](img266.gif)
|
![$\displaystyle =\underset{\widetilde{X}}{\underbrace{\left[ \begin{array}[c]{ccc} \widetilde{X}^{1} & & \\ & \ddots & \\ & & \widetilde{X}^{7} \end{array} \right] }}\ \alpha+\underset{\widetilde{\varepsilon}}{\underbrace{\left[ \begin{array}[c]{c} \widetilde{\varepsilon}_{t}^{1}\\ \vdots\\ \widetilde{\varepsilon}_{t}^{7} \end{array} \right] }}$](img267.gif)
|
(34) |
where the
Under the Litterman prior
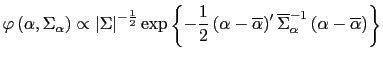
|
(35) |
the posterior densities are given by36
| (36) | ||
![$\displaystyle =\left[ \left( \widetilde{X}^{\prime}\ \Sigma _{e}^{-1}\otimes I_{T}\ \widetilde{X}\right) +\overline{\Sigma}_{\alpha} ^{-1}\right] ^{-1}.$](img289.gif)
|
(37) |
I use the posterior odds
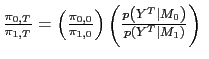 to compare the BACH-CBO Probit Models (
to compare the BACH-CBO Probit Models (![]() ) to the VAR specification
(
) to the VAR specification
(![]() ). As shown in
table 13 the former outperforms the
latter, suggesting that non linear dynamics might be important for
understanding the evolution of policy rates.
). As shown in
table 13 the former outperforms the
latter, suggesting that non linear dynamics might be important for
understanding the evolution of policy rates.
6 Conclusions
In this paper I have derived and estimated with Bayesian techniques a bivariate model to account for interdependence between Fed and ECB decisions. I have operationalized interest rate timing decisions with a Bivariate Autoregressive Conditional Hazard (BACH) model and magnitude decisions with a Conditional Bivariate ordered (CBO) Probit model. The timing model yields evidence supporting the hypothesis that (i) institutional factors (scheduled FOMC and Governing Council meetings) and inflation rates are relevant variables for both central banks, (ii) output plays a minor role in timing decisions, and (iii) there exists synchronization but no follower behavior. The magnitude model illustrates that (i) inflation rates are the most important variables in determining interest rate levels, (ii) output plays a prime role for US magnitude decisions, and (iii) the posterior odds ratio favors a model with correlation in magnitude changes. I also find that, based on the posterior odds ratio, my model outperforms a linear VAR specification.
My findings are necessarily based on a relatively small sample; however, there seems to be evidence suggesting that timing and magnitude changes are in fact quite interesting issues. The paper provides evidence in favor of interaction in US and EMU interest rate timing and magnitude decisions, after controlling for traditional variables that have commonly been used in the literature. The paper offers a new methodology to analyze interdependence, however, it does not provide a complete answer to the underlying problem about what is in fact the source of the interdependence and whether interdependence is optimal. Identifying where the interdependence comes from and analyzing whether results are robust to the inclusion of a larger set of explanatory variables remain important topics for further research.
Bibliography
- Aruoba, S.B., Diebold, F.X. and
Scotti, C., `` Real-Time Estimate of Business Conditions,''
mimeo
- Bartolini, L. and Prati, A,
2003, `` The Execution of Monetary Policy: A Tale of Two Central
Banks,'' Economic Policy, 37,
437-467
- Bauwens L., Lubrano M. and Richard J.F.,
1999, `` Bayesian Inference in Dynamic Econometric Models,'' Oxford
University Press, New York
- Benigno, P., 2002, `` A
Simple Approach to International Monetary Policy Coordination,''
Journal of International Economics, 57,
177-196
- Bergin, P.R. and Jordà, O.,
2003, `` Measuring Monetary Policy Interdependence,'' Journal of International Money and Finance, 23,
5
- Canova, F., forthcoming, ``
Methods for Applied Macroeconomic Research,'' Princeton University
Press.
- Cecchetti, S. and O'Sullivan, R.,
2003, `` The European Central Bank and the Federal Reserve,''
Oxford Review of Economic Policy, 19,
1
- Clarida, R.,
Galí, J., Gertler, M., 2002, `` A simple framework for
international monetary policy analysis,'' Journal of Monetary Economics 49, 879-904
- Cogley, T.
and Sargent,T. J., 2002, `` Evolving Post World War II U.S.
