
News, Noise, and Estimates of the "True" Unobserved State of the Economy
Keywords: GDP, statistical discrepancy, news and noise, signal-to-noise ratios, optimal combination of estimates, business cycles
Abstract:
Which provides a better estimate of the "true" state of the U.S. economy, gross domestic product (GDP) or gross domestic income (GDI)? Past work has assumed the idiosyncratic variation in each estimate is pure noise, taking greater variability to imply lower reliability. We develop models that relax this assumption, allowing the idiosyncratic variation in the estimates to be partly or pure news; then greater variability may imply higher information content and greater reliability. Based on evidence from revisions, we reject the pure noise assumption for GDI growth, and our results favor placing a higher weight on GDI due to its relatively large idiosyncratic variability. This calls into question the suitability of the pure noise assumption in other contexts, including dynamic factor models.
JEL classification: C1, C82.
1 Introduction
For analysts of economic fluctuations, estimating the true state of the economy from imperfectly measured official statistics is an ever-present problem. As most economists agree that no one statistic is a perfect gauge of the state of the economy, many have proposed using some type of weighted
average of multiple imperfectly measured statistics instead. Examples include the composite index of coincident indicators,1 and averages of different measures
of aggregate economic activity such as gross domestic product (GDP) and its income-side counterpart GDI. While the precise meaning of the state of the economy can vary from case to case, in this paper we take it to mean the growth rate of the size of the economy as traditionally defined in the U.S.
National Income and Product Accounts (NIPAs).2![]() 3
3
The main point of our paper is as follows. To our knowledge, all prior attempts to produce such a weighted average of imperfectly measured statistics have made a strong implicit assumption that drives their weighting: that the idiosyncratic variation in each measured statistic is pure noise, or completely uncorrelated with information about the true state of the economy.4 Under this assumption, a statistic with greater idiosyncratic variance is given a smaller weight because it is assumed to contain more noise. We consider the implications of relaxing this assumption, allowing the idiosyncratic variation in each measured statistic to contain news, or information about the true state of the economy. If the idiosyncratic variation is mostly news, the implied weighting is diametrically opposite that of the noise assumption: a statistic with greater idiosyncratic variance should be given a larger weight because it contains more information about the true state of the economy. The implicit noise assumption relied upon in numerous prior papers is arbitrary, and more information must be brought to bear on this issue.
Focusing on GDP and GDI allows us to make this basic point in a simple bivariate context. These two measures of the size of the U.S. economy would equal one another if all the transactions in the economy were observed, but measurement difficulties lead to the statistical discrepancy between the two; their quarterly growth rates often diverge significantly. Weale (1992) and others5 have estimated the growth rate of "true" unobserved GDP as a combination of measured GDP growth and GDI growth, generally concluding that GDI growth should be given more weight than measured GDP growth. Is GDI really the more accurate measure? We argue for caution, as the results are driven entirely by the noise assumption: the models implicitly assume that since GDP growth has higher variance than GDI growth over their sample period, it must be noisier, and so should receive a smaller weight. However GDP may have higher variance because it contains more information about "true" unobserved GDP (this is the essence of the news assumption); then measured GDP should receive the higher weight.
In the general version of our model that allows the idiosyncratic component of each measured statistic to be a mixture of news and noise, virtually any set of weights can be rationalized by making untestable assumptions about the mixtures. More information must be brought to bear on the problem; otherwise the choice of weights will be arbitrary. This point is broadly applicable, extending well beyond the simple bivariate case of GDP and GDI. For example, a large and growing literature on dynamic factor models uses principal components or other methods to extract common factors out of large data sets; see Stock and Watson (2002), Forni, Hallin, Lippi, and Reichlin (2000), Bernanke and Boivin (2003), Giannone, Reichlin, and Small (2005), Bernanke, Boivin, and Eliasz (2005), and Boivin and Ng (2006).6 While often these common factors are used for pure forecasting, sometimes they are equated with unobserveables of interest, assuming the idiosyncratic components of the variables in the dataset are uninteresting noise. However if these idiosyncratic components do contain useful information about the unobserveables of interest, estimating the unobserveables optimally may require taking weighted averages of the variables in the dataset very different from those implied by the factor models.
While this fundamental indeterminancy - the arbitrary nature of most weighting schemes - is somewhat disturbing, in the case of combining GDP and GDI we bring more information to bear on the problem to help pin down the weights. GDI growth has more idiosyncratic variation than GDP growth in the sample we employ, which starts in the mid 1980s after the marked reduction in the variance of the measured estimates - see McConnell and Perez-Quiros (2000). However the initial GDI growth estimates have negligible idiosyncratic variance; it is only through revisions that the idiosyncratic variance of GDI growth becomes relatively large. If the revisions add news, and not noise - an assumption that is consistent with our knowledge of the revisions process and that follows previous research such as Mankiw, Runkle and Shapiro (1984) and Mankiw and Shapiro (1986) - then there must be a strong presumption that the idiosyncratic variation in GDI growth is largely news, news derived from the revisions.
We decompose the revisions to GDP and GDI growth into news and noise, show how to place bounds on the shares of their idiosyncratic variances that are news, and based on these bounds we test the assumptions of the pure noise model, rejecting them at conventional significance levels. Based on its relatively large idiosyncratic variation, GDI growth should be weighted more heavily, not less, in estimating "true" unobserved GDP growth. This leads to some interesting modifications of economic history: for example both before and after the 1990-1991 recession, economic growth is weaker than indicated by measured GDP growth. Furthermore, our results indicate that measured GDP growth understates the true variability of the economy's growth rate, a fact with clear implications for real business cycle, asset pricing, and other models.
