
Cointegration Test with Stationary Covariates and the CDS-Bond Basis during the Financial Crisis
Keywords: Cointegration, stationary covariates, local asymptotic power, CDS basis.
Abstract:
JEL Classification: C12, C22, G12.
1 Introduction
Tests for cointegration are important tools for empirical macroeconomics and finance. Residual based tests for the null of no cointegration, pioneered by Engle & Granger (1987), have the advantages of computational ease and good small sample size properties. These tests involve running regressions and forming simple test statistics. However, residual based tests suffer from low power under the alternative hypothesis. Among other papers, this problem is highlighted by Pesavento (2004), who finds that while residual based tests have good size in most cases, their power disadvantage relative to system-based cointegration tests is significant.
The goal of this paper is to construct a more powerful residual based cointegration test. In empirical analysis, researchers often have data on variables other than the cointegration candidates. For instance, when testing for Purchasing Power Parity (PPP), time series for GDP and money growth rates are observed together with exchange rates and prices (see Amara & Papell, 2006). These variables, or covariates, may be helpful in uncovering cointegration relationships. The idea of this paper is to take advantage of these covariates in testing for cointegration.
The inclusion of stationary covariates has been shown to improve the power of tests under local-to-unity alternatives in the univariate setting. Hansen (1995) first proposed a unit root test where the leads and lags of stationary covariates are included in the inference. Elliott & Jansson (2003) provided point optimal unit root tests that include stationary covariates in presence of deterministic trends. In the multivariate setting, Jansson (2004) shows that stationary covariates can be used to increase power of tests with the null of cointegration. In addition, Seo (1998) shows that covariates significantly improve the power of Johansen rank tests, while Rahbek & Mosconi (1999) study the asymptotic implications of covariate inclusion.
We add to the work described above by including stationary covariates in the construction of the Augmented Dickey-Full (ADF) cointegration test. Intuitively, when stationary covariates related to the cointegration candidates are included in the residual regression, parameters of the regression are more precisely estimated, resulting in a more powerful test. The new test is named the Covariate Augmented Dickey-Fuller (CADF) test. The extent of power improvement depends on the long-run correlations between the stationary covariates and cointegration candidates. Asymptotic analysis shows that the local-to-unity power functions of the CADF test depends critically on these long-run correlations. Not surprisingly, when the covariates and cointegration candidates have zero long-run correlations, the power functions are the same as those of the ADF test.
Large sample Monte Carlo simulations are used to illustrate the asymptotic results, revealing two interesting facts. First, the power of ADF test serves as the lower bound for the power of the CADF test, in all experiments conducted. This means that asymptotically, the CADF test does at least as well as the ADF test. Second, the power of the CADF test is the highest when the covariates are highly correlated with both the cointegration error as well as the right hand side variables in the cointegration relationship.
Deriving asymptotic critical values for the CADF test is difficult due to the presence of nuisance parameters in the asymptotic null distribution. As pointed out by Elliott & Pesavento (2009), there are no obvious ways to estimate the nuisance parameters. Therefore, we propose a bootstrap procedure to obtain critical values in finite samples. Small sample Monte Carlo simulations are conducted to assess the performance of the bootstrapped CADF tests under various cases of deterministic trends and various correlation scenarios. They show that the CADF test has reasonable size and good power in finite samples relative to not only the ADF test, but the Johansen test as well.
In an empirical application of the new test, we investigate whether there are cointegrating relationships between Credit Default Swap (CDS) spreads and corporate bond spreads, for 24 US firms during the 2007-2009 financial crisis. Previous work Blanco (2005), Zhu (2006), De Wit (2006), Levin (2005) and Norden & Weber (2009), for instance, establishes that cointegration between CDS and bond spreads holds for most firms during benign economic periods. However, it may be the case that traditional cointegration tests used in these studies cannot as easily detect the same relationships during the recent crisis, due to the unprecedented levels of market volatility and uncertainty. The CADF test allows us to partially control for such factors through the use of covariates such as the and VIX index returns and the Libor-OIS spread. Indeed, the CADF test finds that cointegration between CDS and bond spreads holds for most firms during the crisis. In comparison, results from the ADF and Johansen tests find cointegration for less firms.
The remainder of the paper will be organized as follows: section 2 describes the model, assumptions, test statistic, and bootstrap inference. It also contains asymptotic analysis of the power of the CADF test. Section 3 investigates the power of the CADF test in large and small samples using simulations. Section 4 presents CADF tests for cointegration between CDS and bond spreads during the financial crisis, and section 5 concludes. The appendix contains mathematical proofs, tables and figures.
2.1 Model
Consider the following system:
![\displaystyle \left[\begin{array}{c}(1-\rho L)\varepsilon_{t}\ \Delta\mathbf{X}_{t}\ \mathbf{Z}_{t}\end{array}\right]=\left[\begin{array}{c}0\\ \mu_{X}+\tau_{X}t\ \mu_{Z}+\tau_{Z}t\end{array}\right]+\xi_{t}(\rho)](img5.gif)
Where
![]() is a vector of scalar
is a vector of scalar
![]() for
for
![]() ,
,
![]() of dimension
of dimension ![]() , and
, and
![]() of dimension
of dimension ![]() .
. ![]() and
and
![]() are the candidates for cointegration.
are the candidates for cointegration.
![]() are stationary covariates to be be utilized in the CADF test.
are stationary covariates to be be utilized in the CADF test.
For brevity and in order to keep notation simple, theoretical work in this paper is based on the case of no deterministic components, i.e.,
![]() and
and
![]() are set equal to zero. In section 3, extensive simulation evidence is presented on the performance of the proposed test when deterministic components are
present.
are set equal to zero. In section 3, extensive simulation evidence is presented on the performance of the proposed test when deterministic components are
present.
The hypothesis of interest is
-
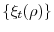 is a stationary process with zero mean, finite variance and continuous spectral density
is a stationary process with zero mean, finite variance and continuous spectral density
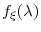 , for
, for
![\lambda\in[0,\pi]](img26.gif) .
. -
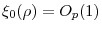 .