Inflation Dynamics,'' NBER Macroeconomics Annual 16
- Corsetti, G., Pesenti, P ,2003, `` The
International dimension of optimal monetary policy,'' Journal of Monetary Economics, 52, 2, 281-305
- Engle, R., 2000, `` The
Econometrics of Ultra-High Frequency Data,'' Econometrica, 68, 1-22
- Engle, R. and
Lunde, A., 2003, `` Trades and Quotes: A Bivariate Point Process,''
Journal of Financial Econometrics, 1,
159-188
- Engle R.F. and Russel J., 1997, ``
Forecasting the Frequency of Changes in Quoted Foreign Exchange
Prices with the Autoregressive Conditional Duration Model,"
J. Empirical Finance, 4, 187-212
- Engle R.F. and Russell J., 1998, ``
Autoregressive Conditional Duration: A New Model for Irregularly
Spaced Transaction Data,'' Econometrica, 66, 1127-1162
- Engle R.F. and Russell J., 2005, ``
A Discrete-State Continuous-Time Model of Financial Transactions
Prices: the ACM-ACD Model,'' Journal of
Business and Economic Statisitcs
- Ehrmann, M. Fratzscher, M., 2003,
`` Monetary Policy Announcements and Money Markets: A Transatlantic
Perspective,'' International Finance,
6, 309-28.
- Ehrmann, M. Fratzscher, M., 2005,
`` Equal size, equal role? Interest rate interdependence between
the euro area and the United States,'' Economic Journal, 115, 930-950
- European Central Bank, 2002, ``
The Single Monetary Policy in the Euro Area. General Documentation
on Eurosystem Monetary Policy Instruments and Procedures''
- Evans, C. L., 1998, ``
Real-Time Taylor Rules and the Federal Funds Futures Market,''
Federal Reserve Bank of Chicago Economic Perspectives (Third
Quarter), 44-55
- Evans, M. D. D., 2005, ``
Where are we now? Real-Time Estimates of the Macro Economy,''
The International Journal of Central
Banking, 1, 2, 127-175
- Faust, J., Rogers, J. H. and
Wright, J.H., 2001, `` An Empirical Comparison of Bundesbank and
ECB Monetary Policy Rules'', IFDP
705
- Gaspar, V., Quiroz-Perez,
G., Sicilia, J., 2001, `` The ECB Monetary Policy Strategy and the
Money Market,'' International Journal of
Finance and Economics, 6, 4, 325-342
- Griffiths, W.,2003, ``
Bayesian Inference in the Seemingly Unrelated Regressions Model,''
in Computer-Aided Econometrics, David E. A. Giles, New York, Marcel
Dekker
- Hamilton J.D. and
Jordà O., 2002, `` A Model for the Federal Reserve Rate
Target,'' Journal of Political Economy,
110, 5, 1135-1167
- Hu, L. and Phillips, P.,
2004, `` Dynamics of Federal Funds Target Rate: a Nonstationary
Discrete Choice Approach,'' Journal of Applied
Econometrics, 19, 851-867.
- Lancaster, T., 1990, `` The
Econometrics Analysis of Transition Data,'' Cambridge University
Press
- Lubik,
T. and Schorfheide, F., 2003, `` Do Central Banks Respond to
Exchange Rates? A Structural Investigation,'' Journal of Monetary Economics, forthcoming
- Orphanides, A.,
2001, `` Monetary Rules Based on Real-Time Data,'' American Economic Review, 91, 4, 964-985
- Pappa, E., 2004, `` Do the
ECBand the fed really need to cooperate? Monetary Policy in a
Two-Country World,'' Journal of Monetary
Economics, 51, 4, 753-779
- Patton, A., 2005, `` Modelling
Asymmetric Exchange Rate Dependence,'' International Economic Review, forthcoming
- Piazzesi, M., 2005, `` Bond
Yields and the Federal Reserve,'' Journal of
Political Economy, 113, 2, 311-344
- Russel, J., 1999,``
Econometric Modeling of Multivariate Irregularly-Spaced
High-Frequency Data,'' mimeo
- Schorfheide, F.,
2000, `` Loss Function-Based Evaluation of DSGE Models,''
Journal of Applied Econometrics, 15,
645-670
- Sims, C. and Zha, T., 1998,
`` Bayesian Methods for Dynamic Multivariate Models,'' International Economic Review, 39, 4, 949-968
- Tajar, A. Denuit, M. and Lambert, P.
