
Board of Governors of the Federal Reserve System
International Finance Discussion Papers
Number 928, April 2008 --- Screen Reader
Version*
Interpreting Long-Horizon Estimates in Predictive Regressions
NOTE: International Finance Discussion Papers are preliminary materials circulated to stimulate discussion and critical comment. References in publications to International Finance Discussion Papers (other than an acknowledgment that the writer has had access to unpublished material) should be cleared with the author or authors. Recent IFDPs are available on the Web at http://www.federalreserve.gov/pubs/ifdp/. This paper can be downloaded without charge from the Social Science Research Network electronic library at http://www.ssrn.com/.
Abstract:
This paper analyzes the asymptotic properties of long-horizon estimators under both the null hypothesis and an alternative of predictability. Asymptotically, under the null of no predictability, the long-run estimator is an increasing deterministic function of the short-run estimate and the forecasting horizon. Under the alternative of predictability, the conditional distribution of the long-run estimator, given the short-run estimate, is no longer degenerate and the expected pattern of coefficient estimates across horizons differs from that under the null. Importantly, however, under the alternative, highly endogenous regressors, such as the dividend-price ratio, tend to deviate much less than exogenous regressors, such as the short interest rate, from the pattern expected under the null, making it more difficult to distinguish between the null and the alternative.
Keywords: Predictive regressions, long-horizon regressions, stock return predictability
JEL classification: C22, G1
1 Introduction
Long-run regressions were made popular by influential articles such as Fama and French (1988) and Campbell and Shiller (1988). When attempting to predict stock returns over longer horizons, often covering several years, rather than on a month-to-month basis, the evidence in favour of predictability generally appears much stronger. For instance, the estimated regression coefficients tend to increase almost linearly with the forecasting horizon. However, in a recent paper, Boudoukh, Richardson, and Whitelaw (2006) (BRW hereafter) show that this pattern is exactly the one to be expected in the absence of predictability. Although it is well known that the estimated slope coefficient will increase with the horizon when there is predictability, BRW appear to be the first ones to observe that the same is also true under the null hypothesis. They interpret their findings as a strong critique of the widespread belief that long-horizon regressions provide solid evidence of predictability (e.g. Cochrane, 2001).1
The aim of the current paper is to understand in more detail the properties of long-horizon estimates under an alternative of predictability. The practical purpose of this is to establish the pattern of estimated coefficients that may be expected both under the null and the alternative, across different forecasting horizons. Although the generally increasing pattern of coefficients in long-horizon regressions is well established, the exact asymptotic sampling properties of long-run estimators under an alternative of predictability are not previously well understood.
I derive the asymptotic distribution of the long-run OLS estimator, with overlapping observations, under the assumptions that the true data generating process is given by the standard linear predictive regression model and that the regressors are highly persistent variables. Under the alternative of predictability, the sampling properties of the long-run estimator are fundamentally different than under the null hypothesis, and the limiting distribution is highly non-standard. From a practical perspective, this result is of individual interest. It shows that confidence intervals for long-run estimates, based on inverting a test statistic that is valid under the null hypothesis, will not be correctly sized under the alternative, given the non-standard distribution.
The theoretical results allow for an exact characterization of the conditional distribution of the long-run estimator, given the short-run estimate. Under the null hypothesis, the long-run estimator is, asymptotically, completely determined once the short-run estimate is given. Importantly, however, this is not true under the alternative of predictability. In fact, the degree to which the long-run estimate can vary independently of the short-run estimate is determined by the degree of endogeneity of the regressors.2 Long-run estimates for highly endogenous regressors, such as the dividend-price ratio, are also almost completely pinned down by the short-run estimate under the alternative hypothesis. On the other hand, for near exogenous regressors such as the short interest rate, the long-run estimator has a relatively large independent component given the short-run estimate.3 Given the short-run estimate, under the alternative of predictability, the implications are that: (i) the highly endogenous regressor will have a more predictable pattern for long-horizons than the near exogenous one, and (ii) this pattern will closely resemble that under the null hypothesis.
These results provide an alternative interpretation of the empirical findings in BRW. BRW interpret the findings that the dividend-price ratio has a pattern very similar to that predicted under the null, whereas the short interest rate does not, as evidence against the predictive ability of the dividend-price ratio and in favor of the predictive ability of the short rate. Given the results in this paper, however, their findings could merely reflect the fact that there is more independent variation in the long-run estimates for fairly exogenous regressors.
2 Model and assumptions
Let ![]() denote the one period stock return
from
denote the one period stock return
from ![]() to
to ![]() and let
and let
![]() be the corresponding
be the corresponding ![]() period return from
period return from
![]() to
to ![]() . The standard
long-run forecasting regression is specified as follows,
. The standard
long-run forecasting regression is specified as follows,
| (1) |
where long-run future returns are regressed onto a one period
predictor, ![]() . Let the OLS estimator of
. Let the OLS estimator of
![]() in equation (1), using
overlapping observations, be denoted by
in equation (1), using
overlapping observations, be denoted by
![]() . The primary focus of
interest will be the properties of
. The primary focus of
interest will be the properties of
![]() for different values of
for different values of
![]() , and in particular the relationship between
, and in particular the relationship between
![]() and
and
![]() for
for ![]() .
.