. - For
![r\in (0,1]](img28.gif) and
and ![[Tr]](img29.gif) denoting the integer part of
denoting the integer part of 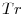 , as
, as
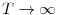
![\displaystyle T^{-1/2}\sum_{t=1}^{[Tr]}\xi_{t}(\rho)\Rightarrow \Omega^{1/2}\mathbf{W}(r)](img32.gif)
Where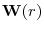 a
a
 standard vector Brownian motion, partitioned conformably into
standard vector Brownian motion, partitioned conformably into
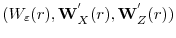 ,
, 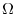 a
positive definite long run variance-covariance matrix
a
positive definite long run variance-covariance matrix
![\displaystyle \Omega\equiv\left[\begin{array}{ccc}\omega_{\varepsilon\varepsilon}&\omega^{'}_{\varepsilon X}&\omega^{'}_{\varepsilon Z}\ \omega_{\varepsilon X}&\Omega_{XX}&\omega^{'}_{XZ}\ \omega_{\varepsilon Z}&\omega_{XZ}&\Omega_{ZZ}\end{array}\right]\equiv 2\pi f_{\xi}(0)](img37.gif)
And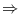 denotes weak convergence. Furthermore, assume that each element in the sigma-algebra
denotes weak convergence. Furthermore, assume that each element in the sigma-algebra
 is independent of
.
is independent of
.
We also define an alternative decomposition of ![]() that is useful in presenting the asymptotic results that follow as:
that is useful in presenting the asymptotic results that follow as:
![\displaystyle \Omega\equiv\left[\begin{array}{cc}\omega_{\varepsilon\varepsilon}&\omega^{'}_{\varepsilon Q}\ \omega_{\varepsilon Q}&\Omega_{QQ}\end{array}\right]](img40.gif) |
Where
![\omega_{\varepsilon Q}=\left[\begin{array}{cc}\omega_{\varepsilon X}^{'}&\omega_{\varepsilon Z}^{'}\end{array}\right]'](img41.gif) and
and
![\mathbf{Q}_{t}\equiv\left[\begin{array}{cc}\Delta\mathbf{X}_{t}^{'}&\mathbf{Z}_{t}^{'}\end{array}\right]'](img43.gif) .
.
- For
 and
,
and
,
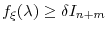 .
. - Define
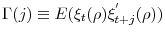 and the following matrix norm: for a
and the following matrix norm: for a  matrix
matrix  ,
,
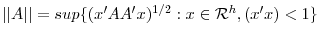 . It is required that
. It is required that
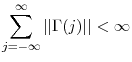
- Define
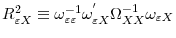 and
and
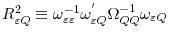 . It is required that
. It is required that
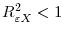 and
and
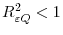 .
.
Suppose data is generated by (1) and (2) and assumptions 1.1, 2.1 and 2.2 are satisfied. Then the following equation holds
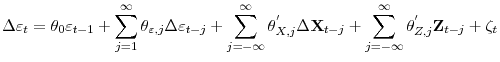
Where
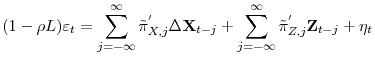
With
Notice that unlike the traditional ADF test, the leads and lags of the covariates, as well as those of
![]() , are included in the CADF regression. Proposition 1 provides the motivation for deriving a test based on a feasible version of (3).
, are included in the CADF regression. Proposition 1 provides the motivation for deriving a test based on a feasible version of (3).
2.2 Test Statistic
![]() is typically not observed unless the cointegrating vector is pre-specified, therefore an estimate of
is typically not observed unless the cointegrating vector is pre-specified, therefore an estimate of ![]() is required. We consider the OLS estimate of the cointegrating vector.1 Let
is required. We consider the OLS estimate of the cointegrating vector.1 Let
![]() be the estimate of the cointegrating vector and
be the estimate of the cointegrating vector and
![]() be the residuals.2 Noting that
be the residuals.2 Noting that
![]() , using (4), similar to the derivation of (3),
, using (4), similar to the derivation of (3),
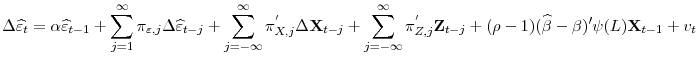
Where conditional on
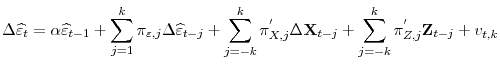
where
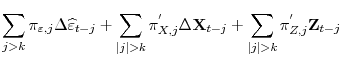 |
A t-statistic to test
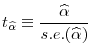 |
(7) |
where s.e.
2.3 The Bootstrap
The asymptotic null distribution depends on difficult to estimate nuisance parameters (more specifically, as shown in the next section,
![]() and
and
![]() ). This is closely related to an issue pointed out by Elliott & Pesavento (2009) regarding the long run correlation parameter
between what would be the equivalent of
). This is closely related to an issue pointed out by Elliott & Pesavento (2009) regarding the long run correlation parameter
between what would be the equivalent of
![]() and
and
![]() of this paper. The authors on p1832 note that "...in practice, this parameter is not only unknown, but also, under the null and local alternative, there is no obvious way
to obtain a good estimate of this parameter". In light of this difficulty, we propose a bootstrap inference instead of relying on asymptotics. In particular, the bootstrap inference is designed to take into account the following cases of deterministic trends:
of this paper. The authors on p1832 note that "...in practice, this parameter is not only unknown, but also, under the null and local alternative, there is no obvious way
to obtain a good estimate of this parameter". In light of this difficulty, we propose a bootstrap inference instead of relying on asymptotics. In particular, the bootstrap inference is designed to take into account the following cases of deterministic trends:
- Case 1.
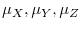 and
and
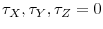 ;
;
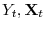 and
and
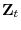 are neither de-meaned nor de-trended prior to inference.
are neither de-meaned nor de-trended prior to inference. - Case 2.
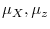 and
,
and
,
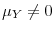 ;
and
are de-meaned prior to inference.
;
and
are de-meaned prior to inference. - Case 3.
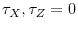 ,
,
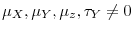 ;
and
are de-meaned and de-trended prior to inference.
;
and
are de-meaned and de-trended prior to inference.
