Dynamic Factor Value-at-Risk for Large,
Heteroskedastic Portfolios*
Keywords: Value-at-Risk, dynamic factor models, stock portfolios
Abstract:
JEL Classification: C1, C22, C22.
1 Introduction
As described in Berkowitz & O'Brien (2002) and Berkowitz & O'Brien (2006), trading portfolios at large financial institutions exhibit two key characteristics: they are driven by a large number of financial variables, such as stock returns, credit spreads, or yield curves, and these variable have time-varying volatilities and correlations. To accurately capture risks in such portfolios, it is important for risk managers to select Value-at-Risk (VaR) methodologies that adequately handle these two characteristics. This paper presents one such VaR methodology that is based on Dynamic Factor Models (DFM, see for instance Stock & Watson (2002)).
When a trading portfolio is driven by a large number of financial variables, Historical Simulation (HS-VaR) is the standard industry practice for computing VaR measures (see, among others, Perignon & Smith (2010) and Berkowitz et al. (2009)). HS-VaR treats past realizations of the financial variables as scenarios for future realizations. Although the HS-VaR is easy to compute, it is not well-suited to capture the time-varying volatilities in financial variables (Pritsker (2006)). Barone-Adesi et al. (1999) and Hull & White (1998) introduced Filtered Historical Simulation (FHS-VaR) as a way of handling time-varying volatility in VaR estimation. In cases where the VaR depends on multiple financial variables, Barone-Adesi et al. (1999) and Pritsker (2006) suggest filtering each variable independently. Univariate filtering imposes a high computational burden, because filtering must be done one variable at a time.1 In addition, FHS-VaR does not explicitly capture time-varying correlations among the financial variables, which may be important particularly during times of financial stress.
We introduce DFM-VaR as a means of capturing the time-varying volatilities and correlations of a large number of financial variables in a VaR estimation. Our main assumption is that the large panel of variables are driven by a smaller set of latent factors. By modeling financial variables through a DFM with time-varying volatilities and correlations among the latent factors, the number of volatilities and correlations to be estimated is greatly reduced, resulting in computational efficiency.
To evaluate whether the DFM-VaR accurately captures risks in financial markets, we combine the DFM with the Dynamic Conditional Correlation (DCC) model of Engle (2002) to estimate VaRs for three stock portfolios: one equally-weighted portfolio of large US stocks, one portfolio with time-varying weights based on momentum, and one portfolio with time-varying weights based on the slope of option implied volatility smile. Several DFM-VaRs with different specifications are compared to the HS-VaR and the FHS-VaR based on univariate filtering. We find that the DFM-VaRs perform better than HS-VaR and FHS-VaR in terms of back-testing breaches and average breach-size in most cases. As expected, the DFM-VaRs were much more efficient to estimate than the FHS-VaR.
We would like to emphasize that our innovation is to use DFM as a way to model VaR in an environment where a large panel of financial variables exhibit time-varying volatilities. The general idea of combining latent factors with GARCH was proposed by Alexander (2001) and Alexander (2002), while theoretical properties of DFM-DCC models were explored by Alessi et al. (2009). These studies provide a platform for this paper to demonstrate how the DFM can be applied effectively in portfolio risk management.
The remainder of the paper is organized as follows. Section 2 describes the general framework for VaR estimation. Section 3 further describes the HS-VaR and FHS-VaR approaches to which we compare the DFM-VaR methodology. Section 4 details the estimation of the DFM-VaR. Section 5 introduces the data and the three test portfolios we use in the empirical analysis. Performances of the VaRs and the associated statistical tests are documented in Section 6. In Section 7, we provide robustness tests to show how the DFM-VaR measures risk for individual stocks which are sensitive to systematic shocks. The last section contains concluding remarks and thoughts for future research. Tables and figures can be found in the Appendix.
2 Economic Problem
Focusing on a one period holding horizon for a trading portfolio,2 the objective is to calculate the ![]() VaR of a portfolio of traded assets, conditional on the information available at time
VaR of a portfolio of traded assets, conditional on the information available at time ![]() .3
.3
Let
![]() be the profit-and-loss of the portfolio at
be the profit-and-loss of the portfolio at ![]() , and
, and
![]() the information set up to time
the information set up to time ![]() . The definition of VaR at level
. The definition of VaR at level
![]() is:
is:
Assume that
where
where
When using (2.2) to calculate ![]() VaR conditional on
VaR conditional on
![]() , we assume that
, we assume that
![]() is known at
is known at ![]() .4 The goal is to estimate the conditional distribution of
.4 The goal is to estimate the conditional distribution of
![]() and choose its
and choose its
![]() quantile as the VaR estimate, as in (2.1). Under the assumption that
quantile as the VaR estimate, as in (2.1). Under the assumption that
![]() is known, the problem reduces to the estimation of the conditional distribution
is known, the problem reduces to the estimation of the conditional distribution
![]() . For this purpose, the risk manager can obtain either parametric or nonparametric estimates of the distribution of
. For this purpose, the risk manager can obtain either parametric or nonparametric estimates of the distribution of
![]() . He then either obtains a closed form solution for the conditional distribution of
. He then either obtains a closed form solution for the conditional distribution of
![]() , or makes draws to obtain scenarios for that distribution. The latter case is usually referred to as the simulation approach to VaR.
, or makes draws to obtain scenarios for that distribution. The latter case is usually referred to as the simulation approach to VaR.