In order to formally analyze the sampling properties of
![]() , the data generating process
for
, the data generating process
for ![]() and
and ![]() need to be
explicitly specified. Following Nelson and Kim (1993) and Campbell
(2001), I assume that
need to be
explicitly specified. Following Nelson and Kim (1993) and Campbell
(2001), I assume that ![]() and
and ![]() satisfy:
satisfy:
| (2) | ||
| (3) |
Thus, the one-period regression in equation (1) coincides with
the true data generating process and for any horizon, ![]() will be the optimal forecaster of returns given current
information at time
will be the optimal forecaster of returns given current
information at time ![]() .4 To capture the near
persistence found in most forecasting variables, such as interest
rates or valuation ratios, it is further assumed that the
auto-regressive root,
.4 To capture the near
persistence found in most forecasting variables, such as interest
rates or valuation ratios, it is further assumed that the
auto-regressive root, ![]() , is close to one in a
local sense. In particular, it is assumed that
, is close to one in a
local sense. In particular, it is assumed that
![]() , where
, where ![]() is some
finite parameter and
is some
finite parameter and ![]() is the sample size with
is the sample size with
![]() . This captures the near unit-root,
or highly persistent, behavior of many predictor variables, but is
less restrictive than a pure unit-root assumption. The near
unit-root construction, where the autoregressive root drifts closer
to unity as the sample size increases, is used as a tool to enable
an asymptotic analysis where the persistence in the data remains
large relative to the sample size, also as the sample size
increases to infinity. That is, if
. This captures the near unit-root,
or highly persistent, behavior of many predictor variables, but is
less restrictive than a pure unit-root assumption. The near
unit-root construction, where the autoregressive root drifts closer
to unity as the sample size increases, is used as a tool to enable
an asymptotic analysis where the persistence in the data remains
large relative to the sample size, also as the sample size
increases to infinity. That is, if ![]() is treated
as fixed and strictly less than unity, then as the sample size
grows, the process
is treated
as fixed and strictly less than unity, then as the sample size
grows, the process ![]() will behave as a
strictly stationary process asymptotically and the standard first
order asymptotic results will not provide a good guide to the
actual small sample properties of the model. For
will behave as a
strictly stationary process asymptotically and the standard first
order asymptotic results will not provide a good guide to the
actual small sample properties of the model. For ![]() , the usual unit-root asymptotics apply to the model,
but this is clearly a restrictive assumption for most potential
predictor variables. Instead, by letting
, the usual unit-root asymptotics apply to the model,
but this is clearly a restrictive assumption for most potential
predictor variables. Instead, by letting
![]() , the effects from the high
persistence in the regressor will appear also in the asymptotic
results, but without imposing the strict assumption of a unit root.
Cavanagh et al. (1995), Lanne (2002), Valkanov (2003), Torous et
al. (2004), and Campbell and Yogo (2006) all use similar models,
with a near unit-root construct, to analyze the predictability of
stock returns.
, the effects from the high
persistence in the regressor will appear also in the asymptotic
results, but without imposing the strict assumption of a unit root.
Cavanagh et al. (1995), Lanne (2002), Valkanov (2003), Torous et
al. (2004), and Campbell and Yogo (2006) all use similar models,
with a near unit-root construct, to analyze the predictability of
stock returns.
The error processes are assumed to satisfy a martingale
difference sequence with finite fourth order moments. That is, let
![]() and
and
![]() be the filtration generated by
be the filtration generated by ![]() . Then
. Then
![]() ,
,
![]() ,
,
![]() ,
and
,
and
![]()
By standard arguments,
![]() where
where
![]() denotes a two dimensional Brownian motion and
denotes a two dimensional Brownian motion and
![]() denotes weak convergence of the
associated probability measures. Further, as
denotes weak convergence of the
associated probability measures. Further, as
![]() ,
,
![]() and an analogous result holds for the demeaned variables
and an analogous result holds for the demeaned variables
![]() , with the
limiting process
, with the
limiting process ![]() replaced by
replaced by
![]() (Phillips, 1987, 1988). Let
(Phillips, 1987, 1988). Let
![]() and
and
![]() be the standardized
Brownian motions, with unit variance and correlation
be the standardized
Brownian motions, with unit variance and correlation
![]() , that correspond to
, that correspond to
![]() and
and
![]() , respectively. By
the properties of conditional normal distributions,
, respectively. By
the properties of conditional normal distributions,
![]() , where
, where
![]() is a Brownian motion with unit
variance and orthogonal to
is a Brownian motion with unit
variance and orthogonal to ![]() . Further, let
. Further, let
![]() be the standardized version of
be the standardized version of
![]() .
.
To ease the notation, define
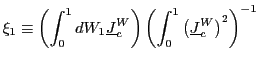 and
and 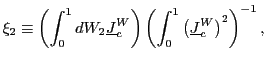
|
(4) |
and write
![]() where
where
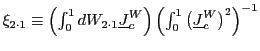 .
.
3 Asymptotic distributions under the null and the alternative
3.1 The limiting distribution of
The foundations for the subsequent analysis is given in the
following theorem, which outlines the asymptotic properties of
![]() under both the null
hypothesis of no predictability and the alternative of
predictability.
under both the null
hypothesis of no predictability and the alternative of
predictability.
1. Under the null hypothesis that ![]() ,
as
,
as
![]() ,
,
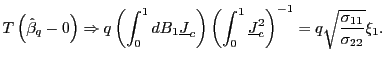
|
(5) |
2. Under the alternative hypothesis that
![]() , as
, as
![]() ,
,
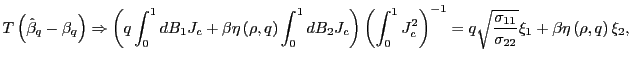
|
(6) |
where
![]() with
with
![]() , and
, and
![]() . For
. For ![]() , it holds exactly that
, it holds exactly that
![]() , and
, and
![]() .
.
Remark 1.1 Note that the asymptotic
distribution of
![]() is identical under the null
and the alternative. That is, for any value of
is identical under the null
and the alternative. That is, for any value of ![]() ,
,
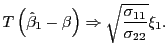
|
(7) |
This follows both from standard asymptotic theory applied to the
one-period OLS estimator, but also from plugging in ![]() in equations (5) and
(6).
in equations (5) and
(6).
Remark 1.2 Under the null hypothesis,
the asymptotic distribution of
![]() is identical to that of
is identical to that of
![]() , apart from a scaling factor.
This result follows from the persistent nature of the regressors;
the intuition behind it is discussed in more detail in Hjalmarsson
(2007). For the purposes of this paper, the implications are that
the short-run and long-run estimators are perfectly correlated
asymptotically. In fact, from equation (5) it follows
that,
, apart from a scaling factor.