(2001) '' Copula-type representation for random couples with
Bernoulli margins,'' discussion paper 0118, Universite Catholique
de Louvain
- Taylor, J., 1993, ``
Discretion versus policy rules in practice,'' Carnegie Rochester
series on Public Policy 39, 195-214
- Zhang,
M, Russel, J., and Tsay, R., 2001, `` A Nonlinear Conditional
Autoregressive Duration Model with Applications to Financial
Transactions Data,'' Journal of
Econometrics, 104, 1, 179-207
7 Appendix
7.1 Fed and ECB
The Federal Reserve System is composed of the Board of Governors and twelve Federal Reserve Banks. The Federal Open Market Committee (FOMC) is the policy-making organ of the Fed system, whose monetary policy decisions are carried out by the Federal Reserve Bank of New York. The Fed's policy tools are required reserve ratios, the discount rate and the Federal funds rate, which is influenced by open market operations. A detailed description of how the Fed system works can be found in Hamilton and Jordà (2002) and in Piazzesi (2005).
Open market operations are used much more frequently than the other two tools. Required reserve holdings have declined considerably in the past ten to fifteen years; the discount window has also had a very limited role in recent years.
When the Fed implements open market operations, it sells (buys) securities to (from) banks and debits (credits) the banks' account at the Fed. This implies an increase (decrease) in the amount of reserves held by banks at the Fed, and therefore will decrease (increase) the amount of reserves that they need to borrow from other banks in order to comply with reserve requirements. The rate at which banks borrow reserves from each other is the effective federal funds rate. When the FOMC sets the federal funds target rate, the New York Fed implements it through open market operations as described above. FOMC meetings are normally held eight times a year, or every five to eight weeks
The European Central Bank (ECB), together with the national central banks of the European Monetary Union (EMU) Member States, constitutes the Eurosystem. The Euro-zone consisted of 11 member states up until 31st December 2000, and comprises 12 members since January 1st, 2001, when Greece joined. The Governing Council of the ECB formulates the monetary policy, the Executive Board implements this monetary policy and ''to the extent deemed possible and appropriate and with a view to ensuring operational efficiency, the ECB [has] recourse to the national central banks to carry out operations which form part of the tasks of the Eurosystem'' (ECB 2002).
The Eurosystem has the primary objective of maintaining price stability. Moreover ``the Eurosystem has to support the general economic policies in the European Community'' and, in order to attain these objectives, it `` conducts open market operations, offers standing facilities and requires credit institutions to hold minimum reserves on accounts with the Eurosystem'' (ECB 2002).
Open market operations are particularly important for signalling the stance of monetary policy, steering interest rates and controlling market liquidity. They are conducted through five types of instruments: reverse transactions (main instrument), outright transactions, issuance of debt certificates, foreign exchange swaps and collection of fixed-term deposits. Open market operations can be sorted in to four categories: main refinancing operations, longer-term refinancing operations, fine-tuning operations and structural operations.
The marginal lending facility and deposit facility are used, respectively, by national eligible institutions37 to obtain (overnight) liquidity from the national central banks and to make overnight deposits with national central banks at pre-specified interest rates. Those interest rates represent the ceiling and the floor for the overnight interest rate.
Moreover, the ECB requires credit institutions to hold minimum reserves on accounts with the national central banks. The double aim is to stabilize money market interest rates by giving institutions an incentive to smooth the effect of temporary liquidity fluctuations, and to improve the ability of the Eurosystem to function as a supplier of liquidity by generating or extending a liquidity shortage. Reserve requirements are determined on the basis of the end of calendar day balances over a one-month period (from the twenty-fourth day of a month to the twenty-third day of the next).