3 Historical and Filtered Historical Simulation
Deriving the distribution of
![]() becomes difficult when its dimension is large. In such cases, the standard practice is to use HS-VaR, where past realizations of
becomes difficult when its dimension is large. In such cases, the standard practice is to use HS-VaR, where past realizations of
![]() are used to build the distribution of
are used to build the distribution of
![]() . The only choice the risk manager faces is the length of the data window. For instance, it is popoular in the industry to use realizations of
. The only choice the risk manager faces is the length of the data window. For instance, it is popoular in the industry to use realizations of
![]() in the past 250 trading days as the empirical distribution of
in the past 250 trading days as the empirical distribution of
![]() .
.
Given that HS-VaR is not well suited to handling time-varying volatilities in
![]() (Pritsker (2006)), researchers have embraced FHS-VaR. FHS-VaR first "filters" each variable in
(Pritsker (2006)), researchers have embraced FHS-VaR. FHS-VaR first "filters" each variable in
![]() using an appropriate volatility model (typically GARCH), then uses the estimated volatility models to forecast the volatilities of the variables at
using an appropriate volatility model (typically GARCH), then uses the estimated volatility models to forecast the volatilities of the variables at ![]() , and finally assigns the volatility forecasts to scenarios of filtered variables (i.e., variables divided by the estimated volatilities) to generate scenarios for
, and finally assigns the volatility forecasts to scenarios of filtered variables (i.e., variables divided by the estimated volatilities) to generate scenarios for
![]() .5
.5
Implementation of FHS-VaR runs into two issues when ![]() is large. First, because each variable in
is large. First, because each variable in
![]() is modeled individually, FHS-VaR does not capture correlations between time-varying volatilities - only unconditional correlations among the filtered variables are captured
(Pritsker (2006)). Second, estimating a separate time-varying volatility model for each variable typically requires a significant computational effort.
is modeled individually, FHS-VaR does not capture correlations between time-varying volatilities - only unconditional correlations among the filtered variables are captured
(Pritsker (2006)). Second, estimating a separate time-varying volatility model for each variable typically requires a significant computational effort.
An obvious alternative to univariate filtering is to construct FHS-VaR using multivariate time-varying volatility models, as in Engle & Kroner (1995) or Engle (2002). These methods have the potential to capture correlations, but do not
lighten the computational burden, because the number of parameters to be estimated is typically in proportion to ![]() . Recent papers such as Engle & Kelly
(2009), Engle (2007) and Engle et al. (2007) have proposed solutions to modeling multivariate time-varying volatilities based on various dimension reduction techniques. The DFM-VaR that we introduce also operates by reducing
the dimensionality of the problem. The appealing feature of the DFM framework is that it relates closely to the factor model analysis of asset returns (e.g., Fama & French (1996)).
. Recent papers such as Engle & Kelly
(2009), Engle (2007) and Engle et al. (2007) have proposed solutions to modeling multivariate time-varying volatilities based on various dimension reduction techniques. The DFM-VaR that we introduce also operates by reducing
the dimensionality of the problem. The appealing feature of the DFM framework is that it relates closely to the factor model analysis of asset returns (e.g., Fama & French (1996)).
4 DFM-VaR Methodology
The applications and properties of DFMs have been documented by, among others, Stock & Watson (2002), Bai & Ng (2007), Bai (2003), and Bai & Ng (2006). Our proposal is to model
![]() as a DFM with time-varying volatility. Various implementations of this type of model have been discussed by Alexander (2001), Alexander (2002) and Alessi et al. (2009). The model we adopt for VaR estimation follows closely to that of Alessi et al. (2009). In particular, we use the DCC volatility model of
Engle (2002). While possible alternative specifications include square root processes (Cox et al. (1985)), or jumps in addition to stochastic volatility, we focus on the set of GARCH models because the theoretical properties of the
DFM-GARCH has already been analyzed by Alessi et al. (2009).
as a DFM with time-varying volatility. Various implementations of this type of model have been discussed by Alexander (2001), Alexander (2002) and Alessi et al. (2009). The model we adopt for VaR estimation follows closely to that of Alessi et al. (2009). In particular, we use the DCC volatility model of
Engle (2002). While possible alternative specifications include square root processes (Cox et al. (1985)), or jumps in addition to stochastic volatility, we focus on the set of GARCH models because the theoretical properties of the
DFM-GARCH has already been analyzed by Alessi et al. (2009).
Let the financial variables
![]() be a vector stationary process with mean zero. The DFM model posits that
be a vector stationary process with mean zero. The DFM model posits that
![]() can be decomposed into a systematic component, driven by a
can be decomposed into a systematic component, driven by a ![]() vector of latent factors
vector of latent factors ![]() , and an idiosyncratic component
, and an idiosyncratic component
![]() . The key is that
. The key is that ![]() , so that the variation of a large
number of variables can be explained with a small set of systematic factors:
, so that the variation of a large
number of variables can be explained with a small set of systematic factors:
where
Following Engle (2002) and Engle & Sheppard (2008),
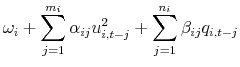
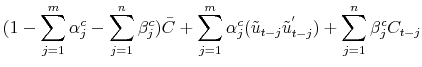
and
In addition, to facilitate the computation of VaR, we impose that the error vector
![]() is IID across time. This assumption does not rule out contemporaneous cross-sectional correlation between elements of the error vector.
is IID across time. This assumption does not rule out contemporaneous cross-sectional correlation between elements of the error vector.
If
![]() , we can re-write the above model in a State Space (SS) representation with a single lag,6
, we can re-write the above model in a State Space (SS) representation with a single lag,6
where
Let
![]() be information up to and including time
be information up to and including time ![]() . Then, to obtain the
forecast distribution of
. Then, to obtain the
forecast distribution of
![]() conditional on
conditional on
![]() , we can use the SS representation as follows:
, we can use the SS representation as follows:
Note, to get a forecast distribution of
- Step 1.