- Step 1. If the deterministic trend follows cases 2 or 3, then de-mean, or de-mean and de-trend
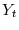 and
and
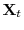 . Estimate
. Estimate
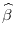 and
and
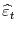 using this data. Run
using this data. Run
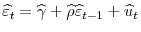 .4
.4 - Step 2. Choose a positive integer
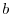 . Define
. Define
![k=[(T-1)/b]](img113.gif) where
where ![[\cdot]](img114.gif) is the integer part. Let
is the integer part. Let
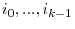 be random i.i.d. draws from the uniform distribution on
be random i.i.d. draws from the uniform distribution on
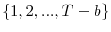 . We generate pseudo series for
. We generate pseudo series for
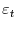 . Set
. Set
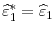 , and for
, and for
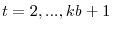 ,
,
![\displaystyle \widehat{\varepsilon}^{*}_{t}=\widehat{\varepsilon}^{*}_{t-1}+\widehat{u}_{i_{[(t-2)/b]}+t-[(t-2)/b]b-1}](img120.gif)
- Step 3. Now construct pseudo series for
and
that reflect the various cases of deterministic trends. Specifically, for
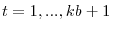 ,
,
- Case 1.
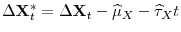 ,
,
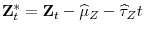 , and
, and
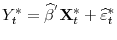
- Case 2.
,
, and
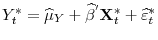
- Case 3.
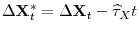 ,
,
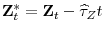 , and
, and
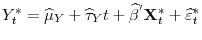
- Case 1.
- Step 4. Finally, with pseudo data
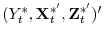 , de-mean or de-mean and de-trend under the appropriate deterministic case, and compute
, de-mean or de-mean and de-trend under the appropriate deterministic case, and compute
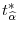 . Repeat steps 1-4 a large number of times to obtain the bootstrap null distribution for
. Repeat steps 1-4 a large number of times to obtain the bootstrap null distribution for
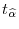 .
.
2.4 Asymptotics
We are interested in the distribution of
![]() under a local-to-unity version of
under a local-to-unity version of ![]() . This section gives
precise statements as to how the distribution for
. This section gives
precise statements as to how the distribution for
![]() is different from the distribution of the ADF test. Following Phillips (1987), Hansen (1995), and
Pesavento (2004), re-define
is different from the distribution of the ADF test. Following Phillips (1987), Hansen (1995), and
Pesavento (2004), re-define ![]() so that for some constant
so that for some constant ![]() ,
,
so that
The truncation lag ![]() in (6) satisfies
in (6) satisfies
![]() as
as
![]() , with the bound that
, with the bound that
![]() .
.
For a symmetric positive definite matrix ![]() , define its Cholesky and inverse Cholesky decompositions as
, define its Cholesky and inverse Cholesky decompositions as
![]() and
and
![]() . Unless otherwise stated, let
. Unless otherwise stated, let
![]() for some vector stochastic process
for some vector stochastic process
![]() .
.
Define
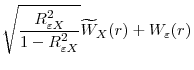 |
|||
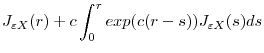 |
where
![\displaystyle D^{c}_{1}\equiv\left[\begin{array}{cc}\sqrt{\frac{1-R^{2}_{\varepsilon Q}}{1-R^{2}_{\varepsilon X}}}\int J^{c}_{\varepsilon X}dW_{\varepsilon}&\int J^{c}_{\varepsilon X}d\mathbf{W}^{'}_{X}\\ \sqrt{\frac{1-R^{2}_{\varepsilon Q}}{1-R^{2}_{\varepsilon X}}}\int \mathbf{W}_{X}dW_{\varepsilon}&\int\mathbf{W}_{X}d\mathbf{W}^{'}_{X}\end{array}\right]](img150.gif)
|
![\displaystyle D^{c}_{2}\equiv\left[\begin{array}{cc}\int (J^{c}_{\varepsilon X})^{2}&\int J^{c}_{\varepsilon X}\mathbf{W}^{'}_{X}\ \int J^{c}_{\varepsilon X}\mathbf{W}_{X}&\int\mathbf{W}_{X}\mathbf{W}^{'}_{X}\end{array}\right]](img151.gif) |
||
![\displaystyle F\equiv\left[\begin{array}{cc}\frac{1-R^{2}_{\varepsilon Q}}{1-R^{2}_{\varepsilon X}}&0\ 0&I_{n}\end{array}\right]](img152.gif) |
![\displaystyle B^{c}\equiv\left[\begin{array}{cc}1&-\left(\int\mathbf{W}^{'}_{X}J^{c}_{\varepsilon X}\right)\left(\int\mathbf{W}_{X}\mathbf{W}^{'}_{X}\right)^{-1}\end{array}\right]'](img153.gif) |
Square matrices
- If in addition assumptions 2 and 3 hold, then
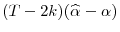
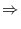
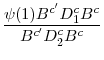
(10) 
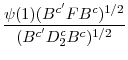
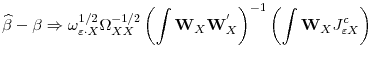
Let the data be generated by (1) and (2) and assume that assumptions 1, 2, and 3 hold. If (8) is true, then as
![]()
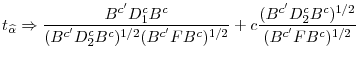
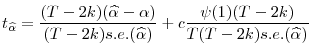 |
This together with Lemma 1 proves the proposition.
Thus, the influence of the covariate feeds through
![]() , the correlation between
, the correlation between
![]() and
and
![]() . To further understand the role of the covariates, consider the case where the covariates have no long run correlation with the cointegration candidates. That is,
. To further understand the role of the covariates, consider the case where the covariates have no long run correlation with the cointegration candidates. That is,
![]() and
and
![]() . In this case, observe that
. In this case, observe that
![]() . This means that now
. This means that now
![]() , where
, where
![\displaystyle \widetilde{D}^{c}_{1}\equiv\left[\begin{array}{cc}\int J^{c}_{\varepsilon X}dW_{\varepsilon}&\int J^{c}_{\varepsilon X}d\mathbf{W}^{'}_{X}\\ \int \mathbf{W}_{X}dW_{\varepsilon}&\int\mathbf{W}_{X}d\mathbf{W}^{'}_{X}\end{array}\right]](img177.gif) |
Furthermore,
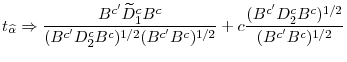
This is the corresponding asymptotic distribution of the ADF test as the covariates have no long run correlations with the cointegration candidates. To the best of our knowledge, (12) is itself a new finding, since the inclusion of leads and lags of
3.1 Large Sample Power
The local-to-unity asymptotic distribution in proposition 2 can be used to assess large sample power of the CADF test. We numerically construct the distribution, for
![]() and -20 using 3,000 samples of Gaussian innovations. Each sample has the size of 3,000, and the innovations are used in constructing the functionals present in the right hand
side of (6). Power is then calculated, for
and -20 using 3,000 samples of Gaussian innovations. Each sample has the size of 3,000, and the innovations are used in constructing the functionals present in the right hand
side of (6). Power is then calculated, for ![]() and -20, as the mass of the distribution to the left of the 5% critical value of the
and -20, as the mass of the distribution to the left of the 5% critical value of the ![]() distribution.
distribution.