The key policy rate of the ECB is the rate applied to main refinancing operations (MRO). It has been either the minimum bid rate of variable rate tenders, or the rate applied to fixed rate tenders. The MRO rate has always been equal to the mid rate of the corridor set by the rates on the standing facilities. MROs are liquidity-providing repurchase transactions that supply the bulk of financing to the financial sector. They occur at a weekly frequency, have a two-week maturity, and are carried out by national central banks on the basis of standard tenders. The MRO rate is set by the Governing Council, which met on alternate Thursdays until October 2001. Since November 2001, interest rate decisions are discussed only during the meeting held on the first Thursday of the month. The Governing Council consists of all the members of the Executive Board and the governors of the national central banks of the Member States that have adopted the euro. The Executive Board consists of the President, the Vice-President, and four other members.
7.2 CBO Probit Model
The log likelihood relative to the magnitude decision is
|
|
(38) |
with
| (39) |
where the probability is computed using the density
![$\displaystyle f\left( \left. \widetilde{y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1},\;x_{t}^{a}=1,\;x_{t}^{b}=0\right) =\frac{f\left( \left. \widetilde{y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1}\right) } {\Pr\left\{ \begin{array}[c]{c} \left[ \left( \widetilde{y}_{t}^{a}\leq c_{2}^{a}\right) \vee\left( \widetilde{y}_{t}^{a}>c_{3}^{a}\right) \right] \\ \wedge\left( c_{2}^{b}<\widetilde{y}_{t}^{b}\leq c_{3}^{b}\right) \end{array} \right\} };$](img298.gif)
|
(40) |
with
| (41) |
where the probability is computed using the density
![$\displaystyle f\left( \left. \widetilde{y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1},\;x_{t}^{a}=0,\;x_{t}^{b}=1\right) =\frac{f\left( \left. \widetilde{y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1}\right) } {\Pr\left\{ \begin{array}[c]{c} \left( c_{2}^{a}<\widetilde{y}_{t}^{a}\leq c_{3}^{a}\right) \\ \wedge\left[ \left( \widetilde{y}_{t}^{b}\leq c_{2}^{b}\right) \vee\left( \widetilde{y}_{t}^{b}>c_{3}^{b}\right) \right] \end{array} \right\} };$](img303.gif)
|
(42) |
and with
| (43) |
where the probability is computed using the density
![$\displaystyle f\left( \left. \widetilde{y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1},\;x_{t}^{a}=x_{t}^{b}=1\right) =\frac{f\left( \left. \widetilde {y}_{t}^{a},\widetilde{y}_{t}^{b}\right\vert w_{t-1}\right) }{\Pr\left\{ \begin{array}[c]{c} \left[ \left( \widetilde{y}_{t}^{a}\leq c_{2}^{a}\right) \vee\left( \widetilde{y}_{t}^{a}>c_{3}^{a}\right) \right] \\ \wedge\left[ \left( \widetilde{y}_{t}^{b}\leq c_{2}^{b}\right) \vee\left( \widetilde{y}_{t}^{b}>c_{3}^{b}\right) \right] \end{array} \right\} }.$](img308.gif)
|
(44) |
7.3 Bayesian Implementation
Following Schorfheide (2000), I compute the mode
![]() of
the posterior density
of
the posterior density
![]() through a numerical
optimization routine and then evaluate the inverse Hessian
through a numerical
optimization routine and then evaluate the inverse Hessian
![]() . I
use a random walk Metropolis algorithm to generate
. I
use a random walk Metropolis algorithm to generate ![]() draws
draws
![]() from the posterior
from the posterior
![]() .38 At each iteration
.38 At each iteration ![]() , I draw a candidate parameter