This result follows from the persistent nature of the regressors;
the intuition behind it is discussed in more detail in Hjalmarsson
(2007). For the purposes of this paper, the implications are that
the short-run and long-run estimators are perfectly correlated
asymptotically. In fact, from equation (5) it follows
that,
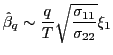 and
and 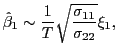
|
(8) |
where ![]() is used to denote an approximate
distributional equivalence. Asymptotically, therefore, the
conditional distribution of
is used to denote an approximate
distributional equivalence. Asymptotically, therefore, the
conditional distribution of
![]() given
given
![]() satisfies
satisfies
![]() . Given
. Given
![]() , the estimator
, the estimator
![]() is thus asymptotically a
deterministic linear function of the forecasting horizon. This is
similar to the result in BRW, which is derived under the assumption
of a fixed autoregressive root
is thus asymptotically a
deterministic linear function of the forecasting horizon. This is
similar to the result in BRW, which is derived under the assumption
of a fixed autoregressive root ![]() that is strictly
less than unity.
that is strictly
less than unity.
Remark 1.3 Under the alternative
hypothesis, the long-run estimator converges to the parameter
![]() ,
which for
,
which for
![]() implies that
implies that
![]() . That
is, the 'true' parameter value,
. That
is, the 'true' parameter value, ![]() , as well as
the estimator
, as well as
the estimator
![]() , grows approximately
one-to-one with the forecasting horizon.
, grows approximately
one-to-one with the forecasting horizon.
Remark 1.4 Under the alternative
hypothesis of predictability, the distribution of
![]() is quite different than
under the null hypothesis. To understand the intuition behind this
result, note first that the true model is given by equations
(2) and (3). The long-run
regression equation is thus a fitted regression, rather than the
data generating process. As shown in Appendix A, the long-run
returns
is quite different than
under the null hypothesis. To understand the intuition behind this
result, note first that the true model is given by equations
(2) and (3). The long-run
regression equation is thus a fitted regression, rather than the
data generating process. As shown in Appendix A, the long-run
returns
![]() actually satisfy the
following relationship when ignoring the constant, derived from
equations (2) and
(3):
actually satisfy the
following relationship when ignoring the constant, derived from
equations (2) and
(3):
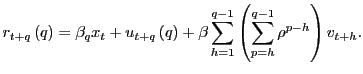
|
(9) |
There are now two error terms, the usual
![]() plus the additional
term
plus the additional
term
![]() , which stems from the fact that at time
, which stems from the fact that at time ![]() there
is uncertainty regarding the path of
there
is uncertainty regarding the path of ![]() for
for
![]() . That is, since the true model
is given by equations (2) and (3), there is
uncertainty regarding both the future realizations of the returns
as well as of the predictor variable when forming
. That is, since the true model
is given by equations (2) and (3), there is
uncertainty regarding both the future realizations of the returns
as well as of the predictor variable when forming ![]() period ahead forecasts. The first error term,
period ahead forecasts. The first error term,
![]() , corresponds to the
asymptotic
, corresponds to the
asymptotic ![]() term in the limiting
distribution and the second error term,
term in the limiting
distribution and the second error term,
![]() , corresponds to the
, corresponds to the ![]() term. For large
term. For large
![]() , the second error term in (9) will clearly
dominate the asymptotic properties since it is of an order of
magnitude larger than the first one, a result reflected in the
weights on
, the second error term in (9) will clearly
dominate the asymptotic properties since it is of an order of
magnitude larger than the first one, a result reflected in the
weights on ![]() and
and ![]() in
equation (6). However,
the weight on
in
equation (6). However,
the weight on ![]() in (6) also depends on
in (6) also depends on
![]() . Thus for
. Thus for ![]() close to
zero,
close to
zero, ![]() will still be important for
relatively large
will still be important for
relatively large ![]() .
.
Remark 1.5 Following the analysis in
BRW, the results are derived under the assumption that ![]() is fixed as
is fixed as
![]() . However, it is easy to
show that the results remain similar if
. However, it is easy to
show that the results remain similar if ![]() increases
with the sample size
increases
with the sample size ![]() , but at a slower pace, such
that
, but at a slower pace, such
that
![]() , as
, as
![]() . Under this assumption,
it follows easily under the null hypothesis that
. Under this assumption,
it follows easily under the null hypothesis that
![]() . Under the alternative hypothesis,
. Under the alternative hypothesis,
![]() , where the first term in (6) now disappears
asymptotically. As discussed in the previous remark, however, the
first term in (6) will
still be important for relatively large
, where the first term in (6) now disappears
asymptotically. As discussed in the previous remark, however, the
first term in (6) will
still be important for relatively large ![]() , provided
, provided
![]() is small; this can be achieved also
for asymptotically large
is small; this can be achieved also
for asymptotically large ![]() by treating
by treating ![]() as small in a local sense. All the results in this
paper therefore hold also under the general assumption that
as small in a local sense. All the results in this
paper therefore hold also under the general assumption that
![]() grows with the sample size but at a slower
pace. As shown in Hjalmarsson (2007), asymptotic results derived
under this assumption seem to provide good approximations of the
finite sample properties of
grows with the sample size but at a slower
pace. As shown in Hjalmarsson (2007), asymptotic results derived
under this assumption seem to provide good approximations of the
finite sample properties of
![]() for forecasting horizons
spanning upwards of
for forecasting horizons
spanning upwards of ![]() to
to ![]() percent of the sample size. For completeness, however, Appendix
B presents the
results for the case where
percent of the sample size. For completeness, however, Appendix
B presents the
results for the case where ![]() is asymptotically
large relative to
is asymptotically
large relative to ![]() , in a manner such that
, in a manner such that
![]() , as
, as
![]() ; i.e. when
; i.e. when ![]() grows at the same pace as the sample size.
grows at the same pace as the sample size.
