
A Reliable and Computationally Efficient Algorithm for Imposing the Saddle Point Property in Dynamic Models
Keywords: Saddle point property, linear rational expections models
Abstract:
1 Introduction and Summary
Economists at the Board have an operational need for tools that are useful for building, estimating and simulating moderate to large scale rational expectations models. This context dictates a need for careful attention to computational efficiency and numerical stability of the algorithms.
These algorithms have proved very durable and useful for staff at the central bank. Many economists at the Federal Reserve Board have used the algorithms in their daily work and their research.2With the exception of researchers at other European central banks[Zagaglia, 2002], few economists outside the US central bank seem to know about the method. This paper attempts to make the method and approach more widely available by describing the underlying theory along with a number of improvements on the original algorithm.3
The most distinctive features of this approach are:
- its algorithm for computing the minimal dimension state space transition matrix
- its use of bi-orthogonality to characterize the asymptotic constraints that guarantee stability (See Section 3.1.2).
- It's reliance on QR Decomposition and the real Schur Decomposition for speed and accuracy.
This unique combination of features makes the algorithm especially effective for large models. See [Anderson, 2006] for a systematic comparison of this algorithm with the alternatives procedures.
The remainder of the paper is organized as follows. Section 3 states the saddle point problem. Section 3 describes the algorithms for solving the homogeneous and inhomogeneous versions of the problem and describes several implementations. Section 4 shows how to compute matrices often found useful for manipulating rational expectations model solutions: the observable structure(Section 4.1) and stochastic transition matrices(Section 4.2). The Appendices contain proofs for the linear algebra underlying the algorithm and the solution of a simple example model.
2 Saddle Point Problem Statement
Consider linear models of the form:
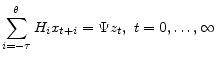 |
(1) |
with initial conditions, if any, given by constraints of the form |
|
| (2) | |
where both |
|
| (3) | |
and
Section 3 describes computationally efficient algorithms for determining the existence and uniqueness of solutions to this problem.
3 The Algorithms
The uniqueness of solutions to system 1 requires that any transition matrix characterizing the dynamics of the linear system have an appropriate number of explosive and stable eigenvalues[Blanchard & Kahn, 1980], and that a certain set of asymptotic linear constraints are linearly independent of explicit and certain other auxiliary initial conditions[Anderson & Moore, 1985].
The solution methodology entails
- Manipulating the left hand side of equation 1 to obtain a state space transition matrix,
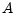 , along with a set of auxiliary initial conditions,
, along with a set of auxiliary initial conditions, 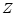 for the homogeneous solution.
for the homogeneous solution.
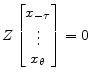 and
and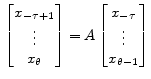
(4)
See Section 3.1.1. - Computing the eigenvalues and vectors spanning the left invariant space associated with large eigenvalues. See Section 3.1.2.
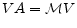
(5)
with the eigenvalues of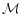 all greater than one in absolute value.
all greater than one in absolute value. - Assembling asymptotic constraints,
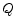 , (See Section 3.1.2.) by combining the:
, (See Section 3.1.2.) by combining the:
- auxiliary initial conditions identified in the computation of the transition matrix and
- the invariant space vectors
(6) - Investigating the rank of the linear space spanned by these asymptotic constraints and, when a unique solution exists,
Figure 1 presents a flowchart of the algorithm.

3.1 Homogeneous Solution
Suppose, for now, that ![]() :4
:4
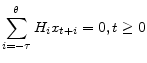 |
(8) |
| (9) |
The homogeneous specification 8 is not restrictive. Since the procedure can handle inhomogeneous versions of equation 1 by recasting the problem in terms of deviations from a steady state value. However, the next section provides a more intuitive, flexible and computationally efficient alternative for computing inhomogeneous solutions.5
3.1.1 State Space Transition Matrix and Auxiliary Initial Conditions: 
This section describes how to determine a first-order state space representation of the equation system 8. The method is an extension of the shuffling algorithm developed in[Luenberger, 1978,Luenberger, 1977]. If
![]() is non-singular, we can immediately obtain
is non-singular, we can immediately obtain
![]() in terms of
in terms of
![]()
| (10) |
However, the natural specification of many economic models has singular
This, first, algorithm applies full rank linear transformations to equations from the original linear system in order to express
![]() in terms of
in terms of
![]() . It produces an unconstrained, typically explosive, autoregressive representation for the evolution of the components of the state space vectors and a set of
vectors that provide important auxiliary initial conditions.