vector
, I draw a candidate parameter
vector ![]() from a jumping distribution
from a jumping distribution
![]() and
I accept the jump from
and
I accept the jump from
![]() so that
so that
![]() with probability
with probability ![]() where
where ![]() is defined as
is defined as
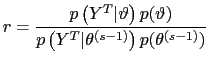
|
(45) |
and reject otherwise. The Markov chain sequence
7.4 Posterior Densities
Let
![]() represent
the parameters and
represent
the parameters and ![]() be the
data. Consider the Litterman prior
be the
data. Consider the Litterman prior
| (46) |
and the SURE likelihood
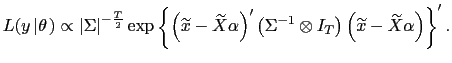
|
(47) |
The argument of
![$\displaystyle \left[ \left( \Sigma^{-1/2}\otimes I_{T}\right) \ \widetilde{x} -\Sigma^{-1/2}\otimes I_{T}\ \widetilde{X}\alpha\right] ^{\prime}\left[ \left( \Sigma^{-1/2}\otimes I_{T}\right) \ \widetilde{x}-\Sigma ^{-1/2}\otimes I_{T}\ \widetilde{X}\alpha\right]$](img332.gif)
|
(48) | |
![$\displaystyle =\left[ \left( \Sigma^{-1/2}\otimes I_{T}\right) \ \widetilde{x}-\left( \Sigma^{-1/2}\otimes I_{T}\widetilde{X}\right) \ \underline{\alpha}\right] ^{\prime}\left[ \left( \Sigma^{-1/2}\otimes I_{T}\right) \ \widetilde {x}-\left( \Sigma^{-1/2}\otimes I_{T}\widetilde{X}\right) \ \underline {\alpha}\right]$](img333.gif)
|
(49) | |
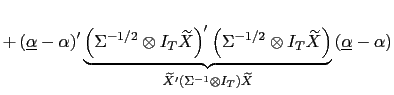
|
(50) | |
![$\displaystyle =\left[ \widetilde{X}^{\prime}\left( \Sigma ^{-1}\otimes I_{T}\right) \widetilde{X}\right] ^{-1}\ \widetilde{X}^{\prime }\left( \Sigma^{-1}\otimes I_{T}\right) \ \widetilde{x}$](img336.gif)
|
(51) |
then
with
|
|
|
|
| US Variables | EMU Variables |
|---|---|
| FOMC | Governing Council |
| US Variables | EMU Variables |
|---|---|
| CPI excl FE index YOY% | MUCPI YOY% |
| GDP Deflator YOY% | GDP Deflator YOY% |
| US Variables | EMU Variables |
|---|---|
| GDP Growth YOY% | GDP Growth YOY% |
| Industrial Production MOM% | Industrial Production MOM% |
| Unemployment Rate | Unemployment Rate |
| US Variables | EMU Variables |
|---|---|
| Eurodollar Rate, Weekly Average | Eurodollar Rate, Weekly Average |
| US Variables | EMU Variables |
|---|---|
| US decision | EMU decision |
|
|
|
|
|
|
|
|
|
|
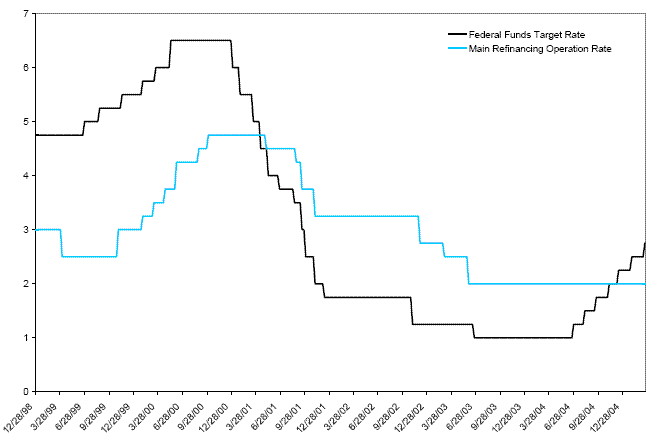
|
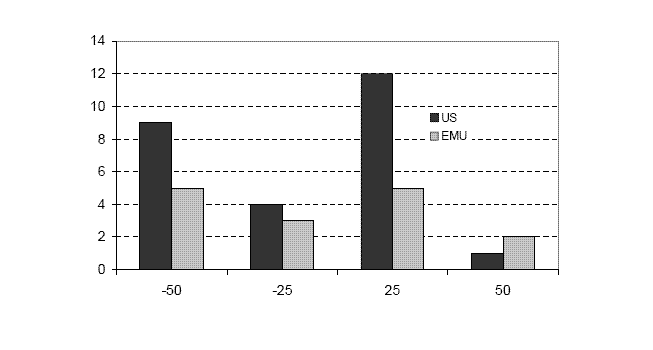
|
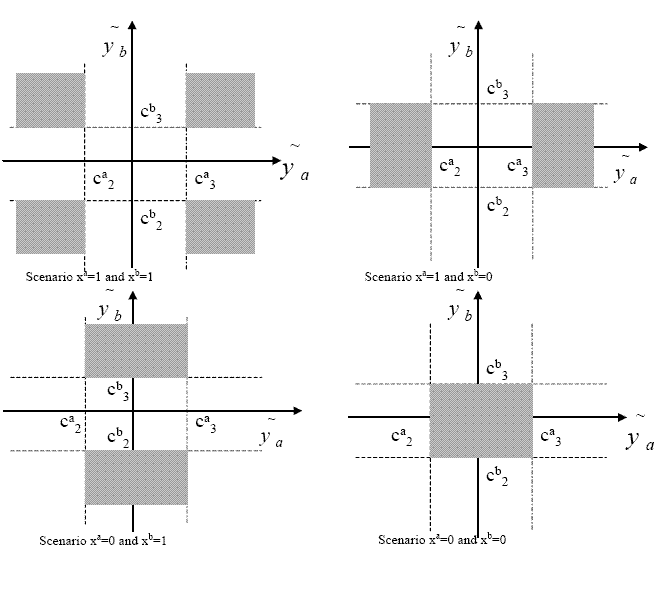
|
![Figure 4 contains 13 panels showing prior and posterior densities for the basic specification of the BACH model. The first 6 panels show prior and posterior densities for the sum of alpha and beta, the alpha proportion, the constant, meeting dummy, inflation, and output for the U.S. economy. The following 6 panels show the same parameters for the euro-area economy. The last panel shows prior and posterior densities for the odds ratio. Each panel exhibits two lines, a red dotted line (prior) and a blue line (posterior). The x-axis range is [0,1] for the sum of alpha and beta and the alpha proportion both in the U.S. and euro area; [0,35] for the constants; [0,12] for the U.S. meeting dummy; [0,10] for the euro-area meeting dummy; [0,2.5] for inflation in both countries; [0,10] for the U.S. output; [0,1.5] for the euro-area output; [0,15] for the odds ratio. The posterior densities for the constants are peaked to the right of the prior densities, the meeting dummy and inflation posteriors are peaked to the left of the prior densities, euro-area output posterior density is peaked considerably to the left of the prior, the odds ratio posterior is peaked slightly to the right of the prior density. Exact values for the prior and posterior means are provided in Tables 4 and 6, respectively. Additional interpretation of the densities is provided in the text in sections 4.2 and 4.4.](img430.gif) |