Note that the test only depends on
![]() and
and
![]() . Nonetheless, it is more intuitive to express power as a function of pairwise correlations
. Nonetheless, it is more intuitive to express power as a function of pairwise correlations
![]() ,
,
![]() , and
, and
![]() . We set
. We set ![]() and all long run variances equal to one. As such,
and all long run variances equal to one. As such,
![]() and
and
![]() . Figures 1-3 display the power
surfaces across different values of
. Figures 1-3 display the power
surfaces across different values of
![]() ,
,
![]() and
and ![]() .
.
Figure 1: Asymptotic Power of CADF test when 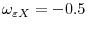
Figure 2: Asymptotic Power of CADF test when 
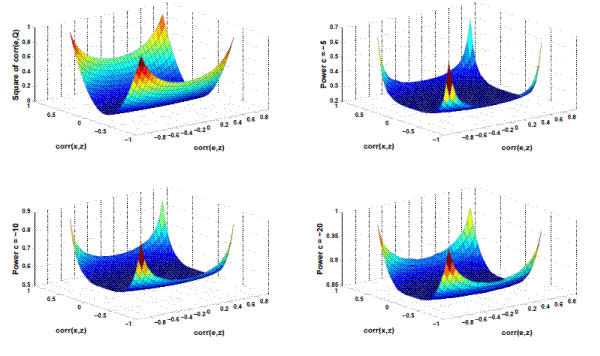
Figure 3: Asymptotic Power of CADF test when 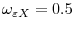
Figures 1, 2, and 3 each show four graphs per figure. The horizontal axes show corr(x,z) and corr(e,z), while the vertical axis shows the square of corr(e,Q) in the top left graph and the local-to-unity power in each of the three remaining graphs. The three graphs showing power on the vertical axis differ by the specifications of the local-to-unity parameter, c. The top right, bottom left, and bottom right graphs show power when c = -5, -10, and -20, respectively. The figures each differ in terms of the specification of corr(e,x). Figures 1, 2, and 3, shows power when corr(e,x) = -0.5, 0, and 0.5, respectively. As expected, for a given combination of corr(e,x), corr(e,z), and corr(x,z), the local-to-unity power increases monotonically as c decreases. Throughout the figures, we see that in general the CADF has high power when corr(e,x) and corr(e,z) are large in magnitude, either with different signs when corr(x,z) is positive, or with the same signs when corr(x,z) is negative. Importantly, the ADF tests (where corr(e,z) and corr(x,z) = 0) always have the lowest power.
As expected, for a given combination of
![]() ,
,
![]() , and
, and
![]() , the power increases monotonically as
, the power increases monotonically as ![]() decreases. Comparing the
graphs in each of the figures with the top-left graph of that figure, it is also clear that the power function mimics the shape of
decreases. Comparing the
graphs in each of the figures with the top-left graph of that figure, it is also clear that the power function mimics the shape of
![]() , although the exact shape varies. Throughout the figures, in general the CADF has high power when
, although the exact shape varies. Throughout the figures, in general the CADF has high power when
![]() and
and
![]() are large in magnitude, either with different signs when
are large in magnitude, either with different signs when
![]() is positive, or with the same signs when
is positive, or with the same signs when
![]() is negative. A heuristic interpretation of these conditions is that power is highest when the covariates
is negative. A heuristic interpretation of these conditions is that power is highest when the covariates
![]() convey different information about
convey different information about
![]() than
than
![]() .
.
Importantly, the ADF tests (corresponding to the point on the graphs where
![]() and
and
![]() ) always have the lowest power. For instance, when
) always have the lowest power. For instance, when
![]() and
and ![]() (top-right graph of figure 2), the ADF test has
a power of roughly 20%, while the power of the CADF test could reach 60%. Asymptotically, one cannot do worse in terms of power by using the CADF test instead of the ADF test.
(top-right graph of figure 2), the ADF test has
a power of roughly 20%, while the power of the CADF test could reach 60%. Asymptotically, one cannot do worse in terms of power by using the CADF test instead of the ADF test.
3.2 Small Sample Size and Power
In this section we study the small sample size and power of the CADF test, and compare the size and power to those of the ADF and Johansen
![]() tests. This exercise is important because it is well known that residual based tests are typically less powerful than Johansen's test in small samples. Furthermore, using these
simulations, we study the effects of the presence of deterministic trends.
tests. This exercise is important because it is well known that residual based tests are typically less powerful than Johansen's test in small samples. Furthermore, using these
simulations, we study the effects of the presence of deterministic trends.
Pseudo time series of length 200 are generated in the following way: for each
![]()
![\displaystyle \left[\begin{array}{c}(1-\rho)\varepsilon^{*}_{t}\ \Delta X^{*}_{t}\ Z^{*}_{t}\end{array}\right]](img195.gif) |
![\displaystyle \left[\begin{array}{c}0\ \mu_{X}+\tau_{X}t\ \mu_{Z}+\tau_{Z}t\end{array}\right]+\Omega^{\frac{1}{2}'}N(0,I_{3})](img197.gif) |
||
Under case 1, all
Repeating this procedure 2,000 times, the empirical rejection rates are obtained, representing the small sample power (where
![]() ) and size (where
) and size (where ![]() ). Table 1 contains the size and power
results.
). Table 1 contains the size and power
results.
