
Board of Governors of the Federal Reserve System
International Finance Discussion Papers
Number 811, July 2004--Screen Reader Version*
THE ET INTERVIEW: PROFESSOR DAVID F. HENDRY
NOTE: International Finance Discussion Papers are preliminary materials circulated to stimulate discussion and critical comment. References in publications to International Finance Discussion Papers (other than an acknowledgment that the writer has had access to unpublished material) should be cleared with the author or authors. Recent IFDPs are available on the Web at http://www.federalreserve.gov/pubs/ifdp/. This paper can be downloaded without charge from the Social Science Research Network electronic library at http://www.ssrn.com/.
Abstract:
This interview for Econometric Theory explores David Hendry's research. Issues discussed include estimation and inference for nonstationary time series; econometric methodology; strategies, concepts, and criteria for empirical modeling; the general-to-specific approach, as implemented in the computer packages PcGive and PcGets; computer-automated model selection procedures; David's textbook Dynamic Econometrics; Monte Carlo techniques (PcNaive); evaluation of these developments in simulation studies and in empirical investigations of consumer expenditure, money demand, inflation, and the housing and mortgage markets; economic forecasting and policy analysis; the history of econometric thought; and the use of computers for live empirical and Monte Carlo econometrics.
Keywords: cointegration, conditional models, consumers' expenditure, diagnostic testing, dynamic specification, encompassing, equilibrium-correction models, error-correction models, exogeneity, forecasting, general-to-specific modeling, housing market, inflation, model design, model evaluation, money demand, Monte Carlo, mortgage market, parameter constancy, PcGets, PcGive, PcNaive, sequential reduction.
JEL Classifications: C1, C5
1 Educational Background, Career, and Interests
Let's start with your educational background and interests. Tell me about your schooling, your original interest in economics and econometrics, and the principal people, events, and books that influenced you at the time.
I went to Glasgow High School but left at 17, when my parents migrated to the north of Scotland. I was delighted to have quit education.
What didn't you like about it?
The basics that we were taught paled into insignificance when compared to untaught issues such as nuclear warfare, independence of post-colonial countries, and so on. We had an informal group that discussed these issues in the playground. Even so, I left school with rather inadequate qualifications: Glasgow University simply returned my application.
That was not a promising start.
No, it wasn't. However, as barman at my parents' fishing hotel in Ross-shire, I met the local Chief Education Officer, who told me that the University of Aberdeen admitted students from ``educationally deprived areas'' such as Ross-shire, and would ignore my Glasgow background. I was in fact accepted by Aberdeen for a 3-year general MA degree (which is a first degree in Scotland)--a ``civilizing'' education that is the historical basis for a liberal arts education.
Why did you return to education when you had been so discouraged earlier?
Working from early in the morning till late at night in a hotel makes one consider alternatives! I had wanted to be an accountant, and an MA opened the door to doing so. At Aberdeen, I studied maths, French, history, psychology, economic history, philosophy, and economics, as these seemed useful for accountancy. I stayed on because they were taught in a completely different way from school, emphasizing understanding and relevance, not rote learning.
What swayed you off of accountancy?
My ``moral tutor'' was Peter Fisk ...
Ah, I remember talking with Peter (author of Fisk (1967)) at Royal Statistical Society meetings in London, but I had not realized that connection.
Peter persuaded me to think about other subjects. Meeting him later, he claimed to have suggested economics, and even econometrics, but I did not recall that.
Were you enrolled in economics?
No, I was reading French, history, and maths. My squash partner, Ian Souter, suggested that I try political economy and psychology as ``easy subjects,'' so I enrolled in them after scraping though my first year.
Were they easy?
I thought psychology was wonderful. Rex and Margaret Knight taught really interesting material. However, economics was taught by Professor Hamilton, who had retired some years before but continued part time because his post remained unfilled. I did not enjoy his course, and I stopped attending lectures. Shortly before the first term's exam, Ian suggested that I catch up by reading Paul Samuelson's (1961) textbook, which I did (fortunately, not Samuelson's (1947) Foundations!). From page one, I found it marvelous, learning how economics affected our lives. I discovered that I had been thinking economics without realizing it.
You had called it accountancy rather than economics?
Partly, but also, I was naive about the coverage of intellectual disciplines.
Why hadn't you encountered Samuelson's text before?
We were using a textbook by Sir Alec Cairncross, the government chief economic advisor at the time and a famous Scots economist. Ian was in second-year economics, where Samuelson was recommended. I read Samuelson from cover to cover before the term exam, which then seemed elementary. Decades later, that exam came back to haunt me when I presented the ``Quincentennial Lecture in Economics'' at Aberdeen in 1995. Bert Shaw, who had marked my exam paper, retold that I had written ``Poly Con'' at the top of the paper. The course was called ``PolEcon,'' but I had never seen it written. He had drawn a huge red ring around ``Poly Con'' with the comment: ``You don't even know what this course is called, so how do you know all about it?'' That's when I decided to become an economist. My squash partner Ian, however, become an accountant.
Were you also taking psychology at the time?
Yes. I transferred to a 4-year program during my second year, reading joint honors in psychology and economics. The Scottish Education Department generously extended my funding to 5 years, which probably does not happen today for other ``late developers.'' There remain few routes to university such as the one that Aberdeen offered or funding bodies willing to support such an education. Psychology was interesting, though immensely challenging--studying how people actually behaved, and eschewing assumptions strong enough to sustain analytical deductions. I enjoyed the statistics, which focused on design and analysis of experiments, as well as conducting experiments, but I dropped psychology in my final year.
You published your first paper, [1], while an undergraduate. How did that come about?
I investigated student income and expenditure in Aberdeen over two years to evaluate changing living standards. To put this in perspective, only about 5% of each cohort went to university then, with most being government funded, whereas about 40% now undertake higher or further education. The real value of such funding was falling, so I analyzed its effects on expenditure patterns (books, clothes, food, lodging, travel, etc.): the paper later helped in planning social investment between student and holiday accommodation.
What happened after Aberdeen?
I applied to work with Dick Stone in Cambridge. Unfortunately he declined, so I did an MSc in econometrics at LSE with Denis Sargan--the Aberdeen faculty thought highly of his work. My econometrics knowledge was woefully inadequate, but I only discovered that after starting the MSc.
Had you taken econometrics at Aberdeen?
Econometrics was not part of the usual undergraduate program, but my desk in Aberdeen's beautiful late-medieval library was by chance in a section that had books on econometrics. I tried to read Lawrence Klein's (1953) A Textbook of Econometrics and to use Jan Tinbergen's (1951) Business Cycles in the United Kingdom 1870-1914 in my economic history course. That led the economics department to arrange for Derek Pearce in the statistics department to help me: he and I worked through Jim Thomas's (1964) Notes on the Theory of Multiple Regression Analysis. Derek later said that he had been keeping just about a week ahead of me, having had no previous contact with problems in econometrics like simultaneous equations and residual autocorrelation.
Was teaching at LSE a shock relative to Aberdeen?
The first lecture was by Jim Durbin on periodograms and spectral analysis, and it was incomprehensible. Jim was proving that the periodogram was inconsistent, but that typical spectral estimators are well-behaved. As we left the lecture, I asked the student next to me, ``What is a likelihood?'' and got the reply ``You're in trouble!''. But luck was on my side. Dennis Anderson was a physicist learning econometrics to forecast future electricity demand, so he and I helped each other through econometrics and economics respectively. Dennis has been a friend ever since, and is now a neighbor in Oxford after working at the World Bank.
Did Bill Phillips teach any of your courses?
Yes, although Bill was only at LSE in my first year. When we discussed my inadequate knowledge of statistical theory, he was reassuring, and I did eventually come to grips with the material. Bill, along with Meghnad Desai, Jan Tymes, and Denis Sargan, ran the quantitative economics seminar, which was half of the degree. They had erudite arguments about autoregressive and moving-average representations, matching Denis's and Bill's respective interests. They also debated whether a Phillips curve or a real-wage relation was the better model for the United Kingdom. That discussion was comprehensible, given my economics background.
What do you recall of your first encounters with Denis Sargan?
Denis was always charming and patient, but he never understood
the knowledge gap between himself and his students. He answered
questions about five levels above the target, and he knew the
material so well that he rarely used lecture notes. I once saw him
in the coffee bar scribbling down a few notes on the back of an
envelope--they constituted his entire lecture. Also, while the
material was brilliant, the notation changed several times in the
course of the lecture: ![]() became
became ![]() , then
, then ![]() , and back to
, and back to ![]() , while
, while ![]() had become
had become ![]() and then
and then ![]() ; and
; and ![]() and
and ![]() got swapped as well.
Sorting out one's notes proved invaluable, however, and eventually
ensured comprehension of Denis's lectures. Our present
teaching-quality assessment agency would no doubt regard his
approach as disastrous, given their blinkered view of pedagogy.
got swapped as well.
Sorting out one's notes proved invaluable, however, and eventually
ensured comprehension of Denis's lectures. Our present
teaching-quality assessment agency would no doubt regard his
approach as disastrous, given their blinkered view of pedagogy.
That sort of lecturing could be discouraging to students, whereas it didn't bother Denis.
One got used to Denis's approach. For Denis, notation was just a vehicle, with the ideas standing above it.
My own recollection of Denis's lectures is that some were crystal clear, whereas others were confusing. For instance, his expositions of instrumental variables and LIML were superb. Who else taught the MSc? Did Jim Durbin?
Yes, Jim taught the time-series course, which reflected his immense understanding of both time- and frequency-domain approaches to econometrics. He was a clear lecturer. I have no recollection of Jim ever inadvertently changing notation--in complete contrast to Denis--so years later Jim's lecture notes remain clear.
What led you to write a PhD after the MSc?
The academic world was expanding rapidly in the United Kingdom after the (Lionel) Robbins report. Previously, many bright scholars had received tenured posts after undergraduate degrees, and Denis was an example. However, as in the United States, a doctorate was becoming essential. I had a summer job in the Labour government's new Department of Economic Affairs, modeling the second-hand car market. That work revealed to me the gap between econometric theory and practice, and the difficulty of making economics operational, so I thought that a doctorate might improve my research skills. Having read George Katona's research, including Katona and Mueller (1968), I wanted to investigate economic psychology in order to integrate the psychologist's approach to human behavior with the economist's utility-optimization inter-temporal models. Individuals play little role in the latter--agents' decisions could be made by computers. By contrast, Katona's models of human behavior incorporated anticipations, plans, and mistakes.
Had you read John Muth (1961) on expectations by then?
Yes, in the quantitative economics seminar, but his results seemed specific to the given time-series model, rather than being a general approach to expectations formation. Models with adaptive and other backward-looking expectations were being criticized at the time, although little was known about how individuals actually formed expectations. However, Denis guided me into modeling dynamic systems with vector autoregressive errors for my PhD.
What was your initial reaction to that topic?
I admired Sargan (1964), and I knew that mis-specifying autocorrelation in a single equation induced modeling problems. Generalizing that result to systems with vector autoregressive errors appeared useful. Denis's approach entailed formulating the `` solved-out'' form with white-noise errors, and then partitioning dynamics between observables and errors. Because any given polynomial matrix could be factorized in many ways, with all factorizations being observationally equivalent in a stationary world, a sufficient number of (strongly) exogenous variables were needed to identify the partition. The longer lag length induced by the autoregressive error generalized the model, but error autocorrelation per se imposed restrictions on dynamics, so the autoregressive-error representation was testable: see [4], [14], and [22], the last with Andy Tremayne.
Did you consider the relationship between the system and the conditional model as an issue of exogeneity?
No. I took it for granted that the variables called `` exogenous'' were independent of the errors, as in strict exogeneity. Bill Phillips (1956) had considered whether the joint distribution of the endogenous and potentially exogenous variables factorized, such that the parameters of interest in the conditional distribution didn't enter the marginal distribution. On differentiating the joint distribution with respect to the parameters of interest, only the conditional distribution would contribute. Unfortunately, I didn't realize the importance of conditioning for model specification at the time.
What other issues arose in your thesis?
Computing and modeling. Econometric methods are pointless unless operational, but implementing the new procedures that I developed required considerable computer programming. The IBM 360/65 at University College London (UCL) facilitated calculations. I tried the methods on a small macro-model of the United Kingdom, investigating aggregate consumption, investment, and output; see [15].
At the time, Denis had several PhD students working on specific sectors of the economy, whereas you were working on the economy as a whole. How much did you interact with the other students?
The student rebellion at the LSE was at its height in 1968-1969; and most of Denis's students worked on the computer at UCL, an ocean of calm. It was a wonderful group to be with. Grayham Mizon wrote code for optimization applied to investment equations, Pravin Trivedi for efficient Monte Carlo methods and modelling inventories, Mike Feiner for ``ratchet'' models for imports, and Ross Williams for nonlinear estimation of durables expenditure. Also, Cliff Wymer was working on continuous-time simultaneous systems, Ray Byron on systems of demand equations, and William Mikhail on finite-sample approximations. We shared ideas and code, and Denis met with us regularly in a workshop where each student presented his or her research. Most theses involved econometric theory, computing, an empirical application, and perhaps a simulation study.
1.1 The London School of Economics
After finishing your PhD at the LSE, you stayed on as a Lecturer, then as a Reader, and eventually as a Professor of Econometrics. Was Denis Sargan the main influence on you at the LSE--as a mentor, as a colleague, as an econometrician, and as an economist?
Yes, he was. And not just for me, but for a whole generation of
British econometricians. He was a wonderful colleague. For
instance, after struggling with a problem for months, a chat with
Denis often elicited a handwritten note later that afternoon,
sketching the solution. I remember discussing Monte Carlo control
variates with Denis over lunch after not getting far with them. He
came to my office an hour later, suggesting a general computable
asymptotic approximation for the control variate that guaranteed an
efficiency gain as the sample size increased. That exchange
resulted in [16] and [27]. Denis was inclined to suggest a solution
and leave you to complete the analysis. Occasionally, our flailings
stimulated him to publish, as with my attempt to extract
![]() th-order autoregressive
errors from
th-order autoregressive
errors from ![]() th-order
dynamics. Denis requested me to repeat my presentation on it to the
econometrics workshop--the kiss of death to an idea! Then he
formulated the common-factor approach in Sargan (1980).
th-order
dynamics. Denis requested me to repeat my presentation on it to the
econometrics workshop--the kiss of death to an idea! Then he
formulated the common-factor approach in Sargan (1980).
How did Jim Durbin and other people at LSE influence you?
In 1973, I was programming GIVE--the Generalized Instrumental Variable Estimator [33]--including an algorithm for FIML. I used the FIML formula from Jim's 1963 paper, which was published much later as Durbin (1988) in Econometric Theory. While explaining Jim's formula in a lecture, I noticed that it subsumed all known simultaneous equations estimators. The students later claimed that I stood silently looking at the blackboard for some time, then turned around and said `` this covers everything.'' That insight led to [21] on estimator generating equations, from which all simultaneous equations estimators and their asymptotic properties could be derived with ease. When Ted Anderson was visiting LSE in the mid-1970s and writing Anderson (1976), he interested me in developing an analog for measurement-error models, leading to [20].
What were your teaching assignments at the LSE?
I taught the advanced econometrics option for the undergraduate degree, and the first year of the two-year MSc. It was an exciting time because LSE was then at the forefront of econometric theory and its applications. I also taught control theory based on Bill Phillips's course notes and the book by Peter Whittle (1963).
Interactions between teaching, research, and software have been important in your work.
Indeed. Writing operational programs was a major theme at LSE because Denis was keen to have computable econometric methods. The mainframe program GIVE was my response. Meghnad Desai called GIVE a ``model destruction program'' because at least one of its diagnostic tests usually rejected anyone's pet empirical specification.
1.2 Overseas Visits
During 1975-1976, you split a year-long sabbatical between Yale--where I first met you--and Berkeley. What experiences would you like to share from those visits?
There were three surprises. The first was that the developments at LSE following Denis's 1964 paper were almost unknown in the United States. Few econometricians therefore realized that autoregressive errors were a testable restriction and typically indicated mis-specification, and Denis's equilibrium-correction (or ``error-correction'') model was unknown. The second surprise was the divergence appearing in the role attributed to economic theory in empirical modeling: from pure data-basing, through using theory as a guideline--which nevertheless attracted the accusation of ``measurement without theory''--to the increasingly dominant fitting of theory models. Conversely, little attention was given to which theory to use, and to bridging the gap between abstract models and data by empirical modeling. The final surprise was how foreign the East Coast seemed, an impression enhanced by the apparently common language. The West Coast proved more familiar--we realized how much we had been conditioned by movies! I enjoyed the entire sabbatical. At Yale, the Koopmans, Tobins, and Klevoricks were very hospitable; and in Berkeley, colleagues were kind. I ended that year at Australian National University (ANU), where I first met Ted Hannan, Adrian Pagan, and Deane Terrell.
One of the academic highlights was the November 1975 conference in Minnesota held by Chris Sims.
Yes, it was, although Chris called my comments in [25]
``acerbic.'' In [25], I concurred with Clive Granger and Paul
Newbold's critique of poor econometrics, particularly that a high
![]() and a low
Durbin-Watson statistic were diagnostic of an incorrect model.
However, I thought that the common-factor interpretation of error
autocorrelation, in combination with equilibrium-correction models,
resolved the nonsense-regressions problem better than differencing,
and it retained the economics. My invited paper [26] at the 1975
Toronto Econometric Society World Congress had discussed a system
of equilibrium corrections that could offset nonstationarity.
and a low
Durbin-Watson statistic were diagnostic of an incorrect model.
However, I thought that the common-factor interpretation of error
autocorrelation, in combination with equilibrium-correction models,
resolved the nonsense-regressions problem better than differencing,
and it retained the economics. My invited paper [26] at the 1975
Toronto Econometric Society World Congress had discussed a system
of equilibrium corrections that could offset nonstationarity.
George Box and Gwilym Jenkins's book (initially published as Box and jenkins (1970)) had appeared a few years earlier. What effect was that having on econometrics?
The debate between the Box-Jenkins approach and the standard econometrics approach was at its height, yet the ideas just noted seemed unknown. In the United States, criticisms by Phillip Cooper and Charles Nelson (1975) of macro-forecasters had stimulated debate about model forms--specifically, about simultaneous systems versus ARIMA representations. However, my Monte Carlo work with Pravin in [8] on estimating dynamic models with moving-average or autoregressive errors had shown that matching the lag length was more important than choosing the correct form; and neither lag length nor model form was very accurately estimated from the sample sizes of 40-80 observations then available. Thus, to me, the only extra ingredients in the Box-Jenkins approach over Bill Phillips's work on dynamic models with moving-average errors (Phillips (2000)) were differencing and data-based modeling. Differencing threw away steady-state economics--the long-run information--so it was unhelpful. I suspected that Box-Jenkins models were winning because of their modeling approach, not their model form; and if a similar approach was adopted in econometrics--ensuring white-noise errors in a good representation of the time series--econometric systems would do much better.
1.3 Oxford University
Why did you decide to move to Nuffield College in January 1982?
Oxford provided a good research environment with many excellent economists, it had bright students, and it was a lovely place to live. Our daughter Vivien was about to start school, and Oxford schools were preferable to those in central London. Amartya Sen, Terence Gorman, and John Muellbauer had all recently moved to Oxford, and Jim Mirrlees was already there. In Oxford, I was initially also acting director of their Institute of Economics and Statistics because academic cutbacks under Margaret Thatcher meant that the University could not afford a paid director. In 1999, the Institute transmogrified into the Oxford economics department.
That sounds strange--not to have had an economics department at a major UK university.