3.2 Finite sample adjustments
In the analysis of BRW, it follows that under the null
hypothesis,
![]() (see equation 6 in BRW), rather than
(see equation 6 in BRW), rather than
![]() , as
found here, where
, as
found here, where
![]() is defined in
Theorem 1.5
However, under the current assumption of
is defined in
Theorem 1.5
However, under the current assumption of
![]() , it follows that
, it follows that
![]() . Thus, for
the local-to-unity specification of
. Thus, for
the local-to-unity specification of ![]() that is
used here,
that is
used here,
![]() and
and ![]() are asymptotically indistinguishable, and replacing
are asymptotically indistinguishable, and replacing ![]() by
by
![]() does not affect the
asymptotic arguments but merely provides a finite sample
adjustment. As the analysis of BRW implies, along with simulation
results that are not reported here, the rate of growth of
does not affect the
asymptotic arguments but merely provides a finite sample
adjustment. As the analysis of BRW implies, along with simulation
results that are not reported here, the rate of growth of
![]() under the null hypothesis
seems to correspond best to
under the null hypothesis
seems to correspond best to
![]() , rather than
, rather than
![]() , in finite samples.
, in finite samples.
Likewise, in Part 2 of Theorem 1, the factor
![]() in front of
in front of ![]() can
be replaced by
can
be replaced by
![]() , since this
multiplier arises in an identical manner to the one in Part 1. That
is, under the alternative hypothesis, one can write,
, since this
multiplier arises in an identical manner to the one in Part 1. That
is, under the alternative hypothesis, one can write,
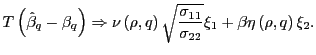
|
(10) |
In the analysis in the next section, I use these finite sample
adjusted results. This does not qualitatively change any of the
results, and for ![]() it holds exactly that
it holds exactly that
![]() .
.
4 The relationship between the long-run and the short-run
The results in the previous section provide the necessary
building blocks for understanding the properties of, and
relationship between, the long- and short-run estimators both under
the null hypothesis and under the alternative of predictability. In
this section, I consider the implications of these results through
an informal analysis. For ease of notation, it is assumed that
![]() .
.
Under both the null and the alternative, the short-run estimator
satisfies,
![]() ,
and one can write informally,
,
and one can write informally,
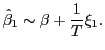 |
(11) |
Similarly, under the null with ![]() , the
long-run estimator satisfies
, the
long-run estimator satisfies
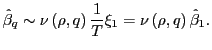
|
(12) |
Thus, as noted above, under the null-hypothesis,
![]() and
and
![]() are perfectly asymptotically
correlated.
are perfectly asymptotically
correlated.
Under the alternative of predictability,
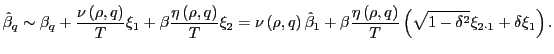
|
(13) |
The distribution of
![]() is now a function of
is now a function of
![]() , as well as an additional
term. Note, however, that given
, as well as an additional
term. Note, however, that given
![]() , the random variable
, the random variable
![]() is fixed, and the only independent
information in
is fixed, and the only independent
information in
![]() , given
, given
![]() , derives from the
, derives from the
![]() variable.
variable.
To better understand the properties of
![]() under the alternative
hypothesis, it is useful to consider the two special cases of
under the alternative
hypothesis, it is useful to consider the two special cases of
![]() and
and ![]() close
to
close
to ![]() . The case of
. The case of ![]() close
to
close
to ![]() will be symmetrical to that of
will be symmetrical to that of ![]() close to
close to ![]() , but the latter is much
more common in stock return applications. To more easily understand
the variation in
, but the latter is much
more common in stock return applications. To more easily understand
the variation in
![]() , Figure 1 shows the density
plots for
, Figure 1 shows the density
plots for ![]() , for different values of
, for different values of
![]() , and
, and ![]() for
the case of
for
the case of ![]()
![]() ; the density of
; the density of
![]() is identical to that of
is identical to that of
![]() .
.
As is seen in Figure 1, ![]() , and hence
, and hence
![]() , is almost always negative, a
fact which will be used in the discussion below. To see this
analytically, consider the case when
, is almost always negative, a
fact which will be used in the discussion below. To see this
analytically, consider the case when ![]() and note
that one can then write
and note
that one can then write
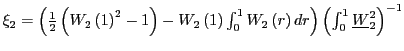 . Since
. Since
![]() is distributed as
a
is distributed as
a
![]() variable, there is an
approximately two-thirds probability that the first term in the
numerator will be negative. The second term will also tend to be
negative, since the correlation between
variable, there is an
approximately two-thirds probability that the first term in the
numerator will be negative. The second term will also tend to be
negative, since the correlation between
![]() and
and
![]() is positive. Further,
when
is positive. Further,
when
![]() is large, the
denominator will also be large, skewing the distribution further to
the left. The ratio will therefore be negative most of the time and
have a negative mean. A similar argument can be made for
is large, the
denominator will also be large, skewing the distribution further to
the left. The ratio will therefore be negative most of the time and
have a negative mean. A similar argument can be made for
![]() .
.
4.1 The case of 
When ![]() ,
,
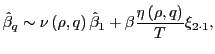
|
(14) |
where the second term is stochastically independent of
![]() . Since
. Since
![]() , as is
apparent from Figure 1 and the discussion above,
, as is
apparent from Figure 1 and the discussion above,
![]() will tend to be below the
curve
will tend to be below the
curve
![]() ; the
5th, 50th and 95th percentile of
; the
5th, 50th and 95th percentile of
![]() , for
, for ![]() , are
given by
, are
given by ![]() ,
, ![]() , and
, and
![]() , respectively. To further understand
the relationship between
, respectively. To further understand
the relationship between
![]() and
and
![]() in this case, consider a
simple example. Suppose
in this case, consider a
simple example. Suppose ![]()
![]() ,
, ![]() , and
, and
![]() , which is a typical
estimate of the short-run slope parameter in a regression with
monthly standardized data such that
, which is a typical
estimate of the short-run slope parameter in a regression with
monthly standardized data such that
![]() (e.g. Campbell and
Yogo, 2006). If the true value of
(e.g. Campbell and
Yogo, 2006). If the true value of ![]() is equal
to zero, then asymptotically,
is equal
to zero, then asymptotically,
![]() .
On the other hand, if
.