- Using the Principal Components (PC) methods of Stock & Watson (2002), Bai (2003) and Bai & Ng (2006), obtain the following estimates for
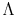 ,
,
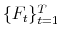 , and
, and
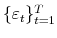 :
:
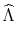
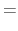
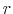 eigen-vectors of
eigen-vectors of
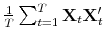 corresponding to the
largest eigenvalues
corresponding to the
largest eigenvalues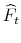
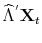 , for
, for 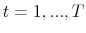
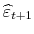
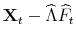
- Step 2.
- With the estimated static factors
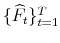 , run the vector autoregression in (4.6), obtain coefficient estimates
, run the vector autoregression in (4.6), obtain coefficient estimates
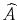 , and VAR residuals
, and VAR residuals
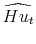 . Following Alessi et al. (2009), estimate
. Following Alessi et al. (2009), estimate 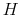 using
using
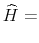 first
first 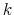 eigen-vectors of
eigen-vectors of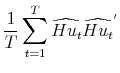
Then, estimate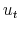 by
by
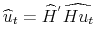 .
. - Step 3.
- Use
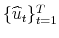 to estimate the DCC model in (4.5), obtain estimates of the DCC parameters,
to estimate the DCC model in (4.5), obtain estimates of the DCC parameters,
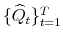 and
and
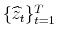 . Using these, build the
. Using these, build the 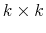 conditional
variance-covariance matrix forecast
conditional
variance-covariance matrix forecast
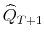 .8
.8 - Step 4.
- Finally, build scenarios for
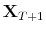 using
using
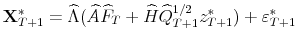 , where
, where
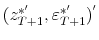 are drawn from
are drawn from
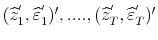 . One can then build scenarios for
. One can then build scenarios for
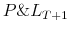 as
as
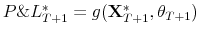 , and choose the appropriate percentile as the VaR estimate
, and choose the appropriate percentile as the VaR estimate
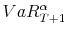 .
.
Finally, using PCs to estimate DFMs will yield factors and loadings that are identified up to a unitary transformation. However, the common component ![]() and the idiosyncratic
shocks
and the idiosyncratic
shocks
![]() are exactly identified. It follows from the results of Alessi et al. (2009) that, if one imposes the additional restriction that
are exactly identified. It follows from the results of Alessi et al. (2009) that, if one imposes the additional restriction that
![]() , the scenarios of
, the scenarios of
![]() form a distribution that consistently estimates the true conditional distribution of
form a distribution that consistently estimates the true conditional distribution of
![]() as
as
![]() .
.
5 Data and Portfolio Construction
We collect daily returns on the stocks in CRSP (share codes 10 and 11) that commonly trade on the NYSE, AMEX, and NASDAQ. We use only stocks that have non-missing returns on almost all trading days from 2007 to 2009. Our final data set contains daily returns on 3,376 stocks across 750 trading days. All VaRs (DFM-VaR, HS-VaR and FHS-VaR) are estimated using this data set, after returns of each stock are winsorized at the 0.25% and 99.75% quantiles of the returns time series distribution.
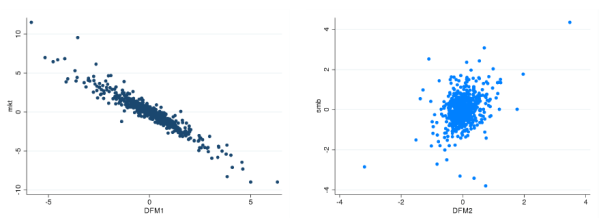
To get a flavor of the nature of the factors used to construct DFM-VaR extracted from this panel of stock returns, Table 8.1 in the Appendix reports the correlations between
the first two principal components of
![]() ,
, ![]() and
and
![]() , and a set of asset pricing factors that includes the Fama-French and momentum factors, as well as the changes on the CBOE's VIX index and returns on the CBOE's PUT index. The VIX and
the PUT indices are created to track volatility and downside risk, respectively. The results show a -95.5% correlation between
, and a set of asset pricing factors that includes the Fama-French and momentum factors, as well as the changes on the CBOE's VIX index and returns on the CBOE's PUT index. The VIX and
the PUT indices are created to track volatility and downside risk, respectively. The results show a -95.5% correlation between ![]() and the market, and a moderate correlation between
and the market, and a moderate correlation between
![]() and both smb (35.4%) and hml (21.5%) (see Figure 8.2 in the appendix).
and both smb (35.4%) and hml (21.5%) (see Figure 8.2 in the appendix).
We form three test portfolios with the stock returns data: one that replicates a broad market index, one based on the momentum effect, and one that includes stocks more likely to experience large swings in prices, as proxied by the slope of the option implied volatility smile.
The first portfolio (S&P 500) is the equally-weighted average return on the S&P 500 constituents as of the end of June 2008, with weights that remain constant throughout the sample period. The second portfolio (Momentum) is the 6-6
overlapping momentum portfolio of Jegadeesh & Titman (1993). The portfolio is designed to go long/short in the stocks with the highest/lowest returns over the past six months, and is rebalanced every six months. The overlapping feature of the portfolio means
that weights typically change every month. The third portfolio (Money) is based on the slope of the implied volatility smile of equity options.9 We define the Money portfolio as the equally-weighted average return of the stocks with the lowest regression slope coefficients (bottom 30% of the distribution in ![]() ), where the slopes are estimated in a manner similar to Bakshi et al. (2003) by regressing the log-implied volatility on the log-moneyness (
), where the slopes are estimated in a manner similar to Bakshi et al. (2003) by regressing the log-implied volatility on the log-moneyness (
![]() ). We focus on daily regressions, consider both in-the-money and out-of-the-money prices, and require a minimum of three observations with maturity between 20 and 40 calendar
days. While our approach is more prone to picking noise in the variation of implied volatility slopes, it does provide portfolio weights that change at a higher frequency.10
). We focus on daily regressions, consider both in-the-money and out-of-the-money prices, and require a minimum of three observations with maturity between 20 and 40 calendar
days. While our approach is more prone to picking noise in the variation of implied volatility slopes, it does provide portfolio weights that change at a higher frequency.10
Table 8.3 in the appendix presents summary statistics for the observed returns of the three portfolios. We point out that the S&P 500 portfolio has the highest mean return while the Money portfolio shows the highest volatility. We also note that the Momentum portfolio has a large negative skew, consistent with a financial crisis period.