![Figure 5 contains 15 panels showing prior and posterior densities for the basic specification CBO Probit model. The first 4 panels show prior and posterior densities for the cut points in the US Probit specification. Panels 5-7 show prior and posterior densities for U.S. inflation, output, and exchange rate parameters. Panels 8-11 show prior and posterior densities for the cut points in the euro-area Probit specification. Panels 12-14 show prior and posterior densities for euro-area. inflation, output, and exchange rate parameters. Panel 15 depicts prior and posterior densities for the correlation coefficient. Each panel exhibits two lines, a red dotted line (prior) and a blue line (posterior). The x-axis range is [-4,4] for the first cut points in both countries; [0,1] and [0,1.5] for the second cut points (increment) in U.S. and euro area, respectively; [0,8] and [0,3] for the third and fourth cut points in both countries; [0,2.5] for inflation in both countries; [0,3] for the U.S. output; [0,1] for the euro-area output; [0,1] and [-1,0]for the euro-dollar exchange rate in the U.S. and EMU, respectively; [-1,1] for the correlation coefficient. The posterior densities for inflation are peaked to the left of the prior densities, while output posterior densities are peaked to the right of the prior density peaks, exchange rates posterior are both peaked closed to zero, the correlation posterior is peaked slightly to the right of the prior density at about 0.5. Exact values for the prior and posterior means are provided in Tables 5 and 7, respectively. Additional interpretation of the densities is provided in the text in sections 4.3 and 4.4.](img431.gif) |
Footnotes
1. I would like to thank Francis X. Diebold, Jesús Fernández-Villaverde and Frank Schorfheide for their invaluable advice. Celso Brunetti, Fabio Canova, Mark Carey, Michael Ehrmann, Gregory Kordas, Jean-Philippe Laforte, Mico Loretan, John Rogers and Robert Vigfusson provided useful comments. Part of this research was conducted while I was at the European Central Bank, for whose hospitality I am thankful. The views expressed in this paper are solely the responsibility of the author and should not be interpreted as reflecting the view of the Board of Governors of the Federal Reserve System or of any other person associated with the Federal Reserve System. Correspondence to: Chiara Scotti, Mail Stop 18, Federal Reserve Board, Washington DC 20551. E-Mail: [email protected] Return to text
2. In particular, the Federal Open Market Committee (FOMC) implements its monetary policy decisions by changing its target for the federal funds rate (FFR), which is the rate at which depository institutions borrow and lend reserves to and from each other overnight. Although the Federal Reserve does not control the FFR directly, it can do so indirectly by varying the supply of reserves available to be traded in the market. On the other hand, the key policy rate set by the Governing Council of the ECB is the rate applied to main refinancing operations, which provide the bulk of liquidity to the financial system.