On the other hand, if
![]() , so that the short-run estimate
is equal to the true value, then conditional on
, so that the short-run estimate
is equal to the true value, then conditional on
![]() , the 5th, 50th and 95th
percentiles of
, the 5th, 50th and 95th
percentiles of
![]() are equal to
are equal to ![]() ,
, ![]() , and
, and ![]() ,
respectively, based on equation (14) and the
percentiles of
,
respectively, based on equation (14) and the
percentiles of
![]() .
.
4.2 The case of
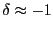
As
![]()
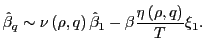
|
(15) |
For ![]() close to minus one,
close to minus one, ![]() is almost always positive, and
is almost always positive, and
![]() will tend to be smaller than
will tend to be smaller than
![]() .
Note also, that once
.
Note also, that once
![]() is determined, there is no
additional variance left in the estimator
is determined, there is no
additional variance left in the estimator
![]() . That is, since
. That is, since
![]() , for a
given
, for a
given
![]() and
and ![]() ,
,
![]() is pinned down, and hence
is pinned down, and hence
![]() as well.
as well.
Consider a similar thought experiment to that above. Again,
suppose ![]()
![]() ,
, ![]() , and
, and
![]() . If
. If ![]() , then
, then
![]() , which implies
that
, which implies
that
![]() and
and
![]() Now,
if
Now,
if
![]() , then
, then
![]() implies
that
implies
that
![]() , and
, and
![]() . If
. If
![]() , then
, then ![]() , and
, and
![]() To the extent that
To the extent that
![]() is greater than or equal to zero, a
large negative correlation
is greater than or equal to zero, a
large negative correlation ![]() severely
limits the range of probable values that
severely
limits the range of probable values that
![]() can attain once
can attain once
![]() is fixed. (The 5th, 50th and
95th percentile of
is fixed. (The 5th, 50th and
95th percentile of ![]() for
for
![]() and
and ![]() , are given
by
, are given
by ![]() ,
, ![]() , and
, and
![]() , respectively.)
, respectively.)
4.3 Implied long-horizon estimates
Thus, when the predictor is exogenous, so that ![]() , somewhat substantial deviations in
, somewhat substantial deviations in
![]() from that predicted under
the null are possible and to some extent expected. When the
regressors are highly endogenous, and
from that predicted under
the null are possible and to some extent expected. When the
regressors are highly endogenous, and ![]() is
close to minus one, the range of possibilities also under the
alternative is more restricted and large deviations from that
predicted under the null are not likely.6
is
close to minus one, the range of possibilities also under the
alternative is more restricted and large deviations from that
predicted under the null are not likely.6
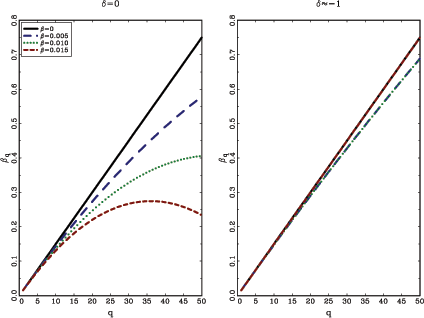
Figure 2 further illustrates this last point. Using equations
(14) and (15), it plots
potential outcomes of
![]() , given
, given
![]() , for four different
values of the true
, for four different
values of the true
![]() . The same
parameters as in the examples above are used, with
. The same
parameters as in the examples above are used, with ![]() and
and ![]() . For
. For
![]() , once
, once
![]() and
and ![]() are
fixed, the outcome of
are
fixed, the outcome of
![]() is fully determined and
there is thus no range of possibilities. For
is fully determined and
there is thus no range of possibilities. For ![]() , there is independent variation left in
, there is independent variation left in
![]() , given
, given
![]() and
and ![]() , in
the form of
, in
the form of
![]() . The graphs for
. The graphs for ![]() show the lower bound of
show the lower bound of
![]() , based on the 5th percentile
of
, based on the 5th percentile
of
![]() . The upper bound, based on the
95th percentile of
. The upper bound, based on the
95th percentile of
![]() is virtually identical to
is virtually identical to
![]() ,
since the 95th percentile of
,
since the 95th percentile of
![]() is almost equal to zero.
is almost equal to zero.
The graphs clearly demonstrate the limited range of plausible
outcomes for
![]() given a typical one-period
estimate of
given a typical one-period
estimate of
![]() , when the regressor is
highly endogenous. Indeed, when the estimate
, when the regressor is
highly endogenous. Indeed, when the estimate
![]() is in fact identical to the
true
is in fact identical to the
true ![]() , the outcome is observationally
equivalent to that under the null hypothesis. When the predictor is
exogenous, the range of outcomes is obviously much larger, and
there is a fair chance of detecting patterns that deviate
substantially from those expected under the null.
, the outcome is observationally
equivalent to that under the null hypothesis. When the predictor is
exogenous, the range of outcomes is obviously much larger, and
there is a fair chance of detecting patterns that deviate
substantially from those expected under the null.
In their empirical analysis, BRW show that the coefficients for the dividend-price ratio, which is highly endogenous, are nearly linear in the forecasting horizon whereas those for the short interest rate, which is nearly exogenous, grow at a much slower pace. In light of Figure 2, these findings are suggestive of predictive ability in the short interest rate, but can say little or nothing regarding the predictive ability of the dividend-price ratio.7
5 Summary and conclusion
To sum up, under the null hypothesis, the long-run estimator is asymptotically completely determined by the one-period estimate and the persistence in the regressor. Under the alternative hypothesis, the degree to which the long-run estimates can vary independently of the one period ones is determined by the degree of endogeneity in the regressors. Nearly exogenous predictors, such as the short interest rate, allow for more independent variation than highly endogenous predictors such as the earnings-price ratio. Unfortunately, long-run estimates therefore provide additional information in cases where short-run inference is relatively straightforward but adds little in the case of endogenous regressors where short-run inference is fraught with difficulties (i.e. Stambaugh, 1999, and Campbell and Yogo, 2006).
Finally, it is worth pointing out, that the asymptotic framework
used in this paper delivers an asymptotically degenerate
distribution of
![]() given
given
![]() , under the null hypothesis.