6 VaR Estimations and Results
We compare the DFM-VaR, HS-VaR and FHS-VaR along three dimensions: the number of VaR breaches, the average size of the breaches, and computational time. The number of breaches is the primary indicator of VaR performance used in the literature as well as in bank regulation.11 If the VaR model is good, we would expect that the 99% VaR, for instance, to be breached by realized portfolio 1% of the time. Average breach size is an indicator of how severe the breaches are, and a decent VaR model is expected to experience reasonablely-sized breaches. Finally, computation time of each VaR measures how efficiently the VaRs can be calculated, which is a very important practical consideration for large financial institutions.
In order to statistically assess the performance of the VaRs, numerous tests have been proposed by the literature, such as the ones in Kupiec (1995), Christoffersen & Pelletier (2004), Engle & Manganelli (2004) and Gaglianone et al. (2011). The majority of these tests are based on statistical properties of the frequency at which breaches occur. As we will describe in details, we perform two tests that are popular in the literature for all VaRs that we calculate. While an evaluation of performances of these tests are out of the scope of this paper, we remind the reader to interpret the results of these tests with caution, particularly because two of our three test portfolios changes over time.12
Formally, a "breach" variable can be defined as:
![\displaystyle B_{t}^{\alpha} =\left\{ \begin{array}[c]{cc} 1 & \text{if } P\&L_{t} <VaR_{t}^{\alpha}\\ 0 & \text{if } P\&L_{t} \geqslant VaR_{t}^{\alpha}\\ \end{array} \right.](img121.gif) |
(6.1) |
Therefore breaches form a sequence of zeros and ones. If the VaR model is correctly specified, the conditional probability of a VaR breach would be
| (6.2) |
for every
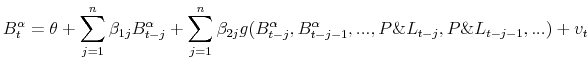 |
(6.3) |
and we set
As suggested by the same authors, we assume that the error term ![]() has a logistic distribution and we estimate a logit model. We test the null that the
has a logistic distribution and we estimate a logit model. We test the null that the ![]() coefficients are zero and
coefficients are zero and
![]() . Inference is based on a likelihood ratio test, using Monte Carlo critical values of Dufour (2006) to alleviate nuisance parameter and
power concerns. Large p-values indicate that one cannot reject the null that the breaches are independent and the number of unconditional breaches is at the desired confidence level.
. Inference is based on a likelihood ratio test, using Monte Carlo critical values of Dufour (2006) to alleviate nuisance parameter and
power concerns. Large p-values indicate that one cannot reject the null that the breaches are independent and the number of unconditional breaches is at the desired confidence level.
The CaViaR test relies heavily on the number of breaches. Since breaches are considered rare events, this test may suffer from the lack of power. Building on this reasoning, Gaglianone et al. (2011) propose a new approach which does not rely solely on binary breach variables. This is the second test we use. The idea behind the test is a quantile regression to test the null hypothesis that the VaR estimate is also the correct estimate of the quantile of the conditional distribution of portfolio returns. This framework should be viewed as a Mincer & Zarnowitz (1969)-type regression framework for a conditional quantile model, and, as such, we refer to it as the Quantile test. The test is based on the comparison of a Wald statistic to a Chi-squared distribution, and a large p-value indicates that one cannot reject the null that the VaR is indeed the correct estimate of the conditional quantile. The Quantile test makes use of more information since it does not solely depend on binary variables, and therefore, as argued by Gaglianone et al. (2011), has better power properties.
6.1 Results
We estimate one day ahead, out-of-sample HS-VaR, FHS-VaR, and three DFM-VaRs for 500 trading days in 2008 - 2009, using a rolling historical window of 250 trading days. For DFM-VaR, we consider three cases: the first two cases set ![]() , but
, but ![]() , while the third case sets
, while the third case sets ![]() and
and ![]() . We note that the cases where
. We note that the cases where ![]() are more in line
with the established fact that stock returns, in general, do not display auto-correlation in first moments at a daily frequency. In the DCC component of DFM-VaR, we set
are more in line
with the established fact that stock returns, in general, do not display auto-correlation in first moments at a daily frequency. In the DCC component of DFM-VaR, we set ![]() and
and
![]() for all
for all ![]() . We compute FHS-VaR by univariate filtering. We
run a GARCH(1,1) on each of the
. We compute FHS-VaR by univariate filtering. We
run a GARCH(1,1) on each of the ![]() stocks, forecast the conditional volatilities of each risk factor at
stocks, forecast the conditional volatilities of each risk factor at ![]() , and construct scenarios of
, and construct scenarios of
![]() based on these volatility forecasts. For all models, we estimate VaR at two different confidence levels, 99% and 95%.14 The VaRs are compared to portfolio returns calculated from the raw, unwinsorized data. In our opinion, this comparison is more interesting in that it acknowledges that the
winsorization process as part of the modeling technique, and should not necessarily receive credit in the model performance assessment.
based on these volatility forecasts. For all models, we estimate VaR at two different confidence levels, 99% and 95%.14 The VaRs are compared to portfolio returns calculated from the raw, unwinsorized data. In our opinion, this comparison is more interesting in that it acknowledges that the
winsorization process as part of the modeling technique, and should not necessarily receive credit in the model performance assessment.