Table 1: Small Sample Simulation Results
|
|
CADF : (
|
Case 1 |
Case 1 |
Case 1 |
Case 2 |
Case 2 |
Case 2 |
Case 3 |
Case 3 |
Case 3 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ADF | 5.50% | 38.10% | 83.60% | 5.90% | 21.40% | 61.60% | 4.25% | 14.50% | 44.20% |
| 0 | Johansen | 5.20% | 21.70% | 61.40% | 7.60% | 15.60% | 45.60% | 8.70% | 15.30% | 35.40% |
| 0 | CADF(.5,.4) | 5.55% | 53.15% | 92.25% | 6.35% | 43.00% | 85.40% | 2.60% | 12.70% | 49.60% |
| 0 | CADF(.2,-.2) | 5.85% | 46.90% | 86.15% | 7.50% | 36.25% | 79.50% | 3.85% | 12.75% | 40.00% |
| 0 | CADF(0,.4) | 4.95% | 51.25% | 90.10% | 6.80% | 40.15% | 83.60% | 2.85% | 13.75% | 47.25% |
| .5 | ADF | 5.60% | 33.00% | 81.45% | 4.80% | 17.60% | 55.40% | 4.50% | 11.00% | 33.90% |
| .5 | Johansen | 6.00% | 32.90% | 78.85% | 7.60% | 22.60% | 63.90% | 8.30% | 19.70% | 50.10% |
| .5 | CADF(.5,.4) | 5.20% | 57.45% | 93.85% | 7.15% | 40.05% | 87.95% | 3.75% | 15.15% | 47.70% |
| .5 | CADF(.2,-.2) | 5.65% | 63.30% | 95.70% | 6.90% | 47.65% | 90.05% | 2.60% | 14.05% | 51.70% |
| .5 | CADF(0,.4) | 4.40% | 65.35% | 95.90% | 6.25% | 45.75% | 91.55% | 2.60% | 17.15% | 57.05% |
| .9 | ADF | 5.50% | 29.00% | 78.20% | 5.00% | 8.00% | 36.80% | 4.10% | 2.00% | 12.10% |
| .9 | Johansen | 5.60% | 96.30% | 100.00% | 4.50% | 86.10% | 99.90% | 8.40% | 69.10% | 99.10% |
| .9 | CADF(.5,.4) | 6.40% | 95.60% | 100.00% | 7.80% | 74.20% | 99.65% | 3.90% | 22.30% | 83.45% |
| .9 | CADF(.2,-.2) | 2.55% | 98.75% | 99.80% | 1.30% | 87.05% | 97.20% | 0.30% | 32.20% | 68.75% |
| .9 | CADF(0,.4) | 2.40% | 97.95% | 98.95% | 1.40% | 83.65% | 93.45% | 0.15% | 31.10% | 60.45% |
Note: Details on the simulation setup are described in Section 2.3. Numbers are empirical rejection frequencies from 2,000 Monte Carlo simulations. Sample size in each simulation is set to 100. Deterministic cases 1, 2, and 3 are as described in Section 2.3 and this section.
For the CADF and Johansen tests, power increases with
![]() . On the other hand, the power of the ADF test decreases with
. On the other hand, the power of the ADF test decreases with
![]() , and in general becomes significantly lower than the power of the CADF and Johansen tests.
, and in general becomes significantly lower than the power of the CADF and Johansen tests.
The power discrepancy between the ADF and CADF test is particularly large when deterministic terms are present (cases 2 and 3), or when
![]() is large. The ADF test performs well when
is large. The ADF test performs well when
![]() , but still fails to show higher power than the CADF test in all cases other than case 3 when
, but still fails to show higher power than the CADF test in all cases other than case 3 when ![]() . The low power of the ADF test in these cases is consistent with previous findings (e.g.,Pesavento 2004). In terms of size (i.e., when
. The low power of the ADF test in these cases is consistent with previous findings (e.g.,Pesavento 2004). In terms of size (i.e., when ![]() ),
the ADF test has good size in almost every case, while the CADF test tends to be under-sized when
),
the ADF test has good size in almost every case, while the CADF test tends to be under-sized when
![]() is large or under case 3.
is large or under case 3.
The CADF test also compares favorably with the Johansen
![]() test (see Johansen, 1991,1988). It is particularly advantageous under cases 1 and 2 when
test (see Johansen, 1991,1988). It is particularly advantageous under cases 1 and 2 when
![]() or .5, while the Johansen test is advantageous under case
3 for
or .5, while the Johansen test is advantageous under case
3 for
![]() . In all other instances, the powers of the two tests are similar. The Johansen test tends to be over-sized, particularly under case 3, whereas the CADF test under
case 3 is typically under-sized.
. In all other instances, the powers of the two tests are similar. The Johansen test tends to be over-sized, particularly under case 3, whereas the CADF test under
case 3 is typically under-sized.
Finally, we observed that there are minor discrepancies in power for CADF test based on different combinations of
![]() , and the best combination differs depending on the deterministic case,
, and the best combination differs depending on the deterministic case, ![]() , and
, and
![]() .
.
4 Cointegration between Credit Default Swap and Bond Spreads
The seller of a CDS contract offers insurance to the buyer of protection against default of an underlying reference entity. In return for protection, the buyer makes regular payments over the life of the contract. Thus, the CDS "spread"7 is often viewed as the price of the credit risk of the underlying reference entity. Abstracting from other factors, an investor who holds a corporate bond for a given entity requires the same premium as the seller of a CDS contract, since both the bond and CDS are exposed to the same default event of the reference entity. The deviation between the corporate bond spread (accounting for the reference rate) and the CDS spread is referred to as the CDS-bond basis.
Following previous literature, we use the CDS spread minus the par asset-swap rate to measure the basis (see, Kocic (2000), Houweling & Vorst (2005), Hull (2004), or see Choudhry (2006)for explanation of alternative measures). Typically, an asset-swap consists of a fixed coupon bond and an interest-rate swap, where the bond holder pays a fixed coupon and receives a floating spread over LIBOR. It can be thought of as measuring the difference between the present value of future cash flows of the bond and the market price of the bond using zero coupon rates (Choudhry, (2006)).
For no arbitrage conditions to hold, the pricing of credit risk for any underlying entity should be the same in both markets, ceteris paribus. As noted by Zhu (2006), under the Duffie (1999) pricing framework, it is possible to replicate a CDS contract synthetically by shorting a maturity matched par fixed coupon bond on the underlying reference entity, and investing the money in a par fixed risk free note. Therefore, the CDS premium equals the bond spread over the reference rate, or zero basis under no arbitrage. If there exists a negative (positive) basis, arbitrage is possible through a negative (positive) basis trade by buying (shorting) the cash bond and buying protection (selling protection) on the CDS contract.
Previous literature (see, for instance, Blanco (2005), Zhu (2006), De Wit 2006, Levin (2005), Norden & Weber (2009)) notes the existence of the basis and establish it is stationary (i.e., CDS and bond spreads are cointegrated) for most firms during benign economic periods. We revisit this cointegration relationship during the financial crisis, which we define as July 2007 to July 2009. Our conjecture is that unprecedented levels of volatility, illiquidity, and market uncertainty may impose difficulties for traditional tests to find cointegration between CDS and bond spreads. The CADF test, on the other hand, may perform better through the use of covariates to account for some of these factors.