. It produces an unconstrained, typically explosive, autoregressive representation for the evolution of the components of the state space vectors and a set of
vectors that provide important auxiliary initial conditions.
Section A.1 presents a proof that repeating this process of annihilating and regrouping rows ultimately produces an
![]() with
with
![]() non-singular. The proof identifies a benign rank condition that guarantees that the algorithm will successfully compute the unconstrained autoregression and the
auxiliary initial conditions.
non-singular. The proof identifies a benign rank condition that guarantees that the algorithm will successfully compute the unconstrained autoregression and the
auxiliary initial conditions.
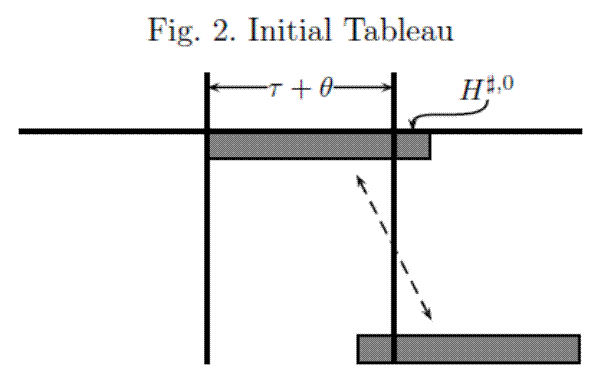
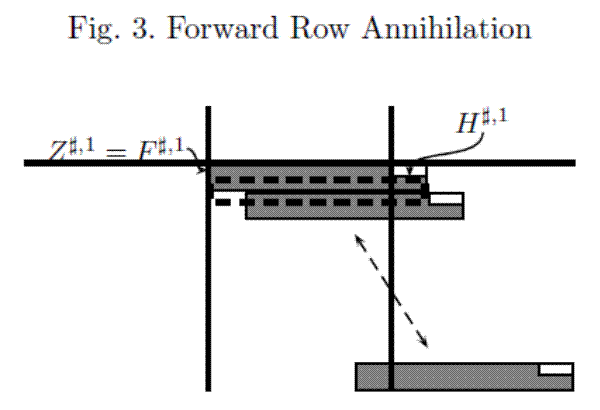
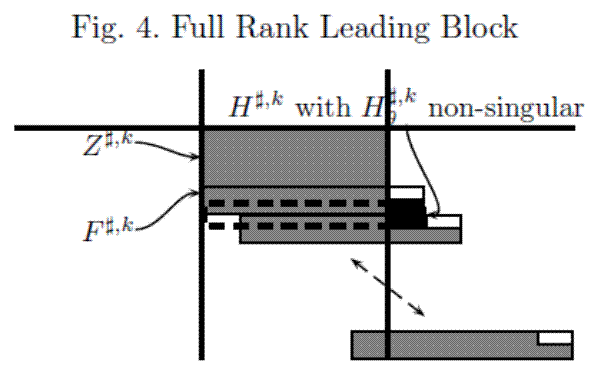
Figures 2-4 provide a graphical characterization of the linear algebraic transformations characterizing the algorithm. Figure 2 presents a graphical characterization of the relevant set of linear constraints for
![]() . The figure represents the regions where the coefficients are potentially non-zero as shaded gray. If
. The figure represents the regions where the coefficients are potentially non-zero as shaded gray. If
![]() is singular, one can find a linear combination of its rows which preserves the rank of
is singular, one can find a linear combination of its rows which preserves the rank of
![]() but which annihilates one or more of its rows.
but which annihilates one or more of its rows.
Consequently, one can pre-multiply the matrices presented in Figure 2 by a unitary matrix to get the distribution of zeros displayed in Figure 3. Since the matrices repeat over time, one need only investigate the rank of the square
matrix
![]() .
.
![]() . With some of the rows of
. With some of the rows of
![]() all zeros. One can regroup the rows in the new tableau to get
all zeros. One can regroup the rows in the new tableau to get
![]() . By construction, the rank of
. By construction, the rank of
![]() can be no less than the rank of
can be no less than the rank of
![]() .
.