This prevents the construction of formal, and asymptotically
meaningful, tests on the joint distribution of
, under the null hypothesis.
This prevents the construction of formal, and asymptotically
meaningful, tests on the joint distribution of
![]() and
and
![]() under the null. BRW devise a
joint test of
under the null. BRW devise a
joint test of
![]() under
the assumption of a fixed
under
the assumption of a fixed ![]() strictly less
than one. However, under these assumptions, the standard asymptotic
distribution of the test is not likely to be well satisfied due to
the standard complications in inference with endogenous and
persistent variables. Monte Carlo simulations not reported in this
paper confirm that for a large negative
strictly less
than one. However, under these assumptions, the standard asymptotic
distribution of the test is not likely to be well satisfied due to
the standard complications in inference with endogenous and
persistent variables. Monte Carlo simulations not reported in this
paper confirm that for a large negative ![]() , the
BRW test will tend to severely over reject. It is also interesting
to note that the Wald statistic of BRW is scaled by
, the
BRW test will tend to severely over reject. It is also interesting
to note that the Wald statistic of BRW is scaled by
![]() , which diverges
to infinity as
, which diverges
to infinity as
![]() . The degenerate case
encountered in the current asymptotics thus follows as a limiting
case in their analysis. The construction of an asymptotically valid
and correctly sized joint test of
. The degenerate case
encountered in the current asymptotics thus follows as a limiting
case in their analysis. The construction of an asymptotically valid
and correctly sized joint test of ![]() and
and
![]() for
for ![]() close to
unity is thus left unresolved.
close to
unity is thus left unresolved.
Appendix A Proof of Theorem 1
Proof. For ease of notation the case with no intercept is treated. The results generalize immediately to regressions with fitted intercepts by replacing all variables by their demeaned versions. Part 1 is proved in Hjalmarsson (2007), but is repeated here for completeness.
1. Under the null hypothesis,
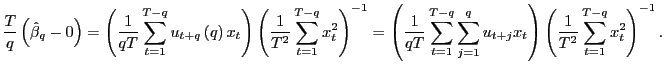
By standard arguments,
![]() as
as
![]() , since for any
, since for any
![]() ,
,
![]() . Therefore,
. Therefore,
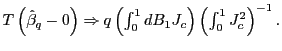
2. By summing up on both sides in equation (2),
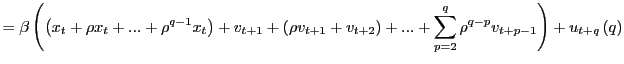
|
||
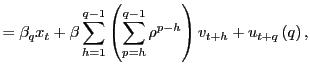
|
where
![]() . Thus,
. Thus,
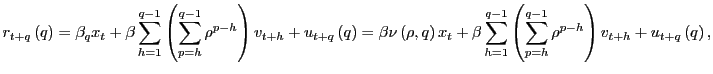
and
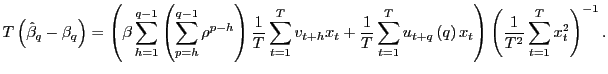
Observe that
![]() for all
for all ![]() . Let
. Let
![]() and it follows that, as
and it follows that, as
![]() ,
,
![]() . By the results in Part 1.,
. By the results in Part 1.,
![]() , as
, as
![]() , and the desired result
follows. Note that,
, and the desired result
follows. Note that,
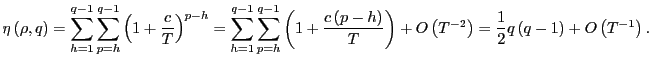
Appendix B Results for the case when
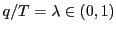 as
as
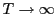
Some of the literature on long-horizon regressions has analyzed
the case where ![]() is asymptotically large relative
to
is asymptotically large relative
to ![]() , such that
, such that
![]() , as
, as
![]() . In the context of this
study, such asymptotics are less useful because the long-run OLS
estimator will not converge to a properly defined long-run
coefficient. Since the current focus is on the distribution of the
long-run estimator conditional on the short-run estimator, it makes
more sense to consider the case when the long-run estimator does
converge. Nevertheless, it is still interesting to see if any of
the results derived in the main text continue to hold under this
assumption.
. In the context of this
study, such asymptotics are less useful because the long-run OLS
estimator will not converge to a properly defined long-run
coefficient. Since the current focus is on the distribution of the
long-run estimator conditional on the short-run estimator, it makes
more sense to consider the case when the long-run estimator does
converge. Nevertheless, it is still interesting to see if any of
the results derived in the main text continue to hold under this
assumption.
Again treating the case without an intercept, Valkanov (2003)
shows that under the null hypothesis, with
![]() as
as
![]()
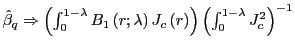 , where
, where
![]() . Under the alternative,
. Under the alternative,
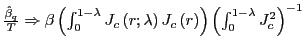 , where
, where
![]() Thus,
Thus,
![]() no longer converges to a
constant and it is therefore not surprising that the strong
connection between the asymptotic distributions for the short-run
and long-run estimators is no longer apparent. Indeed, given the
highly non-standard limiting distributions, it is difficult to get
a grasp of the properties of
no longer converges to a
constant and it is therefore not surprising that the strong
connection between the asymptotic distributions for the short-run
and long-run estimators is no longer apparent. Indeed, given the
highly non-standard limiting distributions, it is difficult to get
a grasp of the properties of
![]() . A very rough approximation,
however, can provide some guidelines.
. A very rough approximation,
however, can provide some guidelines.
Note that
![]() and
and
![]() . Under the null hypothesis, it follows that
. Under the null hypothesis, it follows that
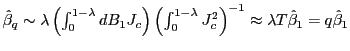 , and under the alternative hypothesis,
, and under the alternative hypothesis,
![]() .
Thus, also for
.
Thus, also for
![]() , it would appear that
, it would appear that
![]() will grow with the
forecasting horizon. Under the null hypothesis, there is still some
indication of the relationship between
will grow with the
forecasting horizon. Under the null hypothesis, there is still some
indication of the relationship between
![]() and
and
![]() , but under the alternative
hypothesis the more subtle connections between the short-run and
the long-run estimator are no longer evident, as might be expected
given the lack of a consistent long-run estimator.