4.1 Covariate Selection
During the financial crisis, evaporation of liquidity in the market caused funding costs to rise (see Giglio, 2010; Fontana, 2010). This coupled with surging counterparty credit risk and market volatility drove the basis wider (see Fontana, 2010)8. While it is difficult to construct explicit proxies for liquidity and counterparty credit risk, our choice of covariates intends to reflect these risk factors.
The first covariate considered is the HFRX Global Hedge Fund Index return (HFRXGL). Hedge funds and banks comprise the largest CDS market participants (see, Anderson, 2010). While banks often use the CDS market to hedge against loan risk, hedge funds on the other hand are important speculators in the CDS market, using CDS contracts as tools to engage in credit arbitrage. Hedge funds also hedge convertible bond positions, and cover their exposures in the CDO market with CDS contracts. It is argued by Brunnermeier (2009) and Anderson (2010) that hedge funds access to external financing plays an important role in the liquidity of assets for which they participate in a large share of market transactions. The extent and rate at which hedge funds can obtain capital is related to their returns (see Boyson (2008), and consequently hedge fund performance affects the liquidity of the CDS market. HFRXGL is therefore used as a proxy for market-wide hedge fund performance.
The second set of covariates is the S&P 500 returns and percentage change VIX. The S&P 500 returns can be viewed as a proxy of market wide performance as a whole, while the VIX index serves as a measure of implied market volatility. Counterparty credit risk and liquidity risk are often heightened during periods of low equity returns and high market volatility. As such, S&P 500 and VIX returns may be driven by the same factors that affect the CDS-bond basis. We also use the two covariates together in order to see how the CADF test performs when there is more than one covariate.
The third covariate is the Libor-OIS spread, which is the difference in the three-month libor and the overnight index swap (OIS) rate. The Libor-OIS spread increases with a perceived rise in bank counterparty credit risk (see Schwarz, 2009). In contrast to CDS contracts, bonds do not have counterparty credit risk. Because counterparty risk is a driver of the basis (see Choudhry, 2006), the Libor-OIS spread is chosen as a covariate.
Finally, daily stock returns for each firm are used as a firm-specific covariate. Drivers of the basis such as firm credit quality, type of institution, the rate at which a firm can obtain funding (see Choudhry, 2006), and many other factors unique to each firm may not be captured by systematic covariates. As noted by Aunon-Nerin et al. (2002), declines in stock price are associated with a rise in CDS premium, and should be considered when assessing credit risk. Therefore, we chose stock returns as a covariate.
4.2 Data
We start with all firms listed in both the Markit Partners CDS and bond data sets between June 2007 and June 2009. Five year CDS spreads are considered as they are the most actively traded. Quotes selected from Markit Partners are for CDS spreads referencing Senior Unsecured, USD denominated debt with the Modified Restructuring (MR) clause. In order to match the remaining maturity of the bond spread to the five year CDS spreads, a generic bond is constructed for each firm from a pool of outstanding bonds similar to the methodology of Zhu (2006).
Using Fixed Income Securities Database (FISD), we constrain our analysis to a list of bonds that meet the following criteria:
- Bonds must not be puttable, callable, convertible, or reverse convertible.
- Bonds must be denominated in USD.
- Bonds must be Senior Unsecured.
- Bonds must be fixed coupon.
For bonds that meet the stated criteria, the daily bond asset-swap rate, the depth of the quote, and type of quote for each bond is obtained from Markit. For each bond, the depth weighted average of both TRACE and Composite quotes is calculated. We eliminate all bonds with remaining maturity shorter than two and a half years or longer than seven years. There are three possible cases in constructing the generic bond for each firm-day. First, all of the firm's available bonds have a shorter remaining maturity than 5 years, or all available bonds have a longer remaining maturity than five years. Second, there is only one bond available. Third, there is at least one bond with maturity shorter than five years and at least one bond with maturity longer than five year. In the first case, the generic bond is the bond with the maturity closest to five years. In the second case, the generic bond is the only available bond. In the third case, the generic bond is the linear interpolation of the closets two bonds on each side of the five year maturity, following Zhu (2006). Using ADF unit root tests, we ensure that all covariates and cointegration candidates are stationary by excluding any firms for which one of these series is non-stationary. The final set of firms has bonds with no more than 20 consecutive days of missing quotes. Based on this construction, there are 24 firms in our final list, similar in length and the number of firms to previous studies.
Daily data for the S&P 500 index, firm stock price, the VIX index, the Libor-OIS spread, and the HFRXGL index are obtained from either Bloomberg or Datastream.9 For each firm, the weekly average of the daily series of bond asset-swap rates, CDS spreads, and each covariate series is calculated. We take the first difference of the log of each covariate, except for the Libor-OIS spread where we simply take the first difference.
4.3 Results
Four sets of CADF tests, one for each set of covariates, is performed under deterministic case 1. Critical values for the CADF test are generated using a 10,000 iteration residual based bootstrap with a block size of 5 (where ![]() ) as described in Section 2.3. To benchmark the CADF tests, we also perform ADF and Johansen cointegration tests using asymptotic critical values. Results for each test are shown in Table 2.
) as described in Section 2.3. To benchmark the CADF tests, we also perform ADF and Johansen cointegration tests using asymptotic critical values. Results for each test are shown in Table 2.