Note that changing the order of the equations in
![]() will not affect the rank of
will not affect the rank of
![]() or the space spanned by the nonzero rows that will enter
or the space spanned by the nonzero rows that will enter
![]() . Since
. Since
![]() is not full rank, a subset of the rows of
is not full rank, a subset of the rows of
![]() will span the same space as
will span the same space as
![]() . The other rows in
. The other rows in
![]() will come from linear combinations of the original system of equations in effect "shifted forward" in time.
will come from linear combinations of the original system of equations in effect "shifted forward" in time.
One can think of the "Full Rank Leading Block" matrix as the result of premultiplications of the "Initial Tableau" by a sequence of unitary matrices. Implementations of the algorithm can take advantage of the fact that the rows of the matrices repeat. The regrouping can be done by "shifting
equations forward" in time in an
![]() version of the tableau.
version of the tableau.
Section A.1 presents a proof that repeating this process of annihilating and regrouping rows ultimately produces an
![]() with
with
![]() non-singular. Algorithm 1 presents pseudo code for an algorithm for computing the components of the state space transition matrix and
the auxiliary initial conditions.
non-singular. Algorithm 1 presents pseudo code for an algorithm for computing the components of the state space transition matrix and
the auxiliary initial conditions.

The algorithm terminates with:
 |
(11) |
with |
|
| (12) | |
Then |
|
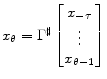 |
(13) |
This unconstrained auto-regression in ![]() provides exactly what one needs to construct the state space transition matrix.
provides exactly what one needs to construct the state space transition matrix.
 |
(14) |
so that |
|
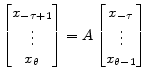 |
(15) |
3.1.2 Asymptotic Linear Constraint Matrix:
In order to compute solutions to equation 8 that converge, one must rule out explosive trajectories. Blanchard and Kahn[Blanchard & Kahn, 1980] used eigenvalue and eigenvector calculations to characterize the space in which the solutions must lie. In contrast, our approach uses an orthogonality constraint to characterize regions which the solutions must avoid.
Each left eigenvector associated with a given eigenvalue is orthogonal to each right eigenvector associated with roots associated with different eigenvalues. Since vectors in the left invariant space associated with roots outside the unit circle are orthogonal to right eigenvectors associated with roots inside the unit circle, a given state vector that is part of a convergent trajectory must be orthogonal to each of these left invariant space vectors. See theorem 4. Thus, the algorithm can exploit bi-orthogonality and a less burdensome computation of vectors spanning the left invariant space in order to rule out explosive trajectories.
If the vectors in V span the invariant space associated with explosive roots, trajectories satisfying equation 8 are non-explosive if and only if
| (16) |
with the eigenvalues of
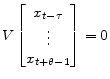 |
(17) |
for some
Combining V and ![]() completely characterizes the space of stable solutions satisfying the linear system 8.
completely characterizes the space of stable solutions satisfying the linear system 8.
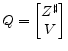 |
(18) |
The first set of equations come from the equations in equation system 8 which do not appear in the transformed system of Equation 1 but must nevertheless be satisfied. The second set of equations come from the constraint that the solutions are non-explosive. Algorithm 3.1.2 provides pseudo code for computing Q.

3.1.3 Convergent Autoregressive Representation: 
The first two algorithms together produce a matrix ![]() characterizing constraints guaranteeing that trajectories are not explosive. See theorem 5 and corollary 2 for a proof. [Hallet & McAdam, 1999] describes how to use the matrix
characterizing constraints guaranteeing that trajectories are not explosive. See theorem 5 and corollary 2 for a proof. [Hallet & McAdam, 1999] describes how to use the matrix ![]() from Section 3.1.2 to impose saddle point
stability in non linear perfect foresight models. However, for linear models with unique saddle point solutions it is often useful to employ an autoregressive representation of the solution. Theorem 6 in Section A.3 provides a fully general
characterization of the existence and uniqueness of a saddle point solution.
from Section 3.1.2 to impose saddle point
stability in non linear perfect foresight models. However, for linear models with unique saddle point solutions it is often useful to employ an autoregressive representation of the solution. Theorem 6 in Section A.3 provides a fully general
characterization of the existence and uniqueness of a saddle point solution.
A summary for typical applications of the algorithm follows. Partition
![]() where
where ![]() has
has ![]() columns. When
columns. When
![]() ,
, ![]() is square. If
is square. If ![]() is non-singular, the system has a unique solution7
is non-singular, the system has a unique solution7
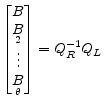 and solutions are of the form and solutions are of the form 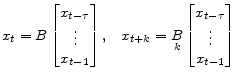 |
(19) |
Algorithm 3 provides pseudo code for computing B.