, but under the alternative
hypothesis the more subtle connections between the short-run and
the long-run estimator are no longer evident, as might be expected
given the lack of a consistent long-run estimator.
Appendix C Asymptotic properties of R2
Let ![]() be the coefficient of
determination from the
be the coefficient of
determination from the ![]() period regression in
equation (1). Using the
same arguments as in the proof of Theorem 1, it follows that
under the null hypothesis,
period regression in
equation (1). Using the
same arguments as in the proof of Theorem 1, it follows that
under the null hypothesis,
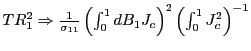 . Similarly,
. Similarly,
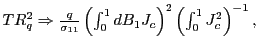 using the result that
using the result that
![]() , which is derived in Hjalmarsson (2007). Thus, asymptotically,
under the null hypothesis,
, which is derived in Hjalmarsson (2007). Thus, asymptotically,
under the null hypothesis,
![]() .
.
Because ![]() is a near-integrated regressor, it
follows easily that
is a near-integrated regressor, it
follows easily that
![]() as
as
![]() . This is not very useful
from a practical perspective and it is more interesting to analyze
the properties under a local alternative,
. This is not very useful
from a practical perspective and it is more interesting to analyze
the properties under a local alternative,
![]() . Under this alternative,
using similar arguments as before,
. Under this alternative,
using similar arguments as before,
![]() and
and
![]() Standardizing so that
Standardizing so that
![]() , and using the approximation
that
, and using the approximation
that
![]() , it
follows that
, it
follows that
![]() and
and
![]() .
.
References
Boudoukh J., M. Richardson, and R.F. Whitelaw, 2006. The myth of long-horizon predictability, Review of Financial Studies, forthcoming.
Campbell, J.Y., 2001. Why long horizons? A study of power against persistent alternatives, Journal of Empirical Finance 8, 459-491.
Campbell, J.Y., and R. Shiller, 1988. Stock prices, earnings, and expected dividends, Journal of Finance 43, 661-676.
Campbell, J.Y., and M. Yogo, 2006. Efficient Tests of Stock Return Predictability, Journal of Financial Economics 81, 27-60.
Cavanagh, C., G. Elliot, and J. Stock, 1995. Inference in models with nearly integrated regressors, Econometric Theory 11, 1131-1147.
Cochrane, J., 2001. Asset Pricing, Princeton, Princeton University Press.
Fama, E.F., and K.R. French, 1988. Dividend yields and expected stock returns, Journal of Financial Economics 22, 3-25.
Goetzman W.N., and P. Jorion, 1993. Testing the Predictive Power of Dividend Yields, Journal of Finance 48, 663-679.
Hansen, L.P., and R.J. Hodrick, 1980. Forward Exchange Rates as Optimal Predictors of Future Spot Rates: An Econometric Analysis, Journal of Political Economy 88, 829-853.
Hjalmarsson, E., 2007. Inference in Long-Horizon Regressions, Working Paper, Federal Reserve Board.
Hodrick, R.J., 1992. Dividend Yields and Expected Stock Returns: Alternative Procedures for Inference and Measurement, Review of Financial Studies 5, 357-386.
Lanne, M., 2002. Testing the Predictability of Stock Returns, Review of Economics and Statistics 84, 407-415.
Kirby, C., 1997. Measuring the Predictable Variation in Stock and Bond Returns, Review of Financial Studies 10, 579-630.
Nelson, C.R., and M.J. Kim, 1993. Predictable Stock Returns: The Role of Small Sample Bias, Journal of Finance 48, 641-661.
Phillips, P.C.B, 1987. Towards a Unified Asymptotic Theory of Autoregression, Biometrika 74, 535-547.
Phillips, P.C.B, 1988. Regression Theory for Near-Integrated Time Series, Econometrica 56, 1021-1043.
Richardson, M., 1993. Temporary Components of Stock Prices: A Skeptic's View, Journal of Business and Economics Statistics 11, 199-207.
Richardson, M., and T. Smith, 1991. Tests of Financial Models in the Presence of Overlapping Observations, Review of Financial Studies 4, 227-254.
Richardson, M., and T. Smith, 1994. A Unified Approach to Testing for Serial Correlation in Stock Returns, Journal of Business 67, 371-399.
Richardson, M., and J.H. Stock, 1989. Drawing Inferences from Statistics Based on Multiyear Asset Returns, Journal of Financial Economics 25, 323-348.
Stambaugh, R., 1999. Predictive regressions, Journal of Financial Economics 54, 375-421.
Torous, W., R. Valkanov, and S. Yan, 2004. On Predicting Stock Returns with Nearly Integrated Explanatory Variables, Journal of Business 77, 937-966.
Valkanov, R., 2003. Long-horizon regressions: theoretical results and applications, Journal of Financial Economics 68, 201-232.
Figure 1: Density plots of
![]() and
and ![]() for c = 0.
for c = 0.
The graphs show the densities for the
Brownian functionals ![]() , for different values
of
, for different values
of ![]() , and
, and ![]() ,
obtained by kernel estimation of simulated data using
,
obtained by kernel estimation of simulated data using ![]() repetitions and a sample size of
repetitions and a sample size of ![]() in each repetition. The shape of the density of
in each repetition. The shape of the density of
![]() is identical to that of
is identical to that of
![]()
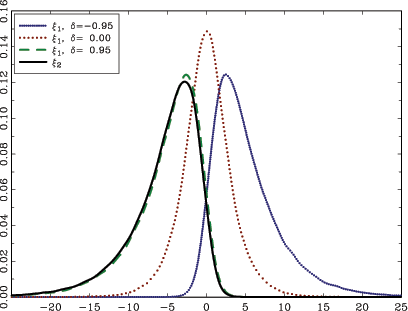
Figure 2: Possible outcomes
of
![]() given
given
![]() and
and ![]() .
.