2.1 Review of News and Noise
Let
![]() be the true growth rate of the economy, let
be the true growth rate of the economy, let
![]() be one of its measured estimates, and let
be one of its measured estimates, and let
![]() be the difference between the two, so:
be the difference between the two, so:
In contrast, if an estimate
![]() were constructed efficiently with respect to a set of information about
were constructed efficiently with respect to a set of information about
![]() (call it
(call it
![]() ), then
), then
![]() would be the conditional expectation of
would be the conditional expectation of
![]() given that information set:
given that information set:
Writing:
the term
These two models are clearly extremes; the next section considers a general model that allows differing degrees of news and noise in the estimates.
2.2 The Mixed News and Noise Model
We consider a model with two estimates of true unobserved GDP growth, each an efficient estimate plus noise:
The noise components
To clearly illustrate the main points of the paper, we focus on the simple case where all variables are jointly normally distributed, and where measured GDP and GDI are serially uncorrelated.9 With normality, the conditional expectation of the true growth rate of the economy is a weighted average of GDP and GDI; netting out means yields:
| (1') |
calling the conditional expectation
| (2') | ![\displaystyle \left( \begin{array}[c]{c}% \omega_{1}\ \omega_{2}% \end{array} \right)](img35.gif) |
![\displaystyle = \left( \begin{array}[c]{cc}% \operatorname{var}\left( \Delta y_{t}^{1}\right) & \operatorname{cov}\left( \Delta y_{t}^{1},\Delta y_{t}^{2}\right) \ \operatorname{cov}\left( \Delta y_{t}^{1},\Delta y_{t}^{2}\right) & \operatorname{var}\left( \Delta y_{t}^{2}\right) \end{array} \right) ^{-1} \left( \begin{array}[c]{c}% \operatorname{cov}\left( \Delta y_{t}^{1},\Delta y_{t}^{\star}\right) \ \operatorname{cov}\left( \Delta y_{t}^{2},\Delta y_{t}^{\star}\right) \end{array} \right)](img36.gif)
|
![\displaystyle = \left( \begin{array}[c]{cc}% \operatorname{var}\left( \Delta y_{t}^{1}\right) & \operatorname{cov}\left( \Delta y_{t}^{1},\Delta y_{t}^{2}\right) \ \operatorname{cov}\left( \Delta y_{t}^{1},\Delta y_{t}^{2}\right) & \operatorname{var}\left( \Delta y_{t}^{2}\right) \end{array} \right) ^{-1} \left( \begin{array}[c]{c}% \operatorname{var}\left( E\left( \Delta y_{t}^{\star}\vert \mathcal{F}_{t}^{1} \right) \right) \ \operatorname{var}\left( E\left( \Delta y_{t}^{\star}\vert \mathcal{F}_{t}^{2} \right) \right) \end{array} \right) ,](img37.gif)
|
using
It is useful to introduce some additional notation. Call the covariance between the two estimates
![]() ; this arises from the overlap between the information sets used to compute the efficient estimates, and correlation between the measurement errors
; this arises from the overlap between the information sets used to compute the efficient estimates, and correlation between the measurement errors
![]() and
and
![]() . The model imposes the condition that the variance of each estimate is at least as large as their covariance; let
. The model imposes the condition that the variance of each estimate is at least as large as their covariance; let
![]() and
and
![]() be the variances of the
be the variances of the
![]() and
and
![]() , respectively. The idiosyncratic variance in each estimate, the
, respectively. The idiosyncratic variance in each estimate, the
![]() for
for ![]() , arises from two potential sources. The first source is the
idiosyncratic news in each estimate - the information in each efficient estimate missing from the other, and the second source is noise.
, arises from two potential sources. The first source is the
idiosyncratic news in each estimate - the information in each efficient estimate missing from the other, and the second source is noise.
Let the share of the covariance between the two estimates that is news, or common information, be ![]() . Similarly, let the news share of the idiosyncratic variance in the
. Similarly, let the news share of the idiosyncratic variance in the ![]() th estimate be
th estimate be ![]() , so
, so
![]() is the fraction of the idiosyncratic variance that is noise. Then equation (2) becomes:
is the fraction of the idiosyncratic variance that is noise. Then equation (2) becomes:
|
![\displaystyle = \left( \begin{array}[c]{cc}% \sigma^{2} + \tau^{2}_{1} & \sigma^{2}\ \sigma^{2} & \sigma^{2} + \tau^{2}_{2}% \end{array} \right) ^{-1} \left( \begin{array}[c]{c}% \chi\sigma^{2} + \chi_{1} \tau^{2}_{1}\ \chi\sigma^{2} + \chi_{2} \tau^{2}_{2}% \end{array} \right) .](img49.gif) |
Solving and substituting into (2) gives:
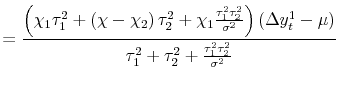 |
||
| (3') | 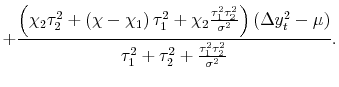 |
Before examing (3) in greater depth, note that the weights on the two component variables here do not necessarily sum to one; the weights on the two components variables and mean ![]() sum
to one. But in some situations the econometrician may have little confidence in the estimated mean
sum
to one. But in some situations the econometrician may have little confidence in the estimated mean ![]() , so it may be inadvisable to use it as the third component in the weighted average. One
way around this problem is to force the weights on
, so it may be inadvisable to use it as the third component in the weighted average. One
way around this problem is to force the weights on
![]() and
and
![]() to sum to one, with
to sum to one, with
![]() ; substituting into (1) and rearranging yields:
; substituting into (1) and rearranging yields:
| (1') |
Adding back in
| (3') | 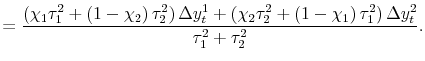 |
With the assumptions of the pure noise model discussed below, this particular estimator is equivalent to the estimator proposed by Weale (1992) and Stone et al (1942). Appendix A clarifies the relation between these earlier estimators and those derived here.