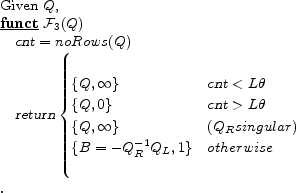
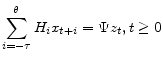
3.2.1 Inhomogeneous Factor Matrices: 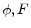
| (22) | |
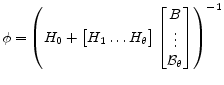 |
(23) |
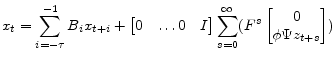 |
(24) |
will satisfy the linear inhomogeneous system equation 20.
See Section A.4 for derivations and formulae. Algorithm 4 provides pseudo code for computing ![]() and
and ![]() .
.
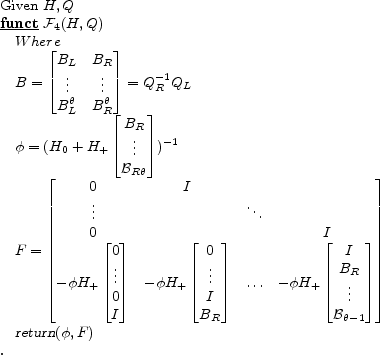
3.2.2 Exogenous VAR Impact Matrix,
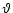
Modelers can augment the homogeneous linear perfect foresight solutions with particular solutions characterizing the impact of exogenous vector autoregressive variables.
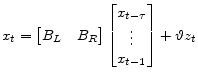
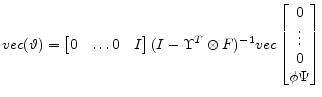
See Section A.5 for derivations and formulae.
3.3 Implementations
This set of algorithms has been implemented in a wide variety of languages. Three implementations, a Matlab, a "C", and a Mathematica implementation, are available from the author.Each implementation avoids using the large tableau of Figure 2. They each shift
elements in the rows of a single copy of the matrix ![]() . Each implementation eliminates inessential lags from the autoregressive representation before constructing the state space transition
matrix for invariant space calculations.
. Each implementation eliminates inessential lags from the autoregressive representation before constructing the state space transition
matrix for invariant space calculations.
The most widely used version is written in MATLAB. The MATLAB version has a convenient modeling language front end for specifying the model equations and generating the ![]() matrices.
matrices.
The "C" version, designed especially for solving large scale models is by far the fastest implementation and most frugal with memory. It uses sparse linear algebra routines from SPARSKIT[Saad, 1994] and HARWELL[Numerical Analysis Group, 1995] to economize on memory. It avoids costly eigenvector calculations by computing vectors spanning the left invariant space using ARPACK[Lehoucq et al., 1996].
For small models, one can employ a symbolic algebra version of the algorithms written in Mathematica. On present day computers this, code can easily construct symbolic state space transition matrices and compute symbolic expressions for eigenvalues for models with 5 to 10 equations. The code can often obtain symbolic expressions for the invariant space vectors when the transition matrix is of dimension 10 or less.
4 Other Useful Rational Expectations Solution Calculations
Economists use linear rational expectations models in a wide array of application. The following sections describe calculations which are useful for optimal policy design, model simulation and estimation exercises.
4.1 Observable Structure: 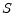
To compute the error term for estimation of the coefficients of these models, one must commit to a particular information set. Two typical choices are t and t-1 period expectations.
Given structural model matrices,
![]() and convergent autoregression matrices
and convergent autoregression matrices
![]() there exists an observable structure matrix,
there exists an observable structure matrix, ![]()
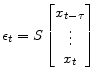 |
(28) |
See Section A.6 for a derivation and formula for ![]() . Algorithm 5 provides pseudo code for computing S for a given lag,
. Algorithm 5 provides pseudo code for computing S for a given lag,
![]() in the availability of information.
in the availability of information.
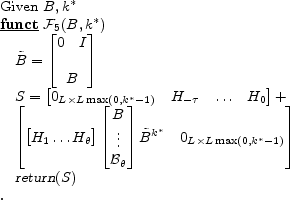
4.2 Stochastic Transition Matrices:
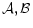
To compute covariances, practitioners will find it useful to construct the stochastic transition matrices
![]() and
and
![]() .