No economics department, and no undergraduate economics degree. Economics was college-based rather than university-based, it lacked a building, and it had little secretarial support. PPE--short for ``Politics, Philosophy, and Economics''--was the major vehicle through which Oxford undergraduates learnt economics. The joke at the time was that LSE students knew everything, but could do nothing with it, whereas Oxford students knew nothing, and could do everything with it.
How did your teaching responsibilities differ between LSE and Nuffield?
At Oxford, I taught the second-year optional econometrics course for the MPhil in economics--36 hours of lectures per year. Oxford students didn't have a strong background in econometrics, mathematics, or statistics, but they were interested in empirical econometric modeling. With the creation of a department of economics, we have now integrated the teaching programs at both the graduate and the undergraduate levels.
1.4 Research Funding
Throughout your academic career, research funding has been important. You've received grants from the Economic and Social Research Council (ESRC, formerly the SSRC), defended the funding of economics generally, chaired the 1995-1996 economics national research evaluation panel for the Higher Education Funding Council for England (HEFCE), and just recently received a highly competitive ESRC-funded research professorship.
On the first, applied econometrics requires software, computers, research assistants, and data resources, so it needs funding. Fortunately, I have received substantial ESRC support over the years, enabling me to employ Frank Srba, Yock Chong, Adrian Neale, Mike Clements, Jurgen Doornik, Hans-Martin Krolzig, and yourself, who together revolutionized my productivity. That said, I have also been critical of current funding allocations, particularly the drift away from fundamental research towards ``user-oriented'' research. ``Near-market'' projects should really be funded by commercial companies, leaving the ESRC to focus on funding what the best researchers think is worthwhile, even if the payoff might be years later. The ESRC seems pushed by government to fund research on immediate problems such as poverty and inner-city squalor--which we would certainly love to solve--but the opportunity cost is reduced research on the tools required for a solution. My work on the fundamental concepts of forecasting would have been impossible without support from the Leverhulme Foundation. I still have more than half of my applications for funding rejected, and I regret that so many exciting projects die. In an odd way, these prolific rejections may reassure younger scholars suffering similar outcomes.
Nevertheless, you have also defended the funding of economics against outside challenges.
In the mid-1980s, the UK meteorologists wanted another super-computer, which would have cost about as much as the ESRC's entire budget. There was an enquiry into the value of social science research, threatening the ESRC's existence. I testified in the ESRC's favor, applying PcGive live to modeling UK house prices to demonstrate how economists analyzed empirical evidence; see [52]. The scientists at the enquiry were fascinated by the predictability of such an important asset price, as well as the use of a cubic differential equation to describe its behavior. Fortunately, the enquiry established that economics wasn't merely assertion.
I remember that one of the deciding arguments in favor of ESRC funding was not by an economist, but by a psychiatrist.
Yes. Griffiths Edwards worked in the addiction research unit at the Maudsley on a program for preventing smoking. An economist had asked him if lung-cancer operations were worthwhile. Checking, he found that many patients did not have a good life post-operation. This role of economics in making people think about what they were doing persuaded the committee of inquiry of our value. Thatcher clearly attached zero weight to insights like Keynes's (1936) General Theory, whereas I suspect that the output saved thereby over the last half century could fund economics in perpetuity.
There also seems to be a difference in attitudes towards, say, a failure in forecasting by economists and a failure in forecasting by the weathermen.
The British press has often quoted my statement that, when weathermen get it wrong, they get a new computer, whereas when economists get it wrong, they get their budgets cut. That difference in attitude has serious consequences, and it ignores that one may learn from one's mistakes. Forecast failure is as informative for us as it is for meteorologists.
That difference in attitude may also reflect how some members of our profession ignore the failures of their own models.
Possibly. Sometimes they just start another research program.
Let's talk about your work on HEFCE.
Core research funding in UK universities is based on HEFCE's research assessment exercise. Peer-group panels evaluate research in each discipline. The panel for economics and econometrics has been chaired in the past by Jim Mirrlees, Tony Atkinson, and myself. It is a huge task. Every five years, more than a thousand economists from UK universities submit four publications each to the panel, which judges their quality. This assessment is the main determinant of future research funding, as few UK universities have adequate endowments. It also unfortunately facilitates excessive government ``micro-management.'' Through the Royal Economic Society, I have tried to advise the funding council about designing such evaluation exercises, both to create appropriate incentives and to adopt a measurement structure that focuses on quality.
1.5 Professional Societies and Journals
Professional societies have several important roles for economists, and you have been particularly active in both the Econometric Society and the Royal Economic Society.
As a life member of the Econometric Society, and as a Fellow since 1976, I know that the Econometric Society plays a valuable role in our profession, but I believe that it should be more democratic by allowing members, and not just Fellows, to have a voice in the affairs of the Society. I was the first competitively elected President of the Royal Economic Society. After empowering its members, the Society became much more active, especially through financing scholarships and funding travel. I persuaded the RES to start up the Econometrics Journal, which is free to members and inexpensive for libraries. Neil Shephard has been a brilliant and energetic first managing editor, helping to rapidly establish a presence for the Econometrics Journal. I also helped found a committee on the role of women in economics, prompted by Karen Mumford and steered to a formal basis by Denise Osborn, with Carol Propper as its first chairperson. The committee has created a network and undertaken a series of useful studies, as well as examined issues such as potential biases in promotions. Some women had also felt that there was bias in journal rejections and were surprised that (e.g.) I still received referee reports that comprised just a couple of rude remarks.
Almost from the start of your professional career, you have been active in journal editing.
Yes. In 1971, Alan Walters (who had the office next door to mine at LSE) nominated me as the econometrics editor for the Review of Economic Studies. Geoff Heal was the Review's economics editor, and we were both in our twenties at the time. I have no idea how Alan persuaded the Society for Economic Analysis to agree to my appointment, although the Review was previously known as the ``Children's Newspaper'' in some sections of our profession. Editing was invaluable for broadening my knowledge of econometrics. I read every submission, as I did later when editing for the Economic Journal and the Oxford Bulletin. An editor must judge each paper and evaluate the referee reports, not just act as a post box. All too often, editors' letters merely say that one of the referees didn't ``like'' the paper, and so reject it. If my referees didn't like a paper that I liked, I would accept the paper nonetheless, reporting the most serious criticisms from the referee reports for the author to rebut. Active editing also requires soliciting papers that one likes, which can be arduous when still handling 100-150 submissions a year.
I then edited the Economic Journal with John Flemming (who regrettably died last year) and covered a wider range of more applied papers. When I began editing the Oxford Bulletin, a shift to the mainstream was needed, and this was helped by commissioning two timely special issues on cointegration that attracted the profession's attention; see [63] and [97].
Some people then nicknamed it the
Oxford Bulletin of Cointegration! Let's
move on to conferences. You organized the Oslo meeting of the
Econometric Society, and you helped create the Econometrics
Conferences of the European Community (EC
![]() ).
).
EC![]() was conceived by
Jan Kiviet and Herman van Dijk as a specialized forum, and I was
delighted to help. Starting in Amsterdam in 1991, EC
was conceived by
Jan Kiviet and Herman van Dijk as a specialized forum, and I was
delighted to help. Starting in Amsterdam in 1991, EC![]() has been very successful, and it
has definitely enhanced European econometrics. We attract about a
hundred expert participants, with no parallel sessions, although
EC
has been very successful, and it
has definitely enhanced European econometrics. We attract about a
hundred expert participants, with no parallel sessions, although
EC![]() does have poster
sessions.
does have poster
sessions.
Poster sessions have been a success in the
scientific community, but they generally have not worked well at
American economics meetings. That has puzzled me, but I gather they
succeeded at EC
![]() ?
?
We encouraged ``big names'' to present posters, we provided
champagne to encourage attendance, and we gave prizes to the best
posters. Some of the presentations have been a delight, showing how
a paper can be communicated in four square meters of wall space,
and allowing the presenter to meet the researchers they most want
to talk to. At a conference the size of EC![]() , about twenty people present
posters at once, so there are two to three audience members per
presenter.
, about twenty people present
posters at once, so there are two to three audience members per
presenter.
That said, in the natural sciences, poster sessions also work at large conferences, so perhaps the ratio is important, not the absolute numbers.
1.6 Long-term Collaborations
Your extensive list of long-term collaborators includes Pravin Trivedi, Frank Srba, James Davidson, Grayham Mizon, Jean-François Richard, Rob Engle, Aris Spanos, Mary Morgan, myself, Julia Campos, John Muellbauer, Mike Clements, Jurgen Doornik, Anindya Banerjee, and, more recently, Katarina Juselius and Hans-Martin Krolzig. What were your reasons for collaboration, and what benefits did they bring?
The obvious ones were a shared viewpoint yet complementary skills, my co-authors' brilliance, energy, and creativity, and that the sum exceeded the parts. Beyond that, the reasons were different in every case. Any research involving economics, statistics, programming, history, and empirical analysis provides scope for complementarities. The benefits are clear to me, at least. Pravin was widely read, and stimulated my interest in Monte Carlo. Frank greatly raised my productivity--our independently written computer code would work when combined, which must be a rarity. When I had tried this with Andy Tremayne, we initially defined Kronecker products differently, inducing chaos! James brought different insights into our work, and insisted (like you) on clarity.
Grayham and I have investigated a wide range of issues. Like yourself, Rob, Jean-François, Katarina, and Mike (and also Søren Johansen, although we have not yet published together), Grayham shares a willingness to discuss econometrics at any time, in any place. On the telephone or over dinner, we have started exchanging ideas about each other's research, usually to our spouses' dismay. I find such discussions very productive. Jean-François and Rob are both great at stimulating new developments and clarifying half-baked ideas, leading to important notions and formalizations. Aris has always been a kindred spirit in questioning conventional econometric approaches and having an interest in the history of econometrics.
Mary is an historian, as well as an econometrician, and so stops me from writing ``Whig history'' (i.e., history as written from the perspective of the victors). With yourself, we have long arguments ending in new ideas, and then write the paper. Julia rigorously checks all derivations and frequently corrects me. John has a clear understanding of economics, so keeps me right in that arena. Mike and I have pushed ahead on investigating a shared interest in the fundamentals of economic forecasting, despite a reluctance of funding agencies to believe that it is a worthwhile activity.
In addition to his substantial econometrics skills, Jurgen is one of the world's great programmers, with an extraordinary ability to conjure code that is almost infallible. He ported PcGive across to C++ after persuading me that there was no future in FORTRAN. We interact on a host of issues, such as on how methodology impinges on the design and structure of programs. Anindya brings great mathematical skills, and Katarina has superb intuition about empirical modeling. Hans-Martin has revived my interest in methodology with automatic model-selection procedures, which he pursues in addition to his ``regime-switching'' research. Ken Wallis and I have regularly commented on each other's work, although we have rarely published together. And, of course, Denis Sargan was also a long-term collaborator, but he almost never needed co-authors, except for [55], which was written jointly with Adrian Pagan and myself. As the acknowledgments in my publications testify, many others have also helped at various stages, most recently Bent Nielsen and Neil Shephard, who are wonderful colleagues at Nuffield.
2 Research Strategy
I want to separate our discussion of research strategy into the role of economics in empirical modeling, the role of econometrics in economics, and the LSE approach to empirical econometric modeling.
2.1 The Role of Economics in Empirical Modeling
I studied economics because unemployment, living standards, and equity are important issues--as noted above, Paul Samuelson was a catalyst in that--and I remain an economist. However, a scientific approach requires quantification, which led me to econometrics. Then I branched into methodology to understand what could be learnt from non-experimental empirical evidence. If econometrics could develop good models of economic reality, economic policy decisions could be significantly improved. Since policy requires causal links, economic theory must play a central role in model formulation, but economic theory is not the sole basis of model formulation. Economic theory is too abstract and simplified, so data and their analysis are also crucial. I have long endorsed the views in Ragnar Frisch's (1933) editorial in the first issue of Econometrica, particularly his emphasis on unifying economic theory, economic statistics (data), and mathematics. That still leaves open the key question as to `` which economic theory.'' `` High-level'' theory must be tested against data, contingent on `` well-established'' lower-level theories. For example, despite the emphasis on agents' expectations by some economists, they devote negligible effort to collecting expectations data and checking their theories. Historically, much of the data variation is not due to economic factors, but to `` special events'' such as wars and major changes in policy, institutions, and legislation. The findings in [205] and [208] are typical of my experience. A failure to account for these special events can elide the role of economic forces in an empirical model.
2.2 The Role of Econometrics in Economics
Is the role of econometrics in economics that of a tool, just as Monte Carlo is a tool within econometrics?
Econometrics is our instrument, as telescopes and microscopes are instruments in other disciplines. Econometric theory and, within it, Monte Carlo, evaluates whether that instrument is functioning as expected. Econometric methodology studies how such methods work when applied.
Too often, a study in economics starts afresh, postulating and then fitting a theory-based model, failing to build on previous findings. Because investigators revise their models and rewrite a priori theories in light of the evidence, it is unclear how to interpret their results. That route of forcing theoretical models onto data is subject to the criticisms in Larry Summers (1991) about the `` illusion of econometrics.'' I admire what Jan Tinbergen called `` kitchen-sink econometrics,'' being explicit about every step of the process. It starts with what the data are; how they are collected, measured, and changed in the light of theory; what that theory is; why it takes the claimed form and is neither more general nor more explicit; and how one formulates the resulting empirical relationship, and then fits it by a rule (an estimator) derived from the theoretical model. Next comes the modeling process, because the initial specification rarely works, given the many features of reality that are ignored by the theory. Finally, ex post evaluation checks the outcome.
That approach suggests a difference between being primarily interested in the economic theory--where data check that the theory makes sense--and trying to understand the data--where the theory helps interpret the evidence rather than act as a straitjacket.
Yes. To derive explicit results, economic theory usually abstracts from many complexities, including how the data are measured. There is a vast difference between such theory being invaluable, and its being optimal. At best, the theory is a highly imperfect abstraction of reality, so one must take the data and the theory equally seriously in order to build useful empirical representations. The instrument of econometrics can be used in a coherent way to interpret the data, build models, and underpin a progressive research strategy, thereby providing the next investigator with a starting point.
2.3 The LSE Approach
What is meant by the LSE approach? It is often associated with you in particular, although many other individuals have contributed to it, and not all of them have been at the LSE.
There are four basic stages, beginning with an economic analysis to delineate the most important factors. The next stage embeds those factors in a general model that also allows for other potential determinants and relevant special features. Then, the congruence of that model is tested. Finally, that model is simplified to a parsimonious undominated congruent final selection that encompasses the original model, thereby ensuring that all reductions are valid.
When developing the approach, the first tractable cases were linear dynamic single equations, where the appropriate lag length was an open issue. However, the principle applies to all econometric modeling, albeit with greater difficulty in nonlinear settings; see Trivedi (1970) and Mizon (1977) for early empirical and theoretical contributions. Many other aspects followed, such as developing a taxonomy for model evaluation, orthogonalizing variables, and re-commencing an analysis at the general model if a rejection occurs. Additional developments generalized this approach to system modeling, in which several (or even all) variables are treated as endogenous. Multiple cointegration is easily analyzed as a reduction in this framework, as is encompassing of the VAR and whether a conditional model entails a valid reduction. Mizon (1995) and [157] provide discussions.
Do you agree with Chris Gilbert (1986) that there is a marked contrast between the `` North American approach'' to modeling and the `` European approach'' ?
Historically, American economists were the pragmatists, but Koopmans (1947) seems to mark a turning point. Many American economists now rely heavily on abstract economic reasoning, often ignoring institutional aspects and inter-agent heterogeneity, as well as inherent conflicts of interest between agents on different sides of the market. Some economists believe their theories to such an extent that they retain them, even when they are strongly rejected by the data. There are precedents in the history of science for maintaining research programs despite conflicts with empirical evidence, but only when there was no better theory. For economics, however, Werner Hildenbrand (1994), Jean-Pierre Benassy (1986), and many others highlight alternative theoretical approaches that seem to accord better with empirical evidence.
3 Research Highlights
We discussed estimator generation already. Let's now turn to some other highlights of your research program, including equilibrium correction, exogeneity, model evaluation and design, encompassing, Dynamic Econometrics, and Gets. These issues have often arisen from empirical work, so let's consider them in their context, focusing on consumers' expenditure and money demand, including the Friedman-Schwartz debate. We should also discuss Monte Carlo as a tool in econometrics, the history of econometrics, and your recent interest in ex ante forecasting, which has emphasized the difference between error correction and equilibrium correction.
3.1 Consumers' Expenditure
Your paper [28] with James Davidson, Frank Srba, and Stephen Yeo models UK consumers' expenditure. This paper is now commonly known by the acronym DHSY, which is derived from the authors' initials.
Some background is necessary. I first had access to computer graphics in the early 1970s, and I was astonished at the picture for real consumers' expenditure and income in the United Kingdom. Expenditure manifested vast seasonality, with double-digit percentage changes between quarters, whereas income had virtually no seasonality. Those seasonal patterns meant that consumption was much more volatile than income on a quarter-to-quarter basis. Two implications followed. First, it would not work to fit first-order lags (as I had done earlier) and hope that dummies plus the seasonality in income would explain the seasonality in consumption. Second, the general class of consumption-smoothing theories like the permanent-income and life-cycle hypotheses seemed mis-focused. Consumers were inducing volatility into the economy by large inter-quarter shifts in their expenditure, so the business sector must be a stabilizing influence.
Moreover, the consumption equation in my macro-model [15] had dramatically mis-forecasted the first two quarters of 1968. In 1968Q1, the Chancellor of the Exchequer announced that he would greatly increase purchase (i.e., sales) taxes unless consumers' expenditure fell, the response to which was a jump in consumers' expenditure, followed in the next quarter by the Chancellor's tax increase and a resulting fall in expenditure. I wrongly attributed my model's forecast failure to model mis-specification. In retrospect, that failure signalled that forecasting problems with econometric models come from unanticipated changes.
At about this time, Gordon Anderson and I were modeling building societies, which are the British analogue of the US savings and loans associations. In [26], we nested the long-run solutions of existing empirical equations, using a formulation related to Sargan (1964), although I did not see the link to Denis's work until much later; see [50]. I adopted a similar approach for modeling consumers' expenditure, seeking a consumption function that could interpret the equations from the major UK macro-models and explain why their proprietors had picked the wrong models. In DHSY [28], we adopted a `` detective story'' approach, using a nesting model for the different variables, valid for both seasonally-adjusted and unadjusted data, with up to 5 lags in all the variables to capture the dynamics. Reformulation of that nesting model delivered an equation that [39] later related to Phillips (1957) and called an error-correction model. Under error correction, if consumers made an error relative to their plan by over-spending in a given quarter, they would later correct that error.
Even with DHSY, a significant change in model formulation occurred just before publication. Angus Deaton (1977) had just established a role for inflation if agents were uncertain as to whether relative or absolute prices were changing.
The first DHSY equation explained real consumers' expenditure given real income, and it significantly over-predicted expenditure through the 1973-1974 oil crisis. Angus's paper suggested including inflation and changes therein. Adding these variables to our equation explained the under-spending. This result was the opposite of what the first-round economic theory suggested, namely, that high inflation should induce pre-emptive spending, given the opportunity costs of holding money. Inflation did not reflect money illusion. Rather, it implied the erosion of the real value of liquid assets. Consumers did not treat the nominal component of after-tax interest as income, whereas the Statistical Office did, so disposable income was being mis-measured. Adding inflation to our equation corrected that. As ever, theory did not have a unique prediction.
DHSY explained why other modelers selected their models, in addition to evaluating your model against theirs. Why haven't you applied that approach in your recent work?