It is clear that not all of the parameters of the unconstrained model are identified: we observe three moments from the variance-covariance matrix of
![]() , which is not enough to pin down the six parameters
, which is not enough to pin down the six parameters
![]() ,
,
![]() ,
,
![]() ,
, ![]() ,
, ![]() , and
, and ![]() . Imposing values for
. Imposing values for ![]() ,
, ![]() , and
, and ![]() allows identification of the remaining
parameters. Some illuminating special cases are examined next, which show how assumptions about the idiosyncratic news shares
allows identification of the remaining
parameters. Some illuminating special cases are examined next, which show how assumptions about the idiosyncratic news shares ![]() and
and ![]() are critical for determining the relative weights on the two component variables.
are critical for determining the relative weights on the two component variables.
2.2.1 The Pure Noise Model
Previous attempts to estimate models of this kind have focused on one particular assumption for the idiosyncratic news shares:
![]() . The implication is that the two information sets must coincide, at least in the universe of information that is relevant for predicting
. The implication is that the two information sets must coincide, at least in the universe of information that is relevant for predicting
![]() , so
, so
![]() . We call this the pure noise model;
equation (3) is then:10
. We call this the pure noise model;
equation (3) is then:10
| (4) | 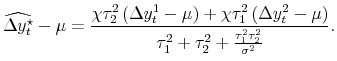 |
In the pure noise model, the weight for one measure is proportional to the idiosyncratic variance of the other measure - since the idiosyncratic variance in each estimate is assumed to be noise, the "noisier" measure is downweighted. The weights on the (net of mean) estimates sum to less than
one; as is typical in the classical measurement error model, coefficients on noisy explanatory variables are downweighted. In fact, as the common variance
![]() approaches zero, the signal-to-noise ratio in the model approaches zero as well, and the formula instructs us to give up on the estimates of GDP and GDI for any given time period,
using the overall sample mean as the best estimate for each and every period.
approaches zero, the signal-to-noise ratio in the model approaches zero as well, and the formula instructs us to give up on the estimates of GDP and GDI for any given time period,
using the overall sample mean as the best estimate for each and every period.
2.2.2 The Pure News Model
The opposite case is what we call the pure news model, where
![]() . Equation (3) then becomes:
. Equation (3) then becomes:
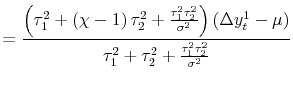 |
||
| (5) | 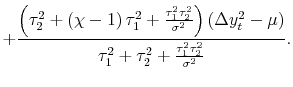 |
The weight for each measure is now proportional to its own idiosyncratic variance - the estimate with greater variance contains more news and hence receives a larger weight. This result is diametrically opposed to that of the noise model.
Under some circumstances it may be reasonable to assume that the covariance between the estimates is pure news, in which case the
![]() terms vanish; then the weights (on the net of mean estimates) sum to a number greater than unity, again opposite the pure noise model. As
terms vanish; then the weights (on the net of mean estimates) sum to a number greater than unity, again opposite the pure noise model. As
![]() (i.e. as the variance common to the two estimates approaches zero), the weight for each estimate approaches unity. In this case, we are essentially adding together two
independent pieces of information about GDP growth. To illustrate, suppose we receive news of a shock that moves
(i.e. as the variance common to the two estimates approaches zero), the weight for each estimate approaches unity. In this case, we are essentially adding together two
independent pieces of information about GDP growth. To illustrate, suppose we receive news of a shock that moves
![]() two percent above its mean, and then receive news of another, independent shock that moves
two percent above its mean, and then receive news of another, independent shock that moves
![]() one percent below its mean. The logical estimate of
one percent below its mean. The logical estimate of
![]() is then the mean plus one percent - i.e. the sum of the two shocks. In Appendix B we work through another example, of two estimates of GDP growth, each based on the growth
rate of a different sector of the economy; if the growth rates of the sectors are uncorrelated, we simply add up the net-of-mean contributions to GDP growth of the two sectors, and then add back in the mean.
is then the mean plus one percent - i.e. the sum of the two shocks. In Appendix B we work through another example, of two estimates of GDP growth, each based on the growth
rate of a different sector of the economy; if the growth rates of the sectors are uncorrelated, we simply add up the net-of-mean contributions to GDP growth of the two sectors, and then add back in the mean.
2.2.3 Arbitrary Weights
Finally, consider another case of interest: if
![]() and
and
![]() , then
, then
![]() and
and
![]() , placing all the weight on variable
, placing all the weight on variable ![]() . If placing all the weight on
either variable can be justified with such assumptions about the idiosyncratic news shares, perhaps any set of weights is possible. This turns out to be the case. Let the ratio of the weights
. If placing all the weight on
either variable can be justified with such assumptions about the idiosyncratic news shares, perhaps any set of weights is possible. This turns out to be the case. Let the ratio of the weights
![]() , so:
, so:
| (6) | 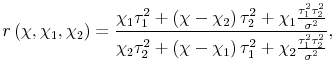
|
where we've expressed
Proof: Consider an example that meets the conditions of the proposition, where
![]() . Then
. Then
![]() . Since
. Since
![]() is a continuous function,
is a continuous function,
![]() , and
lim
, and
lim![]() , the result holds by theorem 4.23 of Rudin (1953). We have
, the result holds by theorem 4.23 of Rudin (1953). We have
![]() , which produces the desired
, which produces the desired
![]() and
and
![]() for any non-negative real
for any non-negative real ![]() .
.
One set of weights is as justifiable as any other; without further information about the estimates, the choice of weights will be arbitrary. In the empirical work below on GDP and GDI, we do bring further information to bear on the problem, and examine which news shares are likely closest to reality.