6.1.1 Descriptive Figures
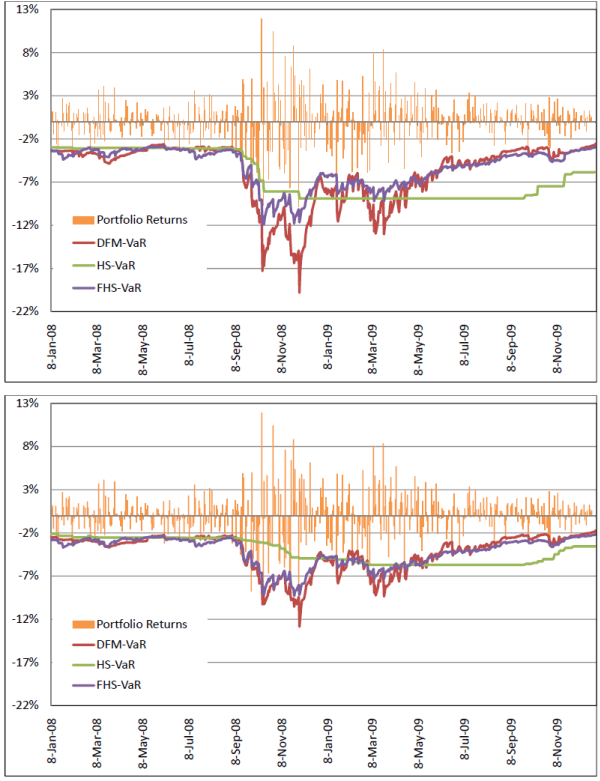
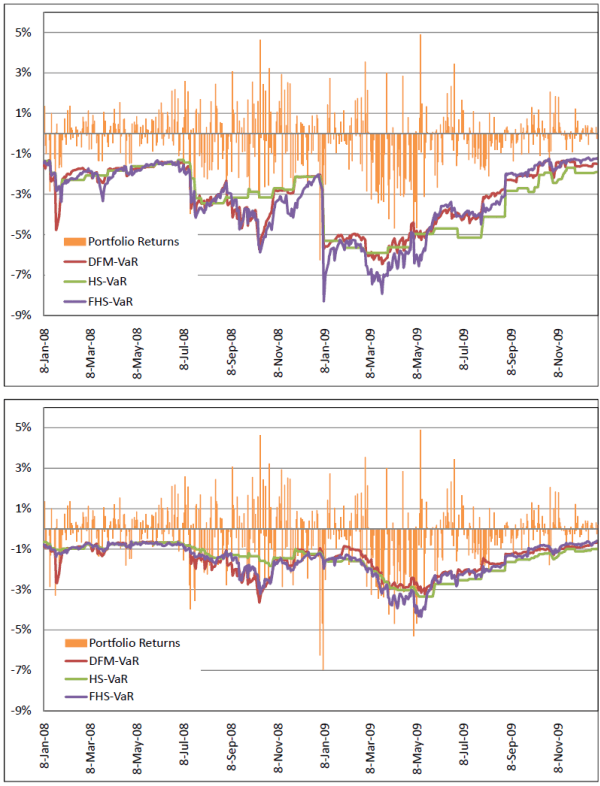
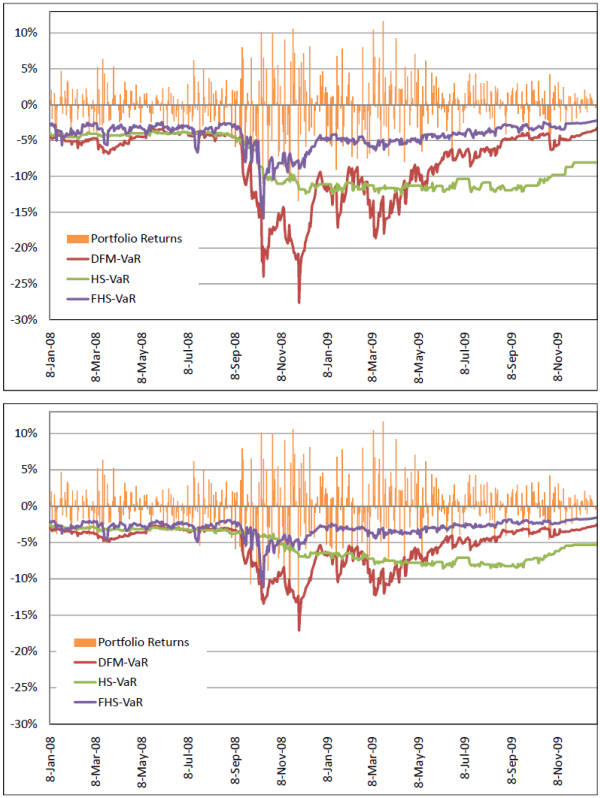
We begin the discussion of results by commenting on the time series plots of portfolio returns and VaR estimates in Figures 8.3 - 8.5. All DFM-VaRs in the figures are based on the case ![]() .15 The top panel in each figure displays the returns alongside the 99% VaRs, while the bottom panel displays returns alongside 95% VaRs. Figure 8.3 displays the return series and VaR estimates for the S&P 500 portfolio. Figure 8.4 displays the
return series and VaR estimates for the Momentum portfolio. Figure 8.5 displays the return series and VaR estimates for the Money portfolio.