It was difficult to do. Several ingredients were necessary to explain other modelers' model selections: their modeling approaches, data measurements, seasonal adjustment procedures, choice of estimators, maximum lag lengths, and mis-specification tests. We first standardized on unadjusted data and replicated models on that. While seasonal filters leave a model invariant when the model is known, they can distort the lag patterns if the model is data-based. We then investigated both OLS and IV but found little difference. Few of the then reported evaluation statistics were valid for dynamic models, so such tests could mislead. Most extant models had a maximum lag of one and low short-run marginal propensities to consume, which seemed too small to reflect agent behavior. We tried many blind alleys (including measurement errors) to explain these low marginal propensities to consume. Then we found that equilibrium correction explained them by induced biases in partial-adjustment models. We designed a nesting model, which explained all the previous findings, but with the paradox that it simplified to a differenced specification, with no long-run term in the levels of the variables. Resolving that conundrum led to the error-correction mechanism. While this ``Sherlock Holmes'' approach was extremely time-consuming, it did stimulate research into encompassing, i.e., trying to explain other models' results from a given model.
Were you aware of Phillips (1954) and Phillips (1957)?
Now the interview becomes embarrassing! I had taken over Bill Phillips's lecture course on control theory and forecasting, so I was teaching how proportional, integral, and derivative control rules can stabilize the economy. However, I did not think of such rules as an econometric modeling device in behavioral equations.
What other important issues did you miss at the time?
Cointegration! Gordon Anderson's and my work on building societies showed that combinations of levels variables could be stationary, as in the discussion by Klein (1953) of the `` great ratios.'' Granger (1981, 1986) later formalized that property as cointegration removing unit roots. Grayham Mizon and I were debating with Gene Savin whether unit roots changed the distributions of estimators and tests, but bad luck intervened. Grayham and I found no changes in several Monte Carlos, but, unknowingly, our data generation processes had strong growth rates.
Rather than unit-root processes with a zero mean?
Yes. We found that estimators were nearly normally distributed, and we falsely concluded that unit roots did not matter; see West (1988).
The next missed issue concerned seasonality and annual
differences. In DHSY, the equilibrium correction was the
four-quarter lag of the log of the ratio of consumption to income,
and it was highly seasonal. However, seasonal dummy variables were
insignificant if one used the Scheffé ![]() procedure; see Savin (1980).
About a week after DHSY's publication, Thomas von Ungern-Sternberg
added seasonal dummies to our equation and, with conventional
procedure; see Savin (1980).
About a week after DHSY's publication, Thomas von Ungern-Sternberg
added seasonal dummies to our equation and, with conventional
![]() -tests, found that
they were highly significant, leading to the `` HUS'' paper, [39].
Care is clearly required with multiple-testing procedures!
-tests, found that
they were highly significant, leading to the `` HUS'' paper, [39].
Care is clearly required with multiple-testing procedures!
Those results on seasonality stimulated an industry on time-varying seasonal patterns, periodic seasonality, and periodic behavior, with many contributions by Denise Osborn (1988, 1991).
Indeed. The final mistake in DHSY was our treatment of liquid assets. HUS showed that, in an equilibrium-correction formulation, imposing a unit elasticity of consumption with respect to income leaves no room for liquid assets. Logically speaking, DHSY went from simple to general. On de-restricting their equation, liquid assets were significant, which HUS interpreted as an integral correction mechanism. The combined effect of liquid assets and real income on expenditure added up to unity in the long run.
The DHSY and HUS models appeared at almost the same time as the Euler-equation approach in Bob Hall (1978). Bob emphasized consumption smoothing, where changes in consumption were due to the innovations in permanent income and so should be ex ante unpredictable. A large literature has tested if changes in consumers' expenditure are predictable in Hall's model. How did your models compare with his?
In [35], James Davidson and I found that lagged variables, as derived from HUS, were significant in explaining changes in UK consumers' expenditure. HUS's model thus encompassed Hall's model. ``Excess volatility'' and ``excess smoothing'' have been found in various models, but few authors using an Euler-equation framework test whether their model encompasses other models.
You produced a whole series of papers on consumers' expenditure.
After DHSY, HUS, and [35], there were four more papers. They were written in part to check the constancy of the models, and in part to extend them. [46] modeled annual inter-war UK consumers' expenditure, obtaining results similar to the post-war relation in DHSY and HUS, despite large changes in the correlation structure of the data. [88] followed up on DHSY, [101] developed a model of consumers' expenditure in France, and [119] revisited HUS with additional data.
The 1990 paper [88] with Anthony Murphy and John Muellbauer finds that additional variables matter.
We would expect that to happen. As the sample size grows,
noncentral ![]() -statistics
become more significant, so models expand. That's another topic
that Denis worked on; see Sargan (1975), and the interesting
follow-up by Robinson (2003).
-statistics
become more significant, so models expand. That's another topic
that Denis worked on; see Sargan (1975), and the interesting
follow-up by Robinson (2003).
It also fits in with the work on
![]() -testing by Hal White
(1990).
-testing by Hal White
(1990).
Yes. Mis-specification evidence against a given formulation accumulates, which unfortunately takes one down a simple-to-general path. That is one reason empirical work is difficult. (The other is that the economy changes.) A `` reject'' outcome on a test rejects the model, but it does not reveal why. Bernt Stigum (1990) has proposed a methodology to delineate the source of failure from each test, but when a test rejects, it still takes a creative discovery to improve a model. That insight may come from theory, institutional evidence, data knowledge, or inspiration. While general-to-specific methodology provides guidelines for building encompassing models, advances between studies are inevitably simple-to-general, putting a premium on creative thinking.
A good initial specification of the general model is a major source of value added, making the rest relatively easy, and incredibly difficult otherwise.
That's correct. Research can be wasted if a key variable is omitted.
3.2 Equilibrium-correction Models and Cointegration
You already mentioned that you had presented an equilibrium-correction model at Sims's 1975 conference.
Yes, in [25], I presented an example that was derived from the
long-run economic theory of consumers' expenditure, and I merely
asserted that there were other ways to obtain stationarity than
differencing. Nonsense regressions are only a problem for static
models, or for those patched up with autoregressive errors. If one
begins with a general dynamic specification, it is relatively easy
to detect that there is no relationship between two unrelated
random walks, ![]() and
and
![]() (say). A
significant drawback of being away from the LSE was the difficulty
of transporting software, so I did not run a Monte Carlo simulation
to check this. Now it is easy to do so, and [229, Figure 1]
shows the distributions of the
(say). A
significant drawback of being away from the LSE was the difficulty
of transporting software, so I did not run a Monte Carlo simulation
to check this. Now it is easy to do so, and [229, Figure 1]
shows the distributions of the ![]() -statistics for the coefficients in the regression
of:
-statistics for the coefficients in the regression
of:
| (1) |
where
What was the connection between [25] and Clive's first papers on cointegration--Granger (1981) and Granger and Weiss (1983)?
At Sims's conference, Clive was skeptical about relating differences to lagged levels and doubted that the correction in levels could be stationary: differences of the data did not have a unit root, whereas their lagged levels did. Investigating that issue helped Clive discover cointegration; see his discussion of [49], and see Phillips (1997).
Your interest in cointegration led to two special issues of the Oxford Bulletin, your book [104], and a number of papers--[61], [64], [78], [95], [98], and [136]--the last three also addressing structural breaks.
The key insight was that fewer equilibrium corrections
(![]() ) than the number of
decision variables (
) than the number of
decision variables (![]() )
induced integrated-cointegrated data, which Søren Johansen
(1988) formalized as reduced-rank feedbacks of combinations of
levels onto growth rates. In the Granger representation theorem in
Engle and Granger (1987), the data are I(1) because
)
induced integrated-cointegrated data, which Søren Johansen
(1988) formalized as reduced-rank feedbacks of combinations of
levels onto growth rates. In the Granger representation theorem in
Engle and Granger (1987), the data are I(1) because ![]() , a situation that I had not
thought about. So, although DHSY was close in some ways, it was far
off in others. In fact, I missed cointegration for a second time in
[32], where I showed that `` nonsense regressions'' could be
created and detected, but I failed to formalize the latter.
Cointegration explained many earlier results. For instance, in
Denis's 1964 equilibrium relationship involving real wages relative
to productivity, the measured disequilibrium fed back to determine
future wage rates, given current inflation rates.
, a situation that I had not
thought about. So, although DHSY was close in some ways, it was far
off in others. In fact, I missed cointegration for a second time in
[32], where I showed that `` nonsense regressions'' could be
created and detected, but I failed to formalize the latter.
Cointegration explained many earlier results. For instance, in
Denis's 1964 equilibrium relationship involving real wages relative
to productivity, the measured disequilibrium fed back to determine
future wage rates, given current inflation rates.
Peter Phillips (1986, 1987), Jim Stock (1987), and others (such as Chan and Wei (1988)) were also changing the mathematical technology by using Weiner integrals to represent the limiting distributions of unit-root processes. Anindya Banerjee, Juan Dolado, John Galbraith, and I thought that the power and generality of that new approach would dominate the future of econometrics, especially since some proofs became easier, as with the forecast-error distributions in [139]. Our interest in cointegration resulted in [104], following Benjamin Disraeli's reputed remark that `` if you want to learn about a subject, write a book about it.''
Or edit a special issue on it!
3.3 Exogeneity
Exogeneity takes us back to Vienna in August 1977 at the European Econometric Society Meeting.
Discussions of the concept of exogeneity abounded in the econometrics literature, but for me, the real insight came from the paper presented in Vienna by Jean-François Richard and published as Richard (1980). Although the concept of exogeneity needed clarifying, the audience at the Econometric Society meeting seemed bewildered, since few could relate to Jean-François's likelihood factorizations and sequential cuts. Rob Engle was also interested in exogeneity, so, when he visited LSE and CORE shortly after the Vienna meeting, the three of us analyzed the distinctions between various kinds of exogeneity and developed more precise definitions. We all attended a Warwick workshop, with Chris Sims and Ed Prescott among the other econometricians, and we argued endlessly. Reactions to our formalization of exogeneity suggested that fundamental methodological issues were in dispute, including how one should model, what the form of models should be, what modeling concepts were, and even what appropriate model concepts were. Since I was working with Jean-François and Rob, I visited their respective institutions (CORE and UCSD) during 1980-1981. My time at both locations was very stimulating. The coffee lounge at CORE saw many long discussions about the fundamentals of modeling with Knud Munk, Louis Phlips, Jean-Pierre Florens, Michel Mouchart, and Jacques Drèze (plus Angus Deaton during his visit). In San Diego, we argued more about technique.
Your paper [44] with Rob and Jean-François on exogeneity went through several revisions before being published, and many of the examples from the CORE discussion paper were dropped.
Regrettably so. Exogeneity is a difficult notion and is prone to ambiguities, whereas examples can help reduce the confusion. The CORE version was written in a cottage in Brittany, which the Hendrys and Richards shared that summer. Jean-François even worked on it while moving along the dining table as supper was being laid. The extension to unit-root processes in [130] shows that exogeneity has yet further interesting implications.
How did your paper [106] on super exogeneity with Rob Engle come about?
Parameter constancy is a fundamental attribute of a model, yet predictive failure was all too common empirically. The ideal condition was super exogeneity, which meant valid conditioning for parameters of interest that were invariant to changes in the distributions of the conditioning variables. Rob correctly argued that tests for super exogeneity and invariance were required, so we developed some tests and investigated whether conditioning variables were valid, or whether they were proxies for agents' expectations. Invalid conditioning should induce nonconstancy, and that suggested how to test whether agents were forward-looking or contingent planners, as in [76].
The idea is a powerful one logically, but there is no formal work on the class of paired parameter constancy tests in which we seek rejection for the forcing variables' model and non-rejection for the conditional model.
That has not been formalized. Following Trevor Breusch (1986), tests of super exogeneity reject if there is nonconstancy in the conditional model, ensuring refutability. The interpretation of non-rejection is less clear.
You reported simulation evidence in [100] with Carlo Favero.
That work was based on my realization in [76] that feedback and feedforward models are not observationally equivalent when structural breaks occur in marginal processes. Intercept shifts in the marginal distributions delivered high power, but changes in the parameters of mean-zero variables were barely detectable. At the time, I failed to realize two key implications: the Lucas (1976) critique could only matter if it induced location shifts; and predictive failure was rarely due to changed coefficients of zero-mean variables. More recently, I have developed these ideas in [183] and [188].
In your forecasting books with Mike Clements--[163] and [170]--you discuss how shifts in the equilibrium's mean are the driving force for empirically detectable nonconstancy.
Interestingly, such a shift was present in DHSY, since inflation was needed to model the falling consumption-income ratio, which was the equilibrium correction. When inflation was excluded from our model, predictive failure occurred because the equilibrium mean had shifted. However, we did not realize that logic at the time.
3.4 Model Development and Design
There are four aspects to model development. The first is model evaluation, as epitomized by GIVE (or what is now PcGive) in its role as a ``model destruction program.'' The second aspect is model design. The third is encompassing, which is closely related to the theory of reduction and to the general-to-specific modeling strategy. The fourth concerns a practical difficulty that arises because we may model locally by general to specific, but over time we are forced to model specific to general as new variables are suggested, new data accrue, and so forth.
On the first issue, Denis Sargan taught us that `` problems'' with residuals usually revealed model mis-specification, so tests were needed to detect residual autocorrelation, heteroscedasticity, non-normality, and so on. Consequently, my mainframe econometrics program GIVE printed many model evaluation statistics. Initially, they were usually likelihood ratio statistics, but many were switched to their Lagrange multiplier form, following the implementation of Silvey (1959) in econometrics by Ray Byron, Adrian Pagan, Rob Engle, Andrew Harvey, and others; see Godfrey (1988).
Why doesn't repeated testing lead to too many false rejections?
Model evaluation statistics play two distinct roles. In the first, the statistics generate one-off mis-specification tests on the general model. Because the general model usually has four or five relevant, nearly orthogonal, aspects to check, a 1% significance level for each test entails an overall size of about 5% under the null hypothesis that the general model is well-specified. Alternatively, a combined test could be used, and both approaches seem unproblematic. However, for any given nominal size for each test statistic, more tests must raise rejection frequencies under the null. This cost has to be balanced against the probability of detecting a problem that might seriously impugn inference, where repeated testing (i.e., more tests) raises the latter probability.
The second role of model evaluation statistics is to reveal invalid reductions from a congruent general model. Those invalid reductions are then not followed, so repeated testing here does not alter the rejection frequencies of the model evaluation tests.
The main difficulty with model evaluation in the first sense is that rejection merely reveals an inappropriate model. It does not show how to fix the problem. Generalizing a model in the rejected direction might work, but that inference is a non sequitur. Usually, creative insight is required, and re-examining the underlying economics may provide that. Still, the statistical properties of any new model must await new data for a Neyman-Pearson quality-control check.
The empirical econometrics literature of the 1960s manifested covert design. For instance, when journal editors required that Durbin-Watson statistics be close to two, residual autocorrelation was removed by fitting autoregressive errors. Such difficulties prompted the concept of explicit model design, leading us to consider what characteristics a model should have. In [43], Jean-François and I formalized model concepts and the information sets against which to evaluate models, and we also elucidated the design characteristics needed for congruence.
If we knew the data generation process (DGP) and estimated its parameters appropriately, we would also obtain insignificant tests with the stated probabilities. So, as an alternative complementary interpretation, successful model design restricts the model class to congruent outcomes, of which the DGP is a member.
Right. Congruence (a name suggested by Chris Allsopp) denotes that a model matches the evidence in all the directions of evaluation; and so the DGP is congruent with itself. Surprisingly, the concept of the DGP once caused considerable dispute, even though (by analogy) all Monte Carlo studies needed a mechanism for generating their data. The concept's acceptance was helped by clarifying that constant parameters are not an intrinsic property of an economics DGP. Also, the theory of reduction explains how marginalization, sequential factorization, and conditioning in the enormous DGP for the entire economy entails the joint density of the subset of variables under analysis; see [69] and also [113] with Steven Cook.
That joint density of the subset of variables is what Christophe Bontemps and Mizon (2003) have since called the local DGP. The local DGP can be transformed to have homoscedastic innovation errors, so congruent models are the class to search; and Bontemps and Mizon prove that a model is congruent if it encompasses the local DGP. Changes at a higher level in the full DGP can induce nonconstant parameters in the local DGP, putting a premium on good selection of the variables.
One criticism of the model design approach, which is also applicable to pre-testing, is that test statistics no longer have their usual distributions. How do you respond to that?
For evaluation tests, that view is clearly correct, whether the testing is within a given study or between different studies. When a test's rejection leads to model revision and only ``insignificant'' tests are reported, tests are clearly design criteria. However, their insignificance on the initial model is informative about that model's goodness.
So, in model design, insignificant test statistics are evidence of having successfully built the model. What role does encompassing play in such a strategy?
In experimental disciplines, most researchers work on the data generated by their own experiments. In macroeconomics, there is one data set with a proliferation of models thereof, which raises the question of congruence between any given model and the evidence provided by rival models. The concept of encompassing was present in DHSY and HUS, but primarily as a tool for reducing model proliferation. The concept became clearer in [43] and [45], but it was only formalized as a test procedure in Mizon and Richard (1986). Although the idea surfaced in David Cox (1962), David emphasized single degree-of-freedom tests for comparing non-nested models, as did Hashem Pesaran (1974), whose paper I had handled as editor for the Review of Economic Studies. I remain convinced of the central role of encompassing in model evaluation, as argued in [75], [83], [118], and [142]. Kevin Hoover and Stephen Perez (1999) suggested that encompassing be used to select a dominant final model from the set of terminal models obtained by general-to-specific simplifications along different paths. That insight sustains multi-path searches and has been implemented in [175] and [206]. More generally, in a progressive research strategy, encompassing leads to a well-established body of empirical knowledge, so new studies need not start from scratch.
As new data accumulate, however, we may be forced to model specific to general. How do we reconcile that with a progressive research strategy?
As data accrue over time, we can uncover both spurious and
relevant effects because spurious variables have central
![]() -statistics, whereas
relevant variables have noncentral
-statistics, whereas
relevant variables have noncentral ![]() -statistics that drift in one direction. By letting
the model expand appropriately and by letting the significance
level go to zero at a suitable rate, the probability of retaining
the spurious effects tends to zero asymptotically, whereas the
probability of retaining the relevant variables tends to unity; see
Hannan and Quinn (1979) and White (1990) for stationary processes.
Thus, modeling from specific to general between studies is not
problematic for a progressive research strategy, provided one
returns to the general model each time. Otherwise, [172] showed
that successively corroborating a sequence of results can imply the
model's refutation. Still, we know little about how well a
progressive research strategy performs when there are intermittent
structural breaks.
-statistics that drift in one direction. By letting
the model expand appropriately and by letting the significance
level go to zero at a suitable rate, the probability of retaining
the spurious effects tends to zero asymptotically, whereas the
probability of retaining the relevant variables tends to unity; see
Hannan and Quinn (1979) and White (1990) for stationary processes.
Thus, modeling from specific to general between studies is not
problematic for a progressive research strategy, provided one
returns to the general model each time. Otherwise, [172] showed
that successively corroborating a sequence of results can imply the
model's refutation. Still, we know little about how well a
progressive research strategy performs when there are intermittent
structural breaks.
3.5 Money Demand
You have analyzed UK broad money demand on both quarterly and annual data, and quarterly narrow money demand for both the United Kingdom and the United States. In your first money-demand study [29], you and Grayham Mizon were responding to work by Graham Hacche (1974) at the Bank of England. How did that arise?