3.1 Data Description
The most widely-used statistic produced by the U.S. Bureau of Economic Analysis (BEA) is GDP, its expenditure-based estimate of the size of the economy; this statistic is the sum of personal consumption expenditures, investment, government expenditures, and net exports. However the BEA also produces an income-based estimate of the size of the economy, gross domestic income (GDI), from different information. National income is the sum of employee compensation, proprietors' income, rental income, corporate profits and net interest; adding consumption of fixed capital and a few other balancing items to national income produces GDI.11 Computing the value of GDP and GDI would be straightforward if it were possible to record the value of all the underlying transactions included in the NIPA definition of the size of the economy, in which case the two measures would coincide. However all the underlying transactions are not recorded: the BEA relies on various surveys, censuses and administrative records, each imperfect, to compute the estimates, and differences between the data sources used to produce GDP and GDI, as well as other measurement difficulties, lead to the statistical discrepancy between the two measures.
Likelihood-ratio tests show breaks in the means and variances of our GDP and GDI growth series in 1984Q3; in this version of the paper we restrict our attention to the new regime - i.e. the post-1984Q3 period. Figure 1 plots the annualized quarterly growth rates of the "latest available" versions of nominal GDP (solid) and GDI (dashed) from 1984Q3 to 2004, pulled from the BEA web site in August 2007.12 This "latest available" vintage is one of numerous vintages of data released by the BEA. The "final current quarterly" vintage, released about three months after the quarter ends, is the first vintage available with a complete time series of both GDP and GDI growth over our sample period. Because the "final current quarterly" nomenclature is somewhat confusing, we call this the "first" vintage, and the "latest" available vintage the "last" vintage. Historically, each "first" vintage estimate has been revised three times at annual revisions, and then periodically every five years at benchmark revisions. We restrict our sample to end in 2004 so that all our "last" vintage observations have passed through the three annual revisions; the time series we employ was last benchmarked in 2003-2004.
At each of the annual revisions and at a benchmark revision, the BEA incorporates more comprehensive and accurate source data. For the current quarterly estimates, most available source data is based on samples, which may contain some noise from sampling errors. Later vintages are based on more comprehensive samples, or sometimes universe counts, so incorporation of these data has the potential to reduce noise.
In addition to potentially noisy data, at the time of the current quarterly estimates the BEA has little hard data at all on some components of GDP and GDI, including much of services consumption.13 For these components the BEA often resorts to "trend extrapolations," assuming the growth rate for the current quarter some average of past growth rates, which can be thought of as approximating conditional expectations based on past history. In later vintages when the BEA receives and substitutes actual data for these extrapolated components, news is added to the estimates. For some missing components the BEA substitutes related data instead of "trend extrapolations"; for example the BEA borrows data from the income-side, using employment, hours and earnings as an extrapolator from some components of services consumption. These estimates may be thought of as approximating conditional expectations based on related labor market information, although if the labor market data contain noise, it is possible that these procedures may introduce common noise to the current quarterly estimates.
3.2 Information about News and Noise from Revisions
Our model for "first" and "last" vintage GDP and GDI growth (![]() ) is:
) is:
Our working assumption is that the revision from "first" to "last" brings the estimates closer to the truth
the term
with
If the revision from "first" to "last" reflects largely increased news, the variance of "last" should exceed the variance of "first," and if the revision reflects decreased noise, the opposite should hold, as discussed in Mankiw and Shapiro (1986). Here we show how to identify the fraction of revision variance that stems from increased news, and the fraction that stems from decreased noise. The variance of the revision is:
| (7) |
since
| (8) |
again relying on the independence of various terms. Equations (7) and (8) pin down the news increase
The first two rows of Table 1 show, for GDP growth and GDI growth, the variances of their "first" and "last" vintages, the change in variance (equation 8), the revision variance (equation 7), and the increase in news and decrease in noise implied by these statistics. For GDP growth, the variances of "last" and "first" are about equal, implying the increase in variance from greater news is about equal to and offsets the decrease in variance from less noise. For GDI growth, the variance of "last" is substantially larger, implying more than 80% of the revision variance stems from increased news.
The third row of the table shows covariances between GDP growth and GDI growth. Note that "first" GDI growth has virtually no idiosyncratic variance - its variance is about equal to its covariance with GDP growth - but after passing through revisions its idiosyncratic variance is substantial. Since the idiosyncratic variance of this "last" estimate stems from revisions, which add news but not noise, it is tempting to conclude that this idiosyncratic variance must be news. However as the equations in Appendix C illustrate, the increase in common news and decrease in common noise are not identified, as would be necessary to pin down precisely the increase in idiosyncratic news. Some of our intuition developed earlier for variances does apply to covariances: increased news can only increase the covariance, while decreased common noise can only decrease the covariance. The fact that the covariance falls implies that the "first" estimates must contain some common noise that is eliminated through revision. One possibility is that this common noise is eliminated from GDP growth but not GDI growth, in which case it then becomes idiosyncratic noise in GDI growth, accounting for some of its higher variance in the "last" estimates.
Appendix C works through the relevant equations describing the change in common and idiosyncratic news and noise. These equations provide bounds on the admissable values of the news shares for the idiosyncratic variances of the "last" vintage estimates,
![]() and
and
![]() , as well as bounds on the news shares of the idiosyncratic and common variances of the "first" vintage estimates,
, as well as bounds on the news shares of the idiosyncratic and common variances of the "first" vintage estimates,
![]() ,
,
![]() and
and ![]() . Table 2 shows various possibilities sketching out the
edges of these boundaries. In these scenarios, we assume all common variance is news unless it is explicitly identified as noise; formally, we assume equation (C.10) holds with equality.
. Table 2 shows various possibilities sketching out the
edges of these boundaries. In these scenarios, we assume all common variance is news unless it is explicitly identified as noise; formally, we assume equation (C.10) holds with equality.