.
Given structural model matrices,
![]() and convergent autoregression matrices
and convergent autoregression matrices
![]() there exist stochastic transition matrices
there exist stochastic transition matrices
![]() ,
,
![]() such that
such that
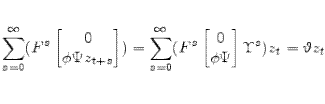
![\displaystyle \begin{bmatrix}x_{t-\tau+1}\\ \vdots\\ x_{t} \end{bmatrix}= \mathcal{A}\begin{bmatrix}x_{t-\tau}\\ \vdots\\ x_{t-1} \end{bmatrix} + \mathcal{B}\begin{bmatrix}\epsilon_{t} + \Psi (E[z_t\vert I_t]-E[z_t\vert I_{t-1}]) \end{bmatrix}](img90.gif) |
(29) |
See Section A.7 for derivations and formulae for
![]() and
and
![]() . Algorithm 6 provides pseudo code for computing
. Algorithm 6 provides pseudo code for computing
![]() and
and
![]()
5 Conclusions
This paper describes a set of algorithms that have proved very durable and useful for staff at the central bank. The most distinctive features of this approach are:
- its algorithm for computing the minimal dimension state space transition matrix
- its use of bi-orthogonality to characterize the asymptotic constraints that guarantee stability.
- It's reliance on QR Decomposition and the real Schur Decomposition for speed and accuracy.
The unique combination of features makes the algorithm more efficient than all the alternatives--especially for large models. Staff at the Federal Reserves have developed a large scale linear rational expectations model consisting of 421 equations with one lead and one lag. This model provides an extreme example of the speed advantage of the Anderson-Moore Algorithm(AMA). On an Intel(R) Xeon 2.80GHz CPU running Linux the MATLAB version of AMA computes the rational expectations solution in 21 seconds while the the MATLAB version of gensys, a popular alternative procedure, requires 16,953 seconds. See [Anderson, 2006] for a systematic comparison of this algorithm with the alternative procedures. The code is available for download at
http://www.federalreserve.gov/Pubs/oss/oss4/aimindex.html
Tech. rept. Federal Reserve System, Finance and Economics Discussion Series.
Economics Letters, 17(3).
Econometrica, 48(5), 1305-11.
Tech. rept. 1996-41. Federal Reserve Board, Finance and Economics Discussion Series.
Tech. rept. 2003-21. Federal Reserve Bank of San Francisco, Working Papers in Applied Economic Theory.
Pages 43-69 of: Fuhrer, Jeffrey C. (ed), `Goals, Guidelines, and Constraints Facing Monetary Policymakers'.
Federal Reserve Bank of Boston Conference Series No. 38.
Quarterly Journal of Economics, 111(November), 1183-1209.
Journal of Money Credit and Banking, 29, No. 2(May), 214-234.
Journal of Money Credit and Banking, 29, No. 3(August), 338-350.
Carnegie-Rochester Conference Series on Public Policy, forthcoming.
Journal of Economic Dynamics and Control, 17, 531-553.
Review of Economics and Statistics, 79, No. 4(November), 573-585.
Journal of Money Credit and Banking, 27, No. 4(November), 1060-70.
Quarterly Journal of Economics, 110(February), 127-159.
American Economic Review, 85(March), 219-239.
Journal of Monetary Economics, 35(February), 115-157.
Kluwer Academic Publishers.
Chap. Accelerating Non Linear Perfect Foresight Solution by Exploiting the Steady State Linearization.
Tech. rept. Department of Computational and Applied Mathematics Rice University.
Are Simple Rules Robust under Model Uncertainty?
Seminar Paper.
IEEE Transactions on Automatic Control, 312-321.
Automatica, 14, 473-480.
Prentice-Hall, Inc.
Tech. rept. The Numerical Analysis Group.
Tech. rept. 98-50. Finance and Economics Discussion Series.
Price Stability and Monetary Policy Effectiveness when Nominal Interest Rates are Bounded at Zero.
Working Paper.
Brookings Papers on Economic Activity.
A Quantitative Exploration of the Opportunistic Approach to Disinflation.
Tech. rept. 97-36. Federal Reserve Board, Finance and Economics Discussion Series.
Tech. rept. Computer Science Department, University of Minnesota.
The American Economic Review, 69(2), 108-113.
Tech. rept. 169. Universita' Politecnica delle Marche (I), Dipartimento di Economia.