For more information about how the Fed and the ECB operate, see the appendix Return to text
3. Please note that the sample only includes the first part of the 2004 through 2006 tightening cycle . Return to text
4. In a traditional approach (e.g. VAR or Taylor rule), the same variables affect both timing and magnitude because the two decisions are normally analyzed together. That is, when there is a jump/change in the rate (magnitude decision), the event is considered to occur (timing decision). Return to text
5. It could be interesting to compare baseline results based on real-time data to results obtained by estimating the model using revised data. However, this goes beyond the scope of this paper. Many papers in the literature have in fact already addressed this issue. Return to text
6. Event time is defined by a
sequence
![]() with
with
![]() representing the
arrival time of an event. Calendar time is simply
representing the
arrival time of an event. Calendar time is simply
![]() Return
to text
Return
to text
7. In particular, they analyse the elapsed times between two consecutive trades and between a trade and a quote. Return to text
8. I need to ensure that
![]() To do so I
follow Hamilton and Jordà (2002) and I use a smooth function
To do so I
follow Hamilton and Jordà (2002) and I use a smooth function
![]() so that
so that
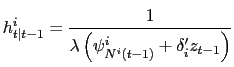
![\begin{displaymath} \lambda(\nu)=\left. \begin{array}[c]{cc} 1.0001 & \nu\geq1\ 1.001+2\Delta_{0}(\nu-1)^{2}/\left[ \Delta_{0}^{2}+(\nu-1)^{2}\right] & 1<\nu<1+\Delta_{0}\ 0.0001+\nu & \nu\geq1+\Delta_{0} \end{array}\right. \end{displaymath}](img80.gif)
9. Only one of the two roots belongs
to ![]() and is
therefore admissible. The root
and is
therefore admissible. The root
![]()
![]() Return
to text
Return
to text
10. Thus in principle the marginal
hazard rate for process
![]() depends on
all the conditioning variables (even the one from process
depends on
all the conditioning variables (even the one from process
![]() ). I will impose the
restriction that process
). I will impose the
restriction that process ![]() variables have no effect on the duration. The same applies to
variables have no effect on the duration. The same applies to
![]() Return to text
Return to text
11. Note that, given
![]() ,
then
,
then
![]() with
probability
with
probability ![]() Thus
Thus
![]() Return to
text
Return to
text
12. The original data is available daily. That is, on a given day I observe whatever data is released, and for variables for which there is no release on that day, I consider the latest available number. To make this a weekly dataset, I am forced to cut off the information on Fridays prior to the meetings. For the ECB, Governing Council meetings are only on Thursdays, so I disregard all the information that arrives thereafter. FOMC meetings are normally held on Tuesdays, thus considering information until the Friday of the previous week is not very restrictive. Return to text
13. Euro-zone inflation is measured by the Monetary Union Index of Consumer Prices (MUICP). Return to text
14. Inflation and output variables, together with their released dates, are taken from Bloomberg. Return to text
15. To compute the MUICP flash estimates, Eurostat uses early price information for the reference month from Member States for which data are available as well as early information about energy prices. The estimation procedure for the MUICP flash estimate combines historical information with partial information on price developments in the most recent months to give a total index for the euro-zone. No detailed breakdown is available. Return to text
16. Thus I do not use flash estimates but only provisional and final estimates before those dates. Return to text
17. I thank Frank Schorfheide for providing GAUSS code for the Bayesian estimation, which can be found at http://www.ssc.upenn.edu/~schorf/programs/gauss-bayesdsge.zip. Return to text
18. I use data on the German Bundesbank because it is the central bank in Europe that most closely resembles the ECB. Faust et al. (2001) study the monetary policy of the ECB and compare it with a simple empirical representation of the monetary policy of the Bundesbank before 1999. Return to text