The first column on table 2 shows news shares resulting from minimization of the total idiosyncratic news in the "last" estimates, subject to the revision equations described in Appendix C. For the "last" estimates, the pure noise model cannot be squared with the revisions information: the idiosyncratic news share for GDI growth of 0.46 is its lowest possible value.15 Under this scenario, all of the 0.96 reduction in the noise variance of "first" GDP is assumed to come from a reduction in common noise, with none of that noise removed from GDI growth so all of it becomes idiosyncratic noise in the "last" GDI estimate. This accounts for about half of the idiosyncratic variance in "last" GDI growth; the remainder of this idiosyncratic variance must be news. Two assumptions in this scenario are unlikely: (i) that all of the decrease in GDP noise occurs in the common component, and (ii) that none of the common noise removed from GDP growth is removed from GDI growth. Regarding (i), some of the idiosyncratic variance of "first" GDP growth of around 0.7 is likely noise, and revisions likely eliminate some of that; regarding (ii), the revisions to GDI growth incorporate virtual census counts from administrative and tax records, which should cut down on noise from sampling errors.
The second column on table 2 shows news shares resulting from maximizing the total idiosyncratic news in the "last" estimates. While the pure news model cannot be squared with the revisions evidence either, something close to the pure news model with (
![]() ,
,
![]() ) equal to (1, 0.86) is admissable. Under this scenario, of the 0.96 reduction in "first" GDP noise variance, about one third stems from a reduction idiosyncratic GDP noise,
about one third stems from a reduction in common noise also removed from GDI growth, and about one third stems from a reduction in common noise not also removed from GDI growth. This appears quite reasonable to us, and we take it as our preferred specification. The assumption that the idiosyncratic
variance in "first" GDI growth is pure news is unlikely, but given the small size of that idiosyncratic component, this assumption makes little difference in the optimal combination formulas.
) equal to (1, 0.86) is admissable. Under this scenario, of the 0.96 reduction in "first" GDP noise variance, about one third stems from a reduction idiosyncratic GDP noise,
about one third stems from a reduction in common noise also removed from GDI growth, and about one third stems from a reduction in common noise not also removed from GDI growth. This appears quite reasonable to us, and we take it as our preferred specification. The assumption that the idiosyncratic
variance in "first" GDI growth is pure news is unlikely, but given the small size of that idiosyncratic component, this assumption makes little difference in the optimal combination formulas.
The last two columns show news shares resulting from minimization of the ratio of optimal weights on the two components. Each of these scenarios makes some unlikely assumptions; for example the scenario in the last column assumes the idiosyncratic variance in "first" GDP growth is entirely
news, so all of the 0.96 reduction in its noise variance comes from a reduction in common noise. These last two scenarios show that revisions give us little concrete information about the idiosyncratic news shares for the "first" estimates: (0, 1) and (1, 0) are possibilities for (
![]() ,
,
![]() ); further experiments showed (0, 0) is a possibility but (1, 1) is not.
); further experiments showed (0, 0) is a possibility but (1, 1) is not.
4 Estimates of "True" Unobserved GDP
Table 3 reports maximum likelihood estimates of the means, covariances, and idiosyncratic variances of GDP and GDI growth, with standard errors beneath the the estimates. These are slightly different from the statistics reported in table 1, because the estimation here imposes equality of mean
GDP growth and mean GDI growth for each vintage. The statistics for the two vintages are estimated jointly, along with covariances between vintages. This allows us to decompose the revision variances into news and noise as in the previous section, and recompute the bounds on the news shares implied
by the equations in Appendix C; these bounds were very similar to those reported in in table 2. The news shares corresponding to each of these bounds imply optimal weights for GDP and GDI growth via equation (3); these are reported in table 3 with standard errors. As in the previous section, these
weights assume equation (C.10) holds with equality; the weights for the "last" estimates assume
![]() , making the assumption typical of dynamic factor models that covariance is signal.
, making the assumption typical of dynamic factor models that covariance is signal.
Consider first the weights for the "first" vintage estimates. In all the scenarios, the weights on GDP and GDI growth sum to less than one: it is optimal to down-weight to some degree the "first" estimates, shrinking them back towards their mean. This is a consequence of the common noise in the "first" estimates implied by the revisions evidence - i.e. the fact that revisions cause the covariance between the estimates to fall; the down-weighting filters some of this noise out of the data. From the standpoint of tracking the economy in real time, for monetary policy or other purposes, these current-quaterly estimates are all that is available, and this result is certainly interesting from that perspective.
Regarding the relative weight to be placed on the GDP vs GDI for the "first" estimates, the last two scenarios show the expected result that we cannot rule out anything definitively based on the revisions evidence. However the first two scenarios show that if a decent share of the idiosyncratic variance of GDP is news (see the assumptions in table 2), GDP will tend to receive the higher weight, since its idiosyncratic variance is so much larger than that of GDI. Since the first two scenarios both favor GDP, the evidence does lean slightly in that direction.
We can make more definitive statements about relative weights for the "last" estimates, and the evidence favors placing a greater weight on GDI. Consider the last two scenarios, which place bounds on the ratio of the weights
![]() and
and
![]() . It is possible to skew the weights much more heavily in favor of GDI than GDP. One sensible way to proceed may be to choose the midpoint of this range of feasible
relative weights, which would then place a greater weight on GDI.16 The first two scenarios favor GDI as well.
. It is possible to skew the weights much more heavily in favor of GDI than GDP. One sensible way to proceed may be to choose the midpoint of this range of feasible
relative weights, which would then place a greater weight on GDI.16 The first two scenarios favor GDI as well.
In the first scenario, the lower bound of
![]() based on the revisions evidence is binding. This lower bound shows that the pure noise model is inconsistent with the assumption that revisions either add news or decrease noise,
but the bound is a function of estimated parameters, so there is some uncertainty about whether this lower bound is really above zero. A statistical test of whether
based on the revisions evidence is binding. This lower bound shows that the pure noise model is inconsistent with the assumption that revisions either add news or decrease noise,
but the bound is a function of estimated parameters, so there is some uncertainty about whether this lower bound is really above zero. A statistical test of whether
![]() is equivalent to a test of whether the difference between
is equivalent to a test of whether the difference between
![]() and the estimated reduction in noise in
and the estimated reduction in noise in
![]() is greater than zero, where the noise reduction is computed as
is greater than zero, where the noise reduction is computed as
![]() . This difference is 1.02, with a standard error of 0.52; hence we may reject the pure noise model at
conventional significance levels based on evidence from revisions, even taking on board the unlikely assumption that all of the reduction in noise in "final" GDP growth stems from the common component.