A.1 Unconstrained Autoregression
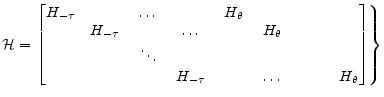
|
(A.1) |
There are two cases:
- When
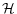 is full rank the algorithm terminates with
is full rank the algorithm terminates with
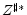 (
(
 ) and non-singular
) and non-singular
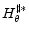 (
(
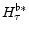 )
) - When
is not full rank the algorithm terminates when some row of
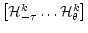 is zero.
is zero.
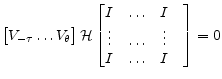
Proof Consider the case whenis singular, increases the row rank of
by at least one. At each step
are full rank. The rank of
.
The following corollary indicates that models with unique steady-states always terminate with non singular
![]() .
.
-
is full rank.
- The origin is the unique steady state of equation 1.
- there exists a sequence of elementary row operations that transforms
into
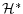
Proof Supposesuch that
. Consequently,
 |
(A.2) |
and |
|
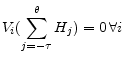 |
(A.3) |
So thatmust be singular.
A.2 Asymptotic Constraints
| (A.4) | |
| (A.5) |
With eigenvalues of
Proof A right eigenvectorand a left-eigenvector
corresponding to distinct eigenvalues
and
are orthogonal.[Noble, 1969] Finite dimensional matrices have finite dimensional Jordan blocks. Raising a given matrix to a power produces a matrix with smaller Jordan blocks. Raising the matrix to a high enough power ultimately eliminates all nontrivial Jordan Blocks. Consequently, the left invariant space vectors are linear combination of the left eigenvectors and the right invariant space vectors are a linear combination of the right eigenvectors of the transition matrix raised to some finite power.
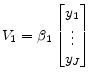 |
(A.6) |
| (A.7) | |
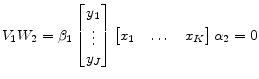 |
(A.8) |
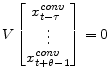 |
(A.9) |
Proof Using, the left generalized eigenvectors of
| (A.10) | |
so that |
|
| (A.11) | |
| (A.12) | |
| (A.13) | |
| (A.14) | |
Consequently, |
|
| (A.15) | |
so that |
|
| (A.16) | |
|
(A.17) |
for some
Proof
| (A.18) | |
means |
|
| (A.19) | |
| (A.20) | |
A.3 Existence and Uniqueness
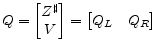 |
(A.21) |
with
The existence of convergent solutions depends on the magnitudes of the ranks of the augmented matrix
| (A.22) | |
and |
|
| (A.23) | |
By construction,
- If
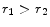 there is no nontrivial convergent solution
there is no nontrivial convergent solution - If
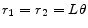 there is a unique convergent solution
there is a unique convergent solution - If
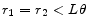 the system has an infinity of convergent solutions
the system has an infinity of convergent solutions
and solutions are of the form 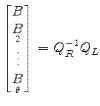
|
(A.24) | |
|
(A.25) | |
If
When
![]() , The system has an infinity of solutions.
, The system has an infinity of solutions.
When ![]() has more than
has more than ![]() rows, The system has a unique nontrivial
solution only for specific values of
rows, The system has a unique nontrivial
solution only for specific values of ![]()
Proof of rank of Q
Proof The theorem applies well known results on existence and uniqueness of solutions to linear equation systems[Noble, 1969]. Ifdoes not lie in the column space of
, then there is no solution. If
lies in the column space of
and the latter matrix is full rank, then there is a unique solution. If
A.4 Proof of Theorem 1
Proof Construct thematrix:
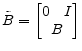 |
(A.26) |
Define |
|
| (A.27) | |
Applying equation 8 to the unique convergent solution, it follows that
where 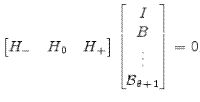
|
(A.28) | |
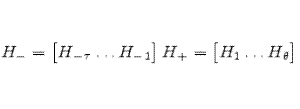
|
(A.29) | |
Which can also be written as:
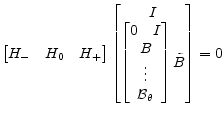 |
(A.30) |
So that:
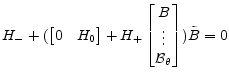 |
(A.31) |
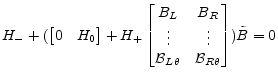 |
(A.32) |
where thematrices are
.