Tony Courakis (1978) had submitted a comment to the Economic Journal criticizing Hacche for differencing data in order to achieve stationarity. Grayham Mizon and I proposed testing the restrictions imposed by differencing as an example of Denis's new common-factor tests--later published as Sargan (1980)--and we developed an equilibrium-correction representation for money demand, using the Bank's data. The common-factor restriction in Hacche (1974) was rejected, and the equilibrium-correction term in our model was significant.
So, you assumed that the data were stationary, even though differencing was needed.
We implicitly assumed that both the equilibrium-correction term and the differences would be stationary, despite no concept of cointegration; and we assumed that the significance of the equilibrium-correction term was equivalent to rejecting the common factor from differencing. Also, the Bank study was specific to general in its approach, whereas we argued for general-to-specific modeling, which was the natural way to test common-factor restrictions using Denis's determinantal conditions. Denis's COMFAC algorithm was already included in GIVE, although Grayham's and my Monte Carlo study of COMFAC only appeared two years later in [34].
Did Courakis (1978) and [29] change modeling strategies in the United Kingdom? What was the Bank of England's reaction?
The next Bank study--of M1 by Richard Coghlan (1978)--considered general dynamic specifications, but they still lacked an equilibrium-correction term. As I discussed in my follow-up [31], narrow money acts as a buffer for agents' expenditures, but with target ratios for money relative to expenditure, deviations from which prompt adjustment. That target ratio should depend on the opportunity costs of holding money relative to alternative financial assets and to goods, as measured by interest rates and inflation respectively. Also, because some agents are taxed on interest earnings, and other agents are not, the Fisher equation cannot hold.
So your interest rate measure did not adjust for tax.
Right. [31] also highlighted the problems confronting a simple-to-general approach. Those problems include the misinterpretation of earlier results in the modeling sequence, the impossibility of constructively interpreting test rejections, the many expansion paths faced, the unknown stopping point, the collapse of the strategy if later mis-specifications are detected, and the poor properties that result from stopping at the first non-rejection--a criticism dating back to Anderson (1962).
A key difficulty with earlier UK money-demand equations had been parameter nonconstancy. However, my equilibrium-correction model was constant over a sample with considerable turbulence after Competition and Credit Control regulations in 1971.
[31] also served as the starting point for a sequence of papers on UK and US M1. You returned to modeling UK M1 again in [60] and [94].
That research resulted in a simple representation for UK M1 demand, despite a very general initial model, with only four variables representing opportunity costs against goods and other assets, adjustment costs, and equilibrium adjustment.
In 1982, Milton Friedman and Anna Schwartz published their book Monetary Trends in the United States and the United Kingdom, and it had many potential policy implications. Early the following year, the Bank asked you to evaluate the econometrics in Friedman and Schwartz (1982) for the Bank's panel of academic consultants, leading to Hendry and Ericsson (1983) and eventually to [93].
You were my research officer then. Friedman and Schwartz's approach was deliberately simple-to-general, commencing with bivariate regressions, generalizing to trivariate regressions, etc. By the early 1980s, most British econometricians had realized that such an approach was not a good modeling strategy. However, replicating their results revealed numerous other problems as well.
Figure 1: A comparison of Friedman and Schwartz's graph of UK velocity with Hendry and Ericsson's graph of UK velocity.
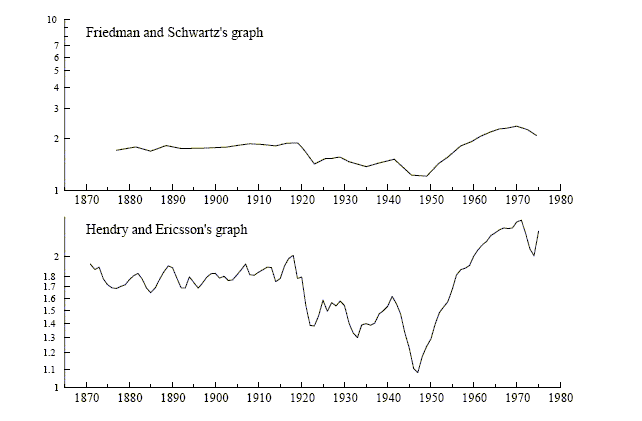
I recall that one of those was simply graphing velocity.
Yes. The graph in Friedman and Schwartz (1982, p. 178, Chart 5.5) made UK velocity look constant over their century of data. I initially questioned your plot of UK velocity--using Friedman and Schwartz's own annual data--because your graph showed considerable nonconstancy in velocity. We discovered that the discrepancy between the two graphs arose mainly because Friedman and Schwartz plotted velocity allowing for a range of 1 to 10, whereas UK velocity itself only varied between 1 and 2.4. Figure 1 reproduces the comparison.
Testing Friedman and Schwartz's equations revealed a considerable lack of congruence. Friedman and Schwartz phase-averaged their annual data in an attempt to remove the business cycle, but phase averaging still left highly autocorrelated, nonstationary processes. Because filtering (such as phase averaging) imposes dynamic restrictions, we analyzed the original annual data. Our paper for the Bank of England panel started a modeling sequence, with contributions from Andrew Longbottom and Sean Holly (1985) and Alvaro Escribano (1985).
Shortly after the meeting of the Bank's panel of academic consultants, there was considerable press coverage. Do you recall how that occurred? The Guardian newspaper started the debate.
As background, monetarism was at its peak. Margaret Thatcher--the Prime Minister--had instituted a regime of monetary control, as she believed that money caused inflation, precisely the view put forward by Friedman and Schwartz. From this perspective, a credible monetary tightening would rapidly reduce inflation because expectations were rational. In fact, inflation fell slowly, whereas unemployment leapt to levels not seen since the 1930s. The Treasury and Civil Service Committee on Monetary Policy (which I had advised in [36] and [37]) had found no evidence that monetary expansion was the cause of the post-oil-crisis inflation. If anything, inflation caused money, whereas money was almost an epiphenomenon. The structure of the British banking system made the Bank of England a ``lender of the first resort,'' and so the Bank could only control the quantity of money by varying interest rates.
At the time, Christopher Huhne was the economics editor at the Guardian. He had seen our critique, and he deemed our evidence central to the policy debate.
As I recall, when Huhne's article hit the press, your phone rang for hours on end.
That it did. There were actually two articles about Friedman and Schwartz (1982) in the Guardian on December 15, 1983. On page 19, Huhne had written an article that summarized--in layman's terms--our critique of Friedman and Schwartz (1982). Huhne and I had talked at length about this piece, and it provided an accurate statement of Hendry and Ericsson (1983) and its implications. In addition--and unknown to us--the Guardian decided to run a front-page editorial on Friedman and Schwartz with the headline Monetarism's guru `distorts his evidence'. That headline summarized Huhne's view that it was unacceptable for Friedman and Schwartz to use their data-based dummy variable for 1921-1955 and still claim parameter constancy of their money-demand equation. Rather, that dummy variable actually implied nonconstancy because the regression results were substantively different in its absence. That nonconstancy undermined Friedman and Schwartz's policy conclusions.
Charles Goodhart (1982) had also questioned that dummy.
It is legitimate to question any data-based dummy selected for a
period unrelated to historical events. Whether that dummy
``distorted the evidence'' is less obvious, since econometricians
often use indicators to clarify evidence or to proxy for unobserved
variables. In its place, we used a nonlinear equilibrium
correction, which had two equilibria, one for normal times and one
for disturbed times (although one could hardly call the First World
War ``normal''). Like Friedman and Schwartz, we did include a dummy
for the two world wars that captured a ![]() increase in demand, probably due
to increased risks. Huhne later did a TV program about the debate,
spending a day at my house filming.
increase in demand, probably due
to increased risks. Huhne later did a TV program about the debate,
spending a day at my house filming.
Hendry and Ericsson (1983) was finally published nearly eight years later in [93], after a prolonged editorial process. Just when we thought the issue was laid to rest, Chris Attfield, David Demery, and Nigel Duck (1995) claimed that our equation had broken down on data extended to the early 1990s whereas the Friedman and Schwartz specification was constant.
To compile a coherent statistical series over a long run of history, Attfield, Demery, and Duck had spliced several different money measures together; but they had not adjusted the corresponding measures of the opportunity cost. With that combination, our model did indeed fail. However, as shown in [166], our model remained constant over the whole sample once we used an appropriate measure of opportunity cost, whereas the updated Friedman and Schwartz model failed. Escribano (2004) updates our equation through 2000 and confirms its continued constancy.
Your model of US narrow money demand also generated controversy, as when you presented it at the Fed.
Yes, that research appeared as [96] with Yoshi Baba and Ross Starr. After the supposed break-down in US money demand recorded by Steve Goldfeld (1976), it was natural to implement similar models for the United States. Many new financial instruments had been introduced, including money market mutual funds, CDs, and NOW and SuperNOW accounts, so we hypothesized that these non-modeled financial innovations were the cause of the instability in money demand. Ross also thought that long-term interest-rate volatility had changed the maturity structure of the bond market, especially when the Fed implemented its New Operating Procedures. A high long rate was no longer a signal to buy because high interest rates were associated with high variances, and interest rates might go higher still and induce capital losses. This situation suggested calculating a certainty-equivalent long-run interest rate--that is, the interest rate adjusted for risk.
Otherwise, the basic approach and specifications were similar. We treated M1 as being determined by the private sector, conditional on interest rates set by the Fed, although the income elasticity was one half, rather than unity, as in the United Kingdom. Seminars at the Fed indeed produced a number of challenges, including the claim that the Fed engineered a monetary expansion for Richard Nixon's re-election. Dummies for that period were insignificant, so agents were willing to hold that money at the interest rates set, confirming valid conditioning. Another criticism concerned the lag structure, which represented average adjustment speeds in a large and complex economy.
Some economists still regard the final formulation in [96] as too complicated. Sometimes, I think that they believe the world is inherently simple. Other times, I think that they are concerned about data mining. Have you had similar reactions?
Data mining could never spuriously produce the sizes of
![]() -values we found,
however many search paths were explored. The variables might proxy
unmodeled effects, but their large
-values we found,
however many search paths were explored. The variables might proxy
unmodeled effects, but their large ![]() -statistics could not arise by chance.
-statistics could not arise by chance.
3.6 Dynamic Econometrics
That takes us to your book Dynamic Econometrics [127], perhaps the largest single project of your professional career so far. This book had several false starts, dating back to just after you had finished your PhD.
In 1972, the Italian public company IRI invited Pravin Trivedi and myself to publish (in Italian) a set of lectures on dynamic modeling. In preparing those lectures, we became concerned that conventional econometric approaches camouflaged mis-specification. Unfortunately, the required revisions took more than two decades!
Your lectures with Pravin set out a research agenda that included a general analysis of mis-specification (as in [18]), the plethora of estimators (unified in [21]), and empirical model design (systematized in [43], [46], [49], and [69]).
Building on the success of [11] in explaining the simulation results in Goldfeld and Quandt (1972), [18] used a simple analytic framework to investigate the consequences of various mis-specifications. As I mentioned earlier (in Section 1.1), I had discovered the estimator generating equation while teaching. To round off the book, I developed some substantive illustrations of empirical modeling, including consumers' expenditure, and housing and the construction sector (which appeared as [59] and [65]). However, new econometric issues continually appeared. For instance, how do we model capital rationing, or the demand for mortgages when only the supply is observed, or the stocks and flows of durables? I realized that I could not teach students how to do applied econometrics until I had sorted out at least some of these problems.
Did you see that as the challenge in writing the book?
Yes. The conventional approach to modeling was to write down the economic theory, collect variables with the same names (such as consumers' expenditure for consumption), develop mappings between the theory constructs and the observations, and then estimate the resulting equations. I had learned that that approach did not work. The straitjacket of the prevailing approach meant that one understood neither the data processes nor the behavior of the economy. I tried a more data-based approach, in which theory provided guidance rather than a complete structure, but that approach required developing concepts of model design and modeling strategy.
You again attempted to write the book when you were visiting Duke University annually in the mid- to late-1980s.
Yes, with Bob Marshall and Jean-François Richard. By that time, common factors, the theory of reduction, equilibrium correction and cointegration, encompassing, and exogeneity had clarified the empirical analysis of individual equations; and powerful software with recursive estimators implemented the ideas. However, modeling complete systems raised new issues, all of which had to be made operational. Writing the software package PcFiml enforced beginning from the unrestricted system, checking its congruence, reducing to a model thereof, testing over-identification, and encompassing the VAR; see [79], [110], and [114]. This work matched parallel developments on system cointegration by Søren, Katarina, and others in Copenhagen.
Analyses were still needed of general-to-specific modeling and diagnostic testing in systems (which eventually came in [122]), judging model reliability (my still unpublished Walras-Bowley lecture), and clarifying the role of inter-temporal optimization theory. That was a daunting list! Bob and Jean-François became more interested in auctions and experimental economics, so their co-authorship lapsed.
I remember receiving your first full draft of Dynamic Econometrics for comment in the late 1980s.
That draft would not have appeared without help from Duo Qin and Carlo Favero. Duo transcribed my lectures, based on draft chapters, and Carlo drafted answers for the solved exercises. The final manuscript still took years more to complete.
Dynamic Econometrics lacks an extensive discussion of cointegration. That is a surprising omission, given your interest in cointegration and equilibrium correction.
All the main omissions in Dynamic Econometrics were deliberate, as they were addressed in other books. Cointegration had been treated in [104]; Monte Carlo in [53] and [95]; numerical issues and software in [81], [99], and [115]; the history of econometrics in [132]; and forecasting was to come, presaged by [112]. That distribution of topics let Dynamic Econometrics focus on modeling. Because (co)integrated series can be reduced to stationarity, much of Dynamic Econometrics assumes stationarity. Other forms of nonstationarity would be treated later in [163] and [170]. Even as it stood, Dynamic Econometrics was almost 1,000 pages long when published!
You dedicated Dynamic Econometrics to your wife Evelyn and your daughter Vivien. How have they contributed to your work on econometrics?
I fear that we tread on thin ice here, whatever I say! Evelyn and Vivien have helped in numerous ways, both directly and indirectly, such as by facilitating time to work on ideas and time to visit collaborators. They have also tolerated numerous discussions on econometrics, corrected my grammar, and, in Vivien's case, questioned my analyses and helped debug the software. As you know, Vivien is now a professional economist in her own right.
3.7 Monte Carlo Methodology
Let's now turn to three of the omissions from Dynamic Econometrics: Monte Carlo, the history of econometrics, and forecasting.
Pravin introduced me to the concepts of Monte Carlo analysis, based on Hammersley and Handscomb (1964). I implemented some of their procedures, particularly antithetic variates (AVs) in [8] with Pravin, and later control variates in [16] with Robin Harrison.
I think that it is worth repeating your story about antithetic variates.
Pravin and I were graduate students at the time. We were investigating forecasts from estimated dynamic models and were using AVs to reduce simulation uncertainty. Approximating moving-average errors by autoregressive errors entailed inconsistent parameter estimates and hence, we thought, biased forecasts. To check, we printed the estimated AV bias for each Monte Carlo simulation of a static model with a moving-average error. We got page upon page of zeros, and a scolding from the computing center for wasting paper and computer time. In fact, we had inadvertently discovered that, when an estimator is invariant to the sign of the data but forecast errors change sign when the data do, then the average of AV pairs of forecast errors is precisely zero: see [8]. The idea works for symmetric distributions and hence for generalized least squares with estimated covariance matrices; see Kakwani (1967). I have since tried other approaches, as in [34] and [58].
Monte Carlo has been important for developing econometric methodology--by emphasizing the role of the DGP--and in your teaching, as reported in [73] and [92].
In Monte Carlo, knowledge of the DGP entails all subsequent results using data from that DGP. The same logic applies to economic DGPs, providing an essential step in the theory of reduction, and clarifying mis-specification analysis and encompassing. Monte Carlo also convinced me that the key issue was specification, rather than estimation. In Monte Carlo response surfaces, the relative efficiencies of estimators were dominated by variations between models, a view reinforced by my later forecasting research. Moreover, deriving control variates yielded insights into what determined the accuracy of asymptotic distribution theory. The software package PcNaive facilitates the live classroom use of Monte Carlo simulation to illustrate and test propositions from econometric theory; see [196]. A final major purpose of Monte Carlo was to check software accuracy by simulating econometric programs for cases where results were known.
Did you also use different software packages to check them against each other?
Yes. The Monte Carlo package itself had to be checked, of course, especially to ensure that its random number generator was i.i.d. uniform.
3.8 The History of Econometrics
How did you become interested in the history of econometrics?
Harry Johnson and Roy Allen sold me their old copies of Econometrica, which went back to the first volume in 1933. Reading early papers such as Haavelmo (1944) showed that textbooks focused on a small subset of the interesting ideas and ignored the evolution of our discipline. Dick Stone agreed, and he helped me to obtain funding from the ESRC. By coincidence, Mary Morgan had lost her job at the Bank of England when Margaret Thatcher abolished exchange controls in 1979, so Mary and I commenced work together. Mary was the optimal person to investigate the history objectively, undertaking extensive archival research and leading to her superb book, Morgan (1990). We had the privilege of (often jointly) interviewing many of our discipline's founding fathers, including Tjalling Koopmans, Ted Anderson, Gerhard Tintner, Jack Johnston, Trygve Haavelmo, Herman Wold, and Jan Tinbergen. The interviews with the latter three provided the basis for [84], [123], and [146]. Mary and I worked on [82] and also collated many of the most interesting papers for [132]. Shortly afterwards, Duo Qin (1993) studied the more recent history of econometrics through to about the mid-1970s.
Your interest must have also stimulated some of Chris Gilbert's work.
I held a series of seminars at Nuffield to discuss the history of econometrics with many who published on the topic, such as John Aldrich, Chris, Mary, and Duo. It was fascinating to re-examine the debates about Frisch's confluence analysis, between Keynes and Tinbergen, etc. On the latter, I concluded that Keynes was wrong, rather than right, as many believe. Keynes assumed that empirical econometrics was impossible without knowing the answer in advance. If that were true generally, science could never have progressed, whereas in fact it has.
You also differ markedly with the profession's view on another major debate--the one between Koopmans and Vining on ``measurement without theory.''
As [132] reveals, the profession has wrongly interpreted that debate's implications. Perhaps this has occurred because the debate is a `` classic''--something that nobody reads but everybody cites. Koopmans (1947) assumed that economic theory was complete, correct, and unchanging, and hence formed an optimal basis for econometrics. However, as Rutledge Vining (1949) noted, economic theory is actually incomplete, abstract, and evolving, so the opposite inference can be deduced. Koopmans's assumption is surprising because Koopmans himself was changing economic theory radically through his own research. Economists today often use theories that differ from those that Koopmans alluded to, but still without concluding that Koopmans was wrong. However, absent Koopmans's assumption, one cannot justify forcing economic-theory specifications on data.
3.9 Economic Policy and Government Interactions
London gave ready access to government organizations, and LSE fostered frequent interactions with government economists. There is no equivalent academic institution in Washington with such close government contacts. You have had long-standing relationships with both the Treasury and the Bank of England.
The Treasury's macro-econometric model had a central role in economic policy analysis and forecasting, so it was important to keep its quality as high as feasible with the resources available. The Treasury created an academic panel to advise on their model, and that panel met regularly for many years, introducing developments in economics and econometrics, and teaching modeling to their recently hired economists.