. This difference is 1.02, with a standard error of 0.52; hence we may reject the pure noise model at
conventional significance levels based on evidence from revisions, even taking on board the unlikely assumption that all of the reduction in noise in "final" GDP growth stems from the common component.
As discussed in the previous section, the second scenario is the set of assumptions about the "last" news shares that we consider most likely. Under this scenario, the informativeness of GDI relative to GDP increases in the revision from "first" to "last", as a greater amount of useful information is incorporated into GDI, causing its idiosyncratic variance to surge past that of GDP. This interpretation is consistent with the findings in Nalewaik (2007a, 2007b), who shows that although GDI appears to be more informative than GDP in recognizing recessions (or, more precisely, more informative in recognizing the state of the world in a two-state Markov switching model for the economy's growth rate), most of that greater information content comes from the information in annual and benchmark revisions.
Placing a greater weight on GDI growth in analyzing the historical behavior of the economy leads to some interesting modifications to economic history, as illustrated in Figures 2 and 3. These figures show "last" GDP growth, GDI growth, and their weighted average using the weights from our
preferred set of news shares in table 3, around the 1990-1991 and 2001 recessions. The three series shown are deflated by the GDP deflator, with the composite estimate deflated after combining. Compared with GDP, the composite estimate shows weaker recoveries from both these recessions: mean growth
in 1991 was 0.6% compared with 1.1% for GDP, and 1.5![]() versus 1.9% for GDP in 2002. The economy leading up to the 1990-1991 recession was weaker
as well, with average 1989 growth of the composite estimate at 2.0% versus 2.7%
for GDP. And the 2001 recession was more severe than indicated by GDP growth, with average growth for that year -0.5% versus 0.2% for GDP. In fitting structural economic relationships, these results should be of some interest.
versus 1.9% for GDP in 2002. The economy leading up to the 1990-1991 recession was weaker
as well, with average 1989 growth of the composite estimate at 2.0% versus 2.7%
for GDP. And the 2001 recession was more severe than indicated by GDP growth, with average growth for that year -0.5% versus 0.2% for GDP. In fitting structural economic relationships, these results should be of some interest.
It is interesting to note that in the fourth quarter of 1999, the growth rate of the combined estimate exceeds the growth rate of both GDP and GDI, while in the third quarter of 2001, the combined growth is less than each estimate. These examples reflect weights on the component series that sum
to more than one, a consequence of the assumption that the idiosyncratic variances of the component series are largely news.
![]() and
and
![]() are independent pieces of information about "true" nominal GDP growth, independent of each other and the common information
are independent pieces of information about "true" nominal GDP growth, independent of each other and the common information
![]() . Adding these three terms together gives an estimate of the variance of "true" GDP growth
. Adding these three terms together gives an estimate of the variance of "true" GDP growth
![]() , based on the information in GDP and GDI growth, but this represents a lower bound on the actual variance of
, based on the information in GDP and GDI growth, but this represents a lower bound on the actual variance of
![]() since there is likely additional information about
since there is likely additional information about
![]() contained in neither available estimate. This lower bound of 5.86 is greater than the variance of either GDP or GDI growth, a fact with potentially important implications
for a wide class of economic models that depend importantly on the variance of the growth rate of the economy, for example many real business cycle and asset pricing models.
contained in neither available estimate. This lower bound of 5.86 is greater than the variance of either GDP or GDI growth, a fact with potentially important implications
for a wide class of economic models that depend importantly on the variance of the growth rate of the economy, for example many real business cycle and asset pricing models.
5 Conclusions
This paper makes a general point about heretofore implicit assumptions employed in taking weighted averages of imperfectly measured statisics, and uses insights from that general point to develop new estimates of aggregate economic activity - "true" unobserved GDP growth - as a weighted average of measured GDP and GDI growth. These two measures should coincide in principle since the underlying concept they attemp to measure is the same, but they do not due to differences in source data. Combining them in some way may produce an estimate that is superior to either one in isolation, but previous attempts to do so have made the strong implicit assumption that the idiosyncratic variation in each measured statistic is pure noise, or completely uncorrelated with "true" GDP. Our model relaxes this assumption, allowing the idiosyncratic variation in each measured statistic to be partly or pure news - i.e. correlated with "true" GDP. This generalized model may weight more heavily the statistic with higher variance, since it may contain a greater amount of information about "true" GDP, in contrast to previous models which always weight less heavily the statistic with higher variance, assuming it contains more measurement error.
We develop new techniques for decomposing revisions into news and noise, and use the revisions evidence to place lower bounds on the shares of idiosyncratic variation in GDP and GDI that are news. Our identification scheme assumes that revisions can only add news or decrease noise, as in Mankiw, Runkle and Shapiro (1984) and Mankiw and Shapiro (1986), and numerous papers following in that tradition. The initial GDI estimates have little idiosyncratic variance, less than GDP, but after passing through revisions the idiosyncratic variance of GDI increases substantially. The fact that this idiosyncratic variation stems from revisions, which add news but not noise, leads to the strong presumption that this variation is news. The techniques we develop for bounding the idiosyncratic news shares show how to test the pure noise model assumptions, which we reject at conventional significance levels: some of the idiosyncratic variation in GDI growth must be news. When combining the revised vintages of the estimates, these results indicate that placing a greater weight on GDI is optimal, precisely because of its greater idiosyncratic variation. Doing so alters economic history in interesting ways: for example both before and after the 1990-1991 recession, economic growth is substantially weaker than indicated by GDP growth. In addition, our results indicate that the true variance of the growth rate of the economy is not equal to the variance of measured GDP growth, as is often assumed in real business cycle, asset pricing, and other models; the true variance is actually higher.