.15 The top panel in each figure displays the returns alongside the 99% VaRs, while the bottom panel displays returns alongside 95% VaRs. Figure 8.3 displays the return series and VaR estimates for the S&P 500 portfolio. Figure 8.4 displays the
return series and VaR estimates for the Momentum portfolio. Figure 8.5 displays the return series and VaR estimates for the Money portfolio.
As argued in Pritsker (2006), HS-VaR is often very stale and outdated, even static. As is evidenced in the figures, the estimates move to a different level only when a significant negative shock occurs and remain there until the shock passes through the sample time frame. A careful comparison of the graphs shows that the portfolio with most composition variation (Money) produces a more dynamic HS-VaR, compared to the S&P 500 and Momentum portfolios. Still, this level of variability is not sufficient to prevent the HS-VaR from being overly conservative for certain periods, and insufficiently conservative for others.
The FHS-VaR is more responsive than the HS-VaR, and it generally moves in the same direction as the DFM-VaR. In fact, for the S&P 500 and Momentum portfolios, FHS-VaR is quite similar to the DFM-VaR. However, for the Money portfolio, FHS-VaR displays levels that lead to frequent breaches. We argue that since the FHS ignores the correlation across risk factors it tends to underestimate risk for the Money portfolio, which exhibits high levels of negative skewness and volatility.
6.1.2 VaR Evaluation Tests
In support of the descriptive figures, we now provide more formal evaluations of all VaRs. To briefly summarize the results to follow, the DFM-VaRs perform well, particularly when compared to HS-VaR, and they are also computationally efficient. The FHS-VaR also has reasonable performance for two out of three portfolios, but it is very computationally burdensome.
Table 8.4 displays the properties and results from statistical tests for all VaR methodologies at the 99% confidence level. The three panels in the table correspond to the three test portfolios. In Panel A, we observe that for the S&P 500 portfolio the DFM-VaRs display very reasonable VaR breaches (1.4% for all three DFM-VaRs, when 1% is expected), while the HS-VaR displays the most (2.8%). FHS-VaR also performs well in terms of VaR breaches, but the size of the breaches are on average substantially higher. (1.03%, compared to 0.66% - 0.75% for DFM-VaRs).
The last two rows in each of the panels display the p-values associated with the the CaViaR and Quantile tests. For the S&P 500 portfolio, the CaViaR test suggests that the null that VaR breaches are independent across time and occurs 1% of the time unconditionally cannot be rejected at a 10% significance level for DFM-VaR withPanel B presents the results for the Momentum portfolio. For this portfolio all VaRs experience too many breaches. FHS-VaR appears to perform the best in terms of breaches and average breach size, and two of the DFM-VaRs (![]() and
and ![]() ) experience similar performance as the FHS-VaR. The DFM-VaR when
) experience similar performance as the FHS-VaR. The DFM-VaR when ![]() performs quite poorly, indicating that the modeling of serial correlation in the factors may not be appropriate for this portfolio. The CaViaR test suggests that all the VaR models are incorrectly specified. With the
exception of the FHS-VaR, the Quantile test also suggests that all VaR estimates fail to capture the true conditional quantile. One could interpret these results as a challenge most methodologies face when dealing with strategies whose associated returns feature excessive negative skewness (see
Table 8.3).
performs quite poorly, indicating that the modeling of serial correlation in the factors may not be appropriate for this portfolio. The CaViaR test suggests that all the VaR models are incorrectly specified. With the
exception of the FHS-VaR, the Quantile test also suggests that all VaR estimates fail to capture the true conditional quantile. One could interpret these results as a challenge most methodologies face when dealing with strategies whose associated returns feature excessive negative skewness (see
Table 8.3).
Recall that the Money portfolio exhibits the largest standard deviation compared to the other two portfolios. In Panel C, we see that the FHS-VaR has the most breaches and the HS-VaR has the large average breach sizes. It is somewhat surprising that the FHS-VaR
performs so poorly for this portfolio, given the Money portfolio's similarities to the S&P 500 portfolio. The CaViaR test suggests that only the DFM-VaR when ![]() displays an acceptable performance at a 10% level, while it rejects all other VaRs at 10%, with particularly strong evidence of rejection for the FHS-VaR. Given its poor performance, it is not surprising that the FHS-VaR is the only VaR being rejected by the
Quantile test at the 10% level.
displays an acceptable performance at a 10% level, while it rejects all other VaRs at 10%, with particularly strong evidence of rejection for the FHS-VaR. Given its poor performance, it is not surprising that the FHS-VaR is the only VaR being rejected by the
Quantile test at the 10% level.
Table 8.5 exhibits the performances of 95% VaRs. The table is structured in the same way as Table 8.4. At this confidence level, the number of breaches is higher for all VaRs as expected (ideally, a VaR should be breached 5% of the time), while the average breach size is typically lower, due to the fact there are many more smaller breaches compared to the 99% VaRs, which tend to be breached only by quite extreme returns. The rankings of the different VaR models at the 95% level are similar to those at the 99% level: the DFM-VaRs generally work well; the FHS-VaR has similar performances as the DFM-VaRs except for the Money portfolio; all VaRs perform relatively poorly for the Momentum portfolio; and the HS-VaR unambiguously performs the worst for the S&P 500 and Money portfolios.