Also, DHSY attracted the Treasury's attention. The negative effect of inflation on consumers' expenditure--approximating the erosion of wealth--entailed that if stimulatory fiscal policy increased inflation, the overall outcome was deflationary. Upon replacing the Treasury's previous consumption function with DHSY, many multipliers in the Treasury model changed sign, and debates followed about what were the correct and wrong signs for such multipliers. Some economists rationalized these signs as being due to forward-looking agents pre-empting government policy, which then had the opposite effect from the previous ``Keynesian'' predictions.
The Bank of England also had an advisory panel. My housing model showed large effects on house prices from changes in outstanding mortgages because the mortgage market was credit-constrained, so (in the mid-1980s) I served on the Bank's panel, examining equity withdrawal from the housing market and the consequential effect of housing wealth on expenditure and inflation. Civil servants and ministers interacted with LSE faculty on parliamentary select committees as well. Once, in a deputation with Denis Sargan and other LSE economists, we visited Prime Minister Callaghan to explain the consequences of expansionary policies in a small open economy.
You participated in two select committees, one on monetary policy and one on economic forecasting.
I suspect that my notoriety was established by [32], my paper nicknamed ``Alchemy,'' which was even discussed in Parliament for deriding the role of money. Shortly after [32] appeared, a Treasury and Civil Service Committee on monetary policy was initiated because many Members of Parliament were unconvinced by Margaret Thatcher's policy of monetary control, and they sought the evidential basis for that policy. The committee heard from many of the world's foremost economists. Most of the evidence was not empirical but purely theoretical, being derived from simplified economic models from which their proprietor deduced what must happen. As the committee's econometric advisor, I collected what little empirical evidence there was, most of it from the Treasury. The Treasury, despite arguing the government's case, could not establish that money caused inflation. Instead, it found evidence that devaluations, wage-price spirals, excess demands, and commodity-price shocks mattered; see [36] and [37].
Those testimonies emphasized theory relative to empirical evidence--a more North American approach.
Many of those presenting evidence were North American, but several UK economists also used pure theory. Developing sustainable econometric evidence requires considerable time and effort, which is problematic for preparing memoranda to a parliamentary committee. Most of my empirical studies have taken years.
Surprisingly, evidence dominated theory in the 1991 enquiry into official economic forecasting; see [91]. There was little relevant theory, but there was no shortage of actual forecasts or studies of them. There were many papers on statistical forecasting, but few explicitly on economic forecasting for large, complex, nonstationary systems in which agents could change their behavior. Forecasts from different models frequently conflicted, and the underlying models often suffered forecast failure. As makridakis and Hibon (2000) and [191] argue, those realities could not be explained within the standard paradigm that forecasts were the conditional expectations. That enquiry triggered my interest in developing a viable theory of forecasting. Even after numerous papers--starting with [124], [125], [137], [138], [139], and [141]--that research program is still ongoing.
You have also interacted with government on the preparation and quality of national statistics.
In the mid-1960s, I worked on National Accounts at the Central Statistical Office with Jack Hibbert and David Flaxen. Attributing components of output to sectors, calculating output in constant prices, and aggregating the components to measure GNP was an enlightening experience. Most series were neither chained nor Divisia, but Laspeyres, and updated only intermittently, often inducing changes in estimated relationships. More recently, in [179] and [190] with Andreas Beyer and Jurgen Doornik, I have helped create aggregate data series for a synthetic Euroland. Data accuracy is obviously important to any approach that emphasizes empirical evidence, and I had learned that, although macro statistics were imperfect, they were usable for statistical analysis. For example, consumption and income were revised jointly, essentially maintaining cointegration between them.
Is that because the relationship is primarily between their nominal values--which alter less on updating--and involves prices only secondarily?
Yes. Ian Harnett (1984) showed that the price indices nearly cancel in the log ratio, which approximates the long-run outcome. However, occasional large revisions can warp the evidence. In the early 1990s, the Central Statistical Office revised savings rates by as much as 8 percentage points in some quarters (from 12% to 4%, say), compared to equation standard errors of about 1%.
In unraveling why these revisions were made, we uncovered mistakes in how the data were constructed. In particular, the doubling of the value-added tax (VAT) in the early 1980s changed the relation between the expenditure, output, and income measures of GNP. Prior to the increase in VAT, some individuals had cheated on their income tax but could not do so on expenditure taxes, so the expenditure measure had been the larger. That relationship reversed after VAT rose to 17.5%, but the statisticians wrongly assumed that they had mis-measured income earlier. Such drastic revisions to the data led me to propose that the recently created Office of National Statistics form a panel on the quality of economic statistics, and the ONS agreed. The panel has since discussed such issues as data measurement, revision, seasonal adjustment, and national income accounting.
3.10 The Theory of Economic Forecasting
The forecast failure in 1968 motivated your research on methodology. What has led you back to investigate ex ante forecasting?
That early failure dissuaded me from real-time forecasting, and it took 25 years to understand its message. In the late 1970s, I investigated ex post predictive failure in [31]. Later, in [62] with Yock Chong and also in [67], I looked at forecasting from dynamic systems, mainly to improve our power to test models. In retrospect, these two papers suggest much more insight than we had at the time--we failed to realize the implications of many of our ideas.
In an important sense, policy rekindled my interest in forecasting. The Treasury missed the sharp downturn in 1989, having previously missed the boom from 1987, and the resulting policy mistakes combined to induce high inflation and high unemployment. Mike Clements and I then sought analytical foundations for ex ante forecast failure when the economy is subject to structural breaks, and forecasts are from mis-specified and inconsistently estimated models that are based on incorrect economic theories and selected from inaccurate data. Everything was allowed to be wrong, but the investigator did not know that. Despite the generality of this framework, we derived some interesting theorems about economic forecasting, as shown in [105], [120], and [121]. The theory's empirical content matched the historical record, and it suggested how to improve forecasting methods.
Surprisingly, estimation per se was not a key issue. The two important features were allowing for mis-specified models and incorporating structural change in the DGP.
Yes. Given that combination, we could disprove the theorem that causal variables must beat non-causal variables at forecasting. Hence, extrapolative methods could win at forecasting, as shown in [171]. As [187] and [188] considered, that result suggests different roles for econometric models in forecasting and in economic policy, with causality clearly being essential in the latter.
The implications are fundamental. Ex ante forecast failure should not be used to reject models, as happened after the first oil crisis; see [159]. An almost perfect model could both forecast badly and be worse than an extrapolative procedure, so the debate between Box-Jenkins models and econometric models needs reinterpretation. In [162], we also came to realize a difference between equilibrium correction and error correction. The first induces cointegration, whereas in the latter a model adjusts to eliminate forecast errors. Devices like random walks and exponentially weighted moving averages embody error correction, whereas cointegrated systems--which have equilibrium correction--will forecast systematically badly when an equilibrium mean shifts, since they continue to converge to the old equilibrium. This explained why the Treasury's cointegrated system had performed so badly in the mid-1980s, following the sharp reduction in UK credit rationing. It also helped us demonstrate in [138] the properties of intercept corrections to offset such shifts. Most recently, [204] offers an exposition and [210] a compendium.
Are you troubled that the best explanatory model need not be the best for forecasting, and that the best policy model could conceivably be different from both, as suggested in [187]?
Some structural breaks--such as shifts in equilibrium means--are inimical to forecasts from econometric models but not from robust devices, which do not explain behavior. Such shifts might not affect the relevant policy derivatives. For example, the effect of interest rates on consumers' expenditure could be constant, despite a shift in the target level of savings due to (say) changed government provisions for health in old age. After the shift, changing the interest rate still will have the expected policy effect, even though the econometric model is mis-forecasting. Because we could robustify econometric models against such forecast failures, it may prove possible to use the same baseline causal econometric model for forecasting and for policy. If the econometric model alters after a policy experiment, then at least we learn that super exogeneity is lacking.
There was considerable initial reluctance to fund such research on forecasting, with referees deeming the ideas as unimplementable. Unfortunately, such attitudes have returned, as the ESRC has recently declined to support our research on this topic. One worries about their judgement, given the importance of forecasting in modern policy processes, and the lack of understanding of many aspects of the problem even after a decade of considerable advances.
4 Econometric Software
4.1 The History and Roles of GIVE and PcGive
In my MSc course, you enumerated three reasons for having written the computer package GIVE. The first was to facilitate your own research, seeing as many techniques were not available in other packages. The second was to ensure that other researchers did not have the excuse of unavailability--more controversial! The third was for teaching.
Non-operational econometric methods are pointless, so computer software must be written. Early versions of GIVE demonstrated the computability of FIML for systems with high-order vector autoregressive errors and latent-variable structures, as in [33]: [174] and [218] provide a brief history. In those days, code was on punched cards. I once dropped my box off a bus and spent days sorting it out.
You dropped your box of cards off a bus?
The IBM 360/65 was at UCL, so I took buses to and from LSE. Once, when rounding the Aldwych, the bus cornered faster than I anticipated, and my box of cards went flying. The program could only be re-created because I had numbered every one of the cards.
I trust that it wasn't a rainy London day!
That would have been a disaster. After moving to Oxford, I ported GIVE to a menu-driven form (called PcGive) on an IBM PC 8088, using a rudimentary FORTRAN compiler; see [81]. That took about four years, with Adrian Neale writing graphics in Assembler. A Windows version appeared after Jurgen Doornik translated PcGive to C++, leading to [195], [201], [197], and [194].
An attractive feature of PcGive has been its rapid incorporation of new tests and estimators--sometimes before they appeared in print, as with the Johansen (1988) reduced-rank cointegration procedure.
Adding routines initially required control of the software, but Jurgen recently converted PcGive to his Ox language, so that developments could be added by anyone writing Ox packages accessible from GiveWin; see Doornik (2001). The two other important features of the software are its flexibility and its accuracy, with the latter checked by standard examples and by Monte Carlo.
Earlier versions of PcGive were certainly less flexible: the menus defined everything that could be done, even while the program's interactive nature was well-suited to empirical model design. The use of Ox and the development of a batch language have alleviated that. I was astounded by a feature that Jurgen recently introduced. At the end of an interactive session, PcGive can generate batch code for the entire session. I am not aware of any other program that has such a facility.
Batch code helps replication. Our latest Monte Carlo package (PcNaive) is just an experimental design front end that defines the DGP, the model specification, sample size, etc., and then writes out an Ox program for that formulation. If desired, that program can be edited independently; and then it is run by Ox to calculate the Monte Carlo simulations. While this approach is mainly menu-driven, it delivers complete flexibility in Monte Carlo. For teaching, it is invaluable to have easy-to-use, uncrashable, menu-driven programs, whereas complicated batch code is a disaster waiting to happen.
In writing PcGive, you sought to design a program that was not only numerically accurate, but also reasonably bug-proof. I wonder how many graduate students have mis-programmed GMM or some other estimator using GAUSS or RATS.
Coding mistakes and inefficient programs can certainly produce
inaccurate output. Jurgen found that the RESET ![]() -statistic can differ by a factor of
a hundred, depending upon whether it is calculated by direct
implementation in regression or by partitioned inversion using
singular value decomposition. Bruce McCullough has long been
concerned about accurate output, and with good reason, as his
comparison in McCullough (1998) shows.
-statistic can differ by a factor of
a hundred, depending upon whether it is calculated by direct
implementation in regression or by partitioned inversion using
singular value decomposition. Bruce McCullough has long been
concerned about accurate output, and with good reason, as his
comparison in McCullough (1998) shows.
The latest development is the software package PcGets, designed with Hans-Martin Krolzig. ``Gets'' stands for ``general-to-specific,'' and PcGets now automatically selects an undominated congruent regression model from a general specification. Its simulation properties confirm many of the earlier methodological claims about general-to-specific modeling, and PcGets is a great time-saver for large problems; see [175], [206], [209], and [226].
PcGets still requires the economist's value added in terms of the choice of variables and in terms of transformations of the unrestricted model.
The algorithm indeed confirms the advantages of good economic analysis, both through excluding irrelevant effects and (especially) through including relevant ones. Still, excessive simplification--as might be justified by some economic theory--will lead to a false general specification with no good model choice. Fortunately, there seems little power loss from some over-specification with orthogonal regressors, and the empirical size remains close to the nominal.
4.2 The Role of Computing Facilities
More generally, computing has played a central role in the development of econometrics.
Historically, it has been fundamental. Estimators that were infeasible in the 1940s are now routine. Excellent color graphics are also a major boon. Computation can still be a limiting factor, though. Simulation estimation and Monte Carlo studies of model selection strain today's fastest PCs. Parallel computation thus remains of interest, as discussed in [214] with Neil Shephard and Jurgen Doornik.
There is an additional close link between computing and econometrics: different estimators are often different algorithms for approximating the same likelihood, as with the estimator generating equation. Also, inefficient numerical procedures can produce inefficient statistical estimates, as with Cochrane-Orcutt estimates for dynamic models with autoregressive errors. In this example, step-wise optimization and the corresponding statistical method are both inefficient because the coefficient covariance matrix is non-diagonal. Much can be learned about our statistical procedures from their numerical properties.
4.3 The Role of Computing in Teaching
Was it difficult to use computers in teaching when only batch jobs could be run?
Indeed it was. My first computer-based teaching was with Ken Wallis using the Wharton model for macroeconomic experiments; see McCarthy (1972). The students gave us their experimental inputs, which we ran, receiving the results several hours later. Now such illustrations are live and virtually instantaneous, and so can immediately resolve questions and check conjectures. The absorption of interactive computing into teaching has been slow, even though it has been feasible for nearly two decades. I first did such presentations in the mid-1980s, and my first interactive-teaching article was [68], with updates in [70] and [131].
Even now, few people use PCs interactively in seminars, although some do in teaching. Perhaps interactive computer-based presentations require familiarity with the software, reliability of the software, and confidence in the model being presented. When I have made such presentations, they have often led to testing the model in ways that I hadn't previously thought of. If the model fails on such tests, that is informative for me because it implies room for model improvement. If the model doesn't fail, then that is additional evidence in favor of the model.
Some conjectures involve unavailable data, but Internet access to data banks will improve that. Also, models that were once thought too complicated to model live--such as dynamic panels with awkward instrumental variable structures, allowing for heterogeneity, etc.--are now included in PcGive. In live Monte Carlo simulations, students often gain important insights from experiments where they choose the parameter values.
5 Concluding Remarks
5.1 Achievements and Failures
What do you see as your most important achievements, and what were your biggest failures?
Achievements are hard to pin down, even retrospectively, but the ones that have given me most pleasure were (a) consolidating estimation theory through the estimator generating equation; (b) formalizing the methodology and model concepts to sustain general-to-specific modeling; (c) producing a theory of economic forecasting that has substantive content; (d) successfully designing computer automation of general-to-specific model selection in PcGets; (e) developing efficient Monte Carlo methods; (f) building useful empirical models of housing, consumers' expenditure, and money demand; and (g) stimulating a resurgence of interest in the history of our discipline.
I now see automatic model selection as a new instrument for the social sciences, akin to the microscope in the biological sciences. Already, PcGets has demonstrated remarkable performance across different (unknown) states of nature, with the empirical data generating process being found almost as often by commencing from a general model as from the DGP itself. Retention of relevant variables is close to the theoretical maximum, and elimination of irrelevant variables occurs at the rate set by the chosen significance level. The selected estimates have the appropriate reported standard errors, and they can be bias-corrected if desired, which also down-weights adventitiously significant coefficients. These results essentially resuscitate traditional econometrics, despite data-based selection; see [226] and [231]. Peter Phillips (1996) has made great strides in the automation of model selection using a related approach; see also [221].
The biggest failure is not having persuaded more economists of the value of data-based econometrics in empirical economics, although that failure has stimulated improvements in modeling and model formulations. This reaction is certainly not uniform. Many empirical researchers in Europe adopt a general-to-specific modeling approach--which may be because they are regularly exposed to its applications--whereas elsewhere other views are dominant, and are virtually enforced by some journals.
What role does failure play in econometrics and empirical modeling?
As a psychology student, I learned that failure was the route to success. Looking for positive instances of a concept is a slow way to acquire it when compared to seeking rejections.
Because macroeconomic data are non-experimental, aren't economists correctly hesitant about over-emphasizing the role of data in empirical modeling?
Such data are the outcome of governmental administrative processes, of which we can only observe one realization. We cannot re-run an economy under a different state of nature. The analysis of non-experimental data raises many interesting issues, but lack of experimentation merely removes a tool, and its lack does not preclude a scientific approach or prevent progress.
It certainly hasn't stopped astronomers, environmental biologists, or meteorologists from analyzing their data.
Indeed. Historically, there are many natural, albeit uncontrolled, experiments. Governments experiment with policies; new legislation has unanticipated consequences; and physical and political turmoil through violent weather, earthquakes, and war are ongoing. It is not easy to persuade governments to conduct controlled, small-scale, regular experiments. I once unsuccessfully suggested randomly perturbing the Treasury bill tender at a regular frequency to test its effects on the discount and money markets and on the banking system.
You have worked almost exclusively with macroeconomic time series, rather than with micro data in cross-sections or in panels. Why did you make that choice?
My first empirical study analyzed panel data, and it helped convince me to focus on macroeconomic time series instead. I was consulting for British Petroleum on bidding behavior, and I had about a million observations in total for oil products on about a thousand outlets for every Canton in Switzerland, monthly, over a decade. BP's linear programming system took prices as parametric, and they wanted to endogenize price determination. The Swiss study sought to estimate demand functions. Even allowing for fixed effects, dynamics dominated, with near-unit roots, despite the (now known) downward biases. We built optimized models to determine bids, assuming that the winning margin had a Weibull distribution, estimated from information on the winning bid and our own bid, which might coincide. I also wrote a panel-data analysis program with Chris Gilbert to study voting behavior in York. The program tested for pooling the cross-sections, the time series, and both. It was difficult to get much out of such panels, as only a tiny percentage of the variation was explained. It seemed unlikely that the remaining variation was random, so much of the explanation must be missing. Because omitted variables would rarely be orthogonal to the included variables, the estimated coefficients would not correspond to the behavioral parameters. With macroeconomic data, the problem is the converse of fitting too well. A difficulty with cross-sections is their dependence on time, so the errors are not independent, due to common effects. Quite early on, I thus decided to first understand time series and then come back to analyzing micro data, but I haven't reached the end of the road on time series yet.
Your view on cross-section modeling differs from the conventional view that it reveals the long run.
I have not seen a proof of that claim. As a counter-example, suppose that a recent shock places all agents in disequilibrium during the measured cross-section.
5.2 Directions for the Future
What directions will your research explore?
A gold mine of new results awaits discovery from extending the theory of economic forecasting in the face of rare events, and from delineating what aspects of models are most important in forecasting. Also, much remains to be understood about modeling procedures. Both are worthwhile topics, especially as new developments are likely to have practical value. The econometrics of economic policy analysis also remains under-developed. For instance, it would help to understand which structural changes affect forecasting but not policy in order to clarify the relationship between forecasting models and policy models. Given the difficulties with impulse response analyses documented in [128], [165], and [188], open models would repay a visit. Policy analyses require congruent models with constant parameters, so more powerful tests of changes in dynamic coefficients are needed.
Many further advances are already in progress for automatic model selection, such as dealing with cointegration, with systems, and with nonlinear models. This new tool resolves a hitherto intractable problem, namely, estimating a regression when there are more candidate variables than observations, as can occur when there are many potential interactions. Provided that the DGP has fewer variables than observations, repeated application of the multi-path search process to feasible blocks is likely to deliver a model with the appropriate properties.
That should keep you busy!
References
Anderson, T. W. (1962) ``The Choice of the Degree of a Polynomial Regression as a Multiple Decision Problem'', Annals of Mathematical Statistics, 33, 1, 255--265.