The graphs show potential outcomes of
![]() , given that
, given that
![]() , for
, for
![]() . The left hand side
panel shows the case for exogenous regressors with
. The left hand side
panel shows the case for exogenous regressors with ![]() and the right hand side shows the case with highly
endogenous regressors. The plots are formed using equations (14)
and (15), letting
and the right hand side shows the case with highly
endogenous regressors. The plots are formed using equations (14)
and (15), letting ![]() and
and ![]() . For
. For
![]() , once
, once
![]() and
and ![]() are
fixed, the outcome of
are
fixed, the outcome of
![]() is fully determined and
there is thus no range of possibilities. The graphs for
is fully determined and
there is thus no range of possibilities. The graphs for ![]() show the lower bound of
show the lower bound of
![]() , based on the 5th
percentile of
, based on the 5th
percentile of
![]() . The upper bound, based on the
95th percentile of
. The upper bound, based on the
95th percentile of
![]() , is virtually identical to
, is virtually identical to
![]() ;
i.e. the line for
;
i.e. the line for ![]() .
.
Footnotes
* This paper has benefitted from comments by Lennart Hjalmarsson, Randi Hjalmarsson and Jonathan Wright, as well as an anonymous referee. Tel.: +1-202-452-2426; fax: +1-202-263-4850; email: [email protected]. The views in this paper are solely the responsibility of the author and should not be interpreted as reflecting the views of the Board of Governors of the Federal Reserve System or of any other person associated with the Federal Reserve System. Return to text
1. Earlier studies discussing other inferential issues in long-horizon regressions include Hansen and Hodrick (1980), Richardson and Stock (1989), Richardson and Smith (1991, 1994), Hodrick (1992), Goetzman and Jorion (1993), Nelson and Kim (1993), Richardson (1993), Kirby (1997), and Valkanov (2003). Return to text
2. A predictive regressor is generally referred to as endogenous if the innovations to the returns are contemporaneously correlated with the innovations to the regressor. When the regressor is strictly stationary, such endogeneity has no impact on the properties of the estimator, but when the regressor is persistent in some manner, the properties of the estimator will be affected (e.g. Stambaugh, 1999). Return to text
3. The contemporaneous correlation between
the innovations to the returns and the innovations to the regressor
determines the endogeneity of a predictive regressor (see previous
footnote). Campbell and Yogo (2006) show that for valuation ratios,
such as the dividend-price ratio, this correlation is large and
often greater than ![]() in absolute magnitude. For
interest rate variables, however, the correlation is close to zero
and, from the perspective of a predictive regression, these
variables are thus nearly exogenous. Return to text
in absolute magnitude. For
interest rate variables, however, the correlation is close to zero
and, from the perspective of a predictive regression, these
variables are thus nearly exogenous. Return to text
4. There are two primary reasons why the analysis of the long-run regression in equation (1) is of interest under the assumption that the true model is given by the short-run equation (2). First, there is the long standing popular belief that predictability is more evident in the long run, and that there may therefore be power gains to analyzing the long-horizon regression, even if the short-run specification given by equation (2) is correct; for instance, Campbell (2001) analyzes the power of long-run tests under the same specification that is used in this paper. Alternatively, since there appears to be no other data generating processes that are widely used for modeling return predictability, in the short- or long-run, the results derived under the data generating process given by equations (2) and (3) can be viewed as a benchmark against which to compare results from other specifications. Return to text
5. I use the '![]() ' sign
here because in the framework of BRW, the asymptotic distribution
of
' sign
here because in the framework of BRW, the asymptotic distribution
of
![]() is not entirely pinned down
by
is not entirely pinned down
by
![]() . Return to text
. Return to text
6. Apart from increasing slope
coefficients, increasing ![]() have also been used as
an argument in favor of long-run predictability. In Appendix
C, I first
replicate BRW's finding that
have also been used as
an argument in favor of long-run predictability. In Appendix
C, I first
replicate BRW's finding that ![]() increases with
the forecast horizon under the null hypothesis. In addition, I show
that the asymptotic properties of
increases with
the forecast horizon under the null hypothesis. In addition, I show
that the asymptotic properties of ![]() under
the alternative hypothesis are not a function of the degree of
endogeneity of the regressor and that
under
the alternative hypothesis are not a function of the degree of
endogeneity of the regressor and that ![]() still
increases almost linearly with the forecasting horizon. Thus,
unlike for
still
increases almost linearly with the forecasting horizon. Thus,
unlike for
![]() , there is no systematic
difference in the asymptotic properties of
, there is no systematic
difference in the asymptotic properties of ![]() for
exogenous and endogenous regressors under the alternative
hypothesis. Return to text
for
exogenous and endogenous regressors under the alternative
hypothesis. Return to text
7. The results in this paper are all based
on the assumption that the regressor follows a near unit-root
process. For a fixed autoregressive root ![]() strictly less than unity, the effects arising from endogeneity
would not appear in the asymptotic analysis, although one could
perhaps obtain some similar results using the finite sample bias
derived in Stambaugh (1999). In practice, of course, the near
unit-root construction is designed to asymptotically capture the
finite sample bias that arises from highly persistent and
endogenous regressors, which are not necessarily unit-root
processes. For regressors with very low persistence, i.e.
strictly less than unity, the effects arising from endogeneity
would not appear in the asymptotic analysis, although one could
perhaps obtain some similar results using the finite sample bias
derived in Stambaugh (1999). In practice, of course, the near
unit-root construction is designed to asymptotically capture the
finite sample bias that arises from highly persistent and
endogenous regressors, which are not necessarily unit-root
processes. For regressors with very low persistence, i.e.
![]() , there will be no effects from
endogeneity and there should thus be no systematic difference
between endogenous and exogenous regressors in the behavior of
either the short-run or the long-run estimators. However, most
relevant predictors of stock returns tend to be highly
persistent. Return to text
, there will be no effects from
endogeneity and there should thus be no systematic difference
between endogenous and exogenous regressors in the behavior of
either the short-run or the long-run estimators. However, most
relevant predictors of stock returns tend to be highly
persistent. Return to text
This version is optimized for use by screen readers. Descriptions for all mathematical expressions are provided in LaTex format. A printable pdf version is available. Return to text