Table 2: Application Results and Test Statistics
| Firm | Johansen |
ADF | CADF (HFRXGL) | CADF (S&P500,VIX) | CADF (Stock Rtn.) | CADF (Libor-OIS) |
| AIG | 23.17*** | -4.74*** | -2.32* | -2.06** | -3.28** | -2.39** |
| ALL | 26.38*** | -4.26*** | -4.40*** | -4.64*** | -4.36*** | -3.75*** |
| AXP | 16.09*** | -2.67* | -3.10*** | -3.55*** | -3.66*** | -2.65** |
| BA | 17.52*** | -4.34*** | -3.85*** | -3.82*** | -4.07*** | -3.77*** |
| CAT | 11.70** | -3.04** | -3.13*** | -2.75*** | -2.54** | -2.43** |
| CIT | 17.21*** | -3.83*** | -2.05** | -2.15** | -2.37** | -2.91*** |
| CL | 28.47*** | -4.82*** | -5.05*** | -5.05*** | -5.30*** | -4.94*** |
| DE | 15.97*** | -3.61*** | -3.67*** | -3.90*** | -3.74*** | -3.21*** |
| DOW | 15.36*** | -3.44*** | -3.86*** | -3.28*** | -3.05*** | -3.37*** |
| ED | 7.80 | -2.42 | -2.20** | -2.20** | -2.09** | -1.96* |
| ENTERP | 7.08 | -0.76 | -1.74 | -1.95 | -1.94 | -1.29* |
| F | 20.58*** | -2.34 | -2.91** | -3.53*** | -3.14** | -2.86** |
| GE | 7.65 | -2.73* | -1.78** | -2.24** | -2.21** | -2.11** |
| GMAC | 21.90*** | -2.92** | -2.34** | -2.98** | -1.82* | -2.71*** |
| GS | 10.48* | -2.61* | -2.92** | -2.98** | -2.95** | -2.86** |
| HSBC | 9.68* | -3.08** | -3.80*** | -3.23*** | -1.88* | -3.01*** |
| KEY | 16.55*** | -3.33** | -3.08** | -3.24*** | -3.00** | -2.71** |
| KIM | 11.85** | -2.14 | -3.24*** | -3.29*** | -3.09** | -3.17*** |
| LEH | 4.31 | -1.83 | -2.15* | -2.45** | -1.93 | -2.16* |
| MER | 4.80 | -2.31 | -0.53 | -0.94 | -1.04 | -0.14 |
| NRUC | 2.83 | -1.54 | -1.85* | -1.24 | -0.94 | -.67 |
| PRU | 26.83*** | -4.27*** | -4.74*** | -4.81*** | -4.62*** | -4.65*** |
| SEAR | 15.96*** | -3.04** | -3.51** | -3.89** | -3.52*** | -3.58*** |
| WFC | 13.22** | -3.41** | -3.20*** | -3.58*** | -4.24*** | -3.69*** |
| # Fail to Reject (10%) | 6 | 7 | 2 | 3 | 4 | 2 |
| # Fail to Reject (5%) | 8 | 10 | 5 | 5 | 6 | 5 |
Notes: 1: Numbers presented are test statistics. 2: ***, **, and * correspond to rejections at the 1, 5, and 10 percent confidence levels, respectively.3: The CADF test is run under deterministic case 1, as described in Section 2.3, with a block size of 5.
The Johansen and ADF tests fail to reject the null of no cointegration at the 10% confidence level for 6 and 7 of the 24 firms, respectively. The CADF test using the S&P 500 index and the percentage change in the VIX fails to reject the null of no cointegration for 3 firms, while the CADF test using firm stock returns fails to reject to null of no cointegration for 4 of the 24 firms at the 10% confidence level. Covariates choices of the HFRXGL index and Libor-OIS spread reject the null of no-cointegration for the most firms, with each failing to reject only 2 firms. Results at the 5% confidence level are qualitatively similar.
Overall, by using covariates the CADF test is able to find more cointegrating relationships than ADF and Johansen tests during the financial crisis. One possible explanation is that the inclusion of covariates removes part of the heightened volatility that may otherwise mask the cointegrating relationships. The strong performance of the CADF test for all sets of covariates is consistent with Anderson (2010), who concludes that during the crisis, systemic factors and market volatility significantly affected the basis.
5 Conclusion and Extensions
This paper introduces a residual based cointegration test with better power. Inclusion of stationary covariates reduces the noise in the system, providing more precise parameter estimates and higher power tests. The test and its asymptotic distribution under the local-to-unity alternative are derived under a simple model and mild assumptions. Due to the dependence of the asymptotic null distribution on hard to estimate nuisance parameters, we provide a bootstrap framework for obtaining test critical values.
Simulations based on the asymptotic results shows that the CADF test has higher power than the ADF test. The magnitude of power improvement depends on the long-run correlation between the cointegration candidates and the stationary covariates. In small samples, Monte Carlo simulations also show that the CADF test has good size and power properties in comparison to the ADF and Johansen tests, under the presence of deterministic trends.
The CADF test is used to study the cointegration relationship between CDS and bond spreads for 24 U.S. firms during the financial crisis. Covariates are chosen to proxy various factors that may affect the CDS-bond basis. The use of covariates allows us to uncover cointegration relationships for more firms than the Johansen and ADF tests, possibly because the covariates partially control for the heightened levels of volatility and market uncertainly that may otherwise mask cointegration relationships.
6.1 Proof of Lemma 1
To prove Lemma 1, some auxiliary results are needed. Define the regressors in the CADF regression as
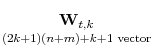 |
![\displaystyle \left[\begin{array}{cccccccccc}\widehat{\varepsilon}_{t-1}&\Delta\mathbf{X}^{'}_{t+k}&...&\Delta\mathbf{X}^{'}_{t-k} &\mathbf{Z}^{'}_{t+k}&...&\mathbf{Z}^{'}_{t-k}&\Delta\widehat{\varepsilon}_{t-1}&...&\Delta\widehat{\varepsilon}_{t-k}\end{array}\right]'](img217.gif)
|
||
![\displaystyle \left[\begin{array}{cc}\widehat{\varepsilon}_{t-1},\widetilde{\mathbf{W}}^{'}_{t,k}\end{array}\right]'](img218.gif) |
Define
From hereon, unless otherwise stated,
If (8) is true, then, as
-
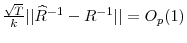 .
. -
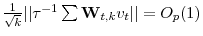 .
. -
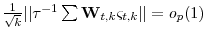 .
. -
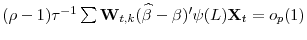 .
.
To prove Lemma 2.4, note that by definition,
![\displaystyle (\rho-1)\tau^{-1}\sum\mathbf{W}_{t,k}(\widehat{\beta}-\beta)'\psi(L)\mathbf{X}_{t}=\left[\begin{array}{c} \frac{c}{T(T-2k)}\sum\widehat{\varepsilon}_{t-1}(\widehat{\beta}-\beta)'\psi(L)\mathbf{X}_{t-1}\ \frac{c}{T\sqrt{T-2k}}\sum\widetilde{\mathbf{W}}_{t,k}(\widehat{\beta}-\beta)'\psi(L)\mathbf{X}_{t-1}\end{array}\right]](img235.gif)
|
The second partition of the vector is clearly
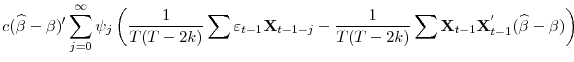 |
Two standard results under assumptions 1 and 2 are
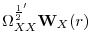
see, for instance, Pesavento (2004, 2006, 2007). Using these and the FCLT, for any finite
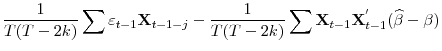 |
|||
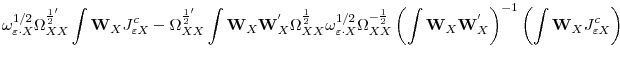
|
|||
| 0 |
This and the fact that
Lemma 1.1 follows directly from (13) and the fact that
![]() .