Anderson, T. W. (1976) ``Estimation of Linear Functional Relationships: Approximate Distributions and Connections with Simultaneous Equations in Econometrics'', Journal of the Royal Statistical Society, Series B, 38, 1, 1--20 (with discussion).
Attfield, C. L. F., D. Demery, and N. W. Duck (1995) ``Estimating the UK Demand for Money Function: A Test of Two Approaches'', Mimeo, Department of Economics, University of Bristol, Bristol, England, November.
Benassy, J.-P. (1986) Macroeconomics: An Introduction to the Non-Walrasian Approach, Academic Press, Orlando.
Bontemps, C., and G. E. Mizon (2003) ``Congruence and Encompassing'', Chapter 15 in B. P. Stigum (ed.) Econometrics and the Philosophy of Economics: Theory-Data Confrontations in Economics, Princeton University Press, Princeton, 354--378.
Box, G. E. P., and G. M. Jenkins (1970) Time Series Analysis: Forecasting and Control, Holden-Day, San Francisco.
Breusch, T. S. (1986) ``Hypothesis Testing in Unidentified Models'', Review of Economic Studies, 53, 4, 635--651.
Chan, N. H., and C. Z. Wei (1988) ``Limiting Distributions of Least Squares Estimates of Unstable Autoregressive Processes'', Annals of Statistics, 16, 1, 367--401.
Coghlan, R. T. (1978) ``A Transactions Demand for Money'', Bank of England Quarterly Bulletin, 18, 1, 48--60.
Cooper, J. P., and C. R. Nelson (1975) ``The Ex Ante Prediction Performance of the St. Louis and FRB-MIT-PENN Econometric Models and Some Results on Composite Predictors'', Journal of Money, Credit, and Banking, 7, 1, 1--32.
Courakis, A. S. (1978) ``Serial Correlation and a Bank of England Study of the Demand for Money: An Exercise in Measurement Without Theory'', Economic Journal, 88, 351, 537--548.
Cox, D. R. (1962) ``Further Results on Tests of Separate Families of Hypotheses'', Journal of the Royal Statistical Society, Series B, 24, 2, 406--424.
Deaton, A. S. (1977) ``Involuntary Saving Through Unanticipated Inflation'', American Economic Review, 67, 5, 899--910.
Doornik, J. A. (2001) Ox 3.0: An Object-oriented Matrix Programing Language, Timberlake Consultants Press, London. 40
Durbin, J. (1988) ``Maximum Likelihood Estimation of the Parameters of a System of Simultaneous Regression Equations'', Econometric Theory, 4, 1, 159--170 (Paper presented to the European Meetings of the Econometric Society, Copenhagen, 1963).
Engle, R. F., and C. W. J. Granger (1987) ``Co-integration and Error Correction: Representation, Estimation, and Testing'', Econometrica, 55, 2, 251--276.
Escribano, A. (1985) ``Non-linear Error-correction: The Case of Money Demand in the U.K. (1878--1970)'', Mimeo, University of California at San Diego, La Jolla, California, December.
Escribano, A. (2004) ``Nonlinear Error Correction: The Case of Money Demand in the United Kingdom (1878--2000)'', Macroeconomic Dynamics, 8, 1, 76--116.
Fisk, P. R. (1967) Stochastically Dependent Equations: An Introductory Text for Econometricians, Charles Griffin, London (Griffin's Statistical Monographs and Courses, No. 21).
Friedman, M., and A. J. Schwartz (1982) Monetary Trends in the United States and the United Kingdom: Their Relation to Income, Prices, and Interest Rates, 1867--1975, University of Chicago Press, Chicago.
Frisch, R. (1933) ``Editorial'', Econometrica, 1, 1, 1--4.
Gilbert, C. L. (1986) ``Professor Hendry's Econometric Methodology'', Oxford Bulletin of Economics and Statistics, 48, 3, 283--307.
Godfrey, L. G. (1988) Misspecification Tests in Econometrics, Cambridge University Press, Cambridge.
Goldfeld, S. M. (1976) ``The Case of the Missing Money'', Brookings Papers on Economic Activity, 1976, 3, 683--730 (with discussion).
Goldfeld, S. M., and R. E. Quandt (1972) Nonlinear Methods in Econometrics, North- Holland, Amsterdam.
Goodhart, C. A. E. (1982) ``Monetary Trends in the United States and the United Kingdom: A British Review'', Journal of Economic Literature, 20, 4, 1540--1551.
Granger, C. W. J. (1981) ``Some Properties of Time Series Data and Their Use in Econometric Model Specification'', Journal of Econometrics, 16, 1, 121--130.
Granger, C.W. J. (1986) ``Developments in the Study of Cointegrated Economic Variables'', Oxford Bulletin of Economics and Statistics, 48, 3, 213--228.
Granger, C. W. J., and A. A. Weiss (1983) ``Time Series Analysis of Error-correction Models'', in S. Karlin, T. Amemiya, and L. A. Goodman (eds.) Studies in Econometrics, Time Series, and Multivariate Statistics: In Honor of Theodore W. Anderson, Academic Press, New York, 255--278.
Haavelmo, T. (1944) ``The Probability Approach in Econometrics'', Econometrica, 12, Supplement, i--viii, 1--118.
Hacche, G. (1974) ``The Demand for Money in the United Kingdom: Experience Since 1971'', Bank of England Quarterly Bulletin, 14, 3, 284--305.
Hall, R. E. (1978) ``Stochastic Implications of the Life Cycle-Permanent Income Hypothesis: Theory and Evidence'', Journal of Political Economy, 86, 6, 971--987. 41
Hammersley, J. M., and D. C. Handscomb (1964) Monte Carlo Methods, Chapman and Hall, London.
Hannan, E. J., and B. G. Quinn (1979) ``The Determination of the Order of an Autoregression'', Journal of the Royal Statistical Society, Series B, 41, 2, 190--195.
Harnett, I. (1984) An Econometric Investigation into Recent Changes of UK Personal Sector Consumption Expenditure, University of Oxford, Oxford (Unpublished M. Phil. Thesis).
Hendry, D. F., and N. R. Ericsson (1983) ``Assertion Without Empirical Basis: An Econometric Appraisal of `Monetary Trends in . . . the United Kingdom' by Milton Friedman and Anna Schwartz'', in Monetary Trends in the United Kingdom, Bank of England Panel of Academic Consultants, Panel Paper No. 22, Bank of England, London, October, 45--101.
Hildenbrand, W. (1994) Market Demand: Theory and Empirical Evidence, Princeton University Press, Princeton.
Hoover, K. D., and S. J. Perez (1999) ``Data Mining Reconsidered: Encompassing and the General-to-specific Approach to Specification Search'', Econometrics Journal, 2, 2, 167--191 (with discussion).
Johansen, S. (1988) ``Statistical Analysis of Cointegration Vectors'', Journal of Economic Dynamics and Control, 12, 2/3, 231--254.
Kakwani, N. C. (1967) ``The Unbiasedness of Zellner's Seemingly Unrelated Regression Equations Estimators'', Journal of the American Statistical Association, 62, 317, 141-- 142.
Katona, G., and E. Mueller (1968) Consumer Response to Income Increases, Brookings Institution, Washington, D.C.
Keynes, J. M. (1936) The General Theory of Employment, Interest and Money, Harcourt, Brace and Company, New York.
Klein, L. R. (1953) A Textbook of Econometrics, Row, Peterson and Company, Evanston.
Koopmans, T. C. (1947) ``Measurement Without Theory'', Review of Economics and Statistics (formerly the Review of Economic Statistics), 29, 3, 161--172.
Longbottom, A., and S. Holly (1985) ``EconometricMethodology and Monetarism: Professor Friedman and Professor Hendry on the Demand for Money'', Discussion Paper No. 131, London Business School, London, February.
Lucas, Jr., R. E. (1976) ``Econometric Policy Evaluation: A Critique'', in K. Brunner and A. H. Meltzer (eds.) The Phillips Curve and Labor Markets, North-Holland, Amsterdam, Carnegie-Rochester Conference Series on Public Policy, Volume 1, Journal of Monetary Economics, Supplement, 19--46 (with discussion).
Makridakis, S., and M. Hibon (2000) ``The M3-Competition: Results, Conclusions and Implications'', International Journal of Forecasting, 16, 4, 451--476.
McCarthy, M. D. (1972) The Wharton Quarterly Econometric Forecasting Model Mark III, University of Pennsylvania, Philadelphia (Studies in Quantitative Economics No. 6).
McCullough, B. D. (1998) ``Assessing the Reliability of Statistical Software: Part I'', American Statistician, 52, 4, 358--366. 42
Mizon, G. E. (1977) ``Inferential Procedures in Nonlinear Models: An Application in a UK Industrial Cross Section Study of Factor Substitution and Returns to Scale'', Econometrica, 45, 5, 1221--1242.
Mizon, G. E. (1995) ``Progressive Modeling of Macroeconomic Time Series: The LSE Methodology'', Chapter 4 in K. D. Hoover (ed.) Macroeconometrics: Developments, Tensions, and Prospects, Kluwer Academic Publishers, Boston, 107--170 (with discussion).
Mizon, G. E., and J.-F. Richard (1986) ``The Encompassing Principle and its Application to Testing Non-nested Hypotheses'', Econometrica, 54, 3, 657--678.
Morgan, M. S. (1990) The History of Econometric Ideas, Cambridge University Press, Cambridge.
Muth, J. F. (1961) ``Rational Expectations and the Theory of Price Movements'', Econometrica, 29, 3, 315--335.
Osborn, D. R. (1988) ``Seasonality and Habit Persistence in a Life Cycle Model of Consumption'', Journal of Applied Econometrics, 3, 4, 255--266.
Osborn, D. R. (1991) ``The Implications of Periodically Varying Coefficients for Seasonal Time-series Processes'', Journal of Econometrics, 48, 3, 373--384.
Pesaran, M. H. (1974) ``On the General Problem of Model Selection'', Review of Economic Studies, 41, 2, 153--171.
Phillips, A. W. (1954) ``Stabilisation Policy in a Closed Economy'', Economic Journal, 64, 254, 290--323.
Phillips, A. W. (1956) ``Some Notes on the Estimation of Time-forms of Reactions in Interdependent Dynamic Systems'', Economica, 23, 90, 99--113.
Phillips, A. W. (1957) ``Stabilisation Policy and the Time-forms of Lagged Responses'', Economic Journal, 67, 266, 265--277.
Phillips, A. W. (2000) ``Estimation of Systems of Difference Equations with Moving Average Disturbances'', Chapter 45 in R. Leeson (ed.) A. W. H. Phillips: Collected Works in Contemporary Perspective, Cambridge University Press, Cambridge, 423--444 (Walras-- Bowley Lecture, Econometric Society Meeting, San Francisco, December 1966).
Phillips, P. C. B. (1986) ``Understanding Spurious Regressions in Econometrics'', Journal of Econometrics, 33, 3, 311--340.
Phillips, P. C. B. (1987) ``Time Series Regression with a Unit Root'', Econometrica, 55, 2, 277--301.
Phillips, P. C. B. (1996) ``Econometric Model Determination'', Econometrica, 64, 4, 763-- 812.
Phillips, P. C. B. (1997) ``The ET Interview: Professor Clive Granger'', Econometric Theory, 13, 2, 253--303.
Qin, D. (1993) The Formation of Econometrics: A Historical Perspective, Clarendon Press, Oxford.
Richard, J.-F. (1980) ``Models with Several Regimes and Changes in Exogeneity'', Review of Economic Studies, 47, 1, 1--20. 43
Robinson, P. M. (2003) ``Denis Sargan: Some Perspectives'', Econometric Theory, 19, 3, 481--494.
Samuelson, P. A. (1947) Foundations of Economic Analysis, Harvard University Press, Cambridge.
Samuelson, P. A. (1961) Economics: An Introductory Analysis, McGraw-Hill Book Company, New York, Fifth Edition.
Sargan, J. D. (1964) ``Wages and Prices in the United Kingdom: A Study in Econometric Methodology'', in P. E. Hart, G. Mills, and J. K. Whitaker (eds.) Econometric Analysis for National Economic Planning, Volume 16 of Colston Papers, Butterworths, London, 25--54 (with discussion).
Sargan, J. D. (1975) ``Asymptotic Theory and Large Models'', International Economic Review, 16, 1, 75--91.
Sargan, J. D. (1980) ``Some Tests of Dynamic Specification for a Single Equation'', Econometrica, 48, 4, 879--897.
Savin, N. E. (1980) ``The Bonferroni and the Scheffé Multiple Comparison Procedures'', Review of Economic Studies, 47, 1, 255--273.
Silvey, S. D. (1959) ``The Lagrangian Multiplier Test'', Annals of Mathematical Statistics, 30, 2, 389--407.
Stigum, B. P. (1990) Toward a Formal Science of Economics: The Axiomatic Method in Economics and Econometrics, MIT Press, Cambridge.
Stock, J. H. (1987) ``Asymptotic Properties of Least Squares Estimators of Cointegrating Vectors'', Econometrica, 55, 5, 1035--1056.
Summers, L. H. (1991) ``The Scientific Illusion in Empirical Macroeconomics'', Scandinavian Journal of Economics, 93, 2, 129--148.
Thomas, J. J. (1964) Notes on the Theory of Multiple Regression Analysis, Contos Press, Athens (Center of Economic Research, Training Seminar Series, No. 4).
Tinbergen, J. (1951) Business Cycles in the United Kingdom, 1870--1914, North-Holland, Amsterdam.
Trivedi, P. K. (1970) ``The Relation Between the Order-Delivery Lag and the Rate of Capacity Utilization in the Engineering Industry in the United Kingdom, 1958--1967'', Economica, 37, 145, 54--67.
Vining, R. (1949) ``Koopmans on the Choice of Variables To Be Studied and of Methods of Measurement'', Review of Economics and Statistics, 31, 2, 77--86.
West, K. D. (1988) ``Asymptotic Normality, When Regressors Have a Unit Root'', Econometrica, 56, 6, 1397--1417.
White, H. (1990) ``A Consistent Model Selection Procedure Based
on ![]() -Testing'',
Chapter
16 in C. W. J. Granger (ed.) Modelling Economic Series: Readings
in Econometric
Methodology, Oxford University Press, Oxford, 369--383.
-Testing'',
Chapter
16 in C. W. J. Granger (ed.) Modelling Economic Series: Readings
in Econometric
Methodology, Oxford University Press, Oxford, 369--383.
Whittle, P. (1963) Prediction and Regulation by Linear Least-square Methods, D. Van Nostrand, Princeton.
THE PUBLICATIONS OF DAVID F. HENDRY
1966
1. Hendry, D. F. (1966) Survey of student income and expenditure at Aberdeen University, 1963--64 and 1964--65. Scottish Journal of Political Economy 13, 363--376.
1970
2. Hendry, D. F. (1970) Book review of Introduction to Linear Algebra for Social Scientists by Gordon Mills. Economica 37, 217--218.
1971
3. Hendry, D. F. (1971a) Discussion. Journal of the Royal Statistical Society, Series A 134, 315.
4. Hendry, D. F. (1971b) Maximum likelihood estimation of systems of simultaneous regression equations with errors generated by a vector autoregressive process. International Economic Review 12, 257--272.
1972
5. Hendry, D. F. (1972a) Book review of Elements of Econometrics by J. Kmenta. Economic Journal 82, 221--222.
6. Hendry, D. F. (1972b) Book review of Regression and Econometric Methods by David S. Huang. Economica 39, 104--105.
7. Hendry, D. F. (1972c) Book review of The Analysis and Forecasting of the British Economy by M. J. C. Surrey. Economica 39, 346.
8. Hendry, D. F., & P. K. Trivedi (1972) Maximum likelihood estimation of difference equations with moving average errors: A simulation study. Review of Economic Studies 39, 117--145.
1973
9. Hendry, D. F. (1973a) Book review of Econometric Models of Cyclical Behaviour, edited by Bert G. Hickman. Economic Journal 83, 944--946.
10. Hendry, D. F. (1973b) Discussion. Journal of the Royal Statistical Society, Series A 136, 385--386.
11. Hendry, D. F. (1973c) On asymptotic theory and finite sample experiments. Economica 40, 210--217.
1974
12. Hendry, D. F. (1974a) Book review of A Textbook of Econometrics by L. R. Klein. Economic Journal 84, 688--689.
13. Hendry, D. F. (1974b) Book review of Optimal Planning for Economic Stabilization: The Application of Control Theory to Stabilization Policy by Robert S. Pindyck. Economica 41, 353.
14. Hendry, D. F. (1974c)Maximum likelihood estimation of systems of simultaneous regression equations with errors generated by a vector autoregressive process: A correction. International Economic Review 15, 260.
15. Hendry, D. F. (1974d) Stochastic specification in an aggregate demand model of the United Kingdom. Econometrica 42, 559--578.45
16. Hendry, D. F., & R. W. Harrison (1974) Monte Carlo methodology and the small sample behaviour of ordinary and two-stage least squares. Journal of Econometrics 2, 151--174.
1975
17. Hendry, D. F. (1975a) Book review of Forecasting the U.K. Economy by J. C. K. Ash and D. J. Smyth. Economica 42, 223--224.
18. Hendry, D. F. (1975b) The consequences of mis-specification of dynamic structure, autocorrelation, and simultaneity in a simple model with an application to the demand for imports. In G. A. Renton (ed.), Modelling the Economy, pp. 286--320 (with discussion). London: Heinemann Educational Books.
1976
19. Hendry, D. F. (1976a) Discussion. Journal of the Royal Statistical Society, Series A 139, 494--495.
20. Hendry, D. F. (1976b) Discussion. Journal of the Royal Statistical Society, Series B 38, 24--25.
21. Hendry, D. F. (1976c) The structure of simultaneous equations estimators. Journal of Econometrics 4, 51--88.
22. Hendry, D. F., & A. R. Tremayne (1976) Estimating systems of dynamic reduced form equations with vector autoregressive errors. International Economic Review 17, 463--471.
1977
23. Hendry, D. F. (1977a) Book review of Studies in Nonlinear Estimation, edited by Stephen M. Goldfeld and Richard E. Quandt. Economica 44, 317--318.
24. Hendry, D. F. (1977b) Book review of The Models of Project LINK, edited by J. L. Waelbroeck. Journal of the Royal Statistical Society, Series A 140, 561--562.
25. Hendry, D. F. (1977c) Comments on Granger-Newbold's `Time series approach to econometric model building' and Sargent-Sims' `Business cycle modeling without pretending to have too much a priori economic theory' . In C. A. Sims (ed.), New Methods in Business Cycle Research: Proceedings from a Conference, pp. 183--202. Minneapolis: Federal Reserve Bank of Minneapolis.
26. Hendry, D. F., & G. J. Anderson (1977) Testing dynamic specification in small simultaneous systems: An application to a model of building society behavior in the United Kingdom. In M. D. Intriligator (ed.), Frontiers of Quantitative Economics, vol. 3A, pp. 361--383. Amsterdam: North-Holland.
27. Hendry, D. F., & F. Srba (1977) The properties of autoregressive instrumental variables estimators in dynamic systems. Econometrica 45, 969--990.
1978
28. Davidson, J. E. H., D. F. Hendry, F. Srba, & S. Yeo (1978) Econometric modelling of the aggregate time-series relationship between consumers' expenditure and income in the United Kingdom. Economic Journal 88, 661--692.
29. Hendry, D. F., & G. E. Mizon (1978) Serial correlation as a convenient simplification, not a nuisance: A comment on a study of the demand for money by the Bank of England. Economic Journal 88, 549--563. 46
1979
30. Hendry, D. F. (1979a) The behaviour of inconsistent instrumental variables estimators in dynamic systems with autocorrelated errors. Journal of Econometrics 9, 295--314.