Note that
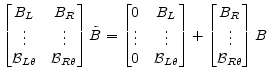 |
(A.33) |
Now
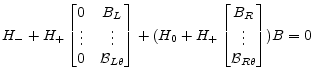 |
(A.34) |
Define
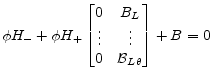
Consider the impact that the timevalue
has on the value of
We can write
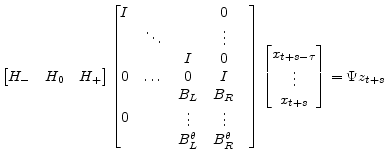
|
(A.37) |
or equivalently,
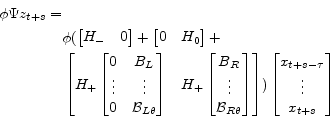
|
(A.38) |
or
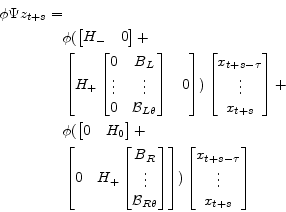
|
(A.39) |
Which by equations A.35 and A.36 can be written
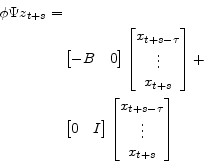 |
(A.40) |
So we have
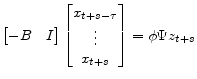
|
(A.41) |
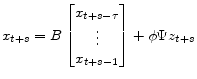 |
(A.42) |
Now consider the impact of. We can write
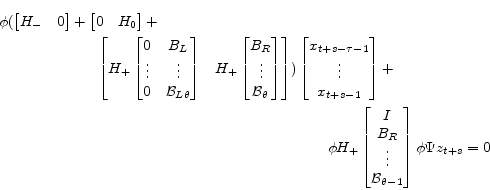
where the last term captures the impact
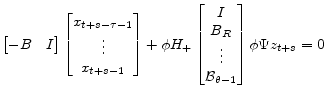 |
(A.43) |
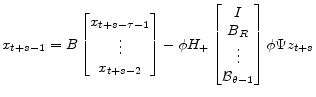 |
(A.44) |
and more generally |
|
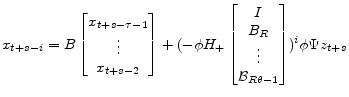 |
(A.45) |
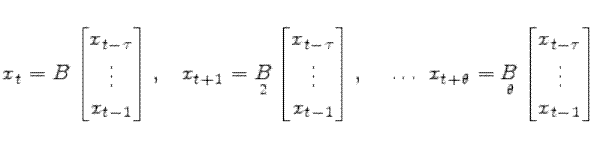
To accommodate lagged expectations, suppose that information on all the endogenous variables becomes available with the same lag () in time:
such that
then set,
![\displaystyle \begin{bmatrix}E [x_{t+1} \vert I_t] \\ \vdots \\ E [x_{t+\theta}\vert I_t] \end{bmatrix} = \begin{bmatrix}B\\ \vdots\\ \mathcal{B}_{\theta} \end{bmatrix} \tilde{B}^{k^\ast} \begin{bmatrix}x^{data}_{t-\tau+1-k^\ast}\\ \vdots \\ x^{data}_{t-k^\ast} \end{bmatrix} +](img187.gif) |
(A.46) |
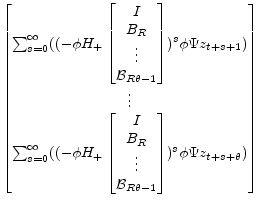
|
(A.47) |
So that
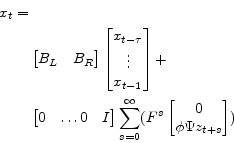
Where
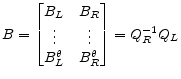 |
(A.48) |
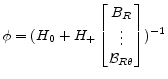 |
(A.49) |
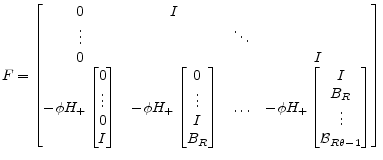
|
(A.50) |
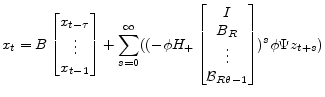 |
(A.51) |
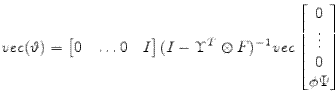
A.6 Observable Structure
Since one can write
![\displaystyle \epsilon_t = \begin{bmatrix}H_{-\tau}\ldots H_0 \end{bmatrix} \begin{bmatrix}x^{data}_{t-\tau}\\ \vdots \\ x^{data}_{t} \end{bmatrix} + \begin{bmatrix}H_{1}\ldots H_\theta \end{bmatrix} \begin{bmatrix}E [x_{t+1} \vert I_t] \\ \vdots \\ E [x_{t+\theta}\vert I_t] \end{bmatrix} - \Psi z_t](img194.gif)