Finally, Table 8.6 compares the average time required by each VaR model to compute one out-of-sample VaR.16 Not surprisingly, HS-VaR is the most computationally efficient, because it requires virtually no modeling. Compared to the FHS-VaR, the DFM-VaRs are highly efficient: while the FHS-VaR takes more than 17 minutes to calculate each VaR, due to the univariate GARCH filtering applied to the 3,376 stocks, the DFM-VaR has average computation time ranging from only 7 to 10 seconds per VaR. From a practical perspective, DFM-VaRs are highly efficient.7 DFM-VaR for Individual Stocks
To the extent that large swings in individual stock prices are generated by systematic shocks, it appears that the DFM-VaR will be able to capture such movements through the extraction of systematic latent factors. Hence, we test whether the DFM-VaR produces better VaR estimates for stocks that have a higher proportion of systematic risk relative to total risk. Indeed, we find that the DFM-VaR generates fewer breaches for stocks with less idiosyncratic risk, relative to HS-VaR.
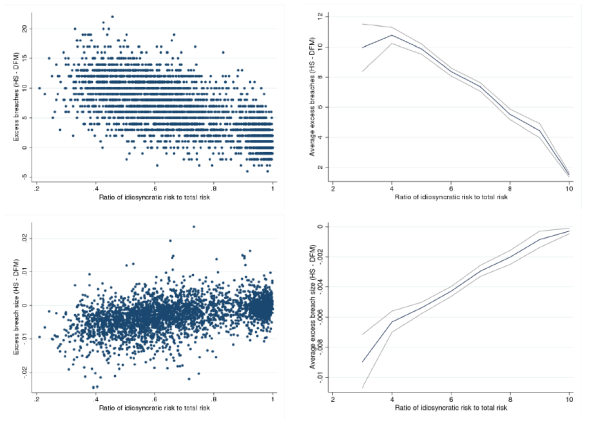
For each stock, we measure total risk as the variance of daily excess returns, and idiosyncratic risk as the variance of the residuals obtained by regressing daily excess returns on the following four factors: market, smb, hml, and momentum.17 The top panels of Figure 8.6 shows the number of breaches of the HS-VaR in
excess of the DFM-VaR (when ![]() and
and ![]() ), both for individual stocks (top-left
panel) and for portfolios of stocks with similar proportions of idiosyncratic risk (top-right panel). The average cumulative difference in the number of breaches (over 2008-2009) monotonically declines in statistically and economically significant terms with the proportion of idiosyncratic risk. In
fact, for stocks with little systematic risk, there is little difference between the HS-VaR and DFM-VaR estimates.
), both for individual stocks (top-left
panel) and for portfolios of stocks with similar proportions of idiosyncratic risk (top-right panel). The average cumulative difference in the number of breaches (over 2008-2009) monotonically declines in statistically and economically significant terms with the proportion of idiosyncratic risk. In
fact, for stocks with little systematic risk, there is little difference between the HS-VaR and DFM-VaR estimates.
8 Conclusions
This paper introduces a VaR methodology suitable for trading portfolios that are driven by a large number of financial variables with time-varying volatilities. The use of Dynamic Factor Models (DFM) in VaR allows the risk manager to accurately account for time-varying volatilities and correlations with relatively small computational burden. We test the method on three stock portfolios and show that DFM-VaR compares favorably to VaRs based on Historical Simulation (HS-VaR) and Univariate Filtered Historical Simulation (FHS-VaR) in terms of back-testing breaches and average breach sizes. In addition, DFM-VaRs are shown to be computationally efficient.
We construct three test portfolios to test the DFM-VaR: one that replicates a broad market index, one based on the momentum effect with portfolio weights that change every month, and one that includes stocks more likely to experience large swings in prices, as proxied by the slope of the options implied volatility smile, with portfolio weights that change every day. The three test portfolios differ in terms of the features of their returns distributions. Our descriptive figures illustrate some of the well-known deficiencies of the commonly-used HS-VaR approach, most notably its inability to capture time-varying volatility. On the other hand, the DFM-VaR and FHS-VaR perform reasonably well in general, but the DFM-VaR clearly out-performs the FHS-VaR in one portfolio.
We use two statistical tests to evaluate the proposed DFM-VaR. These tests are based on Engle & Manganelli (2004) and Gaglianone et al. (2011). For the equally-weighted, time-invariant S&P 500 portfolio and the daily re-balancing Money portfolios, the evaluation tests suggest that the proposed DFM-VaR performs well. Because the Momentum portfolio is characterized by a high level of negative skewness, none of the models was able to estimate the VaR very accurately. Still, the DFM-VaR provides reasonable estimates for that portfolio.
To the extent that large swings in individual stock prices are generated by systematic shocks, it is possible that the DFM-VaR will able to capture such movements through the systematic latent factors extracted in the proposed procedure. Hence, as a robustness check, we test whether the DFM-VaR produces better VaR estimates for individual stocks that have a higher proportion of systematic risk relative to total risk. As expected, we find that the DFM-VaR generates fewer breaches for stocks with less idiosyncratic risk than HS-VaR.
In future work, we plan to investigate how DFM-VaR may be able model financial variables with richer time series dynamics, like price jumps. Such an extension would be useful when modeling portfolios of assets with non-linear payoffs, like options, or assets of a different class than stocks, such as tranched credit derivatives or interest rate swaptions.
Bibliography
ECB Working Paper.
Financial Times - Prentice Hall.
Review of Banking, Finance and Monetary Economics, Economic Notes 31(2):337-359.
Econometrica 71(1):135-171.
Econometrica 74(3):1133-1150.
Journal of Business and Economic Statistics 25(1):52-60.
The Review of Financial Studies 16(1):101-143.
Journal of Futures Markets 19:583-602.
Journal of Business and Economic Statistics 14(4):465-474.
Management Science, pp. 1-15.
The Journal of Finance LVII(3):1093-1111.
NBER.
Journal of Financial Economterics 2(1):84-108.
Econometrica 53(2):385-407.
Journal of Econometrics 133(2):433-477.
Journal of Business and Economic Statistics 20(3):339-350.