The news vs. noise considerations highlighted here are ubiquitous when attempting to estimate unobserveables. Take the well known index of coincident indicators as constructed by Stock and Watson (1989), used by Diebold and Rudebusch (1996) and many other economists. Stock and Watson decompose each of four time series into a common factor plus an idiosyncratic component; a time series that covaries relatively less with the other three will receive less weight in the common factor and have higher idiosyncratic variance. Stock and Watson define the state of the economy as this common factor, so a series with greater (relative) idiosyncratic variance receives less weight in this construct. Is this best weighting? There may be good reasons to define the state of the economy as this common factor, following the venerable tradition of Burns and Mitchell (1946). However if we define the state of the economy as something other than this common factor, the answer to this question is unclear: if the idiosyncratic components of the time series are noise, the Stock and Watson approach is appropriate, but if the idiosyncratic components are news, then time series that contain much idiosyncratic variation are uniquely informative about the state of the economy, and should be weighted more heavily.
This same point is applicable to the burgeoning literature on dynamic factor models using large datasets. For example, Bernanke et al (2005) equate linear combinations of common factors with four unobserved variables: (1) the output gap, (2) a cost-push shock, (3) output, and (4) inflation. They take these last two as unobserveable due to measurement difficulties, in the same spirit as our work here. However it is unlikely that the idiosyncratic components of all 120 time series they use to extract the common factors are uncorrelated with these four unobserveables. For example, our results indicate that information from the income side of the national accounts probably contains useful information about the growth rate of output, above and beyond the information contained in expenditure-side variables. So it may be possible to improve the results in Bernanke et al (2005), for example by allowing correlation between unobserveables (1) or (3) and the idiosyncratic components of their employment and income variables.
These examples illustrate that the noise assumption, treating idiosyncratic variance as a bad, is often implicit in models of imperfect measurement. We have examined some circumstances for which this assumption may be inappropriate, where it is possible that idiosyncratic variance should be treated as a good instead. While realizing this leads to some fundamental indeterminancies, our work here has taken some initial steps towards deriving estimators appropriate for handling these situations.
Equation (3') with the pure noise assumptions yields
![]() , essentially the estimator presented in Weale
(1992).17 This paper applied to the case of U.S. GDP and GDI the techniques developed in Stone, Champernowne, and Meade (1942) and Byron (1978); see also
Weale (1985), and Smith, Satchell, and Weale (1998). In the general case, Stone et al (1942) considered a row vector of estimates
, essentially the estimator presented in Weale
(1992).17 This paper applied to the case of U.S. GDP and GDI the techniques developed in Stone, Champernowne, and Meade (1942) and Byron (1978); see also
Weale (1985), and Smith, Satchell, and Weale (1998). In the general case, Stone et al (1942) considered a row vector of estimates ![]() that should but do not satisfy the set of accounting
constraints
that should but do not satisfy the set of accounting
constraints ![]() . They produce a new set of estimates
. They produce a new set of estimates
![]() that satisfy the constraints by solving the constrained quadratic minimization problem:
that satisfy the constraints by solving the constrained quadratic minimization problem:
| (A.1) | ||
| S.T. |
The matrix
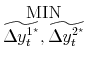 |
![\displaystyle \left( \begin{array}[c]{cc}% \widetilde{\Delta y_{t}^{1^{\star}}}-\Delta y_{t}^{1} & \widetilde{\Delta y_{t}^{2^{\star}}}-\Delta y_{t}^{2}% \end{array} \right) V^{-1} \left( \begin{array}[c]{c}% \widetilde{\Delta y_{t}^{1^{\star}}}-\Delta y_{t}^{1}\ \widetilde{\Delta y_{t}^{2^{\star}}}-\Delta y_{t}^{2}% \end{array} \right)](img148.gif)
|
|
| S.T. |
Substituting the constraint into the objective function, we have:
| (A.2) | ![\displaystyle \left( \begin{array}[c]{cc}% \widetilde{\Delta y_{t}^{\star}}-\Delta y_{t}^{1} & \widetilde{\Delta y_{t}^{\star}}-\Delta y_{t}^{2}% \end{array} \right) V^{-1} \left( \begin{array}[c]{c}% \widetilde{\Delta y_{t}^{\star}}-\Delta y_{t}^{1}\ \widetilde{\Delta y_{t}^{\star}}-\Delta y_{t}^{2}% \end{array} \right) ,](img151.gif)
|
with
![\displaystyle = \left( \begin{array}[c]{cc}% \tau^{2}_{1} & 0\ 0 & \tau^{2}_{2}% \end{array} \right) .](img154.gif) |
Solving the quadratic minimization problem with this
Problem (A.2) is a different minimization problem than the least squares minimization problems that we solve in this paper, where we solve for the weights in (1) or (1') and then compute the predicted values
![]() ; problem (A.2) solves for
; problem (A.2) solves for
![]() directly, leaving the weights implicit. In solving for the weights in (1) or (1'), assumptions must be made about the covariances between
directly, leaving the weights implicit. In solving for the weights in (1) or (1'), assumptions must be made about the covariances between
![]() and the estimates
and the estimates
![]() , whereas in (A.2) assumptions must be made about
, whereas in (A.2) assumptions must be made about ![]() ; as we have
seen, when these assumptions are equivalent and when some constraints are applied to (1), the two approaches can give the same result. Comparing the Stone, Champernowne, and Meade (1942) approach with the approach taken here, in a more general setting such as in (A.1), is beyond the scope of this
paper, but is another interesting avenue for future research.
; as we have
seen, when these assumptions are equivalent and when some constraints are applied to (1), the two approaches can give the same result. Comparing the Stone, Champernowne, and Meade (1942) approach with the approach taken here, in a more general setting such as in (A.1), is beyond the scope of this
paper, but is another interesting avenue for future research.