|
(A.54) |
We find that
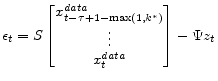 |
(A.55) |
where |
|
| (A.56) | |
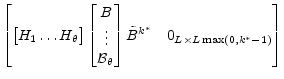 |
(A.57) |
Note that for
![]()
| (A.58) |
and for
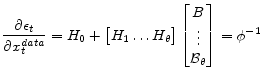 |
(A.59) |
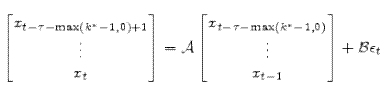
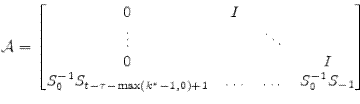
B. An Example
This section applies algorithms 1-3 to the following model with N=2.[Taylor, 1979]
![\displaystyle w_t=\frac{1}{N}E_t[\sum_{i=0}^{N-1}W_{t+i}] - \alpha (u_t-u_n) + \nu_t](img204.gif) |
(B.1) |
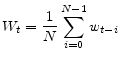 |
(B.2) |
| (B.3) | |
| (B.4) |
The initial matrix
![]() , for the example model with variable order
, for the example model with variable order
![]() is
is
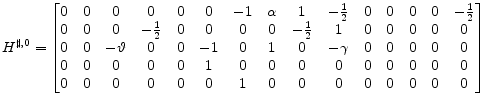
|
We would like to express the time
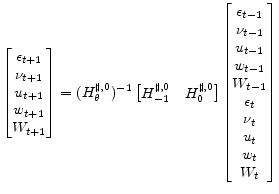
|
Since
![]() is singular, we use equations dated subsequent to the present time period to construct a set of linear constraints where the leading block is non singular.
is singular, we use equations dated subsequent to the present time period to construct a set of linear constraints where the leading block is non singular.
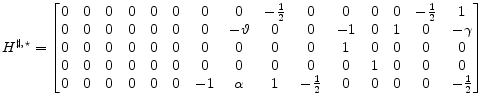
|
So that
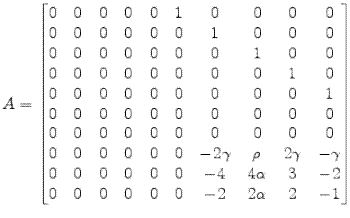
|
(B.5) | |
where
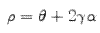
|
(B.6) | |
For the example model
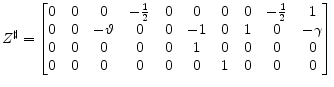
|
where the |
|
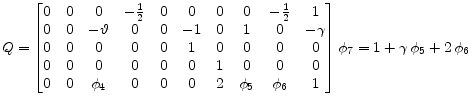
|
|
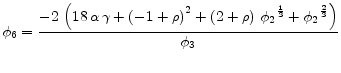 |
|
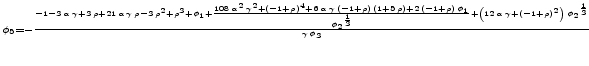
|
|
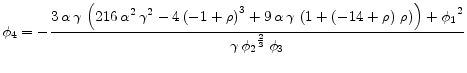 |
|
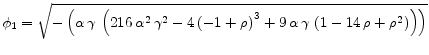 |
|
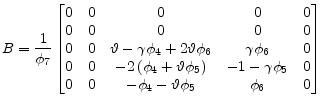
|
Footnotes
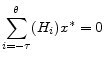 |
(7) |
lie in a linear subspace of
When ![]() has more than
has more than ![]() rows, The system has a unique nontrivial solution
only for specific values of
rows, The system has a unique nontrivial solution
only for specific values of ![]() . Return to Text
. Return to Text