.
To prove the two statements in Lemma 1.2, re-write the CADF regression (6) as
![]() . First note that
. First note that
![]() is the first element of
is the first element of
Decompose the first term on the right hand side in the following way:
Using Lemma 2,
Given this, by the diagonality of ![]() ,
,
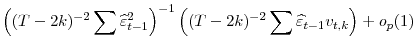 |
|||
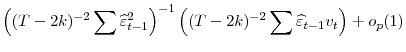 |
Consider the denominator in the last equation:
![\displaystyle \frac{\omega^{-1}_{\varepsilon\cdot X}}{(T-2k)^{2}}\sum\widehat{\varepsilon}^{2}_{t-1}=\frac{\omega^{-1}_{\varepsilon\cdot X}}{(T-2k)^{2}}\left[\begin{array}{cc}1& -(\widehat{\beta}-\beta)'\end{array}\right]\sum\left[\begin{array}{cc}\varepsilon^{2}_{t-1}&\varepsilon_{t-1}\mathbf{X}^{'}_{t}\ \varepsilon_{t-1}\mathbf{X}_{t}&\mathbf{X}_{t}\mathbf{X}^{'}_{t}\end{array}\right]\left[\begin{array}{c}1\ -(\widehat{\beta}-\beta)\end{array}\right]](img261.gif)
|
By Lemma 1.1,
![\displaystyle \left[\begin{array}{cc}1&-(\widehat{\beta}-\beta)'\end{array}\right]\Rightarrow B^{c'}\left[\begin{array}{cc}1&0\ 0&\omega^{1/2}_{\varepsilon\cdot X}\Omega^{-\frac{1}{2}'}_{XX} \end{array}\right]](img262.gif) |
This, together with (13), implies that
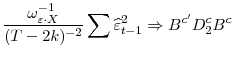
Now consider the numerator
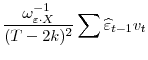 |
![\displaystyle \frac{\omega^{-1}_{\varepsilon\cdot X}}{(T-2k)^{2}}\left[\begin{array}{cc}1& -(\widehat{\beta}-\beta)'\end{array}\right]\sum\left[\begin{array}{cc}\varepsilon_{t-1}\psi(L)\eta_{t} &\varepsilon_{t-1}\psi(L)\Delta\mathbf{X}^{'}_{t}\ \mathbf{X}_{t}\psi(L)\eta_{t}&\mathbf{X}_{t}\Delta\mathbf{X}^{'}_{t}\end{array}\right]\left[\begin{array}{c}1\ -(\widehat{\beta}-\beta)\end{array}\right]](img269.gif)
|
||
![\displaystyle \psi(1)B^{c'}\left[\begin{array}{cc}\omega_{\varepsilon\cdot X}^{-1/2}\omega_{\varepsilon\cdot Q}^{1/2}\int J^{c}_{\varepsilon X}dW_{\varepsilon}&\int J^{c}_{\varepsilon X}d\mathbf{W}^{'}_{X}\ \omega_{\varepsilon\cdot X}^{-1/2}\omega_{\varepsilon\cdot Q}^{1/2}\int \mathbf{W}_{X}dW_{\varepsilon}&\int \mathbf{W}_{X}d\mathbf{W}^{'}_{X}\end{array}\right]B^{c}](img270.gif)
|
|||
Since
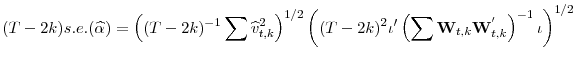 |
where
![\displaystyle (T-2k)^{-1}\left[\begin{array}{cc}1&(\widehat{\beta}-\beta)'\end{array}\right]\sum \psi(L)\left[\begin{array}{cc}\eta^{2}_{t}&\eta_{t}\Delta\mathbf{X}^{'}_{t}\ \Delta\mathbf{X}_{t}\eta_{t}&\Delta\mathbf{X}_{t}\Delta\mathbf{X}^{'}_{t}\end{array}\right]\left[\begin{array}{c}1\ (\widehat{\beta}-\beta)\end{array}\right]](img280.gif)
|
|||
![\displaystyle \psi^{2}(1)B^{c'}\left[\begin{array}{cc}\omega_{\varepsilon\cdot Q}&0\ 0&\omega_{\varepsilon X}I_{n}\end{array}\right]B^{c}](img281.gif) |
|||
Since
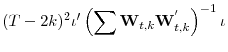 |
|||
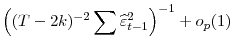 |
|||
This proves Lemma 1.2.
Bibliography
Applied Financial Economics 16(1):29-39.
Applied Economics Letters 17(10):999-1003.
The Journal of Finance 60(5):2255-2281.
NBER Working Paper .
Journal of Economic Perspectives 23(1):77-100.
Bloomberg.
National Bank of Belgium.
Financial Analysts Journal 55(1):73-87.
Journal of Econometrics 115(1):75-89.
Econometric Theory 25(06):1829-1850.
Econometrica 55(2):251-276.
Working Papers .
Princeton Univ Pr.
Econometric Theory 11(05):1148-1171.
Journal of International Money and Finance 24(8):1200-1225.
Journal of Banking & Finance 28(11):2789-2811.
Econometric Theory 20(01):56-94.
Journal of economic dynamics and control 12(2-3):231-254.
Econometrica: Journal of the Econometric Society 59(6):1551-1580.
Lehman Brothers Fixed Income Derivatives Research .
In Fourth Joint Central Bank Research Conference. Citeseer.
Journal of the American Statistical Association 90(429).
European financial management 15(3):529-562.
Econometrica 71(3):813-855.
Journal of Econometrics 122(2):349-384.
Journal of Time Series Analysis 28(1):111-137.
European University Institute.
Biometrika 74(3):535.
The Review of Economic Studies 53(4):473-495.
Econometrica: Journal of the Econometric Society 58(1):165-193.
The Annals of Statistics 20(2):971-1001.
Econometrics Journal 2(1):76-91.
Econometric Theory 7(01):1-21.
Journal of Econometrics 85(2):339-385.
Journal of Financial Services Research 29(3):211-235.