31. Hendry, D. F. (1979b) Predictive failure and econometric modelling in macroeconomics: The transactions demand for money. In P. Ormerod (ed.), Economic Modelling: Current Issues and Problems in Macroeconomic Modelling in the UK and the US, pp. 217--242. London: Heinemann Education Books.
1980
32. Hendry, D. F. (1980) Econometrics-Alchemy or science? Economica 47, 387--406.
33. Hendry, D. F., & F. Srba (1980) AUTOREG: A computer program library for dynamic econometric models with autoregressive errors. Journal of Econometrics 12, 85--102.
34. Mizon, G. E., & D. F. Hendry (1980) An empirical application and Monte Carlo analysis of tests of dynamic specification. Review of Economic Studies 47, 21--45.
1981
35. Davidson, J. E. H., & D. F. Hendry (1981) Interpreting econometric evidence: The behaviour of consumers' expenditure in the UK. European Economic Review 16, 177--192 (with discussion).
36. Hendry, D. F. (1981a) Comment on HM Treasury's memorandum, `Background to the Government's economic policy' . In House of Commons (ed.), Third Report from the Treasury and Civil Service Committee, Session 1980--81, Monetary Policy, vol. 3, pp. 94--96 (Appendix 4). London: Her Majesty's Stationery Office.
37. Hendry, D. F. (1981b) Econometric evidence in the appraisal of monetary policy. In House of Commons (ed.), Third Report from the Treasury and Civil Service Committee, Session 1980--81, Monetary Policy, vol. 3, pp. 1--21 (Appendix 1). London: Her Majesty's Stationery Office.
38. Hendry, D. F., & J.-F. Richard (1981) Model formulation to simplify selection when specification is uncertain. Journal of Econometrics 16, 159.
39. Hendry, D. F., & T. von Ungern-Sternberg (1981) Liquidity and inflation effects on consumers' expenditure. In A. S. Deaton (ed.), Essays in the Theory and Measurement of Consumer Behaviour: In Honour of Sir Richard Stone, pp. 237--260. Cambridge: Cambridge University Press.
1982
40. Hendry, D. F. (1982a) Comment: Whither disequilibrium econometrics? Econometric Reviews 1, 65--70.
41. Hendry, D. F. (1982b) A reply to Professors Maasoumi and Phillips. Journal of Econometrics 19, 203--213.
42. Hendry, D. F. (1982c) The role of econometrics in macro-economic analysis. UK Economic Prospect 1982, 26--38.
43. Hendry, D. F., & J.-F. Richard (1982) On the formulation of empirical models in dynamic econometrics. Journal of Econometrics 20, 3--33. 47
1983
44. Engle, R. F., D. F. Hendry, & J.-F. Richard (1983) Exogeneity. Econometrica 51, 277--304.
45. Hendry, D. F. (1983a) Comment. Econometric Reviews 2, 111--114.
46. Hendry, D. F. (1983b) Econometric modelling: The `consumption function' in retrospect. Scottish Journal of Political Economy 30, 193--220.
47. Hendry, D. F. (1983c) On Keynesian model building and the rational expectations critique: A question of methodology. Cambridge Journal of Economics 7, 69--75.
48. Hendry, D. F., & R. C. Marshall (1983) On high and low
![]() 2
contributions. Oxford
Bulletin of Economics and Statistics 45, 313--316.
2
contributions. Oxford
Bulletin of Economics and Statistics 45, 313--316.
49. Hendry, D. F., & J.-F. Richard (1983) The econometric analysis of economic time series. International Statistical Review 51, 111--148 (with discussion).
1984
50. Anderson, G. J., & D. F. Hendry (1984) An econometric model of United Kingdom building societies. Oxford Bulletin of Economics and Statistics 46, 185--210.
51. Hendry, D. F. (1984a) Book review of Advances in Econometrics: Invited Papers for the 4th World Congress of the Econometric Society, edited by Werner Hildenbrand. Economic Journal 94, 403--405.
52. Hendry, D. F. (1984b) Econometric modelling of house prices in the United Kingdom. In D. F. Hendry and K. F. Wallis (eds.), Econometrics and Quantitative Economics, pp. 211--252. Oxford: Basil Blackwell.
53. Hendry, D. F. (1984c) Monte Carlo experimentation in econometrics. In Z. Griliches and M. D. Intriligator (eds.), Handbook of Econometrics, vol. 2, pp. 937--976. Amsterdam: North-Holland.
54. Hendry, D. F. (1984d) Present position and potential developments: Some personal views [on] time-series econometrics. Journal of the Royal Statistical Society, Series A 147, 327--338 (with discussion).
55. Hendry, D. F., A. Pagan, & J. D. Sargan (1984) Dynamic specification. In Z. Griliches and M. D. Intriligator (eds.), Handbook of Econometrics, vol. 2, pp. 1023--1100. Amsterdam: North-Holland.
56. Hendry, D. F., & K. F.Wallis (eds.) (1984a) Econometrics and Quantitative Economics. Oxford: Basil Blackwell.
57. Hendry, D. F., & K. F. Wallis (1984b) Editors' introduction. In D. F. Hendry and K. F. Wallis (eds.), Econometrics and Quantitative Economics, pp. 1--12. Oxford: Basil Blackwell.
1985
58. Engle, R. F., D. F. Hendry, & D. Trumble (1985) Small-sample properties of ARCH estimators and tests. Canadian Journal of Economics 18, 66--93.
59. Ericsson, N. R., & D. F. Hendry (1985) Conditional econometric modeling: An application to new house prices in the United Kingdom. In A. C. Atkinson and S. E. Fienberg (eds.), A Celebration of Statistics: The ISI Centenary Volume, pp. 251--285. New York: Springer-Verlag. 48
60. Hendry, D. F. (1985) Monetary economic myth and econometric reality. Oxford Review of Economic Policy 1, 72--84.
1986
61. Banerjee, A., J. J. Dolado, D. F. Hendry, & G. W. Smith (1986) Exploring equilibrium relationships in econometrics through static models: SomeMonte Carlo evidence. Oxford Bulletin of Economics and Statistics 48, 253--277.
62. Chong, Y. Y., & D. F. Hendry (1986) Econometric evaluation of linear macro-economic models. Review of Economic Studies 53, 671--690.
63. Hendry, D. F. (ed.) (1986a) Econometric Modelling with Cointegrated Variables. Special Issue, Oxford Bulletin of Economics and Statistics, 48, 3, August.
64. Hendry, D. F. (1986b) Econometric modelling with cointegrated variables: An overview. Oxford Bulletin of Economics and Statistics 48, 201--212.
65. Hendry, D. F. (1986c) Empirical modeling in dynamic econometrics. Applied Mathematics and Computation 20, 201--236.
66. Hendry, D. F. (1986d) An excursion into conditional varianceland. Econometric Reviews 5, 63--69.
67. Hendry, D. F. (1986e) The role of prediction in evaluating econometric models. Proceedings of the Royal Society, London, Series A 407, 25--33.
68. Hendry, D. F. (1986f) Using PC-GIVE in econometrics teaching. Oxford Bulletin of Economics and Statistics 48, 87--98.
1987
69. Hendry, D. F. (1987a) Econometric methodology: A personal perspective. In T. F. Bewley (ed.), Advances in Econometrics: Fifth World Congress, vol. 2, pp. 29--48. Cambridge: Cambridge University Press.
70. Hendry, D. F. (1987b) Econometrics in action. Empirica (Austrian Economic Papers) 14, 135--156.
71. Hendry, D. F. (1987c) PC-GIVE: An Interactive Menu-driven Econometric Modelling Program for IBM-compatible PC's, Version 4.2. Oxford: Institute of Economics and Statistics and Nuffield College, University of Oxford, January.
72. Hendry, D. F. (1987d) PC-GIVE: An Interactive Menu-driven Econometric Modelling Program for IBM-compatible PC's, Version 5.0. Oxford: Institute of Economics and Statistics and Nuffield College, University of Oxford, November.
73. Hendry, D. F., & A. J. Neale (1987) Monte Carlo experimentation using PC-NAIVE. In T. B. Fomby and G. F. Rhodes, Jr. (eds.), Advances in Econometrics: A Research Annual, vol. 6, pp. 91--125. Greenwich: JAI Press.
1988
74. Campos, J., N. R. Ericsson, & D. F. Hendry (1988) Comment on Telser. Journal of the American Statistical Association 83, 581.
75. Hendry, D. F. (1988a) Encompassing. National Institute Economic Review 3/88, 88--92.
76. Hendry, D. F. (1988b) The encompassing implications of feedback versus feedforward mechanisms in econometrics. Oxford Economic Papers 40, 132--149. 49
77. Hendry, D. F. (1988c) Some foreign observations on macro-economic model evaluation activities at INSEE--DP. In INSEE (ed.), Groupes d'Études Macroeconometriques Concertées: Document Complémentaire de Synthèse, pp. 71--106. Paris: INSEE.
78. Hendry, D. F., & A. J. Neale (1988) Interpreting long-run equilibrium solutions in conventional macro models: A comment. Economic Journal 98, 808--817.
79. Hendry, D. F., A. J. Neale, & F. Srba (1988) Econometric analysis of small linear systems using PC-FIML. Journal of Econometrics 38, 203--226.
1989
80. Hendry, D. F. (1989a) Comment. Econometric Reviews 8, 111--121.
81. Hendry, D. F. (1989b) PC-GIVE: An Interactive Econometric Modelling System, Version 6.0/6.01. Oxford: Institute of Economics and Statistics and Nuffield College, University of Oxford, January.
82. Hendry, D. F., & M. S. Morgan (1989) A re-analysis of confluence analysis. Oxford Economic Papers 41, 35--52.
83. Hendry, D. F., & J.-F. Richard (1989) Recent developments in the theory of encompassing. In B. Cornet and H. Tulkens (eds.), Contributions to Operations Research and Economics: The Twentieth Anniversary of CORE, pp. 393--440. Cambridge: MIT Press.
84. Hendry, D. F., A. Spanos, & N. R. Ericsson (1989) The contributions to econometrics in Trygve Haavelmo's The Probability Approach in Econometrics. Sosialø konomen 43, 12--17.
1990
85. Campos, J., N. R. Ericsson, & D. F. Hendry (1990) An analogue model of phaseaveraging procedures. Journal of Econometrics 43, 275--292.
86. Hendry, D. F., E. E. Leamer, & D. J. Poirier (1990) The ET dialogue: A conversation on econometric methodology. Econometric Theory 6, 171--261.
87. Hendry, D. F., & G. E. Mizon (1990) Procrustean econometrics: Or stretching and squeezing data. In C. W. J. Granger (ed.), Modelling Economic Series: Readings in Econometric Methodology, pp. 121--136. Oxford: Oxford University Press.
88. Hendry, D. F., J. N. J. Muellbauer, & A. Murphy (1990) The econometrics of DHSY. In J. D. Hey and D. Winch (eds.), A Century of Economics: 100 Years of the Royal Economic Society and the Economic Journal, pp. 298--334. Oxford: Basil Blackwell.
89. Hendry, D. F., A. J. Neale, & N. R. Ericsson (1990) PC-NAIVE: An Interactive Program for Monte Carlo Experimentation in Econometrics, Version 6.01. Oxford: Institute of Economics and Statistics and Nuffield College, University of Oxford.
1991
90. Hendry, D. F. (1991a) Comments: `The response of consumption to income: A crosscountry investigation' by John Y. Campbell and N. Gregory Mankiw. European Economic Review 35, 764--767.
91. Hendry, D. F. (1991b) Economic forecasting. In House of Commons (ed.), Memoranda on Official Economic Forecasting, Treasury and Civil Service Committee, Session 1990--
91. London: Her Majesty's Stationery Office. 5092. Hendry, D. F. (1991c) Using PC-NAIVE in teaching econometrics. Oxford Bulletin of Economics and Statistics 53, 199--223.
93. Hendry, D. F., & N. R. Ericsson (1991a) An econometric analysis of U.K. money demand in Monetary Trends in the United States and the United Kingdom by Milton Friedman and Anna J. Schwartz. American Economic Review 81, 8--38.
94. Hendry, D. F., & N. R. Ericsson (1991b) Modeling the demand for narrow money in the United Kingdom and the United States. European Economic Review 35, 833--881 (with discussion).
95. Hendry, D. F., & A. J. Neale (1991) A Monte Carlo study of the effects of structural breaks on tests for unit roots. In P. Hackl and A. H. Westlund (eds.), Economic Structural Change: Analysis and Forecasting, pp. 95--119. Berlin: Springer-Verlag.
1992
96. Baba, Y., D. F. Hendry, & R. M. Starr (1992) The demand for M1 in the U.S.A., 1960--1988. Review of Economic Studies 59, 25--61.
97. Banerjee, A., & D. F. Hendry (eds.) (1992a) Testing Integration and Cointegration. Special Issue, Oxford Bulletin of Economics and Statistics, 54, 3, August.
98. Banerjee, A., & D. F. Hendry (1992b) Testing integration and cointegration: An overview. Oxford Bulletin of Economics and Statistics 54, 225--255.
99. Doornik, J. A., & D. F. Hendry (1992) PcGive Version 7: An Interactive Econometric Modelling System. Oxford: Institute of Economics and Statistics, University of Oxford.
100. Favero, C., & D. F. Hendry (1992) Testing the Lucas critique: A review. Econometric Reviews 11, 265--306 (with discussion).
101. Hendry, D. F. (1992a) Assessing empirical evidence in macroeconometrics with an application to consumers' expenditure in France. In A. Vercelli and N. Dimitri (eds.), Macroeconomics: A Survey of Research Strategies, pp. 363--392. Oxford: Oxford University Press.
102. Hendry, D. F. (1992b) An econometric analysis of TV advertising expenditure in the United Kingdom. Journal of Policy Modeling 14, 281--311.
103. Hendry, D. F., & J.-F. Richard (1992) Likelihood evaluation for dynamic latent variables models. In H. M. Amman, D. A. Belsley, and L. F. Pau (eds.), Computational Economics and Econometrics, pp. 3--17. Dordrecht: Kluwer Academic Publishers.
1993
104. Banerjee, A., J. J. Dolado, J.W. Galbraith, & D. F. Hendry (1993) Co-integration, Error Correction, and the Econometric Analysis of Non-stationary Data. Oxford: Oxford University Press.
105. Clements, M. P., & D. F. Hendry (1993) On the limitations of comparing mean square forecast errors. Journal of Forecasting 12, 617--637 (with discussion).
106. Engle, R. F., & D. F. Hendry (1993) Testing super exogeneity and invariance in regression models. Journal of Econometrics 56, 119--139.
107. Hendry, D. F. (1993a) Econometrics: Alchemy or Science? Essays in Econometric Methodology. Oxford: Blackwell Publishers. 51
108. Hendry, D. F. (1993b) Introduction. In D. F. Hendry (ed.), Econometrics: Alchemy or Science? Essays in Econometric Methodology, pp. 1--7. Oxford: Blackwell Publishers.
109. Hendry, D. F. (1993c) Postscript: The econometrics of PC-GIVE. In D. F. Hendry (ed.), Econometrics: Alchemy or Science? Essays in Econometric Methodology, pp. 444--466. Oxford: Blackwell Publishers.
110. Hendry, D. F., & G. E. Mizon (1993) Evaluating dynamic econometric models by encompassing the VAR. In P. C. B. Phillips (ed.), Models, Methods, and Applications of Econometrics: Essays in Honor of A. R. Bergstrom, pp. 272--300. Cambridge: Basil Blackwell.
111. Hendry, D. F., & R. M. Starr (1993) The demand for M1 in the USA: A reply to James M. Boughton. Economic Journal 103, 1158--1169.
1994
112. Clements,M. P., & D. F. Hendry (1994) Towards a theory of economic forecasting. In C. P. Hargreaves (ed.), Nonstationary Time Series Analysis and Cointegration, pp. 9--52. Oxford: Oxford University Press.
113. Cook, S., & D. F. Hendry (1994) The theory of reduction in econometrics. In B. Hamminga and N. B. De Marchi (eds.), Idealization VI: Idealization in Economics, vol. 38 of Pozna'n Studies in the Philosophy of the Sciences and the Humanities, pp. 71--100. Amsterdam: Rodopi.
114. Doornik, J. A., & D. F. Hendry (1994a) PcFiml 8.0: Interactive Econometric Modelling of Dynamic Systems. London: International Thomson Publishing.
115. Doornik, J. A., & D. F. Hendry (1994b) PcGive 8.0: An Interactive Econometric Modelling System. London: International Thomson Publishing.
116. Engle, R. F., & D. F. Hendry (1994) Appendix: The reverse regression (Appendix to `Testing super exogeneity and invariance in regression models'). In N. R. Ericsson and J. S. Irons (eds.), Testing Exogeneity, pp. 110--116. Oxford: Oxford University Press.
117. Ericsson, N. R., D. F. Hendry, & H.-A. Tran (1994) Cointegration, seasonality, encompassing, and the demand for money in the United Kingdom. In C. P. Hargreaves (ed.), Nonstationary Time Series Analysis and Cointegration, pp. 179--224. Oxford: Oxford University Press.
118. Govaerts, B., D. F. Hendry, & J.-F. Richard (1994) Encompassing in stationary linear dynamic models. Journal of Econometrics 63, 245--270.
119. Hendry, D. F. (1994) HUS revisited. Oxford Review of Economic Policy 10, 86--106.
120. Hendry, D. F., & M. P. Clements (1994a) Can econometrics improve economic forecasting? Swiss Journal of Economics and Statistics 130, 267--298.
121. Hendry, D. F., & M. P. Clements (1994b) On a theory of intercept corrections in macroeconometric forecasting. In S. Holly (ed.), Money, Inflation and Employment: Essays in Honour of James Ball, pp. 160--182. Aldershot: Edward Elgar.
122. Hendry, D. F., & J. A. Doornik (1994) Modelling linear dynamic econometric systems. Scottish Journal of Political Economy 41, 1--33.
123. Hendry, D. F., & M. S. Morgan (1994) The ET interview: Professor H. O. A. Wold: 1908--1992. Econometric Theory 10, 419--433. 52
1995
124. Clements, M. P., & D. F. Hendry (1995a) Forecasting in cointegrated systems. Journal of Applied Econometrics 10, 127--146.
125. Clements, M. P., & D. F. Hendry (1995b) Macro-economic forecasting and modelling. Economic Journal 105, 1001--1013.
126. Clements, M. P., & D. F. Hendry (1995c) A reply to Armstrong and Fildes. Journal of Forecasting 14, 73--75.
127. Hendry, D. F. (1995a) Dynamic Econometrics. Oxford: Oxford University Press.
128. Hendry, D. F. (1995b) Econometrics and business cycle empirics. Economic Journal 105, 1622--1636.
129. Hendry, D. F. (1995c) Le rôle de l'économétrie dans l'économie scientifique. In A. d'Autume and J. Cartelier (eds.), L'Économie Devient-Elle Une Science Dure?, pp. 172--196. Paris: Economica.
130. Hendry, D. F. (1995d) On the interactions of unit roots and exogeneity. Econometric Reviews 14, 383--419.
131. Hendry, D. F., & J. A. Doornik (1995) A window on econometrics. Cyprus Journal of Economics 8, 77--104.
132. Hendry, D. F., & M. S. Morgan (eds.) (1995a) The Foundations of Econometric Analysis. Cambridge: Cambridge University Press.