Prepared for a Festchrift for David Hendry.
NYU Working Paper.
Econometric Theory 11(5):122-150.
Journal of Business and Economic Statistics 22(4):367-381.
NYU Working Paper.
NYU Working Paper.
Journal of Finance 51:55-84.
Journal of Business and Economic Statistics 29(1):150-160.
Journal of Risk 1:5-19.
The Journal of Finance 48(1):65-91.
Journal of Banking and Finance 28:1845-1865.
Journal of Derivatives 3:73-84.
National Bureau of Economic Research, New York.
Journal of Banking and Finance 34:362-377.
Journal of Banking and Finance 30:561-582.
Journal of Business and Economic Statistics 20(2):147-162.
Table shows correlations between selected asset pricing factors and the DFM-VaR factors. Mkt, smb, hml and umd are the Fama-French and momentum factors, while dPut is the arithmetic return on the PUT index provided by the CBOE, and dVix is the change in the implied volatility index VIX.
![]() and
and ![]() are the first two principal components extracted from the stock
returns data set.
are the first two principal components extracted from the stock
returns data set.
Table shows correlations between selected asset pricing factors and the DFM-VaR factors. Mkt, smb, hml and umd are the Fama-French and momentum factors, while dPut is the arithmetic return on the PUT index provided by the CBOE, and dVix is the change in the implied volatility index VIX.
![]() and
and ![]() are the first two principal components extracted from the stock
returns data set. 9/2008-12/2008.
are the first two principal components extracted from the stock
returns data set. 9/2008-12/2008.
Table shows summary statistics for the three portfolios described in section 5. Unwinsorized returns data on 3,376 individual stocks are used to calculate portfolio summary statistics over 750 trading days in 2007 - 2009.
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 1.40% | 1.40% | 1.40% | 2.80% | 1.20% |
| Avg. breach size | 0.75% | 0.75% | 0.66% | 1.17% | 1.03% |
| CaViaR p-value | 10.09% | 8.35% | 20.48% | 0.60% | 85.56% |
| Quantile test p-value | 51.73% | 68.48% | 88.83% | 44.33% | 95.14% |
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 2.60% | 2.40% | 7.80% | 2.80% | 2.40% |
| Avg. breach size | 1.25% | 1.35% | 1.24% | 1.33% | 1.17% |
| CaViaR p-value | 0.05% | 0.05% | 0.05% | 0.05% | 0.05% |
| Quantile test p-value | 1.55% | 8.17% | 0.01% | 4.71% | 15.45% |
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 1.60% | 1.40% | 1.60% | 2.00% | 8.60% |
| Avg. breach size | 0.91% | 1.00% | 0.85% | 1.76% | 1.69% |
| CaViaR p-value | 5.70% | 11.29% | 7.55% | 2.00% | 0.05% |
| Quantile test p-value | 42.91% | 46.65% | 65.96% | 27.01% | 9.72% |
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 4.80% | 5.60% | 5.00% | 6.60% | 4.20% |
| Avg. breach size | 0.91% | 0.82% | 0.98% | 1.77% | 0.97% |
| CaViaR p-value | 53.97% | 29.69% | 47.93% | 0.15% | 49.88% |
| Quantile test p-value | 68.51% | 97.99% | 56.61% | 0.82% | 20.55% |
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 16.00% | 14.20% | 21.80% | 15.80% | 14.80% |
| Avg. breach size | 0.85% | 0.85% | 1.10% | 0.98% | 0.80% |
| CaViaR p-value | 0.05% | 0.05% | 0.05% | 0.05% | 0.05% |
| Quantile test p-value | 0.57% | 0.20% | 0.00% | 0.00% | 0.01% |
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Breach % | 5.80% | 5.80% | 6.00% | 7.20% | 15.60% |
| Avg. breach size | 1.13% | 1.15% | 1.27% | 2.12% | 1.96% |
| CaViaR p-value | 24.69% | 27.89% | 64.67% | 0.10% | 0.10% |
| Quantile test p-value | 46.41% | 62.12% | 48.68% | 0.68% | 0.00% |
Table shows statistics on competing VaR models, across the three test portfolios. All VaRs are estimated using a 250 days rolling historical window, using methods described sections 4 and 6.1. "Breach %" is the percentage of days (out of 500 trading days in 2008-2009) for which realized portfolio returns breached the 95% VaR. "Avg. breach size" is the average of the sizes of the breaches over the 500 days. "CaViaR p-value" is the Monte Carlo based p-value (using 2000 replications) of the CaViaR test statistics described in section 6. "Quantile p-value" is the p-value of the Quantile test statistics with respect to a Chi-squared distribution with two degrees of freedom, as described in section 6.
| DFM-VaR |
DFM-VaR |
DFM-VaR |
HS-VaR | FHS-VaR | |
| Comp. Time | 7.1 secs | 8.2 secs | 9.8 secs | 0.5 secs | 17.6 mins |
Table shows computation time required by different VaR models. "Comp. Time" is the average computation time it takes to calculate one VaR, across the 500 out-of-sample VaRs calculated. The same Matlab server is used to compute all VaRs, and all VaRs are computation began at the same time.
The graphs display the time series of the first two principal components extracted from the stock returns data set (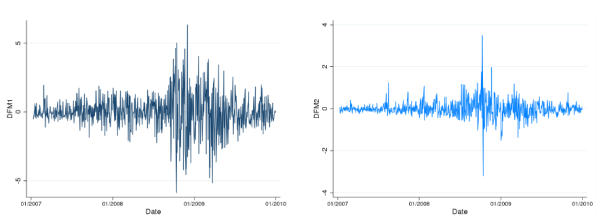
 |
 |
 |