19. Omitted simulation results show
that the BACH model, as well as all ACD and ACH type models, need a
long data sample to identify the expected duration parameters
(![]() and
and
![]() ) and the
constants. Return to text
) and the
constants. Return to text
20. This data problem could have been avoided by analyzing the Fed and the Bank of Japan, or the Fed and the Bank of Canada. However, I believe that investigating the Fed and the ECB is more interesting. Return to text
21. Interpretation of the posterior
odds is as follows:
![]() null hypothesis is supported;
null hypothesis is supported;
![]() evidence against
evidence against
![]() ;
;
![]() substantial evidence against
substantial evidence against ![]() ;
;
![]() strong
evidence against
strong
evidence against ![]() ;
;
![]() very
strong evidence against
very
strong evidence against ![]() ;
;
![]() decisive evidence
against
decisive evidence
against ![]() . Return to
text
. Return to
text
22. See Lubik and Schorfheide. Return to text
23. I actually assume that
![]() and
and
![]() are the
average inflation and output growth rates over the sample
period. Return to text
are the
average inflation and output growth rates over the sample
period. Return to text
24. For computational convenience
the covariates data have been rescaled, so that ![]() and
and ![]() basis point changes read as
basis point changes read as ![]() and
and ![]() respectively. Return to
text
respectively. Return to
text
25. That is, I expect
![]() Return to
text
Return to
text
26. Thus unemployment and the CPI dominate GDP and GDP deflator measures. Intuitively, unemployment and the CPI are monthly statistics and therefore more promptly incorporate new information. Return to text
27. Both the univariate
Autoregressive Conditional Hazard (ACH) model and the Bivariate
Autoregressive Conditional Hazard (BACH) require long data series
to estimate ACD-type parameters (![]() and
and ![]() ). Return to
text
). Return to
text
28. Persistence is measured as
![]() Return to
text
Return to
text
29. The marginal data density for the former is -160.3, while for the latter is -165.45. Return to text
30. The marginal data density of the specification that includes meeting dummies, inflation, output and exchange rates is 162.57. Return to text
31. By relating these shocks to the VAR literature, it turns out that, given the assumption that interest rates only depend on past values of output and inflation, the disturbances in equations (20) and (21) are purely monetary shocks. Return to text
32. I use monthly data for the VAR. I use monthly averages of the effective Federal Funds rate and Eonia rate as interest rate variables. The bilateral exchange rate is also a monthly average. Return to text
33. Hence, for example, I do not included lagged interest rates in the equations. Return to text
34. For ease of notation I do not include a constant term, but the estimated version also has a constant term in each equation. Return to text
35. So for example
![]() ,
given our current specification, will be a
,
given our current specification, will be a ![]() matrix containing the
matrix containing the
![]() -dimensional vectors
-dimensional vectors
![]()
![]() ,
, ![]() and
and ![]() . Return to
text
. Return to
text
36. See the appendix for the derivation. Return to text
37. Financially sound institutions that are subject to the minimum reserve requirement and that fulfill operational criteria satisfy these eligibility requirements. More information about eligible counterparties can be found in chapter 2 of ECB (2002). Return to text
38. I use
![]() for
the BACH model and
for
the BACH model and
![]() for
the CBO Probit Model. Return to
text
for
the CBO Probit Model. Return to
text
39. Only dummy![]() Return to table
Return to table
40. Only dummy![]() Return to table
Return to table
This version is optimized for use by screen readers. Descriptions for all mathematical expressions are provided in LaTex format. A printable pdf version is available. Return to text