133. Hendry, D. F., & M. S. Morgan (1995b) Introduction. In D. F. Hendry and M. S. Morgan (eds.), The Foundations of Econometric Analysis, pp. 1--82. Cambridge: Cambridge University Press.
1996
134. Banerjee, A., & D. F. Hendry (eds.) (1996) The Econometrics of Economic Policy. Special Issue, Oxford Bulletin of Economics and Statistics, 58, 4, November.
135. Banerjee, A., D. F. Hendry, & G. E. Mizon (1996) The econometric analysis of economic policy. Oxford Bulletin of Economics and Statistics 58, 573--600.
136. Campos, J., N. R. Ericsson, & D. F. Hendry (1996) Cointegration tests in the presence of structural breaks. Journal of Econometrics 70, 187--220.
137. Clements, M. P., & D. F. Hendry (1996a) Forecasting in macro-economics. In D. R. Cox, D. V. Hinkley, and O. E. Barndorff-Nielsen (eds.), Time Series Models: In Econometrics, Finance and Other Fields, pp. 101--141. London: Chapman and Hall.
138. Clements,M. P., & D. F. Hendry (1996b) Intercept corrections and structural change. Journal of Applied Econometrics 11, 475--494.
139. Clements,M. P., &D. F. Hendry (1996c) Multi-step estimation for forecasting. Oxford Bulletin of Economics and Statistics 58, 657--684.
140. Doornik, J. A., & D. F. Hendry (1996) GiveWin: An Interface to Empirical Modelling, Version 1.0. London: International Thomson Business Press.
141. Emerson, R. A., & D. F. Hendry (1996) An evaluation of forecasting using leading indicators. Journal of Forecasting 15, 271--291.
142. Florens, J.-P., D. F. Hendry, & J.-F. Richard (1996) Encompassing and specificity. Econometric Theory 12, 620--656. 53
143. Hendry, D. F. (1996a) On the constancy of time-series econometric equations. Economic and Social Review 27, 401--422.
144. Hendry, D. F. (1996b) Typologies of linear dynamic systems and models. Journal of Statistical Planning and Inference 49, 177--201.
145. Hendry, D. F., & J. A. Doornik (1996) Empirical Econometric Modelling Using PcGive 9.0 for Windows. London: International Thomson Business Press.
146. Hendry, D. F., & M. S. Morgan (1996) Obituary: Jan Tinbergen, 1903--94. Journal of the Royal Statistical Society, Series A 159, 614--616. 1997
147. Banerjee, A., & D. F. Hendry (eds.) (1997) The Econometrics of Economic Policy. Oxford: Blackwell Publishers.
148. Barrow, L., J. Campos, N. R. Ericsson, D. F. Hendry, H.-A. Tran, & W. Veloce (1997) Cointegration. In D. Glasner (ed.), Business Cycles and Depressions: An Encyclopedia, pp. 101--106. New York: Garland Publishing.
149. Campos, J., N. R. Ericsson, & D. F. Hendry (1997) Phase averaging. In D. Glasner (ed.), Business Cycles and Depressions: An Encyclopedia, pp. 525--527. New York: Garland Publishing.
150. Clements, M. P., & D. F. Hendry (1997) An empirical study of seasonal unit roots in forecasting. International Journal of Forecasting 13, 341--355.
151. Desai, M. J., D. F. Hendry, & G. E. Mizon (1997) John Denis Sargan. Economic Journal 107, 1121--1125.
152. Doornik, J. A., & D. F. Hendry (1997) Modelling Dynamic Systems Using PcFiml 9.0 for Windows. London: International Thomson Business Press.
153. Ericsson, N. R., & D. F. Hendry (1997) Lucas critique. In D. Glasner (ed.), Business Cycles and Depressions: An Encyclopedia, pp. 410--413. New York: Garland Publishing.
154. Hendry, D. F. (1997a) Book review of Doing Economic Research: Essays on the Applied Methodology of Economics by Thomas Mayer. Economic Journal 107, 845--847.
155. Hendry, D. F. (1997b) Cointegration analysis: An international enterprise. In H. Jeppesen and E. Starup-Jensen (eds.), University of Copenhagen: Centre of Excellence, pp. 190--208. Copenhagen: University of Copenhagen.
156. Hendry, D. F. (1997c) The econometrics of macroeconomic forecasting. Economic Journal 107, 1330--1357.
157. Hendry, D. F. (1997d) On congruent econometric relations: A comment. Carnegie- Rochester Conference Series on Public Policy 47, 163--190.
158. Hendry, D. F. (1997e) The role of econometrics in scientific economics. InA. d'Autume and J. Cartelier (eds.), Is Economics Becoming a Hard Science?, pp. 165--186. Cheltenham: Edward Elgar.
159. Hendry, D. F., & J. A. Doornik (1997) The implications for econometric modelling of forecast failure. Scottish Journal of Political Economy 44, 437--461.
160. Hendry, D. F., & N. Shephard (eds.) (1997a) Cointegration and Dynamics in Economics. Special Issue, Journal of Econometrics, 80, 2, October. 54
161. Hendry, D. F., & N. Shephard (1997b) Editors introduction. Journal of Econometrics 80, 195--197.
1998
162. Clements, M. P., & D. F. Hendry (1998a) Forecasting economic processes. International Journal of Forecasting 14, 111--131 (with discussion).
163. Clements, M. P., & D. F. Hendry (1998b) Forecasting Economic Time Series. Cambridge: Cambridge University Press.
164. Doornik, J. A., D. F. Hendry, & B. Nielsen (1998) Inference in cointegrating models: UK M1 revisited. Journal of Economic Surveys 12, 533--572.
165. Ericsson, N. R., D. F. Hendry, & G. E. Mizon (1998) Exogeneity, cointegration, and economic policy analysis. Journal of Business and Economic Statistics 16, 370--387.
166. Ericsson, N. R., D. F. Hendry, & K. M. Prestwich (1998a) The demand for broad money in the United Kingdom, 1878--1993. Scandinavian Journal of Economics 100, 289--324 (with discussion).
167. Ericsson, N. R., D. F. Hendry, & K. M. Prestwich (1998b) Friedman and Schwartz (1982) revisited: Assessing annual and phase-average models of money demand in the United Kingdom. Empirical Economics 23, 401--415.
168. Hendry, D. F., & G. E. Mizon (1998) Exogeneity, causality, and co-breaking in economic policy analysis of a small econometric model of money in the UK. Empirical Economics 23, 267--294.
169. Hendry, D. F., & N. Shephard (1998) The Econometrics Journal of the Royal Economic Society: Foreward. Econometrics Journal 1, i--ii.
1999
170. Clements, M. P., & D. F. Hendry (1999a) Forecasting Non-stationary Economic Time Series. Cambridge: MIT Press.
171. Clements, M. P., & D. F. Hendry (1999b) On winning forecasting competitions in economics. Spanish Economic Review 1, 123--160.
172. Ericsson, N. R., & D. F. Hendry (1999) Encompassing and rational expectations: How sequential corroboration can imply refutation. Empirical Economics 24, 1--21.
173. Hendry, D. F. (1999) An econometric analysis of US food expenditure, 1931--1989. In J. R. Magnus and M. S. Morgan (eds.), Methodology and Tacit Knowledge: Two Experiments in Econometrics, pp. 341--361. Chichester: John Wiley and Sons.
174. Hendry, D. F., & J. A. Doornik (1999) The impact of computational tools on time-series econometrics. In T. Coppock (ed.), Information Technology and Scholarship: Applications in the Humanities and Social Sciences, pp. 257--269. Oxford: Oxford University Press.
175. Hendry, D. F., & H.-M. Krolzig (1999) Improving on `Data mining reconsidered' by K. D. Hoover and S. J. Perez. Econometrics Journal 2, 202--219.
176. Hendry, D. F., & G. E. Mizon (1999) The pervasiveness of Granger causality in econometrics. In R. F. Engle and H. White (eds.), Cointegration, Causality, and Forecasting: A Festschrift in Honour of Clive W. J. Granger, pp. 102--134. Oxford: Oxford University Press. 55
2000
177. Barnett, W. A., D. F. Hendry, S. Hylleberg, T. Teräsvirta, D. Tjøstheim, & A. Würtz (2000a) Introduction and overview. In W. A. Barnett, D. F. Hendry, S. Hylleberg, T. Teräsvirta, D. Tjøstheim, and A.Würtz (eds.), Nonlinear Econometric Modeling in Time Series: Proceedings of the Eleventh International Symposium in Economic Theory, pp. 1--8. Cambridge: Cambridge University Press.
178. Barnett, W. A., D. F. Hendry, S. Hylleberg, T. Teräsvirta, D. Tjøstheim, & A. Würtz (eds.) (2000b) Nonlinear Econometric Modeling in Time Series: Proceedings of the Eleventh International Symposium in Economic Theory. Cambridge: Cambridge University Press.
179. Beyer, A., J. A. Doornik, & D. F. Hendry (2000) Reconstructing aggregate Euro-zone data. Journal of Common Market Studies 38, 613--624.
180. Hendry, D. F. (2000a) Does money determine UK inflation over the long run? In R. E. Backhouse and A. Salanti (eds.), Macroeconomics and the Real World, vol. 1, pp. 85--114. Oxford: Oxford University Press.
181. Hendry, D. F. (2000b) Econometrics: Alchemy or Science? Essays in Econometric Methodology. Oxford: Oxford University Press, New Edition.
182. Hendry, D. F. (2000c) Epilogue: The success of general-to-specific model selection. In D. F. Hendry (ed.), Econometrics: Alchemy or Science? Essays in Econometric Methodology, New Edition, pp. 467--490. Oxford: Oxford University Press.
183. Hendry, D. F. (2000d) On dectectable and non-detectable structural change. Structural Change and Economic Dynamics 11, 45--65.
184. Hendry, D. F., & M. P. Clements (2000) Economic forecasting in the face of structural breaks. In S. Holly and M. Weale (eds.), Econometric Modelling: Techniques and Applications, pp. 3--37. Cambridge: Cambridge University Press.
185. Hendry, D. F., & K. Juselius (2000) Explaining cointegration analysis: Part I. Energy Journal 21, 1--42.
186. Hendry, D. F., & G. E. Mizon (2000a) The influence of A.W. Phillips on econometrics. In R. Leeson (ed.), A. W. H. Phillips: Collected Works in Contemporary Perspective, pp. 353--364. Cambridge: Cambridge University Press.
187. Hendry, D. F., & G. E. Mizon (2000b) On selecting policy analysis models by forecast accuracy. In A. B. Atkinson, H. Glennerster, and N. H. Stern (eds.), Putting Economics to Work: Volume in Honour of Michio Morishima, pp. 71--119. London: STICERD, London School of Economics.
188. Hendry, D. F., & G. E. Mizon (2000c) Reformulating empirical macroeconometric modelling. Oxford Review of Economic Policy 16, 138--159.
189. Hendry, D. F., & R. Williams (2000) Distinguished fellow of the Economic Society of Australia, 1999: Adrian R. Pagan. Economic Record 76, 113--115.
2001
190. Beyer, A., J. A. Doornik, & D. F. Hendry (2001) Constructing historical Euro-zone data. Economic Journal 111, F102--F121.
191. Clements, M. P., & D. F. Hendry (2001a) Explaining the results of the M3 forecasting competition. International Journal of Forecasting 17, 550--554. 56
192. Clements, M. P., & D. F. Hendry (2001b) Forecasting with difference-stationary and trend-stationary models. Econometrics Journal 4, S1--S19.
193. Clements, M. P., & D. F. Hendry (2001c) An historical perspective on forecast errors. National Institute Economic Review 2001, 100--112.
194. Doornik, J. A., & D. F. Hendry (2001a) Econometric Modelling Using PcGive 10 . Vol. 3, London: Timberlake Consultants Press (with Manuel Arellano, Stephen Bond, H. Peter Boswijk, and Marius Ooms).
195. Doornik, J. A., & D. F. Hendry (2001b) GiveWin Version 2: An Interface to Empirical Modelling. London: Timberlake Consultants Press.
196. Doornik, J. A., & D. F. Hendry (2001c) Interactive Monte Carlo Experimentation in Econometrics Using PcNaive 2 . London: Timberlake Consultants Press.
197. Doornik, J. A., & D. F. Hendry (2001d) Modelling Dynamic Systems Using PcGive 10 . Vol. 2, London: Timberlake Consultants Press.
198. Hendry, D. F. (2001a) Achievements and challenges in econometric methodology. Journal of Econometrics 100, 7--10.
199. Hendry, D. F. (2001b) How economists forecast. In D. F. Hendry and N. R. Ericsson (eds.), Understanding Economic Forecasts, pp. 15--41. Cambridge: MIT Press.
200. Hendry, D. F. (2001c) Modelling UK inflation, 1875--1991. Journal of Applied Econometrics 16, 255--275.
201. Hendry, D. F., & J. A. Doornik (2001) Empirical Econometric Modelling Using PcGive 10 . Vol. 1, London: Timberlake Consultants Press.
202. Hendry, D. F., & N. R. Ericsson (2001a) Editors' introduction. In D. F. Hendry and N. R. Ericsson (eds.), Understanding Economic Forecasts, pp. 1--14. Cambridge: MIT Press.
203. Hendry, D. F., & N. R. Ericsson (2001b) Epilogue. In D. F. Hendry and N. R. Ericsson (eds.), Understanding Economic Forecasts, pp. 185--191. Cambridge: MIT Press.
204. Hendry, D. F., & N. R. Ericsson (eds.) (2001c) Understanding Economic Forecasts. Cambridge: MIT Press.
205. Hendry, D. F., & K. Juselius (2001) Explaining cointegration analysis: Part II. Energy Journal 22, 75--120.
206. Hendry, D. F., & H.-M. Krolzig (2001) Automatic Econometric Model Selection Using PcGets 1.0 . London: Timberlake Consultants Press.
207. Hendry, D. F., & M. H. Pesaran (2001a) Introduction: A special issue in memory of John Denis Sargan: Studies in empirical macroeconometrics. Journal of Applied Econometrics 16, 197--202.
208. Hendry, D. F., & M. H. Pesaran (eds.) (2001b) Special Issue in Memory of John Denis Sargan 1924--1996: Studies in Empirical Macroeconometrics. Special Issue, Journal of Applied Econometrics, 16, 3, May--June.
209. Krolzig, H.-M., & D. F. Hendry (2001) Computer automation of general-to-specific model selection procedures. Journal of Economic Dynamics and Control 25, 831--866. 57
2002
210. Clements, M. P., & D. F. Hendry (eds.) (2002a) A Companion to Economic Forecasting. Oxford: Blackwell Publishers.
211. Clements, M. P., & D. F. Hendry (2002b) Explaining forecast failure in macroeconomics. In M. P. Clements and D. F. Hendry (eds.), A Companion to Economic Forecasting, pp. 539--571. Oxford: Blackwell Publishers.
212. Clements, M. P., & D. F. Hendry (2002c) Modelling methodology and forecast failure. Econometrics Journal 5, 319--344.
213. Clements, M. P., & D. F. Hendry (2002d) An overview of economic forecasting. In M. P. Clements and D. F. Hendry (eds.), A Companion to Economic Forecasting, pp. 1--18. Oxford: Blackwell Publishers.
214. Doornik, J. A., D. F. Hendry, & N. Shephard (2002) Computationally intensive econometrics using a distributed matrix-programming language. Philosophical Transactions of the Royal Society, London, Series A 360, 1245--1266.
215. Hendry, D. F. (2002a) Applied econometrics without sinning. Journal of Economic Surveys 16, 591--604.
216. Hendry, D. F. (2002b) Forecast failure, expectations formation and the Lucas Critique. Annales D'Économie et de Statistique 2002, 21--40.
2003
217. Campos, J., D. F. Hendry, & H.-M. Krolzig (2003) Consistent model selection by an automatic Gets approach. Oxford Bulletin of Economics and Statistics 65, 803--819.
218. Doornik, J. A., & D. F. Hendry (2003a) PcGive. In C. G. Renfro (ed.), ``A Compendium of Existing Econometric Software Packages'', Journal of Economic and Social Measurement, 26, forthcoming.
219. Doornik, J. A., & D. F. Hendry (2003b) PcNaive. In C. G. Renfro (ed.), ``A Compendium of Existing Econometric Software Packages'', Journal of Economic and Social Measurement, 26, forthcoming.
220. Haldrup, N., D. F. Hendry, & H. K. van Dijk (2003a) Guest editors' introduction: Model selection and evaluation in econometrics. Oxford Bulletin of Economics and Statistics 65, 681--688.
221. Haldrup, N., D. F. Hendry, & H. K. van Dijk (eds.) (2003b) Model Selection and Evaluation. Special Issue, Oxford Bulletin of Economics and Statistics, 65, supplement.
222. Hendry, D. F. (2003a) Book review of Causality in Macroeconomics by Kevin D. Hoover. Economica 70, 375--377.
223. Hendry, D. F. (2003b) Forecasting pitfalls. Bulletin of E.U. and U.S. Inflation and Macroeconomic Analysis 2003, 65--82.
224. Hendry, D. F. (2003c) J. Denis Sargan and the origins of LSE econometric methodology. Econometric Theory 19, 457--480.
225. Hendry, D. F., & M. P. Clements (2003) Economic forecasting: Some lessons from recent research. Economic Modelling 20, 301--329.
226. Hendry, D. F., & H.-M. Krolzig (2003a) New developments in automatic general-tospecific modeling. In B. P. Stigum (ed.), Econometrics and the Philosophy of Economics: 58 Theory-Data Confrontations in Economics, pp. 379--419. Princeton: Princeton University Press.
227. Hendry, D. F., & H.-M. Krolzig (2003b) PcGets. In C. G. Renfro (ed.), ``A Compendium of Existing Econometric Software Packages'', Journal of Economic and Social Measurement, 26, forthcoming.
2004
228. Campos, J., N. R. Ericsson, & D. F. Hendry (eds.) (2004) Readings on General-to- Specific Modeling. Cheltenham: Edward Elgar, forthcoming.
229. Hendry, D. F. (2004) The Nobel memorial prize for Clive W. J. Granger. Scandinavian Journal of Economics 106, forthcoming.
230. Hendry, D. F., & M. P. Clements (2004) Pooling of forecasts. Econometrics Journal 7, forthcoming.
231. Hendry, D. F., & H.-M. Krolzig (2004) Sub-sample model selection procedures in general-to-specific modelling. In R. Becker and S. Hurn (eds.), Contemporary Issues in Economics and Econometrics: Theory and Application, pp. 53--75. Cheltenham: Edward Elgar.
Footnotes
1. Forthcoming in Econometric Theory. The interviewer is a senior supervisory economist in the Division of International Finance, Board of Governors of the Federal Reserve System, Washington, D.C. 20551 U.S.A., and the interviewee is an ESRC Professorial Research Fellow and the head of the Economics Department at the University of Oxford. They may be reached on the Internet at [email protected] and [email protected] respectively. The views in this interview are solely the responsibility of the author and the interviewee and should not be interpreted as reflecting the views of the Board of Governors of the Federal Reserve System or of any other person associated with the Federal Reserve System. We are grateful to Julia Campos, Jonathan Halket, Jaime Marquez, Kristian Rogers, and especially Peter Phillips for helpful comments and discussion, and to Margaret Gray and Hayden Smith for assistance in transcription. Empirical results and graphics were obtained using PcGive Professional Version 10: see [195] and [201]. This discussion paper is available from the author and at www.federalreserve.gov/pubs/ifdp/2004/811/default.htm on the WorldWide Web. Return to text
This version is optimized for use by screen readers. A printable pdf version is available.