We will consider two efficient estimates of true GDP growth, one based on consumption growth, and the other based on the growth rate of investment. After constructing each efficient estimate, we will discuss how to produce the improved estimate of true GDP growth by combining them with equation (5).
Let
![]() ,
,
![]() ,
,
![]() , and
, and
![]() be the contributions to true GDP growth
be the contributions to true GDP growth
![]() of consumption, investment, government, and net exports, so:
of consumption, investment, government, and net exports, so:
For simplicity, we will examine the case where neither
The relation between
![]() and
and
![]() determines the nature of the efficient estimates and weights on
determines the nature of the efficient estimates and weights on
![]() and
and
![]() in equation (5). Consider first the case where these variables are independent. Then:
in equation (5). Consider first the case where these variables are independent. Then:
There is no information common to
Next consider the case where
![]() and
and
![]() are perfectly correlated, so:
are perfectly correlated, so:
 |
Given that
Finally consider the general linear case. In this case:
Least squares projections tell us that
The variance parameters of the news model are identified from the following relations:
Substituting
It should be pointed out that, when combining
![]() and
and
![]() in this particular example, using equation (5) is not the most natural way to proceed. An easier and more intuitive procedure would be to set
in this particular example, using equation (5) is not the most natural way to proceed. An easier and more intuitive procedure would be to set
![]() to zero in
to zero in
![]() , set
, set
![]() to zero in
to zero in
![]() , and then combine, producing:
, and then combine, producing:
Consider first the covariance between the revision to GDP growth and the revision to GDI growth:
| (C.1) |
The change in the covariance between GDP growth and GDI growth (pre- and post-revision) is a more complicated expression:
| (C.2) | ||
using the independence of the noise terms from the conditional expectations.
Drilling down further, for the covariance between the conditional expectations in (C.2), we have
![]() , and:
, and:
| (C.3) | ||
The common news in the "last" estimates is equal to the common news in the "first" estimates plus terms stemming from the revisions. The last term
Similarly, for the noise terms in (C.2),
![]() , and:
, and:
| (C.4) |
The common noise in the "last" estimates equals the common noise in the "first" estimates minus three revision terms. The last term
Substituting (C.3) and (C.4) into (C.2) yields:
| (C.5) |
The relation between (C.1) and (C.5) is evidently a bit more complicated than the relation between (7) and (8); there is no unique solution for the six terms appearing in these two equations.
Next consider the idiosyncratic news in the "last" estimate of ![]() . This is equal to the idiosyncratic news in the "first" estimate of
. This is equal to the idiosyncratic news in the "first" estimate of ![]() , minus the part of this idiosyncratic news revealed to
, minus the part of this idiosyncratic news revealed to ![]() by revision (and hence transforming it to common news), plus the
idiosyncratic news added to
by revision (and hence transforming it to common news), plus the
idiosyncratic news added to ![]() by revision,
by revision,
![]() :
:
| (C.6) |
The overall increase in news from revisions, computed from (7) and (8), is the sum of this change in idiosyncratic news (C.6) and the change in common news as computed from (C.3):
| (C.7) |
Finally consider the idiosyncratic noise in each "last" estimate. Let
![]() be the idiosyncratic noise in
be the idiosyncratic noise in
![]() eliminated by revision. Noise common to the two "first" estimates that is eliminated from
eliminated by revision. Noise common to the two "first" estimates that is eliminated from ![]() but not
but not ![]() now appears as idiosyncratic noise in the "last"
now appears as idiosyncratic noise in the "last" ![]() estimate, so:
estimate, so:
| (C.8) |
The overall noise reduction from revisions, computed from (7) and (8), is the sum of this change in idiosyncratic noise (C.8) and the change in common noise as computed from (C.4):
| (C.9) |
Equations (C.7) and (C.9) for ![]() , (C.1) and (C.5) are six equations in ten unknowns (
, (C.1) and (C.5) are six equations in ten unknowns (
![]() and
and
![]() for
for ![]() and the six terms on the right-hand side of (C.5)). These
six equations limit the admissable values for the ten unknowns, which in turn limit the range of admissable values for
and the six terms on the right-hand side of (C.5)). These
six equations limit the admissable values for the ten unknowns, which in turn limit the range of admissable values for
![]() and
and
![]() as can be seen from (C.6) and (C.8). For the "first" estimates, the admissable values for
as can be seen from (C.6) and (C.8). For the "first" estimates, the admissable values for
![]() are constrained by
are constrained by
![]() , while
, while
![]() is constrained by
is constrained by
![]() . We also have:
. We also have:
| (C.10) |
| Measure | (1)
|
(2)
|
(3) (2)-(1) |
(4)
Revision:
Total |
(5)
Revision:
|
(6)
Revision:
|
|---|---|---|---|---|---|---|
|
|
4.18 | 4.18 | 0.00 | 1.91 | 0.96 | 0.96 |
|
|
3.61 | 5.15 | 1.64 | 2.31 | 1.93 | 0.39 |
|
|
3.48 | 3.15 | -0.33 | 0.71 | ? | ? |
|
|
|
|
|
|
|---|---|---|---|---|
|
|
0.22 | 1.00 | 0.11 | 1.00 |
|
|
0.46 | 0.86 | 0.61 | 0.65 |
|
|
0.41 | 0.58 | 0.00 | 1.00 |
|
|
0.08 | 1.00 | 1.00 | 0.00 |
| 0.61 | 0.81 | 0.66 | 0.73 |
| Vintage |
|
|
|
|
||||
|---|---|---|---|---|---|---|---|---|
| First | 5.56
(0.21) |
3.44
(0.57) |
0.72
(0.23) |
0.13
(0.20) |
0.44
(0.02) |
0.16
(0.03) |
0.45
(0.16) |
0.39
(0.19) |
| Last | 5.71
(0.21) |
3.11
(0.61) |
1.03
(0.41) |
1.98
(0.48) |
0.40
(0.04) |
0.55
(0.03) |
0.53
(0.11) |
0.63
(0.08) |